






目录
(一)主成分分析中第一个主成分、第二个主成分、第三个主成分......有顺序关系吗,它们的位置是随便乱排的吗?
(二)每个主成分是原始数据各个特征的线性组合对不对,或者说主成分荷载矩阵是不是每个主成分对应的各个特征的线性系数?
(四)进行主成分分析之前进行数据标准化/归一化,还是主成分分析之后?或者主成分分析之前之后都需要进行数据标准化/归一化?
一、PCA的步骤
主成分分析(PCA, Principal Component Analysis)是一种常用的数据降维技术,旨在将一组可能相关的变量转换为一组线性不相关的变量,称为主成分,同时尽可能多地保留原始数据集的信息。以下是PCA的主要步骤:
1. 数据标准化:
由于PCA对变量的尺度敏感,首先需要对数据进行标准化处理,通常通过减去均值并除以标准差完成,确保每个变量具有单位方差,从而使它们处于相同尺度上。
2. 计算协方差矩阵:
对于中心化后的数据,计算其协方差矩阵。协方差矩阵描述了各变量间的相互关系,对角线上的元素是各变量的方差,非对角线元素是变量间的协方差。
3. 计算特征值和特征向量:
解决协方差矩阵的特征值问题。特征值代表了数据在各个新坐标轴上的方差大小,而对应的特征向量则指明了新坐标轴的方向。通常使用特征分解或奇异值分解(SVD)方法获得这些值。
4. 选择主成分:
按特征值大小排序,选择前k个最大的特征值对应的特征向量。这些特征向量定义了新的坐标系,其中前k个坐标轴(即主成分)包含了原始数据最多的信息。k的选择可以通过解释总方差的百分比来确定,比如选择能够解释95%方差的主成分数。
5. 数据转换:
将原始数据投影到由选定的主成分定义的新空间中。这一步是通过计算原始数据与选定特征向量的乘积实现的,得到的是降维后的数据表示。
6. 结果解释与可视化:
降维后的数据可以用于后续的分析或可视化。主成分往往具有一定的解释意义,有助于理解数据的主要结构和模式。
7. 重构数据(如果需要):
使用降维后的数据和主成分,可以尝试重构原始数据的近似版本,以便评估信息损失情况。
通过上述步骤,PCA不仅能够降低数据的维度,简化模型复杂度,提高计算效率,还能去除噪声,突出数据的主要特
二、PCA的作用
PCA 的主要应用包括:
降维:PCA 可以用于减少数据的维度,去除数据中的冗余信息,提高数据的计算效率,并有助于可视化数据。
特征提取:PCA 可以用于提取数据中的主要特征,减少特征的数量,同时保留数据的重要信息。
去噪:PCA 可以用于去除数据中的噪声,提高数据的质量。
可视化:PCA 可以用于将高维数据映射到低维空间,以便更容易可视化和理解数据。
三、PCA参数介绍
pca = PCA(n_components=None,copy=True,whiten=False,svd_solver="auto",
tol=0.0,iterated_power="auto",random_state=None)这些参数描述了在使用主成分分析(PCA)算法时可以调整的一些选项,以下是对每个参数的详细解释:
1. `n_components`(主成分数量):
* 描述:决定PCA算法应该保留的主成分数量。
* 默认值:`None`,即保留所有主成分。
* 其他选项:
* 整数k:保留前k个主成分。
* 小数:表示保留的主成分的方差百分比。
* 作用:通过选择适当的主成分数量,可以实现数据的降维,减少数据的维度,同时保留最重要的特征信息。
2. `copy`(复制数据):
* 描述:决定是否在运行PCA算法之前复制输入数据。
* 默认值:`True`,即复制数据,以免修改原始数据。
* 其他选项:`False`,直接在原始数据上进行计算。
* 作用:通常建议保留为默认值,以确保不会意外修改原始数据。
3. `whiten`(白化处理):
* 描述:决定是否对数据进行白化处理。
* 默认值:`False`,即不进行白化处理。
* 其他选项:`True`,进行白化处理。
* 作用:白化是一种线性变换,可以使投影后的数据具有相同的方差,有助于提高数据的可解释性。
4. `svd_solver`(SVD求解器类型):
* 描述:决定使用的SVD(奇异值分解)求解器的类型。
* 默认值:`"auto"`,根据输入数据的大小和特征数量选择最合适的求解器。
* 其他选项:`"full"`、`"arpack"`和`"randomized"`。
* 作用:具体选择哪种求解器取决于数据集的大小和矩阵的结构,可以根据实际情况进行调整。
5. `tol`(收敛容差):
* 描述:决定奇异值分解的收敛容差。
* 默认值:`0.0`,表示使用默认的收敛容差。
* 作用:较小的值会产生更精确的结果,但也会增加计算时间。
6. `iterated_power`(幂迭代次数):
* 描述:决定幂迭代方法的迭代次数。
* 默认值:`"auto"`,使用一种启发式方法选择迭代次数。
* 作用:通常情况下,不需要手动调整这个参数,算法会自动选择合适的迭代次数。
7. `random_state`(随机数种子):
* 描述:决定随机数生成器的种子,用于在使用"randomized"求解器时控制随机性。
* 默认值:`None`,随机数生成器使用当前系统时间作为种子。
* 作用:通过设置相同的随机种子,可以确保在相同的数据上获得可重复的结果。
这些参数提供了在使用PCA算法时进行调整的灵活性,可以根据数据集的特点和分析需求进行相应的设置。
四、一些问题回答
(一)主成分分析中第一个主成分、第二个主成分、第三个主成分......有顺序关系吗,它们的位置是随便乱排的吗?
回答:
(1)在主成分分析中,主成分是按照它们所代表的方差大小排序的,也就是说第一个主成分对应的方差是最大的,第二个主成分对应的方差次大,以此类推。因此,主成分之间是有顺序关系的,它们的位置不是随便乱排的,而是按照方差大小依次排列的。这种顺序关系确保了我们能够按照主成分的重要性对数据进行适当的降维和分析。
(2)第一个主成分是数据中方差最大的方向,也就是数据在这个方向上的变化最大。第二个主成分是与第一个主成分正交的方向中方差第二大的方向。第三个主成分则是与前两个主成分正交的方向中方差第三大的方向。数学上,主成分分析通过计算数据的协方差矩阵的特征值和特征向量来找到主成分。第一个主成分对应于协方差矩阵的最大特征值所对应的特征向量,第二个主成分对应于第二大特征值所对应的特征向量,以此类推。
(3)在主成分分析(PCA)中,一般情况下第一个主成分(PC1)是最重要的,因为它解释了数据中方差最大的方向。随后的每个主成分(如第二主成分PC2、第三主成分PC3等)按顺序捕捉剩余方差,并且其解释的方差通常会依次减少。这意味着PC2解释的是除去PC1后剩余数据变异中的最大部分,PC3则解释PC1和PC2之后剩余变异的最大部分,以此类推。
每个后续主成分都是正交(即相互独立)于前面的所有主成分,且按照对方差的贡献度递减排序。因此,从重要性角度来看,确实越往后的主成分相对于前几个主成分来说,对数据整体变异的解释能力逐渐减弱。在实际应用中,人们常常只选取前几个主成分来近似原始数据,因为这些主成分已经包含了大部分信息,而后面的主成分可能被认为是噪声或次要因素。不过,这也取决于分析的具体需求和数据本身的特性,有时较靠后的主成分也可能携带特定分析中有意义的信息。
(二)每个主成分是原始数据各个特征的线性组合对不对,或者说主成分荷载矩阵是不是每个主成分对应的各个特征的线性系数?

(三)进行PCA后,如何对主成分进行命名
主成分分析(PCA)后得到的新变量,即主成分,通常是按照解释方差的大小进行排序的,第一个主成分解释了最大的方差,第二个次之,依此类推。由于PCA是一种数学变换,生成的主成分往往没有直接的实际意义,它们是原始变量的线性组合。因此,直接命名主成分并不像命名原始变量那样基于具体的物理或现实世界的属性。
尽管如此,可以按照以下几种方式对主成分进行描述或“命名”:
1. **根据解释的方差比例**:最直接的方式是依据其解释的方差比例来命名,如“第一主成分(PC1)”,它说明了这是解释数据方差最多的一个成分。进一步可以描述为“解释XX%方差的第一主成分”。
2. **功能或特征描述**:尝试理解主成分与原始变量的关系后,可以根据其主要影响的特征或功能给予描述性名称。例如,如果PCA结果显示第一主成分主要由身高和体重这两个变量的线性组合主导,你可能将其描述为“身体尺寸因子”。
3. **潜在概念命名**:有时,主成分能反映出数据中隐藏的模式或结构,如果能识别出这些模式与某个理论或领域知识相符,可以据此命名。例如,在市场研究中,如果一个主成分与消费者偏好高度相关,可以称之为“消费者偏好指数”。
4. **数学特性**:在某些研究背景下,主成分的数学属性(如正负方向、斜率等)可能具有解释意义,据此也可以给予相应的数学描述命名。
需要注意的是,给主成分命名更多是一种解读和解释过程,需要结合PCA的结果、专业知识以及数据分析的目的来综合考虑。在学术或专业报告中,通常会提供主成分的详细解释,并可能包括因子载荷图或贡献度分析来辅助理解每个主成分的意义。
(四)进行主成分分析之前进行数据标准化/归一化,还是主成分分析之后?或者主成分分析之前之后都需要进行数据标准化/归一化?
进行主成分分析之前一般需要进行数据标准化,以确保不同尺度的变量在分析过程中公平地贡献信息,避免因量纲不同导致的误解或偏差,从而使它们处于同一量级上。
然而,你提到的是在主成分分析之后是否还需要进行数据标准化,这通常是不必要的。主成分分析过程本身(特别是在使用了相关矩阵或在软件中默认进行了标准化时)已经考虑了变量尺度的影响。完成主成分分析后,得到的主成分是原始变量的线性组合,并且在计算过程中已经考虑了标准化的效果。因此,分析得到的主成分得分已经是标准化后的结果,无需再次进行标准化。
总结来说,数据标准化是PCA预处理的一部分,而非事后操作。在得到主成分后,接下来的操作如解释成分、进行进一步统计测试或建模等,通常直接基于主成分分析的结果进行,不再需要对这些结果进行额外的标准化处理。
五、python代码实现主成分分析PCA
注意:
在进行主成分分析之前建议一定或者是最好进行数据标准化/归一化,本次没有进行数据表标准化/归一化,伙伴在跟着下边的步骤进行主成分分析代码实战时,建议自己先处理一下数据归一化的步骤。
在进行主成分分析(PCA)之前,通常会对数据进行标准化(或归一化)。标准化可以确保数据在进行PCA时具有相同的重要性,避免因为不同特征的尺度差异而导致PCA结果不准确。
可以参照以下这个链接:
python实现将数据标准化到指定区间[a,b]+正向标准化+负向标准化-CSDN博客
(一)导入数据集
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
df.label.value_counts()#分类标签的样本数
# 从DataFrame中提取输入特征(前四列)存储在变量 'x' 中
X = df.iloc[:, 0:4]
# 从DataFrame中提取目标变量(最后一列)存储在变量 'y' 中
y = df.iloc[:, -1]
# print("查看第一个数据: \n", X.iloc[0, 0:4])
本次对鸢尾花数据集的四个特征进行PCA,即对X中的数据进行降维,X的数据呈现如下:
(二)使用PCA进行数据降维
from sklearn.decomposition import PCA
model = PCA()
model.fit(X)这里没有人为设置PCA的参数选择,那就是默认系统内置的选择
强调一下:
n_components这个参数,如果没有设置的话,那么就默认保留所有的主成分,我们进行降维的原始数据有四个特征,那么就会保留四个主成分,n_components=3那么就会自动保留前三个方差最大的主成分。注意:n_components=5或者5以上的数,针对本次数据集是不可以的,因为我们最多有四个特征,所以最多产生4个主成分。
(三)查看方差贡献
#每个主成分能解释的方差
print('每个主成分能够解释的方差:{}'.format(model.explained_variance_))
(四)查看方差贡献率及其可视化
(1)查看方差贡献率
#每个主成分能解释的方差的百分比/方差贡献率
print('每个主成分能够解释的方差的百分比/方差贡献率:{}'.format(model.explained_variance_ratio_))
pca.explained_variance_ratio_的输出结果是一个一维数组,包含了每个主成分解释的方差比例。
这个比例可以用来评估每个主成分的重要性。一般来说,解释方差比例越高的主成分,其包含的信息量越大,对原始数据的解释能力越强。
(2)方差贡献率可视化
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.figure(figsize=(12,7))
#可视化
plt.plot(range(1, len(model.explained_variance_ratio_) + 1), model.explained_variance_ratio_, 'o-')
# plt.xlabel('Principal Component',fontsize=20,labelpad=20)
# plt.ylabel('Proportion of Variance Explained',fontsize=20,labelpad=20)
plt.xlabel('第几个主成分',fontsize=20,labelpad=20)
plt.ylabel('每个主成分对应的方差贡献率',fontsize=20,labelpad=20)
plt.title('方差贡献率',fontsize=20,pad=15)
plt.tick_params(labelsize=16)#设置坐标轴上标签的字体大小
# plt.grid(True,alpha=0.4)
plt.show()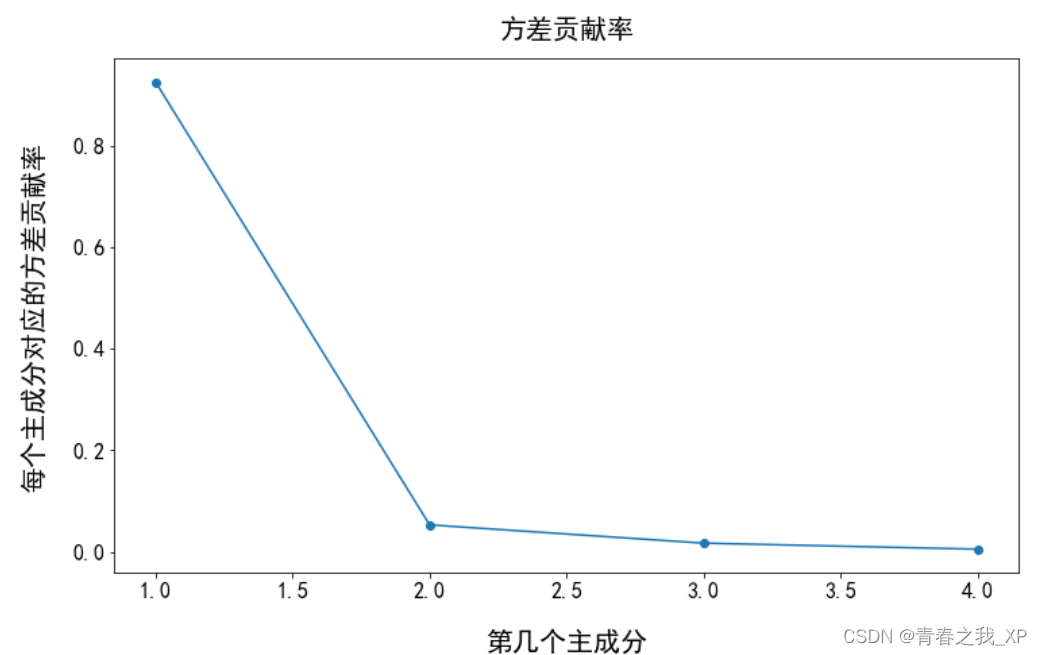
(五)查看累计方差贡献率及其可视化
(1)查看累计方差贡献率
# 计算主成分,并确定需要保留多少个主成分来解释指定比例的方差
print('累计方差贡献率:{}'.format(model.explained_variance_ratio_.cumsum()))![]()
(2) 累计方差贡献率可视化
#画累计百分比,这样可以判断选几个主成分
plt.plot(range(1, len(model.explained_variance_ratio_) + 1),model.explained_variance_ratio_.cumsum(), 'o-')
plt.xlabel('主成分个数',fontsize=20,labelpad=20)
plt.ylabel('累计方差贡献率',fontsize=15,labelpad=20)
plt.axhline(0.95, color='r', linestyle='--', linewidth=1)
plt.title('累计方差贡献率',fontsize=20)
plt.tick_params(labelsize=16)#设置坐标轴上标签的字体大小
plt.show()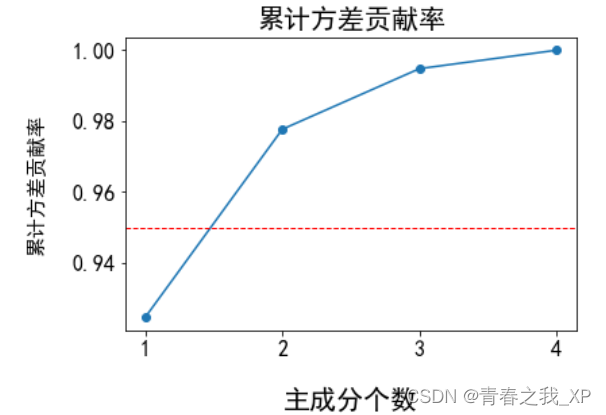
(六) 选择主成分并进行命名
(1)选择主成分
上图中的红线,是我们设置的阈值,代表方差贡献率达到0.95,也就是我们人为的设定希望方差贡献率达到0.95,那么本次就选前两个主成分来解释原始的四个特征,也就是将原始的四维数据降到二维。
(2)对主成分进行命名
对于第一个主成分,可以根据其代表的四个特征的线性组合系数来命名。由于系数分别对应于[sepal length、sepal width、petal length、petal width],可以看出petal length和petal width的系数相对较大,这意味着这个主成分主要反映了花瓣长度和宽度的信息。因此,您可以将这个主成分命名为“花瓣尺寸因子”或类似的名称,以表明它是花瓣尺寸特征的一个综合指标。
在PCA分析中,主成分的命名通常与其解释的变异性或特征的重要性有关。第一个主成分(PC1)通常解释数据中最多的变异性,而后续的主成分则解释剩余的变异性。在您的案例中,由于第一个主成分的特征向量中petal length和petal width的系数较大,这表明它们对主成分的贡献最大,因此命名时应当反映这一点。
同理,将第二个主成分命名为“花萼尺寸因子
(七)将方差贡献率和累计方差贡献率同时可视化
cum_var_exp = np.cumsum(model.explained_variance_ratio_)
plt.figure(figsize=(10, 6), dpi=100) # 增加图的大小和分辨率
plt.bar(range(1, 5), model.explained_variance_ratio_, alpha=0.7, align='center', color='skyblue', label='Individual Variance')
plt.step(range(1, 5), cum_var_exp, where='mid', color='orange', label='Cumulative Variance')
plt.ylabel('方差贡献率', fontsize=16, labelpad=10)
plt.xlabel('主成分', fontsize=16, labelpad=10)
plt.legend(loc='best', fontsize=12)
plt.axhline(0.8, color='r', linestyle='--', linewidth=1)
plt.grid(True, linestyle='--', alpha=0.5) # 添加网格线
plt.tick_params(labelsize=12)
plt.title('Explained Variance by Principal Components', fontsize=18, pad=20) # 调整标题位置和字体大小
plt.tight_layout() # 调整布局以防止标签被裁剪
plt.show()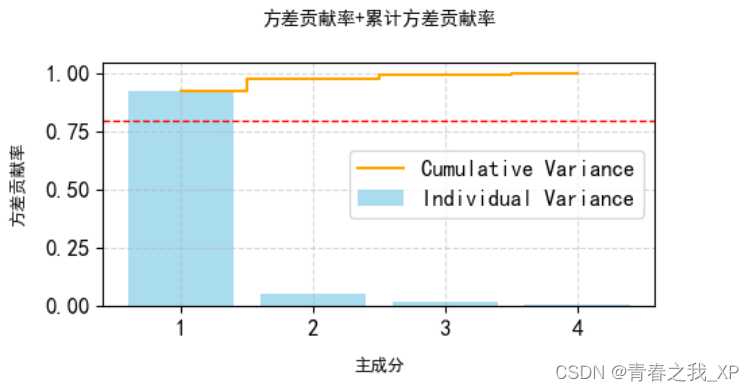
(八)查看主成分荷载矩阵
#主成分核载矩阵
model.components_
columns = ['PC' + str(i) for i in range(1, 5)]
pca_loadings = pd.DataFrame(model.components_, columns=X.columns, index=columns)
round(pca_loadings, 2)
# 该矩阵展示了每个主成分是原始数据的线性组合,以及线性的系数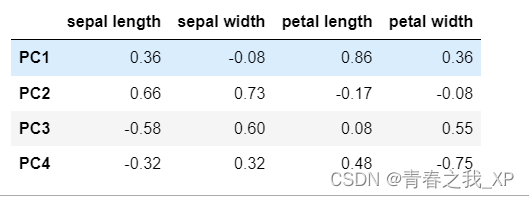
每个主成分是原始数据各个特征的线性组合对不对,或者说主成分荷载矩阵是不是每个主成分对应的各个特征的线性系数?

# 打印出每个主成分对应的属性特征
for i, row in pd.DataFrame(model.components_).iterrows():
print(f"Principal Component {i+1}:")
print(row)
print()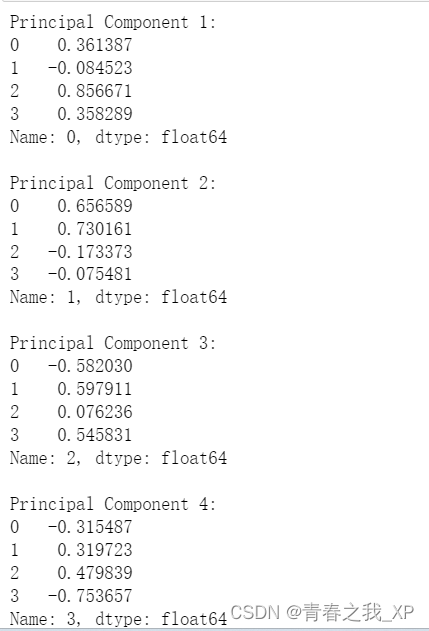
(九)输出降维后的数据
pca = PCA(n_components=2)
pca.fit(X)
# 打印降维后的数据
# 调用fit_transform方法,将输入数据进行降维转换
new = pca.fit_transform(X)
new=pd.DataFrame(new)
# 使用rename函数更改列名
new.rename(columns=dict(zip(new.columns, ["花瓣尺寸因子","花萼尺寸因子"])), inplace=True)
print('PCA降维后数据:')
new = pd.concat([new, pd.DataFrame(iris.target,columns=['标签'])], axis=1)
new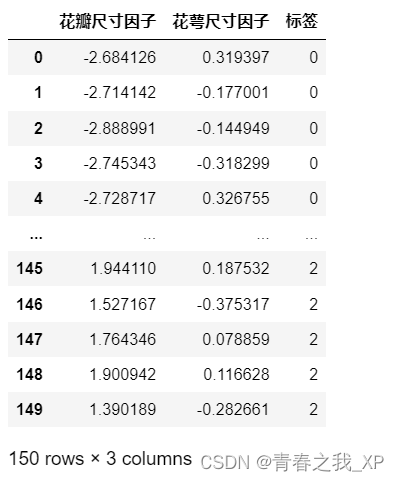
(十)主成分分析结果可视化
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
fig = plt.figure(figsize=(5, 5))
ax = fig.add_subplot(1, 1, 1)
ax.set_xlabel('花瓣尺寸因子', fontsize=15)
ax.set_ylabel('花萼尺寸因子', fontsize=15)
ax.set_title('2 component PCA', fontsize=20)
# 设置刻度值的格式化字符串
formatter = ticker.StrMethodFormatter("{x:.1f}")
ax.xaxis.set_major_formatter(formatter)
ax.yaxis.set_major_formatter(formatter)
targets = [0, 1, 2]
colors = ['r', 'g', 'b']
for target, color in zip(targets, colors):
indices = new['标签'] == target
ax.scatter(new.loc[indices, '花瓣尺寸因子'],
new.loc[indices, '花萼尺寸因子'],
c=color,
s=50)
ax.legend(targets)
ax.grid()
plt.show()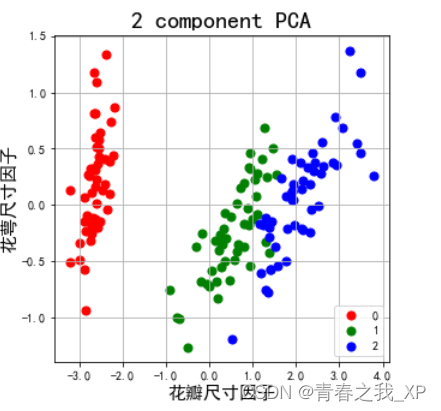


















 1932
1932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









