







 文章讲述了作者如何利用Python和机器学习技术,尤其是LSTM神经网络,从120万中文姓名数据集中训练模型预测性别。通过将姓名转换为拼音并编码为数值向量,作者实现了性别预测功能,并将其集成到一个网页应用程序中。
文章讲述了作者如何利用Python和机器学习技术,尤其是LSTM神经网络,从120万中文姓名数据集中训练模型预测性别。通过将姓名转换为拼音并编码为数值向量,作者实现了性别预测功能,并将其集成到一个网页应用程序中。
大家好,小编为大家解答python性别年龄分布图怎么做的的问题。很多人还不知道python性别统计学生人数代码,现在让我们一起来看看吧!
Source code download: 本文相关源码
前言
做这个项目的起因是之前csdn给我推荐了一个问答:基于机器学习的姓名预测性别的手机app开发。我点进去发现已经有人回答了,链接点进去一看,好家伙,这不是查表算概率吗,和机器学习有半毛钱关系Python Turtle画递归树。而且我觉得用姓名预测性别挺扯淡的,去查了一下,发现某知名爱国企业和国外的都有提供姓名预测性别的api,看来是可以尝试做的。
吐槽完了,先上最后做出来的结果: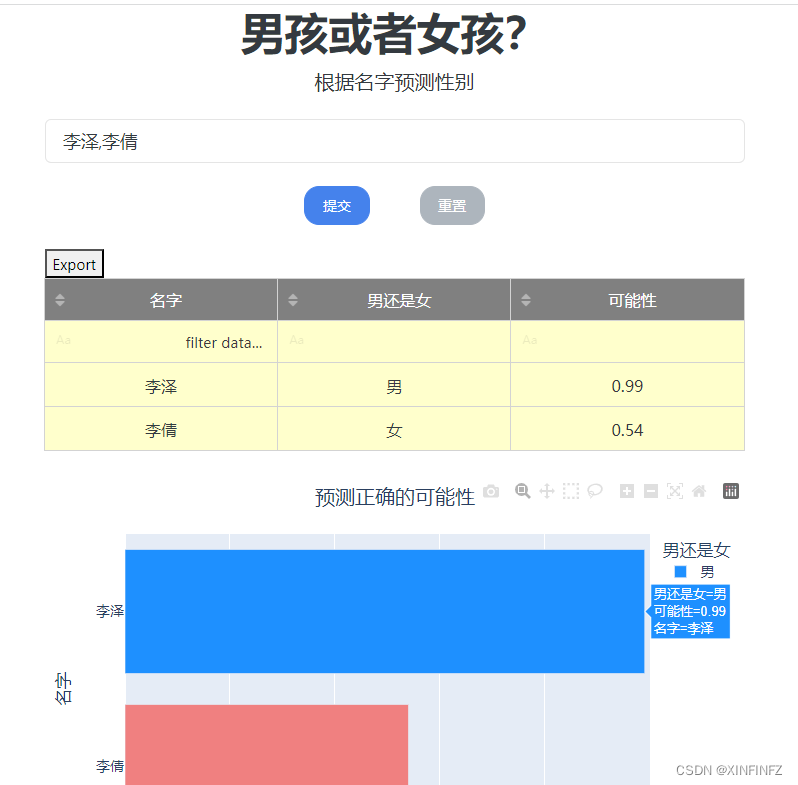
准确性还是可以的,并且支持人名批量查询,整个网页响应速度也很快。
环境
我用的是python3.10,需要安装以下包:
numpy
pandas
pypinyin
tensorflow-cpu
plotly(网页)
dash(网页)
方法
1.如何拿到人名和性别的数据集。这个我一开始去搜那篇查表文章背后所用的数据库从哪来的,在github上找到了它的人名出现频率图,但是没有找到原始数据库,据说是从什么泄露的kaifangjilu里拿出来的,我一想这tm不是违法吗,难道没有合法手段拿到这样的数据集资源了吗?我还是在github上找到了120万人名和性别的数据集:
点进去找到Chinese_Names_Corpus_Gender(120W).txt这个文件
2.如何对中文姓名进行特征提取,转化为机器能理解的语言。 这个想来想去还是决定把中文先转换为无注音的拼音,然后对每一个字母进行字母表数字的转换,事实证明确实效果不错。
具体如下图所示: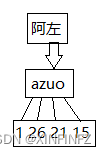
代码
代码分为三块,数据准备代码,数据训练代码,网页app代码。
数据准备代码
首先把下载下来的txt转换为csv文件: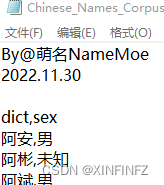
把前面的东西去掉,然后文件后缀一改,就摇身一变成为了以逗号为分割的经典csv文件。
接下来开始读取处理数据:
import pandas as pd
df = pd.read_csv("test.csv")
df
这里我是在notebook里运行的,结果如下:
我们首先需要把性别转换为0,1表示男,女:
df['sex'].replace(['男', '女','未知'],
[0, 1, 2], inplace=True)
然后批量转换姓名并保存到新的csv文件中:
from pypinyin import lazy_pinyin
import time
count = 0
a1 = time.time()
for x in df['dict']:
list_p 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









