






1.数组名的理解
在使用指针访问数组的内容时有如下的代码:
1 int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
2 int* p = &arr[0];
这里使用&arr[0]的方式得到是数组的首元素的地址(即数组第一个元素的地址),但是数组名arr本身就是首元素地址。
我们来测试一下:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0]=%p\n", &arr[0]);
printf("arr=%p\n", arr);
printf("&arr=%p\n", &arr);
return 0;
}
结果为:

显然上面打印的地址一模一样,所以数组名就是首元素(数组第一个元素地址)的地址。
但是,也有特殊的情况,如下:
1 int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
2 printf("%d", sizeof(arr));
按道理,这里输出结果应该是4,但实际输出结果是40。这就数组名不是首元素地址的特例之一。
仅有两个特列(它们都表示整个数组),如下:
- sizeof(数组名),这里表示的是整个数组,计算的是整个数组的大小,单位是字节。
- &数组名,这里也表示整个数组,取出的是整个数组的地址(虽然打印的地址是一样的,但是整个数组的地址和首个元素的地址本质上是有区别的)。
那么arr与&arr有什么区别呢?看下面代码:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0]=%p\n", &arr[0]);
printf("arr =%p\n", arr);
printf("&arr =%p\n", &arr);
printf("\n");
printf("&arr[0]+1=%p\n", &arr[0]+1);
printf("arr+1 =%p\n", arr+1);
printf("&arr+1 =%p\n", &arr+1);
return 0;
}
输出结果:
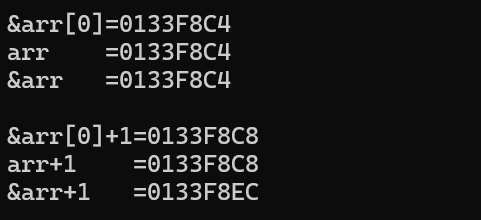
通过输出结果,可以发现以下几点:
3. 打印&arr[0]、arr、&arr的地址都一样。
4. &arr[0]和&arr[0]+1相差4个字节,arr和arr+1也相差4个字节,这是因为&arr[0]和arr都是数组首元素地址。
5. &arr和&arr+1(或&arr[0]+1)相差40个字节,这是因为&arr取的是整个数组的地址,而+1操作就是跳过整个数组(即跳过40个字节)。
补充:
看一下这段代码:思考一下arr,arr[0],&arr[0],&arr的类型是什么?
int main()
{
int arr[10] = {0};
return 0;
}
- arr的类型是
int[10] - arr[0]的类型是
int - &arr[0]的类型是
int* - &arr的类型是
int (*)[10]
2.使用指针访问数组
看下面这两段代码:
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
int i = 0;
//输入
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
int i = 0;
//输入
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
}
//输出
for (i = 0; i < sz; i++)
{
printf("%d ", p[i]);
}
return 0;
}
由这两段代码的输出结果可以看出,*(p+i)和p[i]本质上是等价的。
3.一维数组传参的本质
数组是可以传递给函数的,下面我们来讨论一下一维数组传参的本质。
void test(int arr[])
{
int sz2 = sizeof(arr) / sizeof(arr[0]);
printf("sz2=%d\n",sz2);
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("sz1=%d\n", sz1);
test(arr);
return 0;
}
输出结果:

由输出结果发现,在将数组转递给函数是没有正确得到数组大小。
原因:一维数组传参的本质。上面讲到数组名是首元素地址,那么在数组传参的时候,本质上是传递数组首元素地址,所以输出上述结果。
所以函数形参理论上使用指针变量来接受数组首元素地址。那么我们在函数内部使用sizeof(arr)实际计算的是一个地址的大小,而不是整个数组大小。
再分析一下下面的代码:
void test(int* arr)
{
int sz2 = sizeof(arr) / sizeof(arr[0]);
printf("sz2=%d\n", sz2);
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("sz1=%d\n", sz1);
test(arr);
return 0;
}
总结:
- 一维数组传参的本质是传递数组首元素地址给函数,因此不能在函数内部计算数组大小。
- 一维数组传参,形参部分可以写成数组形式,也可以写成指针形式。
4.二级指针
指针变量存放变量的地址,而指针也是变量,那指针变量的地址存放在哪?
答案是:二级指针。
二级指针变量存放的是一级指针的地址。
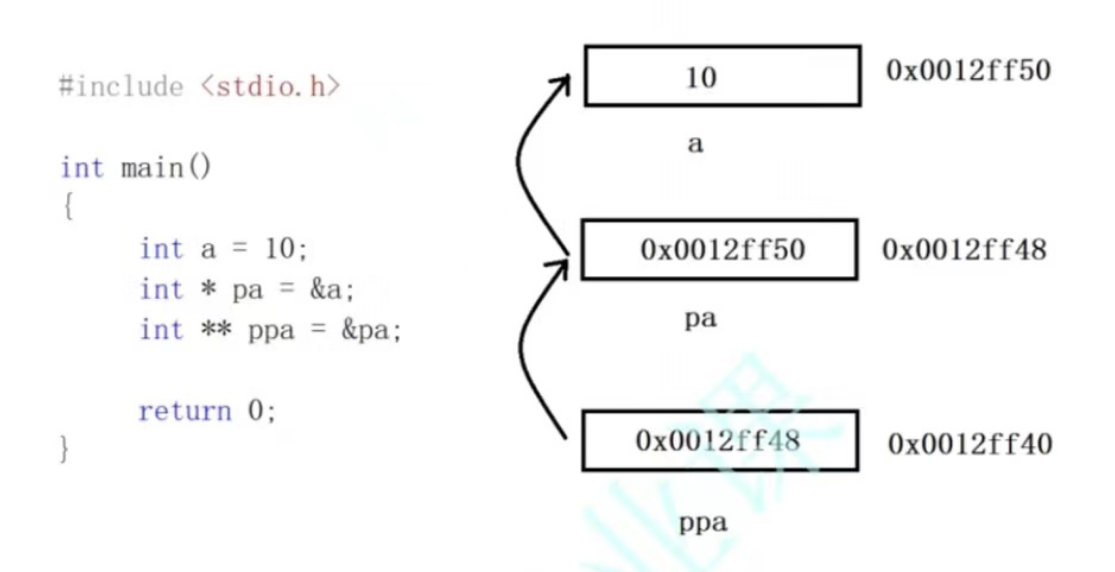
那么二级指针有什么用呢?当我们找不到一级指针时可以利用二级指针来找到一级指针。
二级指针的运算:
- *ppa访问的是pa(即一级指针的地址)。
- **ppa访问的是a(即一级指针指向的内容)。
int main()
{
int a = 30;
int* pa = &a;
int** ppa = &pa;
printf("%p\n", pa);
printf("%p\n", ppa);
printf("%p\n", *ppa);
printf("%d\n", **ppa);
return 0;
}

5.指针数组
类比一下,整型数组存放的每个元素都是整形,字符数组存放的每个元素都是字符。那么指针数组存放的每个元素都是什么?答案是:指针。
类型:
- 整形指针数组
int*arr[] - 字符指针数组:
char*arr[] - 浮点型指针数组:
float*arr[] - 等等…
数组存放在一段连续的空间,而指针数组的元素又指向一块空间。
6.指针数组模拟二维数组
int main()
{
int arr1[] = { 1,2,3,4 };
int arr2[] = { 2,3,4,5 };
int arr3[] = { 3,4,5,6 };
int*parr[3] = { arr1,arr2,arr3 };
int i = 0;
for (i = 0; i < 3; i++)
{
int j = 0;
for (j = 0; j < 3; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}
parr是数组首元素地址,parr[1]得到的是数组arr2的首元素地址,parr[i][j]得到的是一维数组中的元素。
7.冒泡排序
冒泡排序的核心思想:相邻两个元素进行比较。排序后的结果是升序。
使用条件:
- 数据数量少,如果数据量太大效率会很低。
- 数据已部分有序,有序的数据冒泡排序的效率会提高。
void bubble_sort(int arr[],int sz)
{
int i = 0;
//外层循环控制冒泡排序趟数
for (i = 0; i < sz-1; i++)
{
int j = 0;
int flag = 1;//假设某一趟有序
//内层循环控制每一趟比较次数
for (j = 0; j < sz - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
int temp = arr[j + 1];
arr[j + 1] = arr[j];
arr[j] = temp;
flag = 0;
}
}
if (1 == flag)
{
break;
}
}
}
int main()
{
int arr[10] = { 2,5,4,7,8,1,3,9,10,6 };
int sz = sizeof(arr) / sizeof(arr[0]);
bubble_sort(arr,sz);
int i = 0;
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
解析一下:上面这一段代码,变量flag作用是为了提高排序效率;当某一趟内层循环没有相邻元素互换位置时,就表明整个序列已经时升序了。
感谢你做我清淡岁月里最耀眼的星辰人潮汹涌。
天青色等烟雨,而我在等你的关注。














 1730
1730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









