






目录
1.环境需求以及需要的包
1、vmware环境pro17
2、虚拟光盘CentOS-7.5-x86_64-DVD-1804.iso
3、jdk-8u212-linux-x64.tar
4、hadoop-3.1.3.tar
2.虚拟机的初步配置
在新建虚拟环境时大多数都选下一步就行,以下小部分可以按我下面的步骤进行
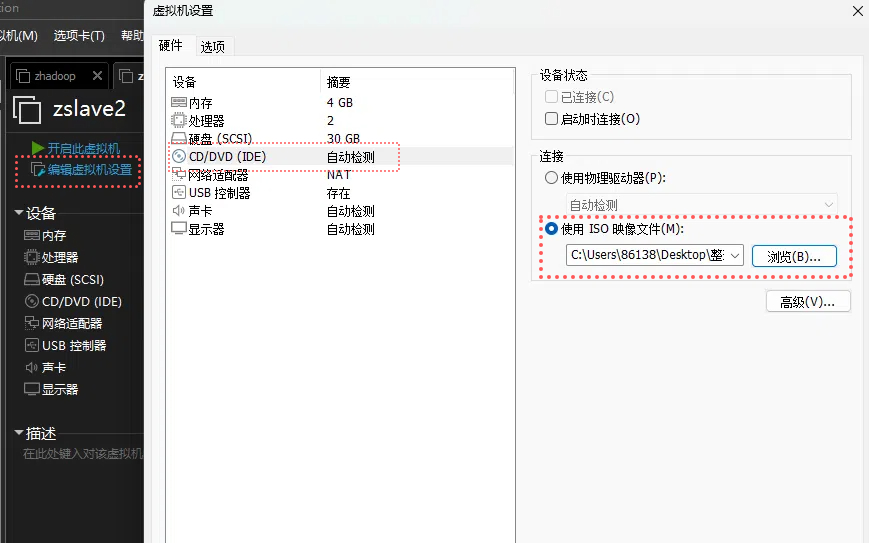
在选择虚拟机存储位置时可以设立一个专门的文件夹方便管理。(也就是下图的位置(L)那)
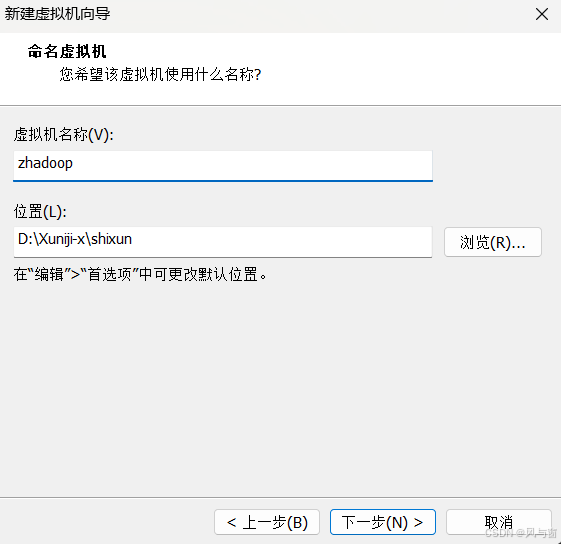
同时之后的磁盘文件也放同一个位置方便管理
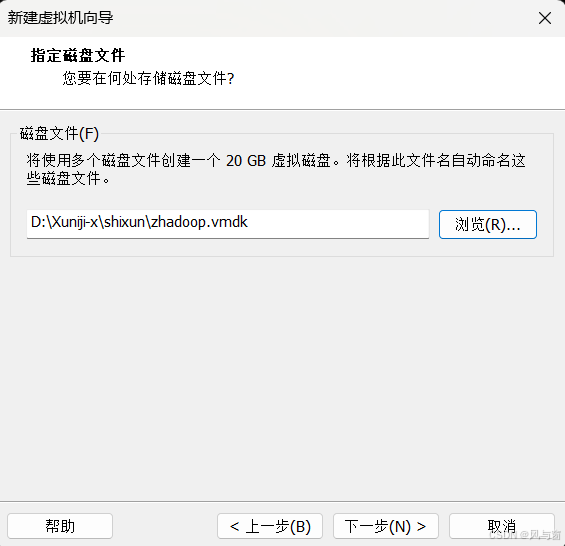
这里的处理器数量可以选1或者2(过多要考虑硬件以及可能影响速率),处理器内核数量2加快处理能力
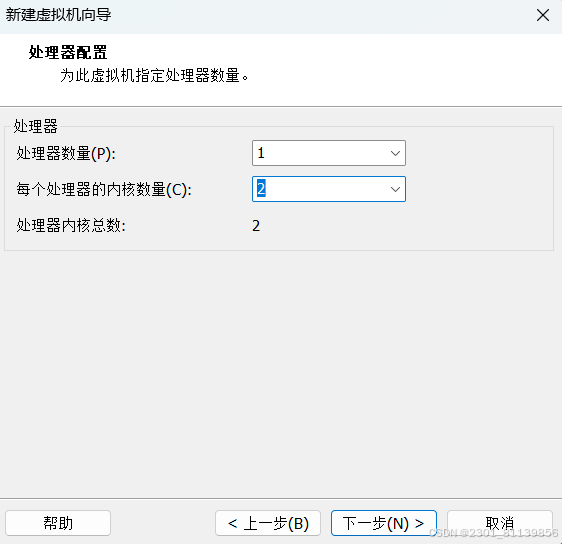
选4gb提高效率,要考虑自身电脑的内存大小,确保能同时启动三个虚拟机也就是要有3×4=12的内存大小如果没有就看情况减小
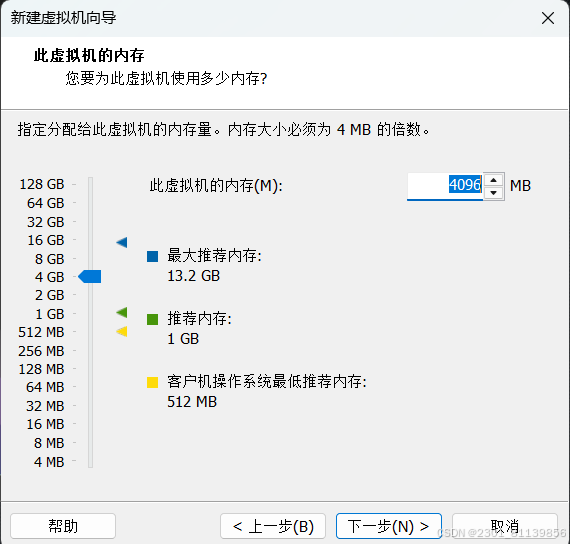
同理要确保自身电脑有4个30g也就是120g的硬盘空间,30gb磁盘才够用
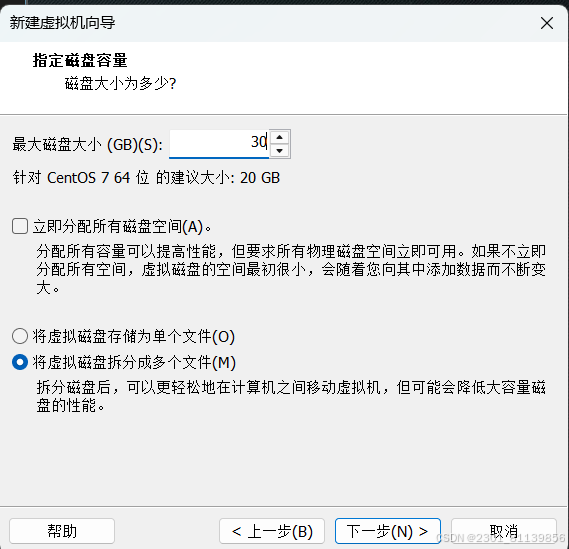
创建后虚拟机的构建读条那里等它读完就好,也不用管
3.虚拟机环境准备
ping www.baidu.com查看能不能通网
如果不行可以参考
虚拟机网络配置教程,ping不通的几种原因及解决办法_ping不通虚拟机ip地址的原因-CSDN博客
进入管理员模式方便操作
Extra Packages for Enterprise Linux(epel)是为“红帽系”的操作系统提供额外的软件包,适用于RHEL、CentOS和Scientific Linux。相当于是一个软件仓库
如果安装的linux是最小系统版还要安装net-tools以及vim,安装桌面版的不用再安装。(按上面配置虚拟机步骤的就默认是桌面版)
yum install -y epel-release时出现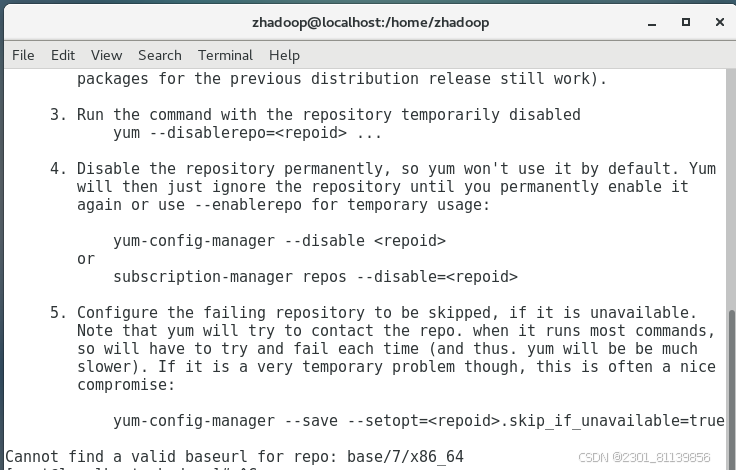
关闭防火墙以及防火墙开机自启
systemctl stop firewalld
systemctl disable firewalld.service

建立新用户(看情况选做,毕竟建虚拟机就自带用户,也就是虚拟机开启要输密码时头像下面那个用户名)
增加用户名和密码
useradd 用户名
passwd 用户名i进入修改 Esc退出修改模式 :wq! 强制保存退出
vim /etc/sudoers使普通用户有root权限使后续操作简单点
找到
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
在下面加上
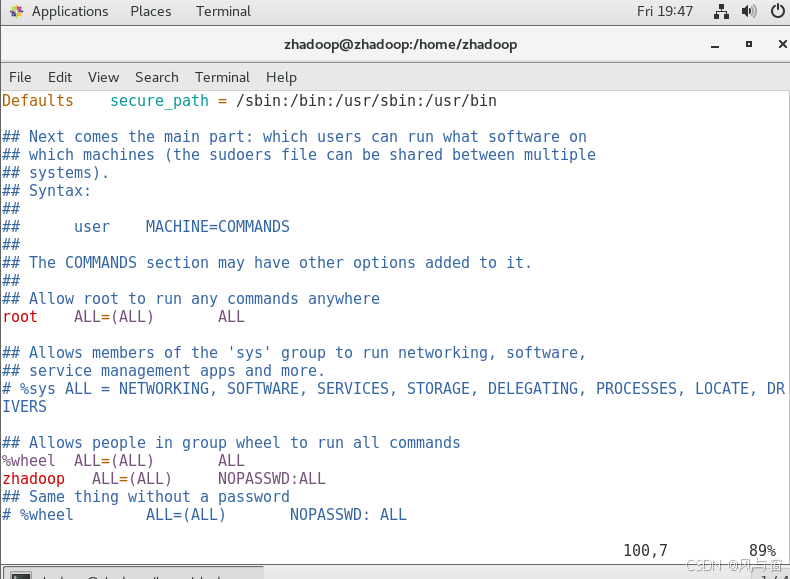
注意更改“用户名”为虚拟机开启要输密码时头像下面那个用户名,又或者你新建的用户名
下面步骤的“用户名”同理
创建用于管理解压的包以及设定包的用户组
mkdir /opt/module
mkdir /opt/software
chown 用户名:用户名 /opt/module
chown 用户名:用户名 /opt/softwarecd/opt
ll查看用户组

卸载虚拟机自带的jdk然后重启
rpm -qa | grep -i java | xargs -n1 rpm -e --nodepsreboot4.克隆虚拟机
以下是虚拟机的锁屏后不需要重新输密码以及不黑屏的教程(可选做毕竟后两步就直接用xshell了)
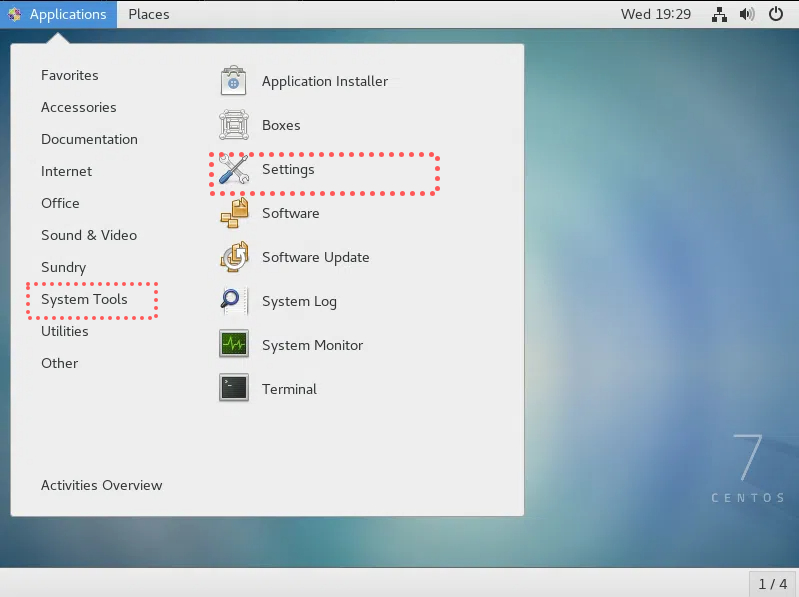
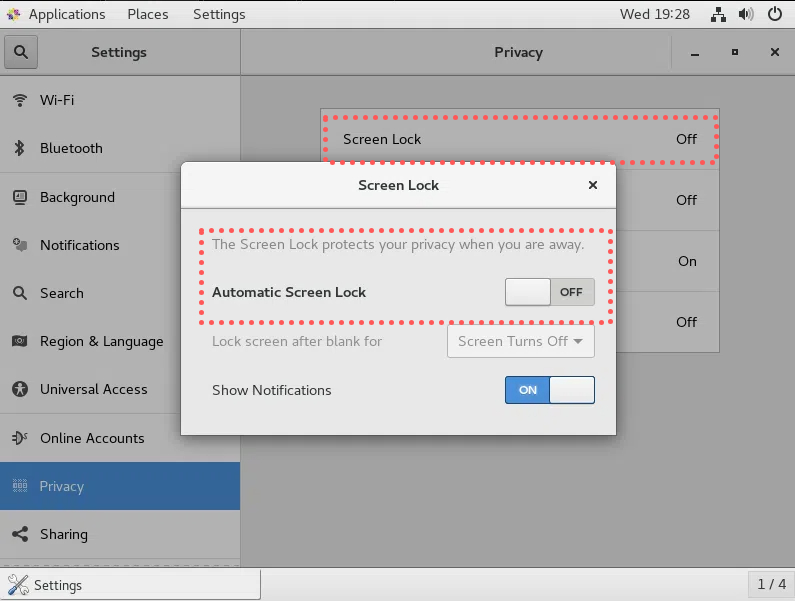
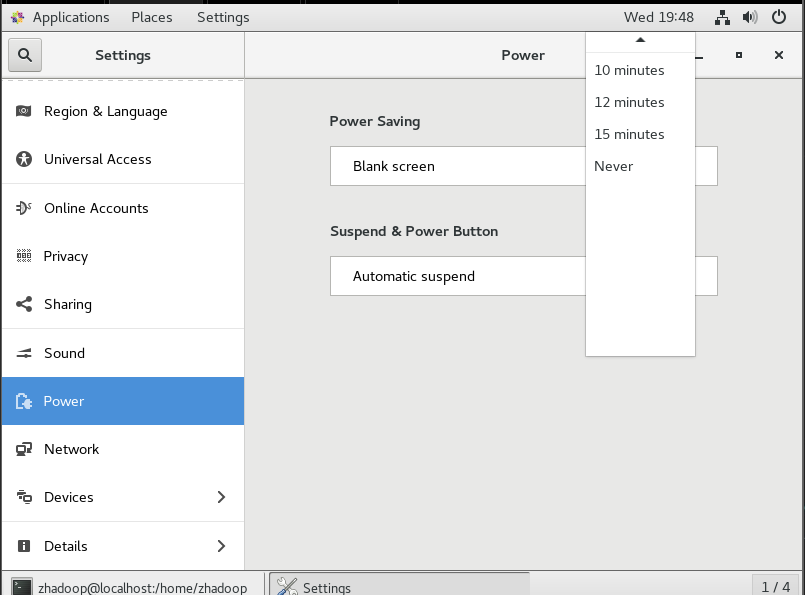
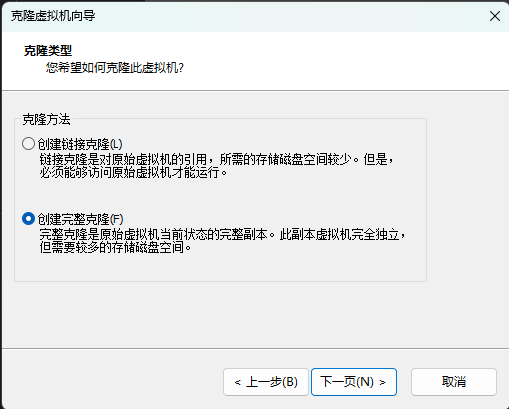
关闭第一台虚拟机后克隆三台虚拟机
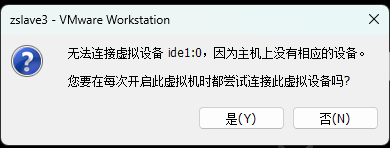
5.ip地址配置
修改虚拟机的ip(四台虚拟机都要配置)
vim /etc/sysconfig/network-scripts/ifcfg-ens33直接把里面内容删了然后修改代码(注意每台虚拟机的IPADDR都要不同也就是
master机可以是192.168.128.100
slave1机可以是192.168.128.101,以此类推)
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.128.101
PREFIX=24
GATEWAY=192.168.128.2
DNS1=192.168.128.2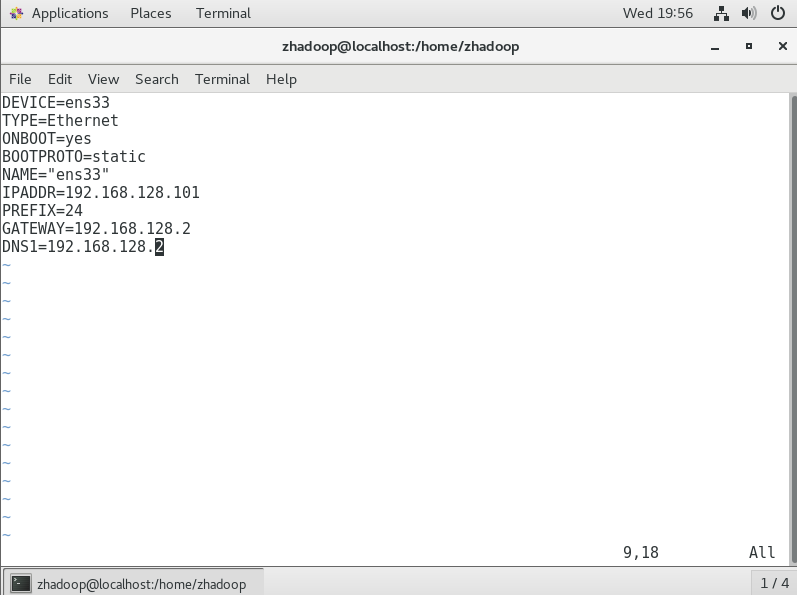
在控制面版中找到查看网络状态和任务->更改适配器设置->找到VMnet8然后右键属性
如果找不到vmnet8可以参考
主机上没有虚拟机网络适配器VMnet8解决办法_主机没有vmnet8网卡-CSDN博客
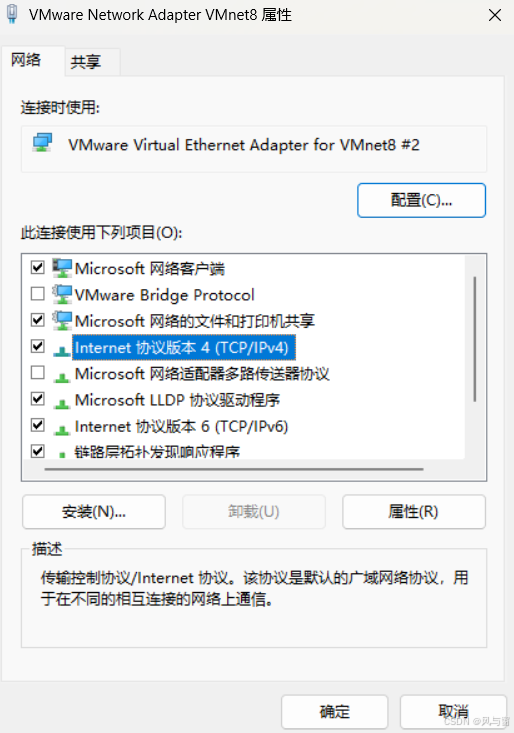
双击图上蓝色的位置修改成以下
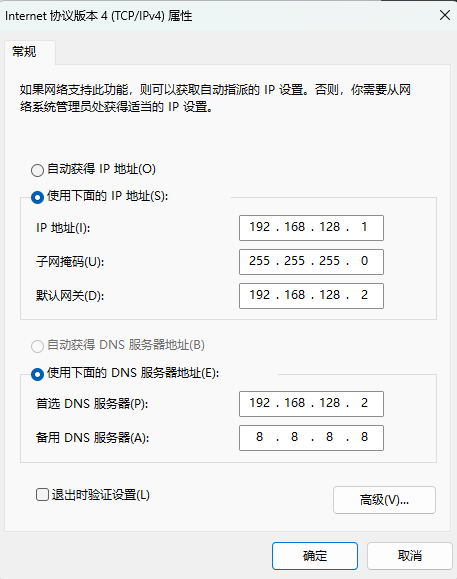
之后配置Linux虚拟机的虚拟网络编辑器,在虚拟机启动器那里左上角编辑(E)->虚拟网络编辑器
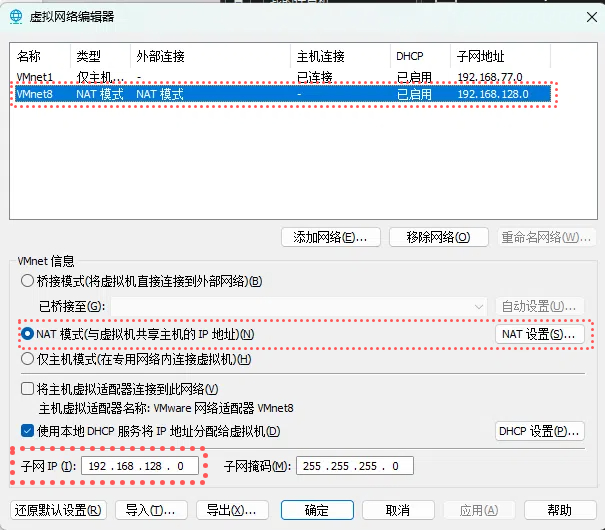
子网ip设定成192.168.128.0
下面的网关ip设定成和上面gateway设定的一样也就是192.168.128.2
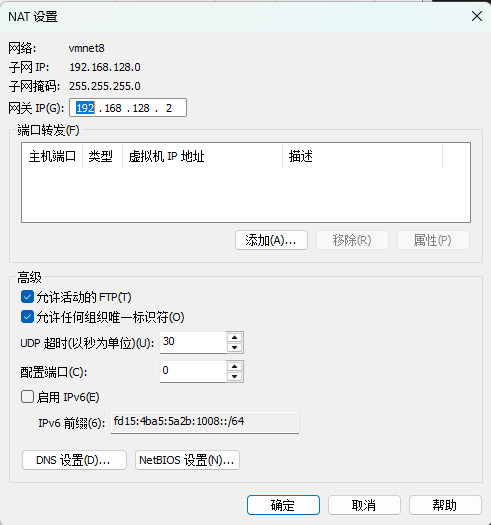
确保Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
修改主机名称以下以slave1进行示范(每台虚拟机都要修改且确保配置的名称对应上ip)
vim /etc/hostname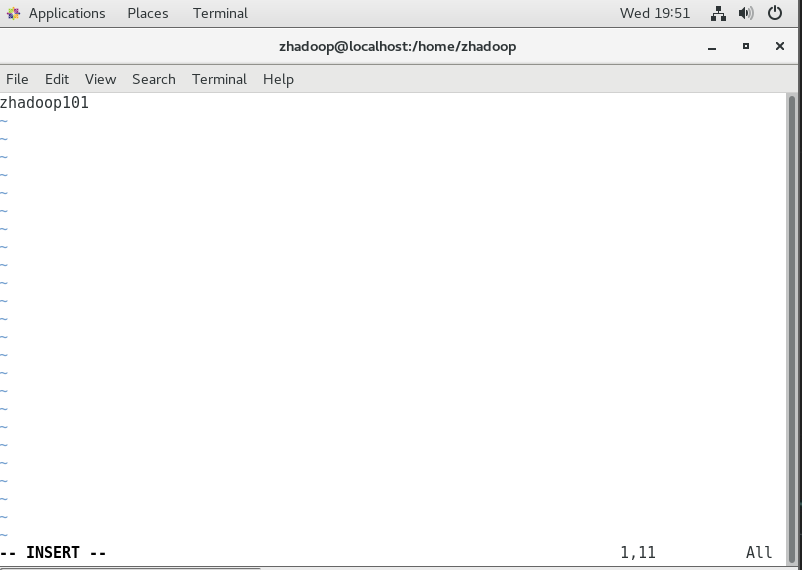
修改主机映射文件hosts
vim /etc/hosts在下面加入以下代码
192.168.128.100 zhadoop100
192.168.128.101 zhadoop101
192.168.128.102 zhadoop102
192.168.128.103 zhadoop103
192.168.128.104 zhadoop104
192.168.128.105 zhadoop105
192.168.128.106 zhadoop106
192.168.128.107 zhadoop107
192.168.128.108 zhadoop108
重启虚拟机
reboot到电脑路径C:\Windows\System32\drivers\etc
打开hosts文件并添加如下内容,然后保存
如果修改不了可以拖到桌面修改了再拖回去
192.168.128.100 zhadoop100
192.168.128.101 zhadoop101
192.168.128.102 zhadoop102
192.168.128.103 zhadoop103
192.168.128.104 zhadoop104
192.168.128.105 zhadoop105
192.168.128.106 zhadoop106
192.168.128.107 zhadoop107
192.168.128.108 zhadoop1086.xhell配置
名称可以按需求(随便)来起
主机需要确保对应你需要启动的虚拟机的ip地址又或者对应的hostname
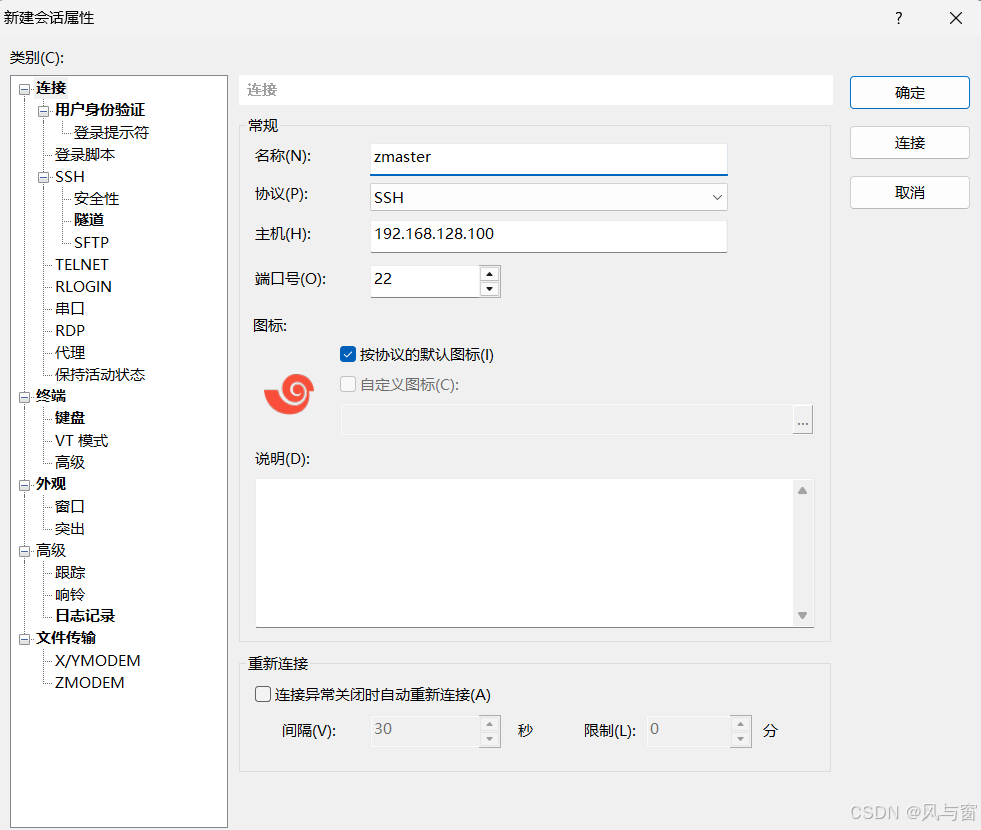
这里是虚拟机按密码进入桌面那个用户
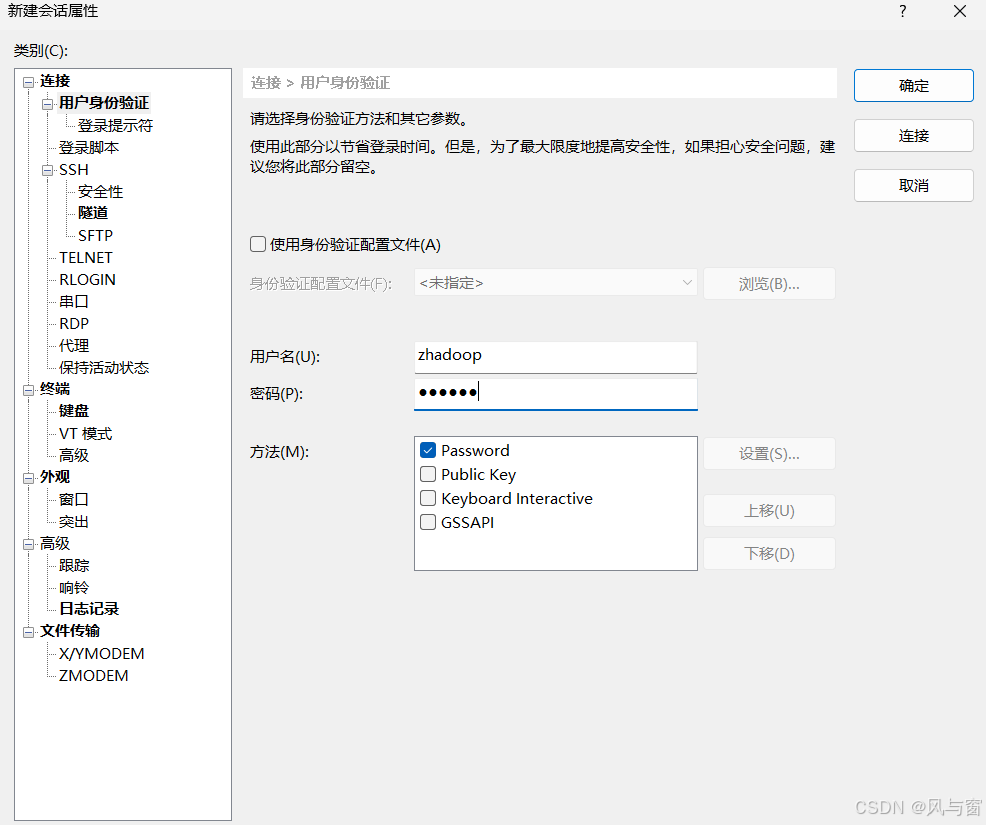
连不上就代表你ip地址没有对上,回去一步步检查
注意观察192.168.128.100的数字有没有对上
1、
vim /etc/sysconfig/network-scripts/ifcfg-ens33的ip地址
2、Linux虚拟机的虚拟网络编辑器的配置的ip
3、Windows系统适配器VMware Network Adapter VMnet8的IP地址
4、
vim /etc/hostname的hostname是否对应
5、
vim /etc/hosts里映射文件是否对应
6、以及电脑里的C:\Windows\System32\drivers\etc下的host文件是否对应
7.jdk和hadoop包的解压
按1修改2路径
然后把需要的包从你的电脑拖到虚拟机里(也就是左拖到右)
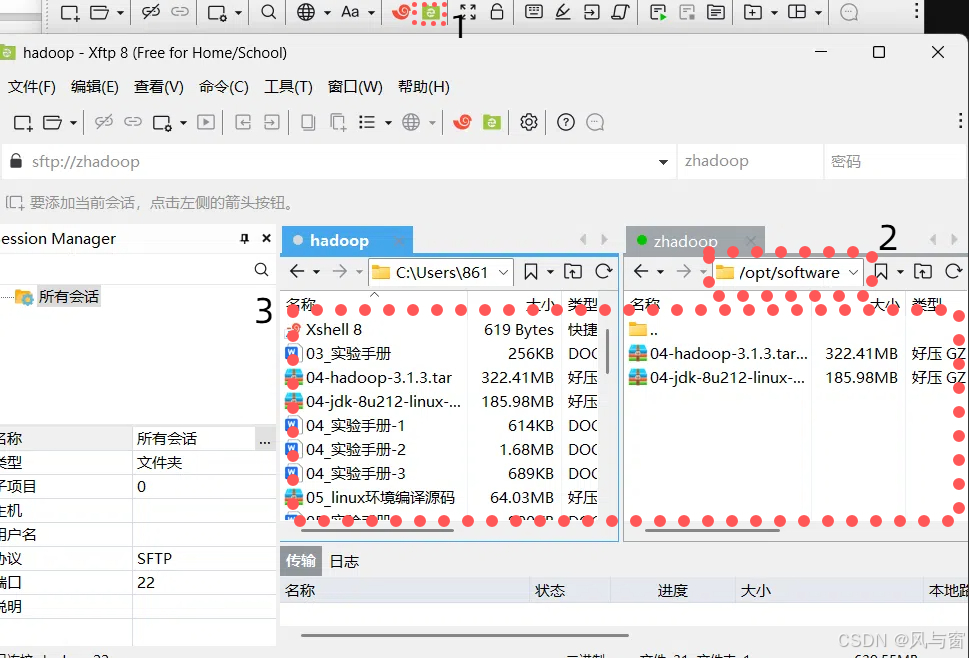
查看是否 复制成功
ls /opt/software/然后解压包
tar -zxvf 包名 -C /opt/module/配置jdk环境变量
sudo vim /etc/profile.d/my_env.sh加入以下代码:wq保存退出
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/binsource一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile查看是否解压成功
java -versioncd到解压的hadoop包里
sudo vim /etc/profile.d/my_env.sh加入以下代码:wq保存退出
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.6.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profilehadoop version8.hadoop的本地运行
hadoop本地运行(单机,也就是在1台虚拟机中就可以做)进行hadoop演示
cd到解压的hadoop包
mkdir wcinput
cd wcinput编辑word.txt文件
vim word.txt加入以下 (注意修改“用户名”为你配置了环境的用户名)
hadoop yarn
hadoop mapreduce
用户名
用户名返回上一级的文件夹也就是hadoop包
cd ..执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput查看是否执行成功
cat wcoutput/part-r-00000成功了会看到结果
用户名 2
hadoop 2
mapreduce 1
yarn 1
9.ssh无密登录配置
完成这个配置可以使之后虚拟机之间的互动不需要反复输入密码
首先随便选择1台虚拟机进行操作我选择slave2
连接slave3
ssh zhadoop103出现让你确认是否连接的填yes然后回车再输入密码
接着退出
exit上面的步骤是确保该虚拟机生成了.ssh文件夹
cd到.ssh生成公钥与私钥
ssh-keygen -t rsa接着按下三个回车生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到需要免密登录的机器上
ssh-copy-id zhadoop100
ssh-copy-id zhadoop101
ssh-copy-id zhadoop102
ssh-copy-id zhadoop103生成公钥与私钥的步骤需要在master和slave1、2、3用户名账号都要分别对需要免密的账号进行操作
10.xsync集群分发脚本
把用户名用户的/opt/module/jdk1.8.0_212分发(拷贝)给hadoop103用户的/opt/moudle里
scp -r /opt/module/jdk1.8.0_212 用户名@hadoop103:/opt/module可以连接到另一个虚拟机进行删除操作
rm -rf wcinput拷贝文件到slave3
rsync -av hadoop-3.1.3/ 用户名@hadoop103:/opt/module/hadoop-2.6.4/xsync集群分发脚本配置
cd /home/用户名
mkdir bin
cd bin
vim xsync添加以下的代码注意改for host in 的用户名名字
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in zhadoop101 zhadoop102 zhadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done修改执行权限
chmod +x xsync测试脚本
xsync /home/用户名/bin脚本复制到bin中 方便全局调用
sudo cp xsync /bin/同步环境变量
sudo ./bin/xsync /etc/profile.d/my_env.sh在slave1和slave3里
source /etc/profile一键ssh脚本配置
cd到bin
vim jpsall#!/bin/bash
for host in zhadoop100 zhadoop101 zhadoop102 zhadoop103
do
echo =============== $host ===============
ssh $host jps
done
修改权限
chmod +x jpsall测试
jpsall一键启动hadoop集群脚本
vim myhadoop#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/mr-jobhistory-daemon.sh start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/mr-jobhistory-daemon.sh stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh zhadoop100 "/opt/module/hadoop-2.6.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
chmod +x myhadoop11.集群配置
配置核心文件
cd $HADOOP_HOME/etc/hadoop修改core-site.xml
vim core-site.xml<configuration>中加入
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://zhadoop101:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.6.4/logs</value>
</property>
</configuration>修改hadoop-env.sh
vim hadoop-env.shexport JAVA_HOME=/opt/module/jdk1.8.0_212
修改yarn-env.sh
vim yarn-env.sh# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/opt/module/jdk1.8.0_212
修改mapred-site.xml
vim mapred-site.xml<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>zhadoop102:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>zhadoop102:19888</value>
</property>
</configuration>
修改yarn-site.xml
vim yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zhadoop102</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.resourcemanager.local-dirs</name>
<value>/opt/module/hadoop-2.6.4/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/module/hadoop-2.6.4/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://zhadoop102:19888/jobhistory/logs</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
修改hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/module/hadoop-2.6.4/data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/module/hadoop-2.6.4/data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>zhadoop103:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
修改hive-site.xml
vim hive-site.xml <?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://zhadoop101:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.PersistenceManagerFactoryClass</name>
<value>org.datanucleus.api.jdo.JDOPersistenceManagerFactory</value>
</property>
<property>
<name>javax.jdo.option.NonTransactionalRead</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.Multithreaded</name>
<value>true</value>
</property>
<property>
<name>datanucleus.connectionPoolingType</name>
<value>BoneCP</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>zhadoop104</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://zadoop101:9083</value>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-1.2.1.war</value>
</property>
</configuration>
集群分发
xsync /opt/module/hadoop-2.6.4/etc/hadoop
到被分发的机上验证
cat /opt/module/hadoop-2.6.4/etc/hadoop/core-site.xml配置workers
vim /opt/module/hadoop-2.6.4/etc/hadoop/slaves分发配置
xsync /opt/module/hadoop-2.6.4/etc
12.启动集群

如果集群是第一次启动需要在zhadoop102格式化namenode,格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。
hdfs namenode -format在启动hdfs(我是配置在zhadoop101)
hadoop目录下
sbin/start-dfs.sh102下启动yarn
sbin/start-yarn.shjps查看所有的集群是否正常启动
上传小文件到集群
集群中创建文件夹
hadoop fs -mkdir /input上传文件
hadoop fs -put 文件路径以及文件名cd到上面配置的文件存储地方可以看到有文件存储进去了
下载文件
hadoop fs -get /路径及文件名 下载到的路径13、常用脚本
hadoop集群启停脚本
cd /home/用户名/bin
vim myhadoop.sh注意先修改下面应该修改的名字(也就是hadoop名)再粘贴
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac增加权限
chmod +x myhadoop.sh2、查看三台服务器的脚本
cd /home/用户名/binvim jpsall#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
donechmod +x jpsall

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









