






现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。
输入格式:
输入数据包括城镇数目正整数N(≤1000)和候选道路数目M(≤3N);随后的M行对应M条道路,每行给出3个正整数,分别是该条道路直接连通的两个城镇的编号以及该道路改建的预算成本。为简单起见,城镇从1到N编号。
输出格式:
输出村村通需要的最低成本。如果输入数据不足以保证畅通,则输出−1,表示需要建设更多公路。
输入样例:
6 15
1 2 5
1 3 3
1 4 7
1 5 4
1 6 2
2 3 4
2 4 6
2 5 2
2 6 6
3 4 6
3 5 1
3 6 1
4 5 10
4 6 8
5 6 3
输出样例:
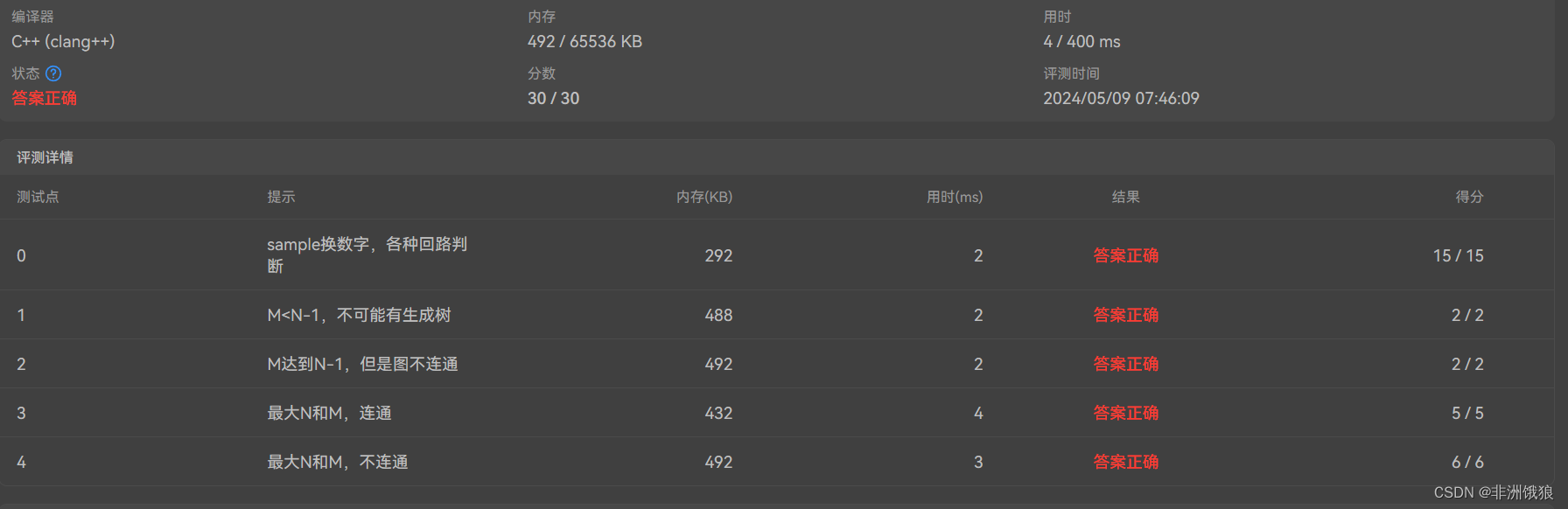
12这是一个典型的无向图最小生成树问题,可通过 Kruskal 或 Prim 算法来解决。
Kruskal算法。我们可以按照边的权重从小到大对图进行排序,然后逐条检查边,将其两端的顶点连接起来。每次成功连接后,将待连接的顶点数量减少 1,直到只剩下一个顶点为止。如果最后剩余一个顶点,则图已连通,输出最小生成树的权重和;否则,输出 -1。
对边按权重进行排序的时间复杂度为 O(m log m)。在连接边的过程中,进行了最多 m 次查询和更新操作,find函数使用了路径压缩的优化,每次查询和更新操作的时间复杂度接近于 O(1)。总的时间复杂度为O(m log m)。
#include<bits/stdc++.h>
using namespace std;
struct E{
int u,v,w;
bool operator<(const E& other) const {
return w<other.w;
};
};
vector<int>parent;
int find(int x){
return parent[x]==x?x:parent[x]=find(parent[x]);
}
void unite(int x,int y){
parent[find(x)]=find(y);
}
bool same(int x,int y){
return find(x)==find(y);
}
int main(){
int n,m,sum=0;
cin>>n>>m;
parent.resize(n+1);
iota(parent.begin(),parent.end(),0);
vector<E>e(m);
for(int i=0;i<m;i++){
cin>>e[i].u>>e[i].v>>e[i].w;
}
sort(e.begin(),e.end());
for(int i=0;i<m;i++){
if(same(e[i].u,e[i].v)){
continue;
}
n--;
unite(e[i].u,e[i].v);
sum+=e[i].w;
}
if(n>1){
cout<<-1;
}
else{
cout<<sum;
}
return 0;
}
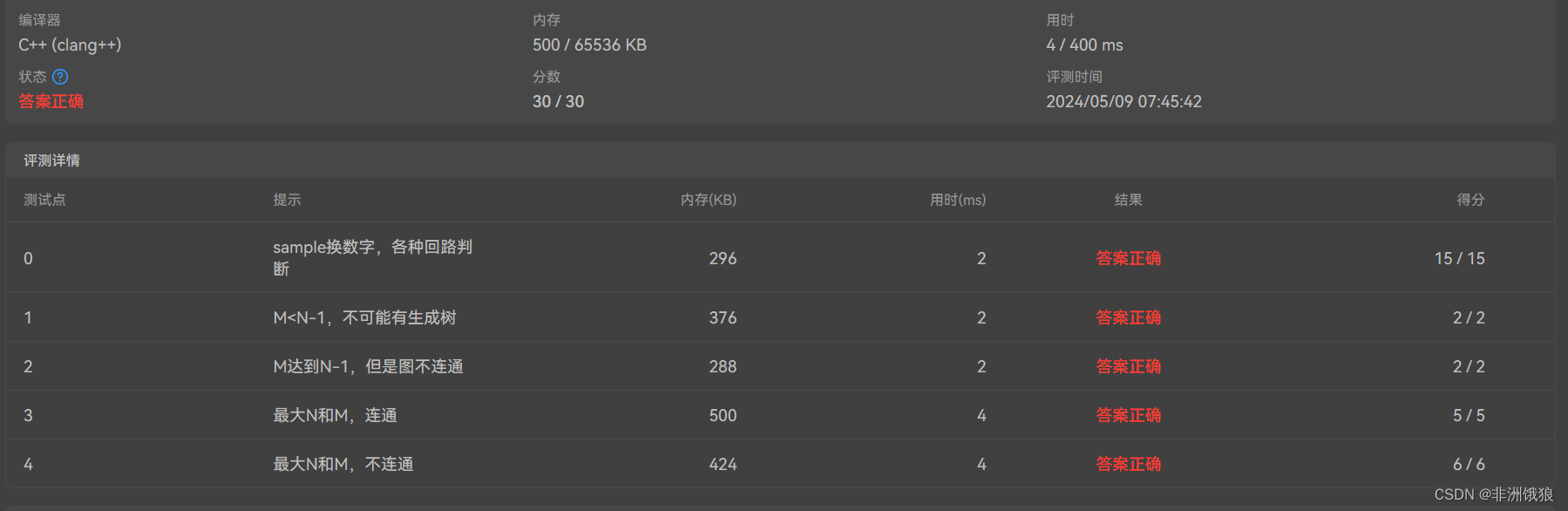
Kruskal算法的优先队列实现与排序思路基本相同,它需要进行m次插入和删除操作,每次操作的时间复杂度为O(log m),因此总的时间复杂度为O(m log m)。
#include<bits/stdc++.h>
using namespace std;
struct E{
int u,v,w;
bool operator < (const E& other) const {
return w>other.w;
};
};
vector<int>parent;
int find(int x){
return parent[x]==x?x:parent[x]=find(parent[x]);
}
void unite(int x,int y){
parent[find(x)]=find(y);
}
bool same(int x,int y){
return find(x)==find(y);
}
int main(){
int n,m,sum=0;
cin>>n>>m;
parent.resize(n+1);
iota(parent.begin(),parent.end(),0);
priority_queue<E>e;
for(int i=0,u,v,w;i<m;i++){
cin>>u>>v>>w;
e.push({u,v,w});
}
while(!e.empty()){
int u=e.top().u,v=e.top().v,w=e.top().w;
e.pop();
if(same(u,v)){
continue;
}
unite(u,v);
n--;
sum+=w;
}
if(n>1){
cout<<-1;
}
else{
cout<<sum;
}
return 0;
}
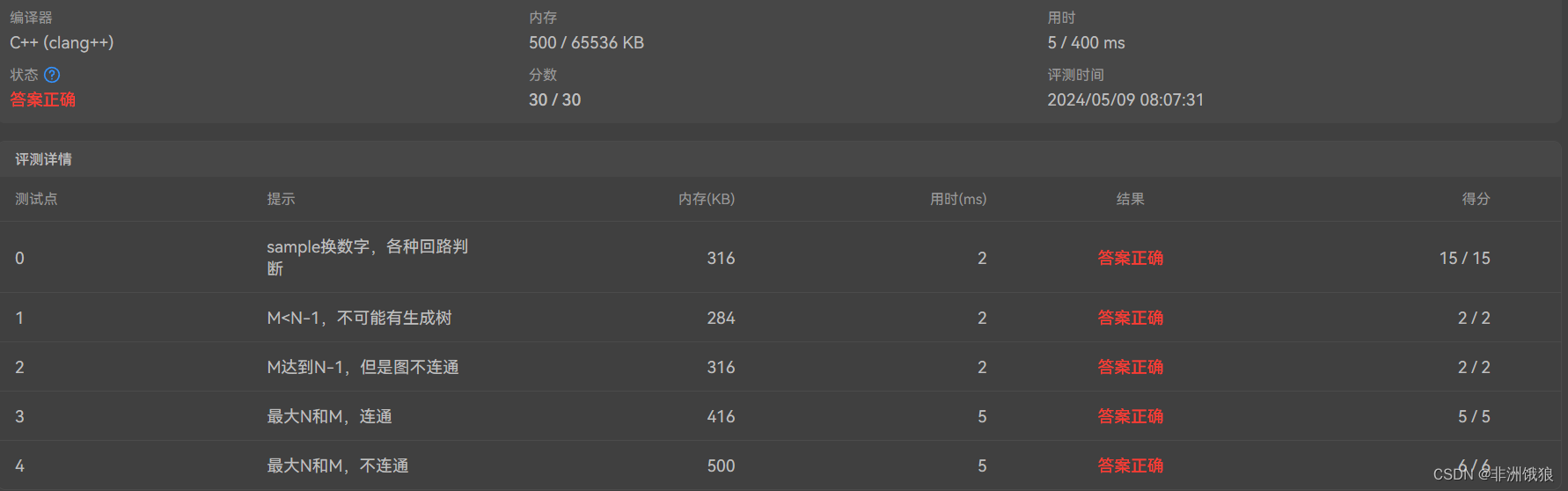
Prim算法与Kruskal算法不同,它采用的是加点的方法,逐步将图分成两个集合,一个是在最小生成树(MST)中的点,另一个是不在MST中的点。首先将一个节点到最小生成树的距离设为0,标记该点在MST内,然后逐渐选择离MST最近的点加入MST。通过判断循环是否进行了n次,我们可以确定是否生成了完整的最小生成树。
这段代码中,通过简单的数组和循环来选择最小边,每次找到最近的节点需要O(n)的时间复杂度,由于需要查找n次,因此总的时间复杂度为O(n^2)。
#include<bits/stdc++.h>
using namespace std;
const int inf=1e9;
int main(){
int n,m,sum=0;
bool flag=false;
cin>>n>>m;
vector<bool>vis(n+1);
vector<vector<pair<int,int>>>E(n+1);
vector<int>dist(n+1,inf);
for(int i=0,u,v,w;i<m;i++){
cin>>u>>v>>w;
E[u].push_back({w,v});
E[v].push_back({w,u});
}
dist[1]=0;
for(int i=0;i<n;i++){
int u=-1;
for(int j=1;j<=n;j++){
if(dist[j]!=inf&&!vis[j]&&(u==-1||dist[u]>dist[j])){
u=j;
}
}
if(u==-1){
break;
}
if(i==n-1){
flag=true;
}
sum+=dist[u];
vis[u]=true;
for(auto& e:E[u]){
int v=e.second,w=e.first;
dist[v]=min(dist[v],w);
}
}
if(!flag){
cout<<-1;
}
else{
cout<<sum;
}
return 0;
}
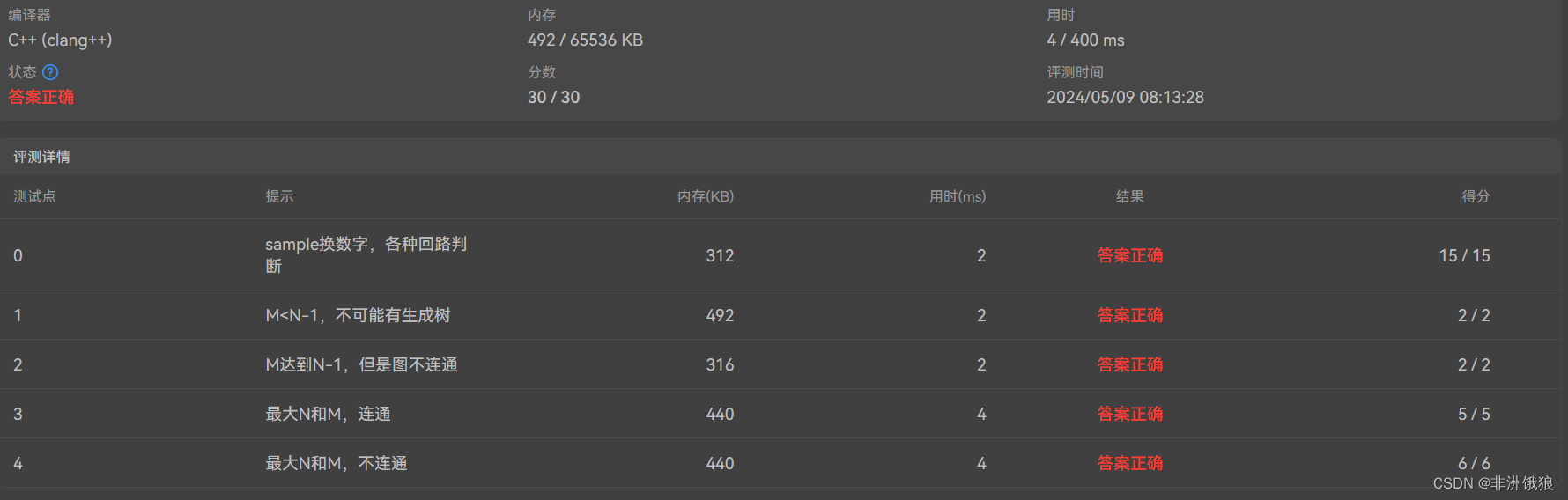
我们可以通过使用优先队列来优化 Prim 算法,以降低查找最近点的时间复杂度。
在Prim算法优先队列的实现中,每次查找最近点的时间复杂度为 O(log n),需要进行 n 次这样的查找。同时,每个顶点的所有邻居都会被检查一次,因此检查所有边的时间复杂度是 O(m),其中 m 表示一个顶点连接的边数。因此,Prim算法的总时间复杂度为 O(nmlog n)。
然而,值得注意的是,尽管使用优先队列在一般情况下是高效的,但在某些特殊情况下,如完全图的情况下,其边数 m 可以达到 n-1,这时总的时间复杂度将达到 O(n^2log n)。相比之下,采用简单数组和循环的实现方式在这种情况下的时间复杂度为 O(n^2)。
#include<bits/stdc++.h>
using namespace std;
const int inf=1e9;
int main(){
int n,m,sum=0;
cin>>n>>m;
vector<bool>vis(n+1);
vector<vector<pair<int,int>>>E(n+1);
vector<int>dist(n+1,inf);
for(int i=0,u,v,w;i<m;i++){
cin>>u>>v>>w;
E[u].push_back({w,v});
E[v].push_back({w,u});
}
dist[1]=0;
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>>que;
que.push({0,1});
while(!que.empty()){
int u=que.top().second;
que.pop();
if(vis[u]){
continue;
}
n--;
vis[u]=true;
sum+=dist[u];
for(auto& e:E[u]){
int v=e.second,w=e.first;
if(!vis[v]&&w<dist[v]){
dist[v]=w;
que.push({w,v});
}
}
}
if(n){
cout<<-1;
}
else{
cout<<sum;
}
return 0;
}















 467
467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









