




文章目录
一、Redis 主从复制
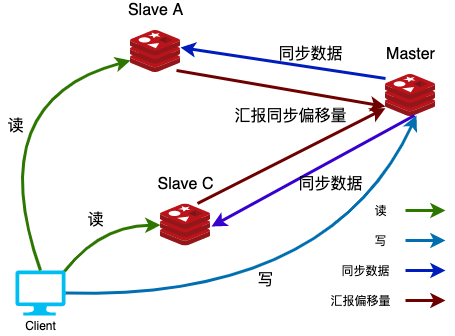
主从复制是 Redis 保障数据不丢失、避免单点故障的核心机制,通过 “主库处理写操作,从库备份数据 / 处理读操作” 的分工,实现数据备份与读写分离。
1.1 复制方式:异步复制
防止主库磁盘损坏导致数据永久丢失:从库会备份主库数据,主库故障时从库可保留数据。
异步复制的特点:主库收到写请求后,立即向客户端返回“成功”,不等待从库同步完成,只保证最终数据一致(而非任意时刻的强一致)。
对比同步复制:同步复制是“主库写完,等所有从库确认收到后再返回”;异步复制是“主库写完就返回,从库后续慢慢同步”。
常见场景:MySQL、Redis 等数据库多采用异步复制;分布式数据库(如部分分布式 KV 存储)常采用“半数以上节点一致”的强一致策略。
另外,是 从库主动向主库建立连接(而非主库主动连从库),这样才能支持线上新增从库的场景。
1.2 配置与状态查看
通过命令行或配置文件,可指定从库同步的主库。
命令行方式:
- Redis 5.0 及以后:使用
replicaof命令。
示例(让当前 Redis 实例成为127.0.0.1:7001的从库):redis-server --replicaof 127.0.0.1 7001 - Redis 5.0 以前:使用
slaveof命令(作用与replicaof一致)。
配置文件方式:
修改 Redis 配置文件(如 redis.conf),添加以下配置(以同步 127.0.0.1:7002 的主库为例):
replicaof 127.0.0.1 7002
查看复制状态:
执行以下命令,可查看主从复制的详细信息(如主从角色、偏移量等):
info replication
1.3 数据同步机制
主从数据同步分为全量同步和增量同步,依赖 运行 ID(RUN ID)、复制偏移量(offset)、环形缓冲区 三大核心组件协作。
1.3.1 全量数据同步
当从库第一次连接主库时,会执行全量同步:主库将所有数据完整发送给从库,从库接收后完成全量备份(这是从库初始化数据的核心方式)。
1.3.2 增量数据同步
当从库与主库断开后重连,如果能复用之前的同步进度,会执行增量同步:只同步断开期间主库新增的写操作。增量同步依赖以下组件:
1. 服务器运行 ID(RUN ID)
每个 Redis 实例(主/从库)启动时,会自动生成40位随机十六进制字符组成的 RUN ID,用于唯一标识自己。
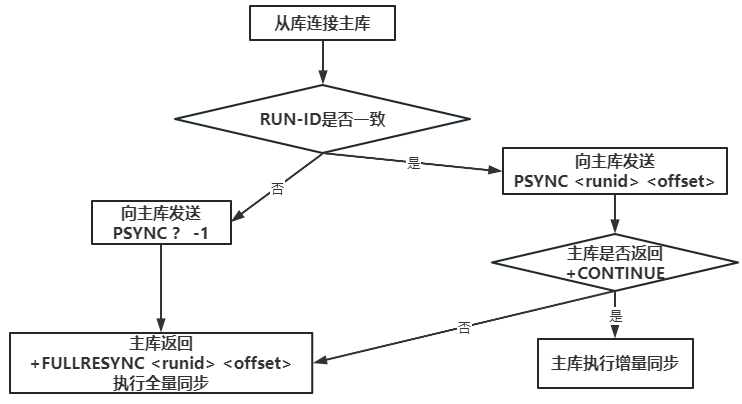
复制流程:
- 初次复制:主库把自己的 RUN ID 发给从库,从库保存该 RUN ID。
- 断线重连:从库向主库发送之前保存的 RUN ID。
- 如果主库 RUN ID 与从库保存的一致:说明从库之前同步的是当前主库,主库尝试增量同步(只发断开期间的新数据)。
- 如果不一致:说明从库之前同步的主库已更换(如主库故障后被替换),主库会执行全量同步(重新发送所有数据)。
2. 复制偏移量(offset)
主库和从库各自维护“复制偏移量”:
- 主库每发送
N字节数据,自身偏移量+N; - 从库每接收
N字节数据,自身偏移量也+N。
通过比较主从偏移量,可判断数据是否一致:偏移量相同则数据完全同步,不同则需进一步同步。
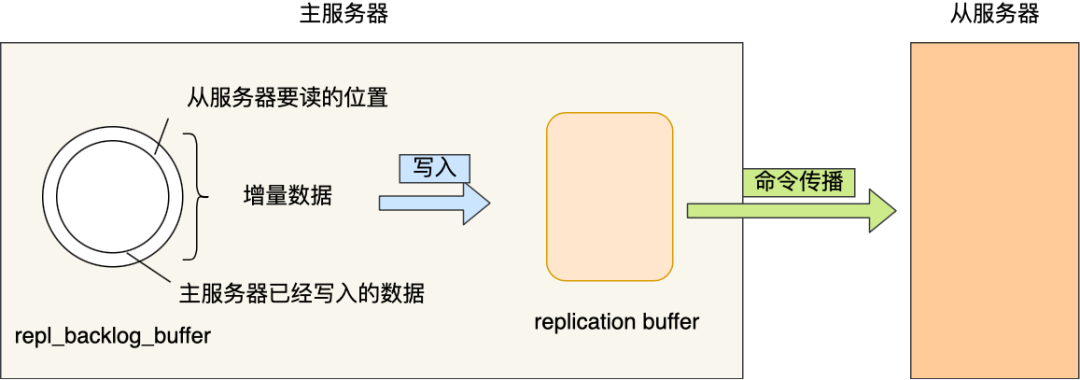
3. 环形缓冲区(复制积压缓冲区)
- 本质:固定长度的先进先出(FIFO)队列。
- 作用:从库断开期间,临时存储主库的写操作,避免重连后直接全量同步。
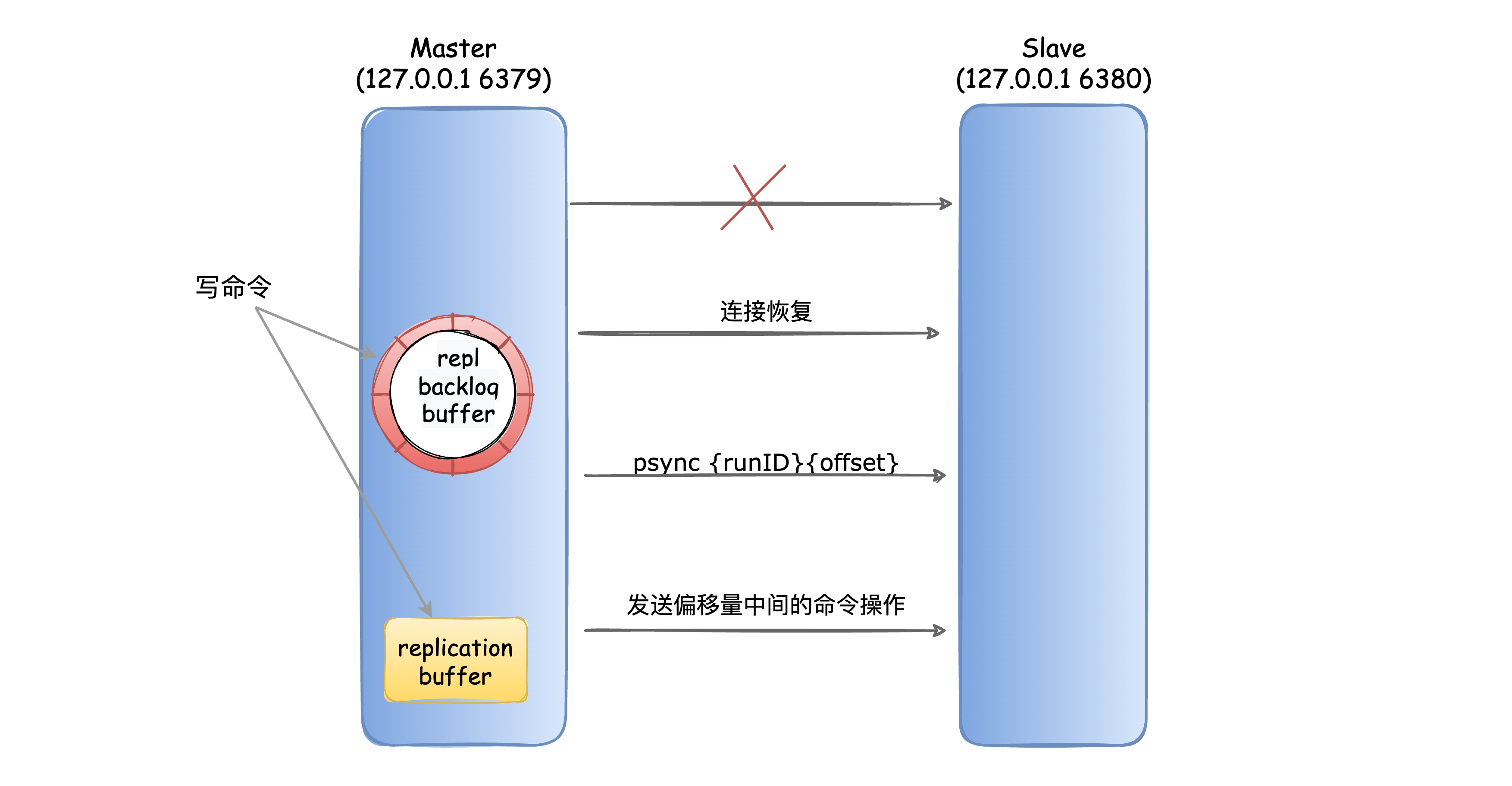
工作逻辑: 当因某些原因(网络抖动或从库宕机)从库与主库断开连接,避免重新连接后开始全量同步,在主 库设置了一个环形缓冲区;该缓冲区会在从库失联期间累计主库的写操作;当从库重连,会发送自 身的复制偏移量到主库,主库会比较主从的复制偏移量:
- 若偏移量 offset 在缓冲区覆盖范围内(断开期间的写操作未被“挤掉”):主库从该偏移量开始,增量同步缓冲区中的写操作。
- 若偏移量 offset 超出缓冲区范围(断开时间太长,缓冲区存不下):主库对从库执行全量同步。
环形缓冲区的配置: 在 redis.conf 中配置缓冲区参数:
# 设置缓冲区大小(示例为 1MB)
repl-backlog-size 1mb
# 所有从库断开后,若 3600 秒内未重连,释放缓冲区
repl-backlog-ttl 3600
缓冲区大小的计算:
为覆盖从库断线重连时间,通常用以下公式估算缓冲区大小:
缓冲区大小 = 断开时间(秒) × 主库平均每秒产生的写命令数据量
断开时间:从库断线后平均重连时间(单位:秒)。主库平均每秒产生的写命令数据量:主库正常运行时,每秒写操作对应的数据体积。
二、Redis 哨兵模式
2.1 原理
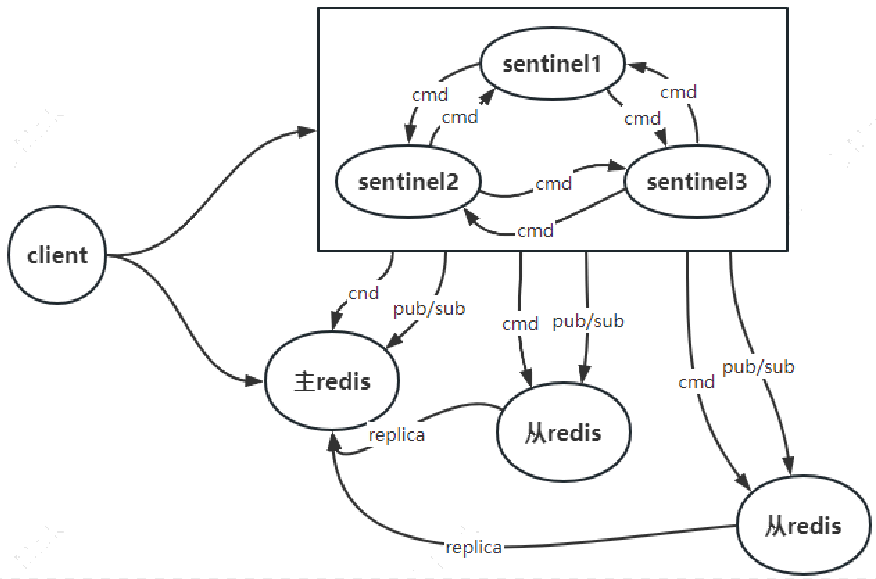
哨兵模式是 Redis 的高可用性解决方案:由一个或多个 sentinel(哨兵)实例组成哨兵系统,监视主库以及这些主库所属的从库的状态;主库故障时,自动将该主库所属的某个从库升级为新的主库,保障服务持续可用。
客户端来连接集群时,
- 首先连接哨兵,通过哨兵来查询主节点的地址,同时订阅“主库切换通知”,监听主节点切换,主库故障时可自动感知新主库地址。
- 然后再连接主节点进行数据交互。
当主节点发生故障时,哨兵主动推送新的主库地址。通过这样客户端无须重启即可自动完成节点切换。
哨兵模式当中涉及多个选举流程采用的是 Raft 算法的领头选举方法的实现
2.2 配置示例
编写哨兵配置文件(如 sentinel.conf),指定监视的主库、主观下线时长等参数。示例:
# 监视名为“mymaster”的主库(地址 127.0.0.1:6379)
# “2”表示至少 2 个哨兵认为主库下线,才判定为“客观下线”
sentinel monitor mymaster 127.0.0.1 6379 2
# 判定“主观下线”的时长:30000 毫秒(30 秒)内,节点对哨兵的 ping 无响应,就被判定为“主观下线”
sentinel down-after-milliseconds mymaster 30000
# 故障切换时,同时同步新主库的从库数量:“1”表示每次只让 1 个从库同步新主库(减少网络瞬间压力)
sentinel parallel-syncs mymaster 1
# 故障切换超时时间:超过 180000 毫秒(3 分钟)未完成故障切换,视为失败
sentinel failover-timeout mymaster 180000
2.3 故障检测与转移
哨兵对主库的故障检测分主观下线和客观下线两个阶段,之后执行故障转移。
主观下线:单个哨兵以 每秒 1 次 的频率,向所有被监视的主库、从库、其他哨兵发送 ping 消息。若主库在 down-after-milliseconds 配置的时长内(如 30000 毫秒),对 ping 无有效响应,该哨兵会将其判定为主观下线(即“我认为它下线了”)。
客观下线:当一个哨兵把主库判定为“主观下线”后,会向其他哨兵询问主库状态:
- 若收到半数以上哨兵回复“主库也下线了”,主库会被判定为客观下线(即“大家都认为它下线了”)。
- 此时,哨兵系统会选举“领头哨兵”,由它执行后续故障转移操作。
故障转移流程:
主节点被判定为客观下线后,开始领头 sentinel 选举(类似 Raft 算法),需要半数以上的 sentinel 支持,选举领头 sentinel 后,开始执行对主节点故障转移:
- 选举新主库:从原主库的从库中,选“最适合”的从库(考虑数据完整性、网络状况等)升级为新主库。
- 通知其他从库同步新主库:让原主库的其他从库,改为同步新主库的数据。
- 处理原故障主库:如果原故障主库恢复,会作为新主库的从库,继续同步新主库数据。
2.4 客户端使用流程
客户端通过以下步骤,连接 Redis 主库并感知主库切换:
步骤 1:连接哨兵,获取主库地址
执行哨兵命令,获取当前主库的 IP 和端口:
SENTINEL GET-MASTER-ADDR-BY-NAME <master-name>
# 示例:master-name 为“mymaster”时,执行
# SENTINEL GET-MASTER-ADDR-BY-NAME mymaster
步骤 2:验证主库身份
连接主库后,执行以下命令验证其是否为真主库:
# 方式 1:查看节点角色
ROLE
# 方式 2:查看复制状态
INFO REPLICATION
步骤 3:订阅主库切换通知
为感知主库故障切换,给哨兵建立发布订阅(PUB/SUB)连接,并订阅 +switch-master 频道:主库切换时,哨兵会向 +switch-master 频道推送通知,客户端收到后可重新连接新主库。
2.5 缺点
哨兵模式虽提升了可用性,但仍有不足:
1. 数据丢失风险
主从采用异步复制,主库故障时从库可能未同步完所有数据,导致部分数据丢失。如果主从延迟大(主库写得快、从库同步慢),丢失数据会更多。
可通过配置降低风险(牺牲部分可用性,减少数据丢失):
# 主库必须至少有 1 个从库正常同步,否则主库停止写操作(保障数据不丢,但主库不可用)
min-slaves-to-write 1
# 定义“正常同步”:从库 10 秒内没反馈同步状态,视为同步异常
min-slaves-max-lag 10
2. 横向扩展能力不足
哨兵模式无法支持 Redis 的“横向扩展”(通过增加节点提升存储/性能),仅解决“主库故障自动切换”的高可用问题,不涉及集群水平扩展。
3. 故障切换有延迟
主库切换过程通常需要 “几十秒”,期间客户端可能遇到短暂的服务不可用。

















 9693
9693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









