






前日我看到一篇帖子上面有一个关于jieba分词的代码,于是仿照着它敲了一次代码,期间运行时遇到种种问题,但终是解决问题成功让代码跑起来了。特此写下总结,便于日后温习。
import jieba
def stopwordlist(filepath):
stopwords=[lines.strip() for lines in open(filepath,'r',encoding='utf-8')]
return stopwords重点分析第三行代码
1.1 文件对象是一个可迭代的。在for语句中,文件中的文本都是一句一句的取出的。所以这时read()和readlines()是没有分别的。
1.2 代码语句简洁高效。代码的格式和lambda函数很像,倒置的。代码用for语句将文件中每句句子都取出,并且去掉每句句子的左右两边的空格和特殊符号,将其作为元素放入list中,一行代码做三个动作。
1.3 str.strip()——删除字符串左右两侧的空格或特殊字符
str.lstrip()——删除字符串左边的空格或特殊字符
str.rstrip()——删除字符串右边的空格或特殊字符
ps:str是不可变的。故该函数返回的只是处理过的副本。原本的str对象没有发生改变。
函数括号中可以指定多个或单个要删除的指定字符,如果是空白则默认删除空格以及制表符、回车符、换行符等特殊字符。
def seg_sentence(sentence):
sentence_seged=jieba.cut(sentence.strip())
stopwords=stopwordlist(r'D:\停用词表\四川大学机器智能实验室停用词库(scu_stopwords).txt')
outstr=''
for word in sentence_seged:
if word not in stopwords:
if word!='\t':
outstr+=word
outstr+=' '
return outstr2.1 运用jieba库分词,返回一个可迭代类型。详见:jieba库-CSDN博客
2.2 停用词:指在自然语言文本中频繁出现但通常被忽略的常用词语。这些词语在文本中出现频率高,但通常对文本的语义贡献较小因此在一些文本处理任务中,如文本分类、信息检索等,可以被忽略或剔除,以减少处理的复杂性、提高处理效率和提取更有意义的词汇特征。
2.3 \t。制表符,相当于“table”键。
def Counter(Str):
List,c=[],[]
for i in Str:
if i != ' ':
List+=i
_List=set(List)
for item in _List:
num=List.count(item)
c.append(num)
Dict=zip(_List,c)
return Dict这里原本的帖子上的代码上没有,所以我只能自己写了,中间出现过不少的问题,通过查资料我弥补了我的一些知识漏洞。
本函数用于对文本中的部分词语(不是停用词的部分)进行计数
3.1 set函数。用于将原本list(括号中的list)中的不重复项选出,作为list返回。效果显示如下图。
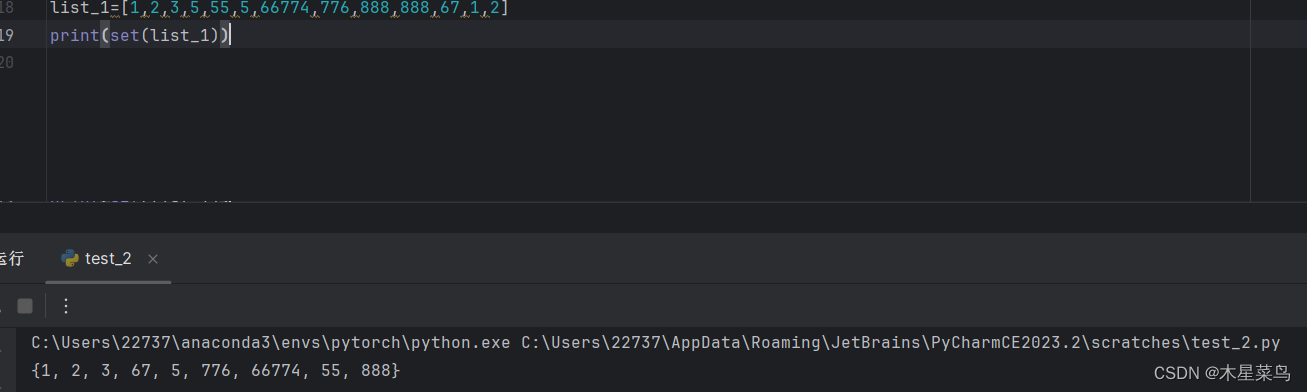
3.2 list.count(element)。该方法用于统计list中的与element相同的元素个数,返回一个int类型。
3.3 list.append(element)。该方法用于向list中追加element,就是按顺序向list中增加element。
3.4 zip()。压缩函数(我自己是这么喊的)。拿本代码中的zip()函数为例。该函数将_List与c这两个list压缩在了一起,其返回的zip类型(我查了zip(),返回的是元组,但是我用type()函数来看其返回值却是zip类型)其中的元素似乎是键值对的形式,因为可以转化为字典类型,值得注意的是,_List与c的元素的个数是一样,不然使用zip()时会报错。我认为键值对,其中键与值的配对也一定是两个list中的元素一一对应的。list也可换成其他可迭代类型。
inputs=open(r'D:\test\neg.txt','r',encoding='utf-8')
outputs=open(r'D:\test\output.txt','w',encoding='utf-8')
for line in inputs:
line_seg=seg_sentence(line)
outputs.write(line_seg)
else:
outputs.close()
inputs.close()
with open(r'D:\test\output.txt','r',encoding='utf-8') as f:
data=jieba.lcut(f.read())
data=dict(Counter(data))
with open(r'D:\test\cipin.txt','a',encoding='utf-8') as c:
for k,v in data.items():
c.write('%s,%d\n'%(k,v))
4.1 dict.items()。该方法用于将dict中的键值对取出,返回一个可迭代类型。在本代码中,k为键,v为值。
这就是全部的对于本次代码的分析,接下来看看整个代码的全貌吧。
import jieba
def stopwordlist(filepath):
stopwords=[lines.strip() for lines in open(filepath,'r',encoding='utf-8')]
return stopwords
def seg_sentence(sentence):
sentence_seged=jieba.cut(sentence.strip())
stopwords=stopwordlist(r'D:\停用词表\四川大学机器智能实验室停用词库(scu_stopwords).txt')
outstr=''
for word in sentence_seged:
if word not in stopwords:
if word!='\t':
outstr+=word
outstr+=' '
return outstr
def Counter(Str):
List,c=[],[]
for i in Str:
if i != ' ':
List+=i
_List=set(List)
for item in _List:
num=List.count(item)
c.append(num)
Dict=zip(_List,c)
return Dict
inputs=open(r'D:\test\neg.txt','r',encoding='utf-8')
outputs=open(r'D:\test\output.txt','w',encoding='utf-8')
for line in inputs:
line_seg=seg_sentence(line)
outputs.write(line_seg)
else:
outputs.close()
inputs.close()
with open(r'D:\test\output.txt','r',encoding='utf-8') as f:
data=jieba.lcut(f.read())
data=dict(Counter(data))
with open(r'D:\test\cipin.txt','a',encoding='utf-8') as c:
for k,v in data.items():
c.write('%s,%d\n'%(k,v))














 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









