






前言
在移动互联网的推动下,短视频平台日益成为人们生活的一部分。短视频,作为国内领先的短视频平台,汇聚了众多用户和丰富多样的内容。对于数据分析、产品运营、市场研究等行业人士而言,掌握短视频平台的数据分析能力显得尤为重要。
一、短视频爬虫是什么?
短视频爬虫是一种自动化工具,旨在从短视频平台上高效地收集公开数据,如视频信息、用户资料、评论和点赞数等。这种工具通常由开发者编写,用于实现以下基本功能和目标:
数据采集:
- 抓取短视频平台上的公开视频内容及其相关元数据。
- 收集用户公开资料,包括但不限于用户名、简介、粉丝数等。
- 获取视频的评论和点赞数据,以分析社会互动情况。
数据分析:
- 对采集到的数据进行处理,运用统计学和机器学习方法提取有价值的信息。
- 分析用户行为模式,如观看习惯、互动频率等。
- 评估内容流行度,识别热门趋势和潜在爆款视频。
市场研究:
- 利用爬取的数据来了解目标市场的用户偏好和需求。
- 监测行业动态,分析竞争对手的表现和市场策略。
- 为品牌营销和广告投放提供数据支持,优化推广效果。
在使用短视频爬虫时,以下几点需要特别注意:
- 遵守法律法规:确保爬虫行为符合当地法律法规,不侵犯用户隐私。
- 尊重平台规则:遵循短视频的使用协议,不进行任何可能干扰平台正常运营的行为。
- 数据保护:对采集到的数据负责,采取适当措施保护用户信息不被滥用。
请记住,尽管爬虫技术本身是中性的,但其应用必须建立在合法和道德的基础之上。任何未经授权的数据采集和使用都可能带来法律风险和道德争议。
二、使用步骤
1.引入库
- 在开始编写爬虫之前,需要引入必要的Python库:
import requests
import json
# 其他可能需要的库,例如解析库BeautifulSoup或lxmlrequests是一个常用的 HTTP 库,用于发送 HTTP 请求。json是用于处理 JSON 数据的库,但在您提供的代码中没有直接使用。
2.设置请求头
为了模拟浏览器行为,我们需要设置合适的请求头:
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
}
headers字典包含了一个User-Agent字段,它模拟了一个常见的浏览器用户代理字符串。这有助于防止服务器认为这是一个自动化工具的请求并可能拒绝服务。

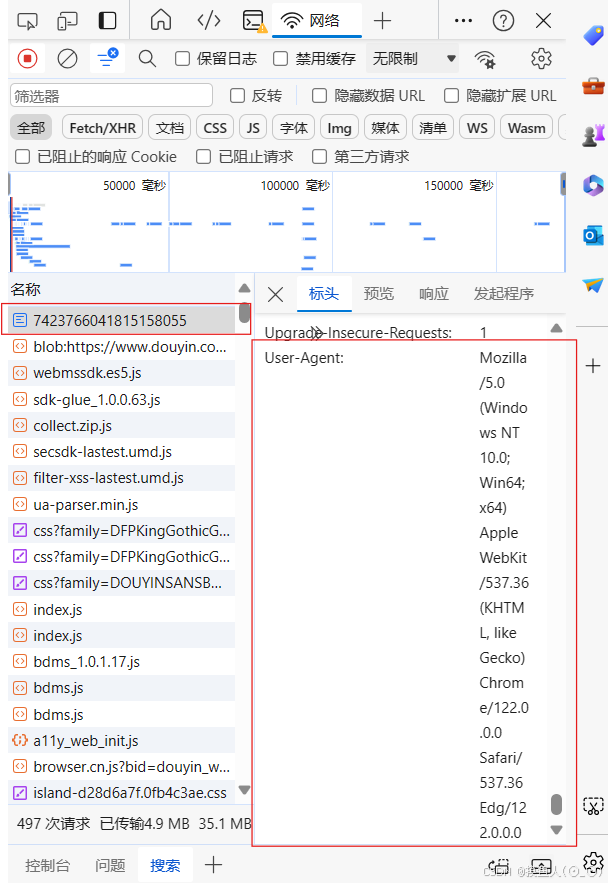
3.定义抖音分享链接
我们将要爬取的短视频视频分享链接存储在一个变量中:
url = "短视频网址链接"
url变量存储了一个短视频视频分享链接。
4.发送 HTTP GET 请求
使用requests库发送GET请求:
r = requests.get(url=url, headers=headers, allow_redirects=False)
- 使用
requests.get()方法发送一个 GET 请求到定义的 URL。 headers=headers参数指定了请求头。allow_redirects=False参数阻止了requests自动处理重定向。这意味着如果服务器返回一个重定向响应(例如状态码 302),requests不会自动跳转到新的 URL。
5.打印响应内容
对服务器响应进行处理,提取所需信息:
print(r.text)
r.text包含了响应的文本内容。由于allow_redirects设置为False,这个文本可能是服务器返回的重定向信息,而不是实际的页面内容。
6.打印响应头部
print(r.headers)
r.headers是一个包含服务器响应头部信息的字典。
7.打印重定向的 Location 头部
if 'Location' in response.headers:
print("重定向的 Location: ", response.headers['Location'])
else:
print("未找到 Location 头部信息,可能没有发生重定向。")
- 如果服务器返回了一个重定向响应,
Location头部将包含新的 URL 地址,即实际的视频页面地址。 -
注意点:
- 如果
Location头部不存在于r.headers中,访问r.headers['Location']将会引发一个KeyError。为了避免这种情况,你应该先检查Location是否存在于r.headers中。 - 短视频等社交媒体平台通常对爬虫有严格的限制,未经授权的爬取可能会违反其服务条款,并可能导致您的 IP 被封禁。
- 短视频的分享链接可能会包含一些加密的参数,直接通过分享链接获取视频内容可能需要解密这些参数。
8.代码示例
以下是一个通用的网络请求示例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0",
}
#抖音分享的连接
url = "短视频网址链接"
# 禁止重定间,设置 allow_redirects=Faise
r = requests.get(url=url, headers=headers, allow_redirects=False)
print(r.text)
print(r.headers)
if 'Location' in r.headers:
print("重定向的 Location: ", r.headers['Location'])
else:
print("没有找到 Location 头部信息,可能是因为没有发生重定向。")
9.运行结果展示
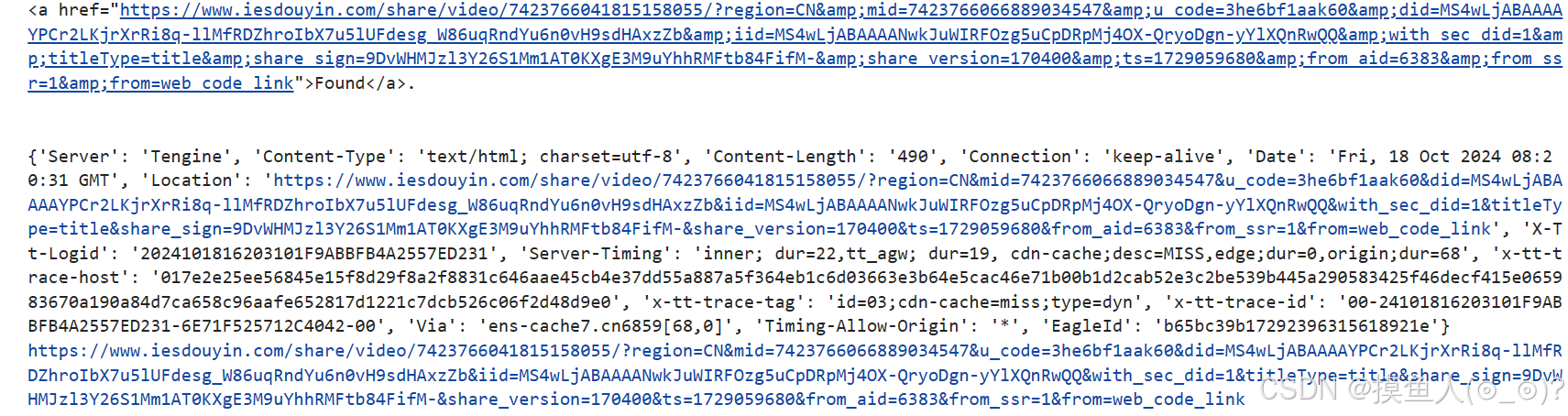
总结
在进行网络数据获取时,以下是一些通用的技巧和注意事项:
-
网络请求
- 模拟浏览器行为:使用真实的 User-Agent。
- 处理重定向:通过设置
allow_redirects=False来捕获重定向信息。 - 异步请求:使用异步库如
aiohttp提高效率。
-
数据解析
- 分析API:通过分析API请求来获取数据。
- JSON解析:使用
json库解析JSON格式数据。 - 正则表达式:用于匹配非结构化数据。
-
防止封禁
- IP代理:使用代理服务器更换IP。
- 限速:设置合理的请求间隔。
- User-Agent池:轮换使用多个 User-Agent。
-
数据存储
- 数据库:将数据存储到数据库中。
- 文件系统:保存文本或图片等数据。
-
功能性技巧
- 登录态维持:处理需要登录才能访问的内容。
- 动态内容加载:使用工具模拟浏览器行为。
-
法律和道德
- 遵守法律:确保行为符合法律法规。
- 尊重隐私:不爬取个人隐私数据。
-
实践中的注意事项
- 异常处理:合理处理网络请求异常。
- 日志记录:记录关键信息便于调试。
示例技巧
- 分析API:通过抓包工具分析API请求。
- 验证码处理:对于验证码问题,考虑合法的解决方案。
最后,开发者应持续关注目标网站的政策更新,并根据实际情况调整策略。任何数据获取行为都应遵循网站的使用协议和相关法律法规。
以上内容已经尽量去除了特定平台的引用,并且强调了合法性和道德性的重要性。在进行爬虫开发时,请确保您的行为符合当地法律法规和网站的服务条款。

















 1442
1442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









