






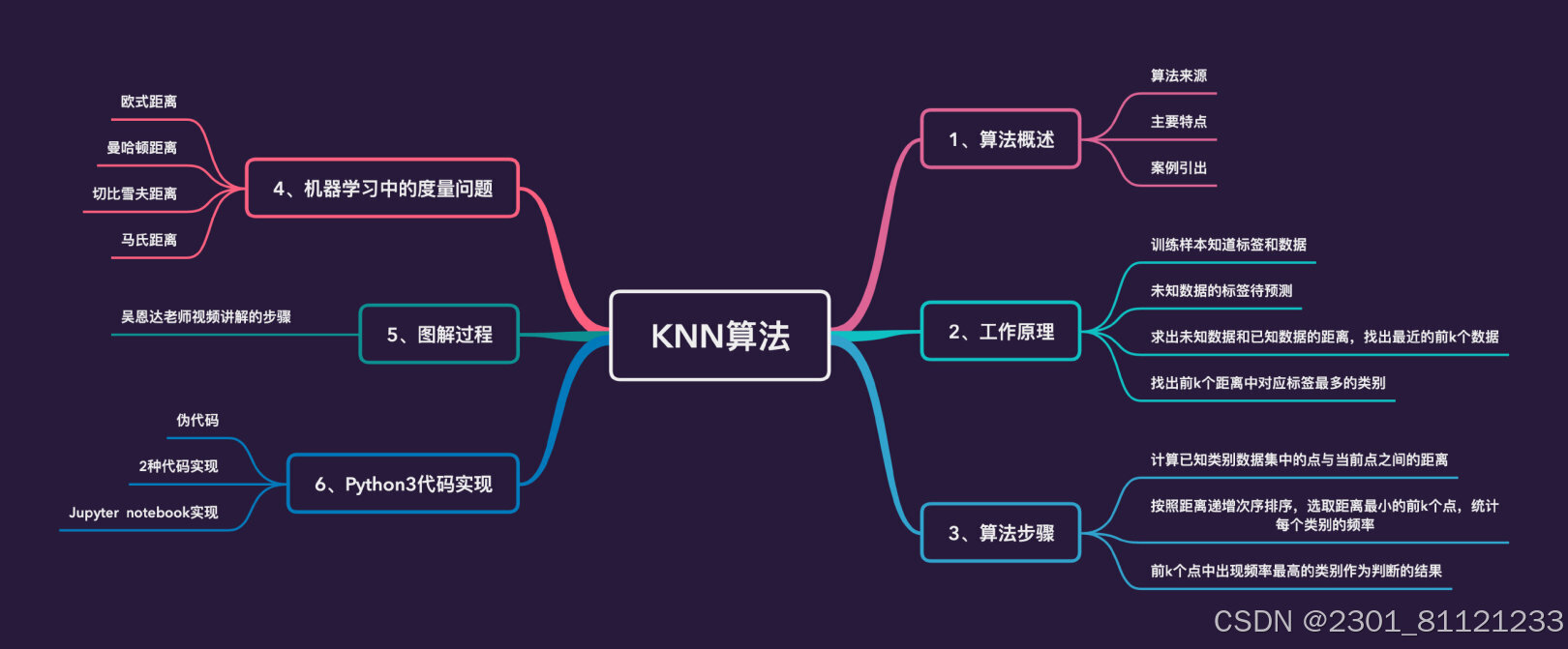
k-近邻算法(K-NearestNeighbors,简称KNN)是一种简单的基于实例的学习算法,它在机器学习领域中非常流行,特别是在分类问题上。KNN算法的基本思想是:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近的k个点)的训练样本的大多数属于某一个类别,则该样本也属于这个类别。

KNN算法的原理如下:
1.选择参数k:k是最近的邻居的数量,通常取一个较小的数值。k的选择对分类结果有很大影响,需要通过交叉验证等方法来确定。
2.计算距离:对于给定的测试样本,计算它与所有训练样本之间的距离。距离度量的方法可以是欧氏距离、曼哈顿距离、切比雪夫距离等。
3.查找最近的k个邻居:根据计算出的距离,找到与测试样本距离最近的k个训练样本。
4.投票分类:对于分类问题,k个邻居中有最多数的类别就是测试样本的预测分类。对于回归问题,则通常取所有邻居的输出值的平均作为预测值。
5.计算误差率:可以计算测试样本的实际分类和预测分类之间的差异,从而评估KNN模型的性能。
KNN算法的优点是简单易懂、容易实现,且无需对数据进行复杂的预处理,它可以处理多分类问题,也可以用于回归问题。然而,KNN算法的缺点也很明显:
-计算复杂度高:对于每个测试样本,都需要计算它与所有训练样本的距离,这在大型数据集上会非常耗时。
-内存消耗大:需要存储所有的训练样本,这对于大数据集来说可能不实用。
-选择k值困难:不同的k值可能导致不同的分类结果,需要通过交叉验证等方法来确定。
-计算距离的度量方法选择:不同的距离度量可能会影响分类结果,需要根据实际情况选择合适的度量方法。
KNN算法的实际应用非常广泛,包括但不限于:
-图像识别:KNN可以用于识别图像中的物体。
-文本分类:KNN可以用于将文本分类到不同的类别中,如垃圾邮件检测。
-生物信息学:KNN可以用于基因表达数据的分类和聚类。
-医学诊断:KNN可以用于疾病的诊断,如根据患者的症状和体检数据预测疾病类型。
-市场分析:KNN可以用于消费者行为分析,如根据消费者的购买历史预测其未来可能购买的商品。
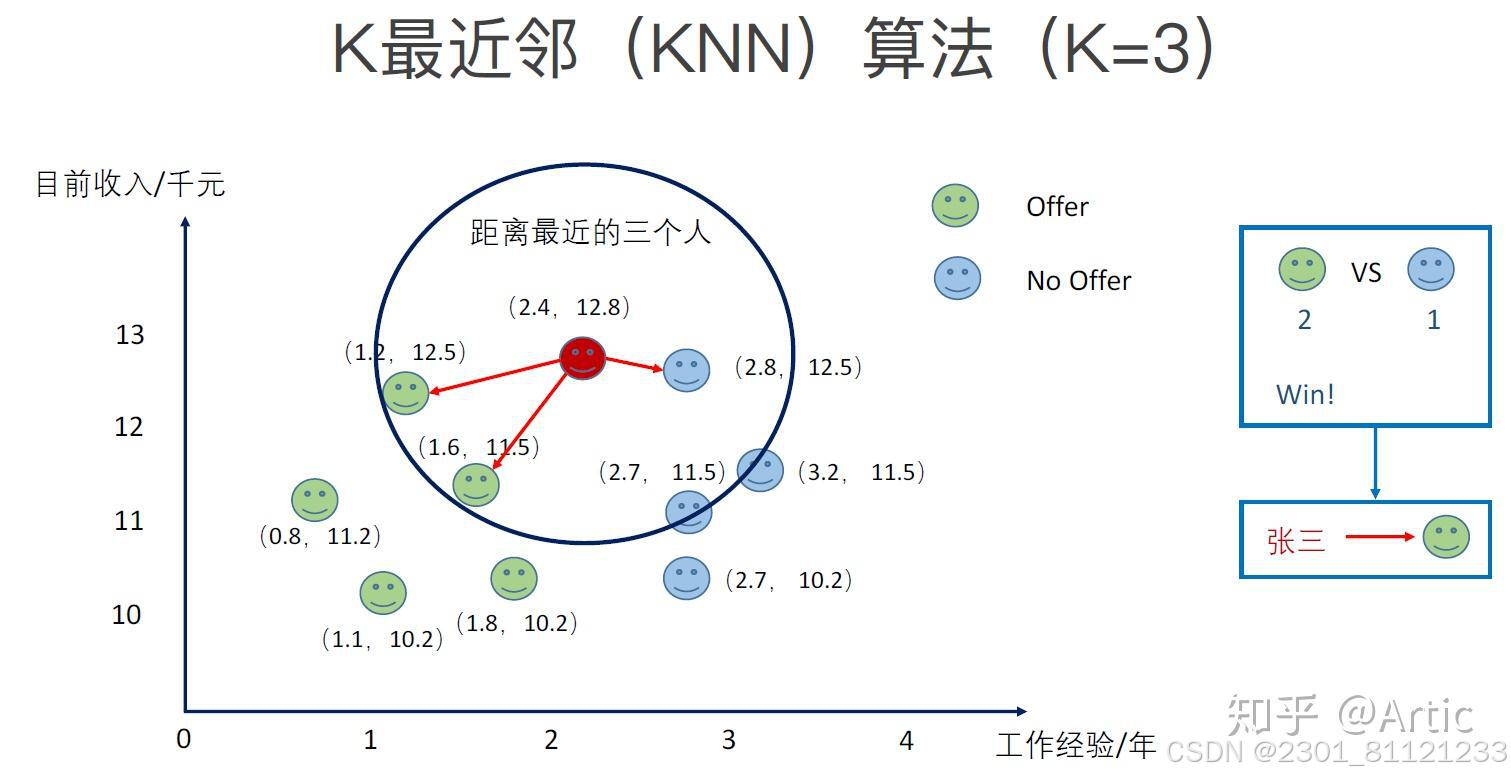
k近邻算法是一种基本的分类和回归算法。其原理是根据已知的训练样本集,对新的输入实例,通过计算其与训练样本集中每个实例的距离,选取k个距离最近的实例,根据这些实例的类别(分类问题)或平均值(回归问题),来预测新实例的类别或取值。
k近邻算法的实现步骤如下:
1. 计算新实例与训练样本集中每个实例的距离;
2. 选取距离最近的k个实例;
3. 对于分类问题,根据k个实例的类别进行投票,选择得票最多的类别作为新实例的类别;
4. 对于回归问题,根据k个实例的取值求平均值作为新实例的预测值。
k近邻算法的实际应用非常广泛,包括但不限于以下领域:
1. 个性化推荐系统:根据用户的历史行为和喜好,通过找到相似用户或相似物品,为用户推荐感兴趣的内容;
2. 文本分类:根据已有的文本类别信息和新的文本内容,判断新的文本属于哪个类别;
3. 图像识别:根据已有的图像库,对新的图像进行分类或识别;
4. 医学诊断:根据患者的症状和已有的病例信息,判断患者可能患有的疾病;
5. 金融风险评估:根据客户的历史数据和行为,对新的风险进行预测和评估。

总的来说,k近邻算法适用于各种需要根据相似性进行分类、回归和预测的场景,具有简单、直观且易于实现的特点。但是在处理大规模数据时,由于需要计算距离,算法效率较低。此外,k近邻算法对于样本分布不平衡和噪声敏感,需要进行适当的数据预处理和参数调优。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









