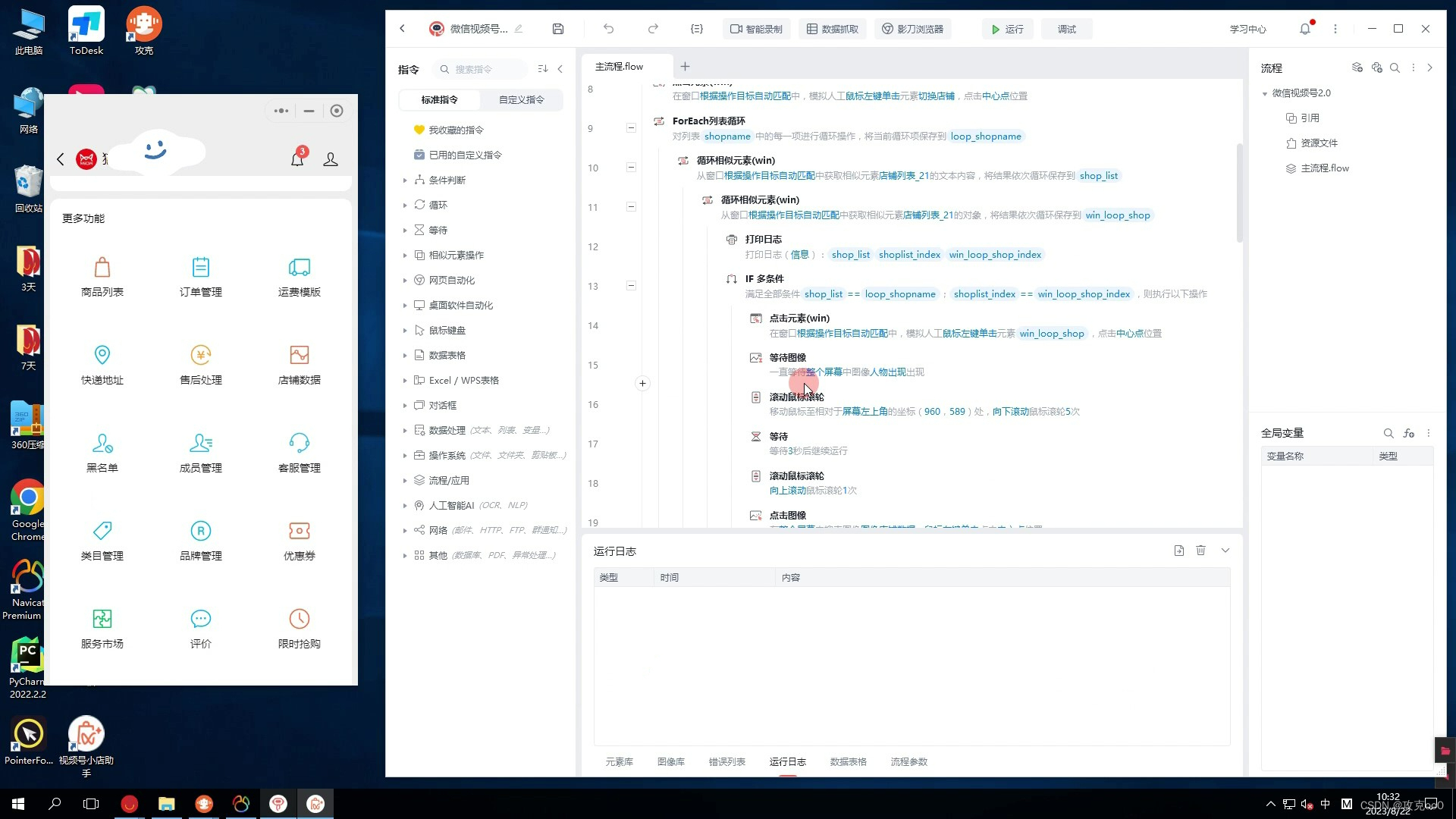
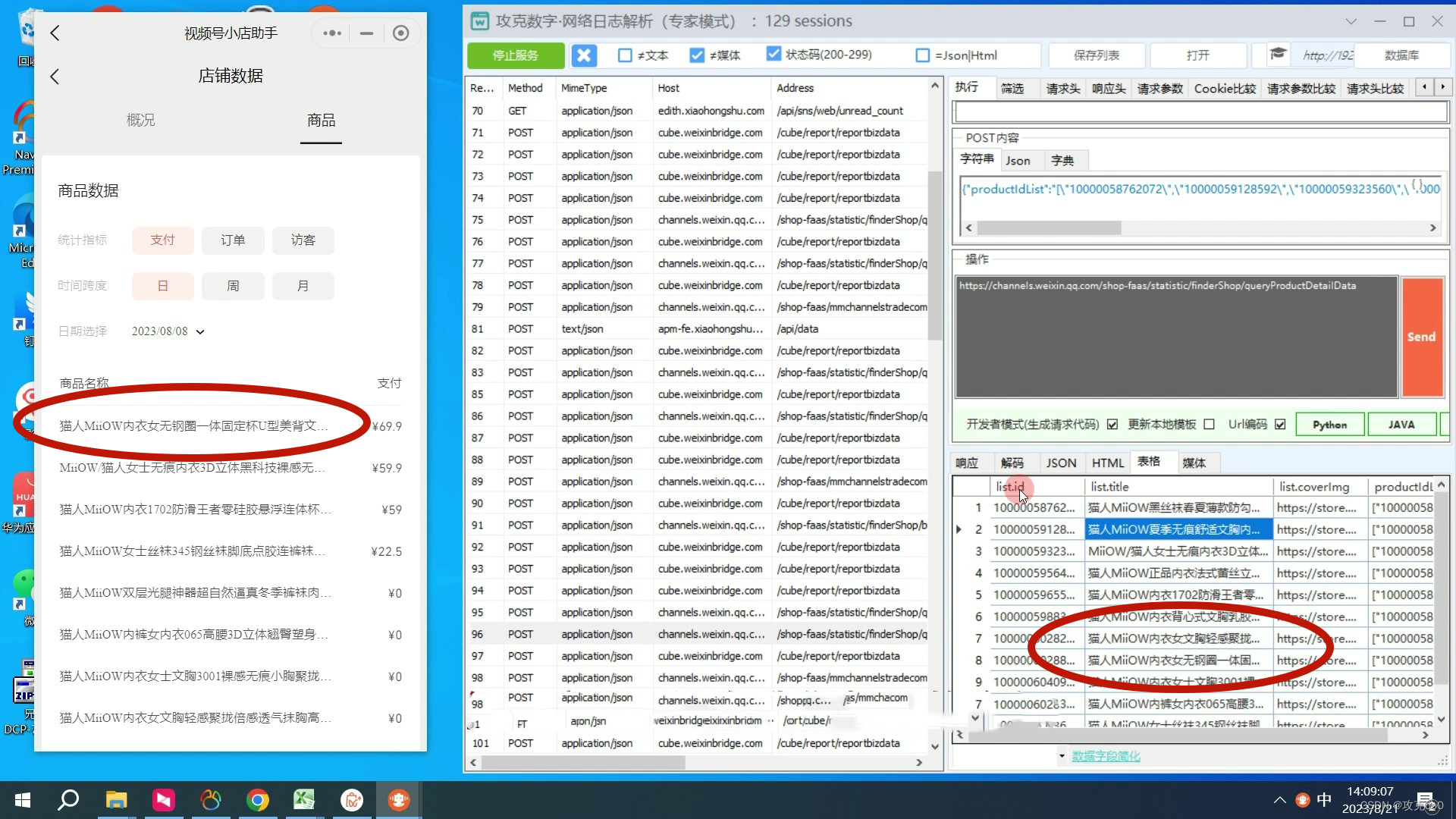
影刀RPA是一款可视化易上手的自动化工具,可以很好的与网页进行交互,下面是一段简单的访问和点击视频号页面的程序: 攻克Data是一款专门解析各类网页日志的工具,经过攻克Data的处理任何复杂凌乱的网页日志可以变成标准的表格数据,没有任何使用门槛只需要同时打开攻克Data和你需要的网页就可: 下载地址:https://www.yuque.com/gk.ai/gkdata/zn5r4grngkk2lidp推荐:GKA496F78CB479347D4F5B3E05892795A5 来看看效果展示:








 本文介绍了影刀RPA这款易于使用的自动化工具,用于与网页交互,演示了访问和操作视频号页面的示例。同时,攻克Data作为强大的网页日志解析工具,能将复杂日志转化为标准表格。两者结合可用于高效采集视频号的商品数据。
本文介绍了影刀RPA这款易于使用的自动化工具,用于与网页交互,演示了访问和操作视频号页面的示例。同时,攻克Data作为强大的网页日志解析工具,能将复杂日志转化为标准表格。两者结合可用于高效采集视频号的商品数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






