






MongoDB副本集群详细操作可以分为以下几个步骤:
1. 安装MongoDB
在所有的复制集节点上安装MongoDB。安装过程取决于你的操作系统,通常可以通过包管理器(如apt或yum)或从官方网站下载二进制包进行安装。
2. 配置MongoDB
每个复制集成员都需要一个配置文件。以下是一个基本的配置文件示例,通常位于/etc/mongod.conf或/usr/local/etc/mongod.conf:
windows环境搭建MongoDB副本集
1. 创建两个mongoDB目录
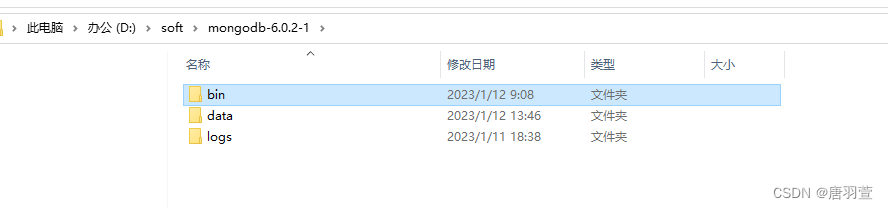
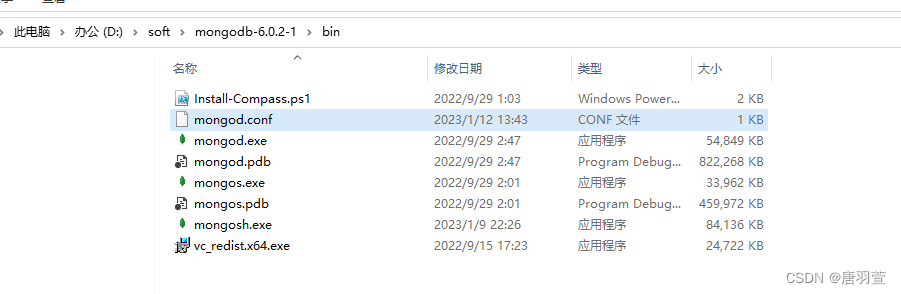
2. 配置相同的副本集名称,不同的端口
#存储
storage:
#数据存储目录 windows这里用斜杠/,不能用反斜杠\
dbPath: "D:/soft/mongodb-6.0.2-2/data"
#journal日志是否开启,默认情况下该日志在最长不超过100ms之后向磁盘写入增量数据
journal:
enabled: true
#网络
net:
#绑定IP,如果此值是‘0.0.0.0’则绑定所有IP
bindIp: localhost,127.0.0.1
#监听端口,默认27017
port: 27019
#副本集
replication:
#副本集名称
replSetName: resGreat
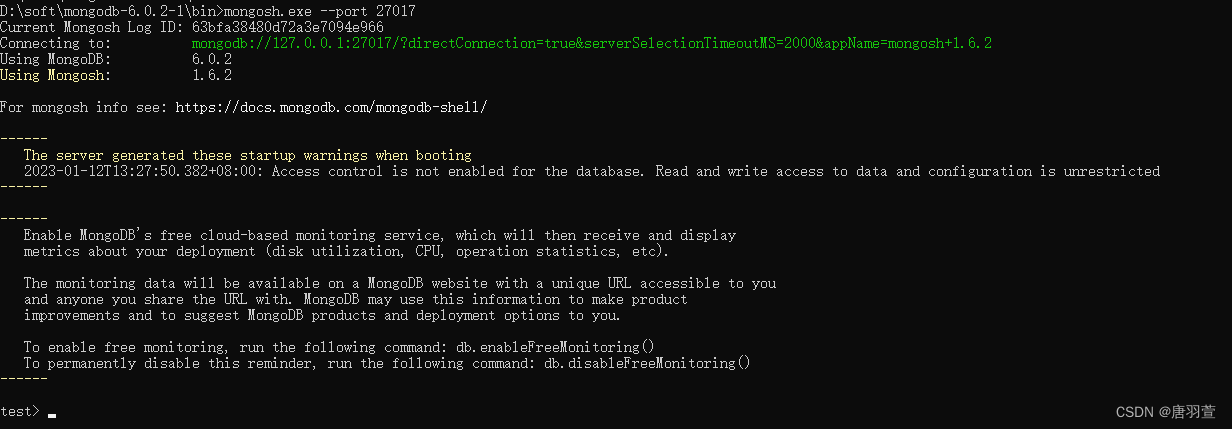
3. 启动两个服务
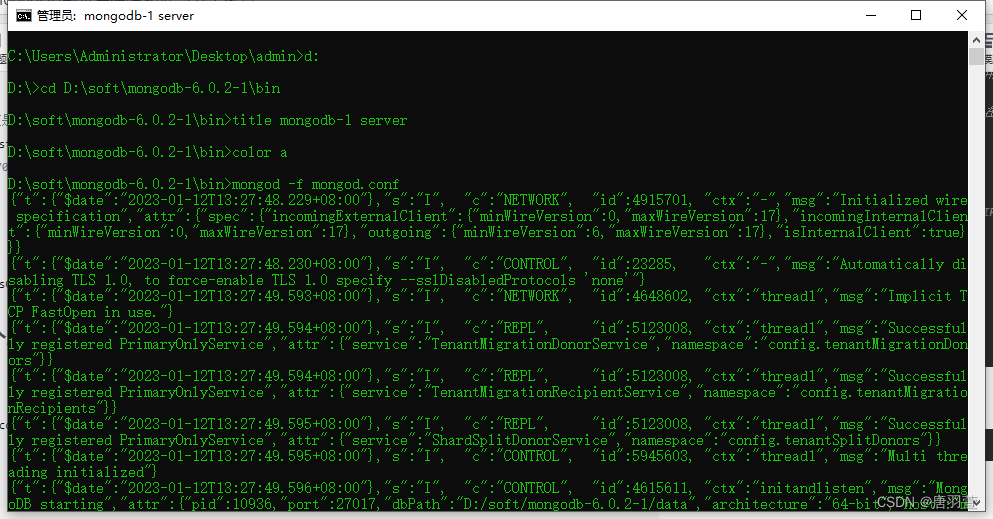
yaml复制代码运行
systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod.log storage: dbPath: /var/lib/mongo journal: enabled: true processManagement: fork: true pidFilePath: /var/run/mongodb/pid net: bindIp: 0.0.0.0 port: 27017 replication: replSetName: "rs0"
注意:确保每个节点的replSetName相同,这是将它们加入到同一个复制集的关键。
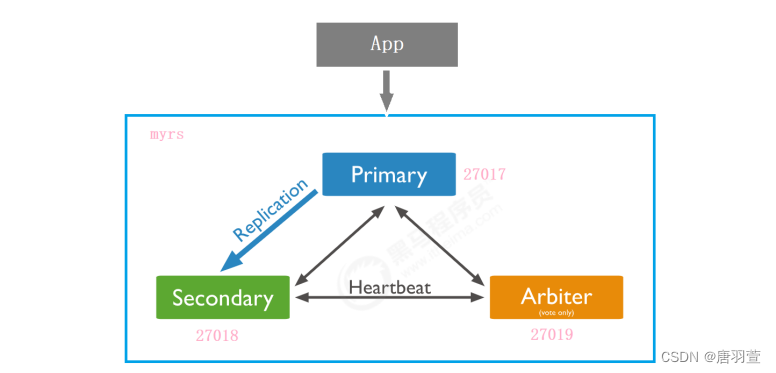
1.2、副本集的三个角色
副本集有两种类型三种角色
两种类型:
主节点(Primary):数据操作的主要连接点,可读写。
次要(辅助、从)节点(Secondaries):数据冗余备份节点,可以读或选举。
三种角色:
主要成员(Primary):主要接收所有写操作。就是主节点。
副本成员(Replicate):从主节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可以读操作(但需要配置)。是默认的一种从节点类型。
仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用
3. 初始化复制集
在其中一个节点上启动mongod实例,并连接到该实例的shell,使用rs.initiate()初始化复制集:
sh复制代码运行
mongo > rs.initiate()
4. 添加复制集成员
在其他节点上启动mongod实例,并将这些节点添加到复制集中:
sh复制代码运行
mongo > rs.add("mongodb://<从节点IP>:27017")
重复此步骤以添加所有节点。
5. 查看复制集状态
执行以下命令查看复制集的状态:
sh复制代码运行
mongo > rs.status()
6. 验证数据同步
在主节点上插入一些数据,然后在从节点上查询,以验证数据是否已同步。
7. 故障切换
如果主节点出现故障,从节点会自动选举新的主节点。你可以在客户端应用程序中设置readPreference为primary、primaryPreferred、secondary、secondaryPreferred、nearest等来控制读取行为。
8. 配置副本集选项
根据需要,可以配置副本集的读写分离、延迟备份等选项。
9. 监控与维护
- 定期检查复制集的状态。
- 确保硬件资源充足,避免磁盘空间不足等问题。
- 监控复制集性能,包括读写延迟和吞吐量。
- 定期备份数据。
- 根据需要进行性能调优。
以上步骤提供了MongoDB副本集群的详细操作指南。在生产环境中部署时,还需要考虑网络配置、安全设置、权限管理等其他因素。
在MongoDB副本集中实现高级读写分离策略,主要涉及到对读取偏好(Read Preference)、写关注(Write Concern)和读关注(Read Concern)的设置。通过调整这些参数可以优化副本集的性能和可靠性,特别是在高负载或对数据一致性有严格要求的环境中。以下将详细介绍如何通过这些设置实现高级的读写分离策略:
- 读取偏好(Read Preference)
- 设置读取偏好:MongoDB提供了几种读取偏好选项,其中包括
primary、primaryPreferred、secondary、secondaryPreferred和nearest。通过在连接字符串中设置readPreference参数,可以控制客户端从哪个成员读取数据。例如,设置为secondaryPreferred会使读取操作优先在从节点进行,从而减轻主节点的负担。 - 应用场景:对于需要高可用读操作的应用,可以使用
secondaryPreferred或nearest模式。这可以确保在主节点不可用时,读操作可以在从节点上继续。
- 设置读取偏好:MongoDB提供了几种读取偏好选项,其中包括
- 写关注(Write Concern)
- 配置写关注:写关注决定了写入操作的确认方式。通过设置
w参数来确认写入操作被复制到指定数量的节点后才返回成功。例如,设置w: "majority"可以确保数据被写入大多数节点。此外,设置j: true确保数据被写入到日志中,从而在发生故障时可以恢复。 - 应用场景:在对数据安全性要求较高的场景下,建议使用
w: "majority"和j: true的组合,以确保数据的安全和可恢复性。
- 配置写关注:写关注决定了写入操作的确认方式。通过设置
- 读关注(Read Concern)
- 配置读关注:读关注帮助客户端处理可能的数据不一致问题。例如,使用
local读关注级别是默认设置,不保证客户读取的数据最新;而linearizable则提供最强的一致性保证,但可能会影响性能。 - 应用场景:在金融或交易类应用中,为了确保读到的数据绝对一致,可以考虑使用
linearizable读关注级别,即使这可能会稍微影响性能。
- 配置读关注:读关注帮助客户端处理可能的数据不一致问题。例如,使用
- 使用标签进行读取优化
- 配置节点标签:可以为副本集中的不同节点设置标签,然后在读取偏好中指定这些标签,从而控制读操作的目标节点。这种方法特别适用于地理位置分散的副本集,可以将读操作定向到最近的节点。
- 应用场景:在全球化部署的应用中,为不同地理位置的副本设置标签,并通过读取偏好中的
tags选项来优化读取路径,降低延迟。
- 高级副本集管理
- 监控与维护:定期检查副本集的同步状态和性能指标。使用如MongoDB Atlas等工具可以方便地监控数据同步状态、延迟和性能。
- 数据一致性检查:定期进行数据一致性检查,确保主节点和从节点之间的数据没有差异。这可以通过自定义脚本或使用专业的数据库管理工具来实现。
综上所述,通过合理配置读取偏好、写关注、读关注以及利用标签优化读取路径,可以在MongoDB副本集中实现高级的读写分离策略。这不仅提高了系统的可用性和性能,还确保了数据的一致性和安全性。在实施这些策略时,还需要持续监控和调整配置,以适应不断变化的业务需求和技术环境。















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









