






Python中的表格对象通常使用pandas库中的DataFrame类来实现。pandas是一个强大的数据处理和分析库,提供了丰富的功能来处理结构化数据。本文将详细介绍如何使用pandas库实现表格对象的操作,包括创建、读取、写入、查询、筛选、排序、分组、统计等操作。
- 安装pandas库
首先,确保已经安装了pandas库。如果没有安装,可以使用以下命令进行安装:
pip install pandas- 导入pandas库
在Python代码中,需要先导入pandas库,然后才能使用其中的DataFrame类。
import pandas as pd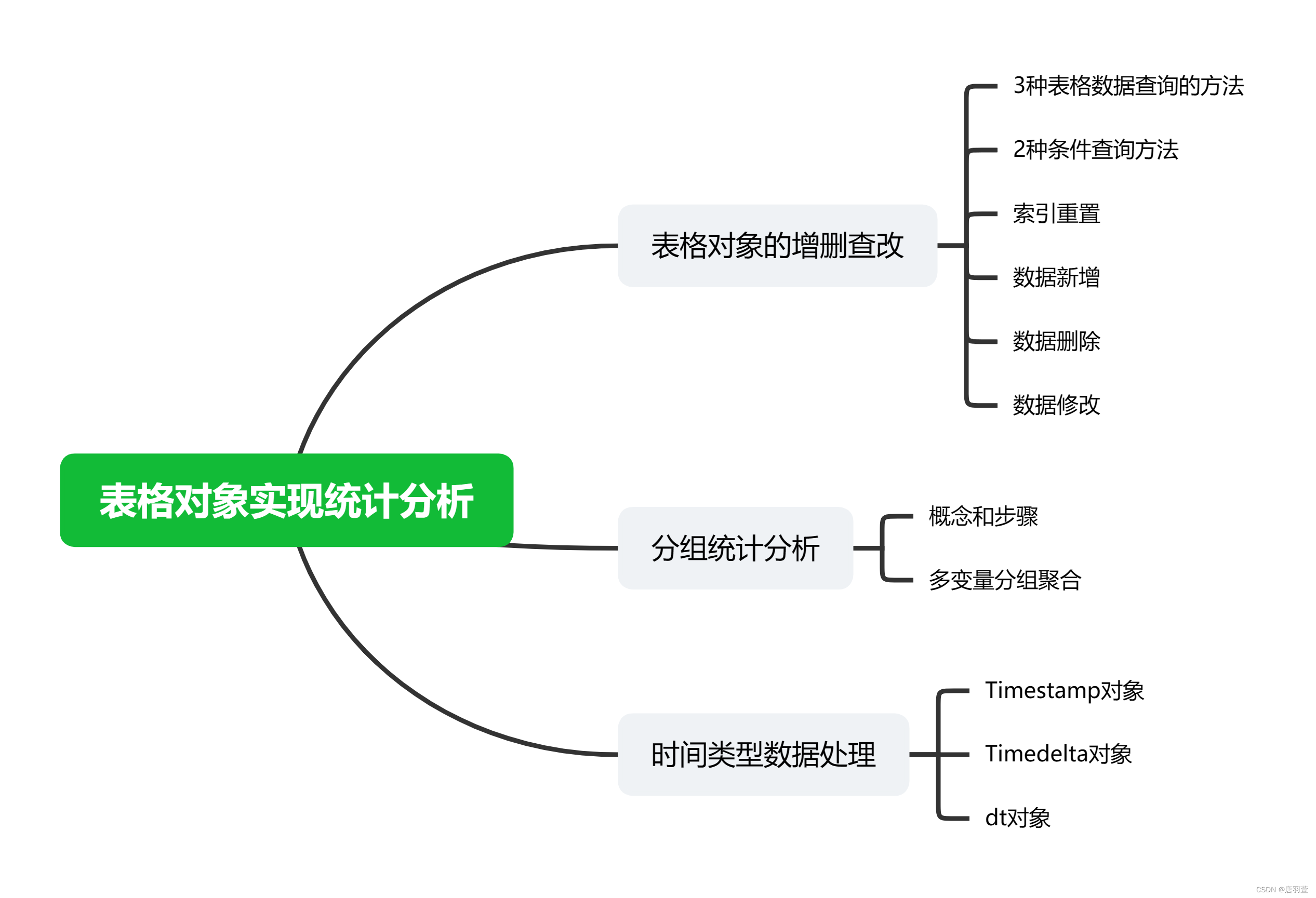 1.创建表格对象
1.创建表格对象
可以使用字典、列表、numpy数组等数据结构来创建表格对象。以下是一些创建表格对象的例子:
# 使用字典创建表格对象
data = {'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'gender': ['F', 'M', 'M']}
df = pd.DataFrame(data)
# 使用列表创建表格对象
data = [['Alice', 25, 'F'],
['Bob', 30, 'M'],
['Charlie', 35, 'M']]
columns = ['name', 'age', 'gender']
df = pd.DataFrame(data, columns=columns)
# 使用numpy数组创建表格对象
import numpy as np
data = np.array([['Alice', 25, 'F'],
['Bob', 30, 'M'],
['Charlie', 35, 'M']])
df = pd.DataFrame(data, columns=['name', 'age', 'gender'])- 读取表格数据
pandas库支持从多种文件格式(如CSV、Excel、SQL数据库等)读取表格数据。以下是一些读取表格数据的例子:
# 读取CSV文件
df = pd.read_csv('data.csv')
# 读取Excel文件
df = pd.read_excel('data.xlsx')
# 读取SQL数据库
import sqlite3
conn = sqlite3.connect('data.db')
df = pd.read_sql_query('SELECT * FROM table_name', conn)- 写入表格数据
pandas库支持将表格数据写入多种文件格式(如CSV、Excel、SQL数据库等)。以下是一些写入表格数据的例子:
# 写入CSV文件
df.to_csv('data.csv', index=False)
# 写入Excel文件
df.to_excel('data.xlsx', index=False)
# 写入SQL数据库
import sqlite3
conn = sqlite3.connect('data.db')
df.to_sql('table_name', conn, if_exists='replace', index=False)- 查询表格数据
可以使用列名、行索引或者条件表达式来查询表格数据。以下是一些查询表格数据的例子:
# 查询指定列的数据
print(df['name'])
# 查询指定行的数据
print(df.loc[0])
# 使用条件表达式查询数据
print(df[df['age'] > 30])- 筛选表格数据
可以使用布尔索引、条件表达式或者函数来筛选表格数据。以下是一些筛选表格数据的例子:
# 使用布尔索引筛选数据
print(df[df['gender'] == 'F'])
# 使用条件表达式筛选数据
print(df[(df['age'] > 30) & (df['gender'] == 'M')])
# 使用函数筛选数据
def filter_func(row):
return row['age'] > 30 and row['gender'] == 'M'
print(df[df.apply(filter_func, axis=1)])- 排序表格数据
可以使用列名对表格数据进行升序或降序排序。以下是一些排序表格数据的例子:
# 按照年龄升序排序
print(df.sort_values(by='age'))
# 按照年龄降序排序
print(df.sort_values(by='age', ascending=False))- 分组表格数据
可以使用一列或多列对表格数据进行分组。以下是一些分组表格数据的例子:
# 按照性别分组
grouped = df.groupby('gender')
print(grouped.mean()) # 计算每个分组的平均值
# 按照多列分组
grouped = df.groupby(['gender', 'age'])
print(grouped.size()) # 计算每个分组的大小- 统计表格数据
可以使用pandas库提供的统计函数对表格数据进行统计分析。以下是一些统计表格数据的例子:
# 计算各列的总和、平均值、最小值、最大值等统计信息
print(df.describe())
# 计算指定列的统计信息
print(df['age'].mean()) # 计算年龄的平均值数据的增删改查
1.增加数据
import pandas as pd
# 创建一个空的DataFrame
df = pd.DataFrame()
# 添加一行数据
df.loc[0] = ['张三', 25, '男']
# 添加一列数据
df['城市'] = ['北京', '上海', '广州']2.删除数据
# 删除一行数据
df.drop(0, inplace=True)
# 删除一列数据
df.drop('城市', axis=1, inplace=True)3.查询数据
# 查询某一行数据
row_data = df.loc[0]
# 查询某一列数据
col_data = df['年龄']
# 查询某个单元格数据
cell_data = df.at[0, '年龄']4.修改数据
# 修改某一行数据
df.loc[0] = ['李四', 30, '女']
# 修改某一列数据
df['年龄'] = [26, 27, 28]
# 修改某个单元格数据
df.at[0, '年龄'] = 29分组统计
1.首先,导入pandas库并创建一个DataFrame:
import pandas as pd
data = {'Category': ['A', 'B', 'A', 'B', 'A', 'B', 'A', 'A'],
'Value': [10, 20, 30, 40, 50, 60, 70, 80]}
df = pd.DataFrame(data)2.使用groupby()函数对数据进行分组:
grouped = df.groupby('Category')3.对分组后的数据进行统计分析,例如计算每个组的平均值、求和、计数等:
mean = grouped.mean()
sum = grouped.sum()
count = grouped.count()4.输出结果:
print("Mean:")
print(mean)
print("Sum:")
print(sum)
print("Count:")
print(count)
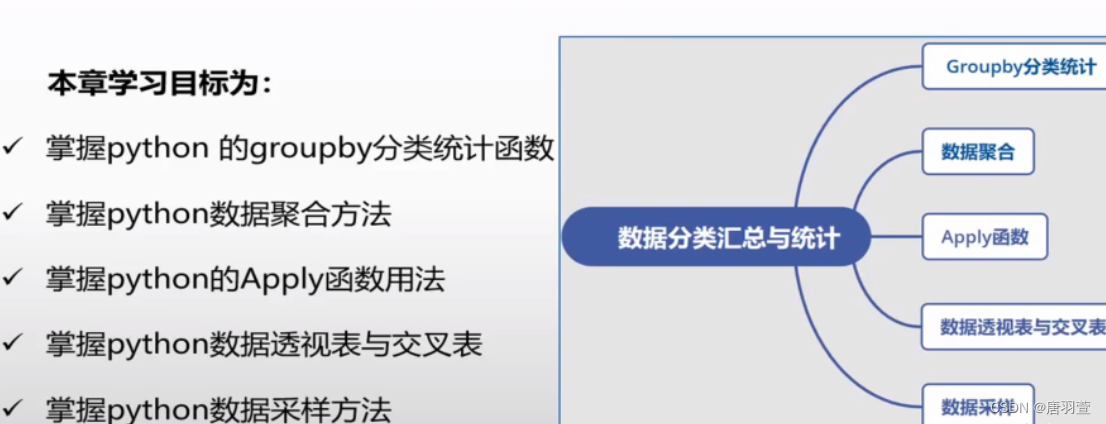
总结:本文详细介绍了如何使用pandas库实现表格对象的操作,包括创建、读取、写入、查询、筛选、排序、分组、统计等操作。通过掌握这些操作,可以方便地处理和分析结构化数据。
数据可视化
数据可视化是一个将数据转换为图形或图像的过程,它旨在帮助用户更好地理解、分析和解释数据。在Python和JavaScript中,有多个强大的库可以用于创建各种类型的数据可视化。以下是一些常用的工具和方法:
- 使用Python进行数据可视化
- Pandas:Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。Pandas 的主要数据结构包括 Series(一维数据)和 DataFrame(二维数据),适用于处理与 Excel 表类似的表格数据以及有序和无序的时间序列数据。
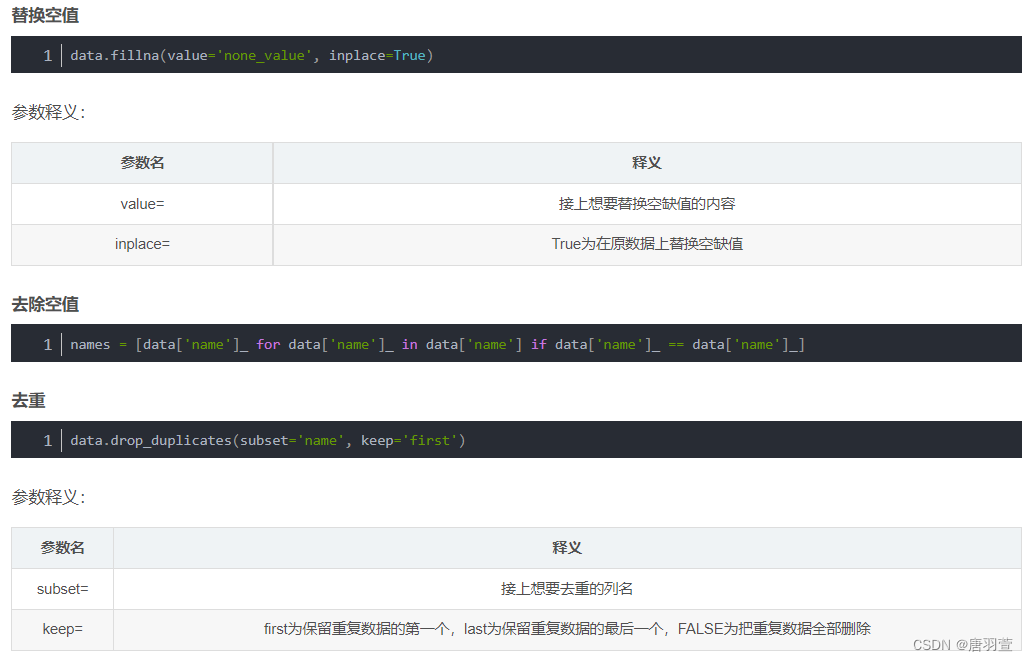
- 数据整理与清洗:使用 Pandas 的
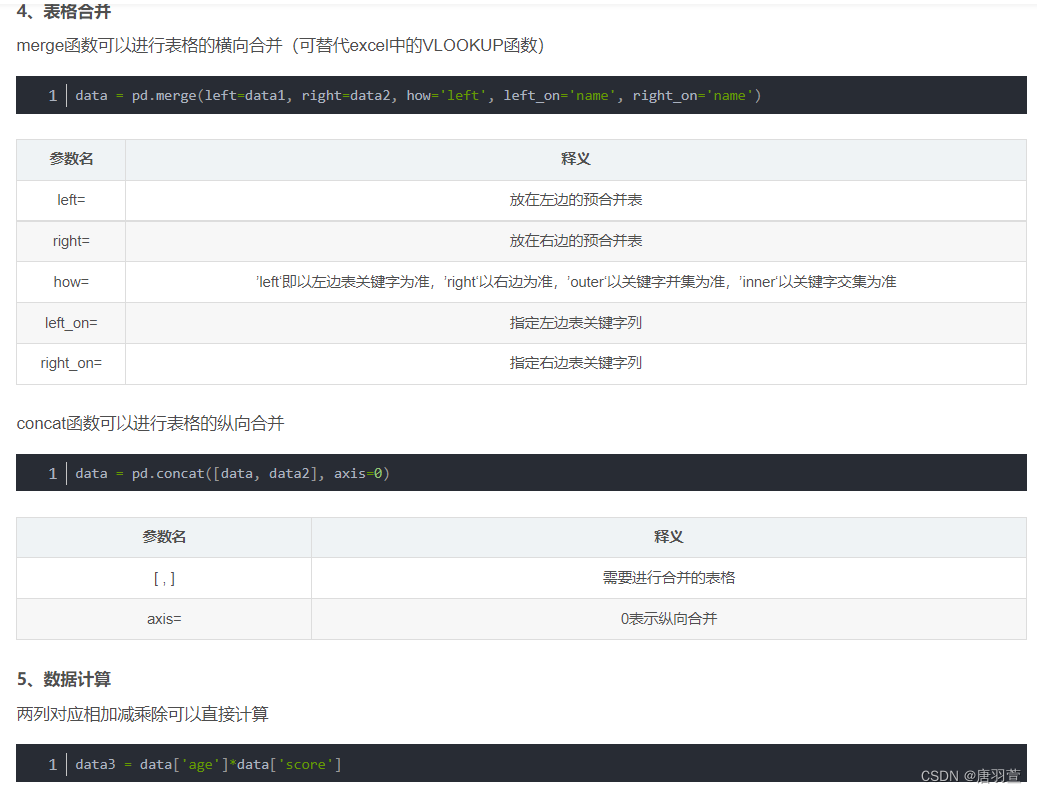
drop,fillna,replace等函数对数据进行预处理。 - 数据分析与建模:通过 Pandas 提供的各类统计方法和数据处理功能,例如
groupby,merge,pivot等,可以进行复杂的数据分析和建模操作。 - 数据可视化与制表:Pandas 内置了绘图功能,可以使用
plot方法生成多种类型的图表,例如条形图、饼图、直方图、散点图等。
- 数据整理与清洗:使用 Pandas 的
- Matplotlib:Matplotlib 是一个 Python 2D绘图库,可用于生成高质量的图形。其接口类似于 MATLAB,并且可以通过简单的代码生成多种类型的图表。
- 基本绘图:使用 Matplotlib 的
pyplot模块可以快速生成图表,只需几行代码即可创建直方图、功率谱、条形图、误差图、散点图等。 - 高级调整:对于高级用户,Matplotlib 提供了面向对象的接口,可以完全控制线型、字体属性、轴属性等,使得图表更加美观和专业。
- 基本绘图:使用 Matplotlib 的
- Seaborn:Seaborn 是基于 Matplotlib 的一个高级绘图库,专门用于统计图形的绘制。它提供了更高级的接口,更容易地创建美观和信息丰富的图表。
- 高级统计图形:Seaborn 支持多种复杂的统计图形,如时间序列图、回归图、分类散点图、多元分布图等。
- 美学风格:Seaborn 提供了多种预设的美学风格,可以快速应用于图表,使其看起来更加漂亮和专业。
- Pyecharts:Pyecharts 是一个用于生成Echarts图表的库。Echarts 是一个使用 JavaScript 实现的开源可视化库,而 Pyecharts 可以在 Python 中使用 Echarts 的功能。
- 多样化图表类型:Pyecharts 支持多种图表类型,包括折线图、柱状图、散点图、饼图、K线图、热力图、地图等。
- 易于集成:Pyecharts 可以很容易地与其他 Python 数据可视化库结合使用,并且可以将图表集成到Web应用中。
- Pandas:Pandas 是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构。Pandas 的主要数据结构包括 Series(一维数据)和 DataFrame(二维数据),适用于处理与 Excel 表类似的表格数据以及有序和无序的时间序列数据。
- 使用JavaScript进行数据可视化
- ECharts介绍:ECharts 是一个使用 JavaScript 实现的开源可视化库,可以流畅地运行在 PC 和移动设备上,兼容当前绝大部分浏览器。
- 底层依赖:ECharts 底层依赖矢量图形库 ZRender,提供直观、交互丰富、可高度个性化定制的数据可视化图表。
- 多平台兼容:ECharts 兼容多种设备,可在 PC 和移动设备上流畅运行,并支持 IE8/9/10/11、Chrome、Firefox、Safari 等多种浏览器。
- 提供多种图表类型:ECharts 提供了丰富的图表类型和交互能力,包括折线图、柱状图、散点图、饼图、雷达图、地图等。
- ECharts入门教程:ECharts 的使用相对简单,官方提供了详细的教程和示例,可以快速上手。
- 下载和引入文件:首先需要下载 ECharts 文件并将其引入到项目中。
- 编写HTML代码:在HTML文件中创建一个有大小的 DOM 容器用于存放图表。
- 初始化实例对象:使用
echarts.init方法初始化一个 ECharts 实例对象。 - 指定配置项和数据:通过配置项指定图表的各种设置,例如标题、提示框、图例、轴、系列等。
- 显示图表:使用
setOption方法将配置项设置给 ECharts 实例对象,即可显示图表。
- ECharts基础配置:了解 ECharts 的基础配置是必要的,这有助于根据需求调整图表的设置。
- 主要配置项:包括
series(系列定义图表类型)、xAxis(X轴设置)、yAxis(Y轴设置)、grid(网格设置)、tooltip(提示框设置)、title(标题设置)、legend(图例设置)和color(颜色设置)等。 - 系列列表:每个系列通过
type决定图表类型,可以在同一个图表中重叠多个系列。 - 坐标轴设置:通过边界留白策略、刻度、标签等调整坐标轴的显示。
- 网格设置:设置直角坐标系内绘图网格的大小和位置。
- 提示框和标题:用于增强用户体验,提供鼠标悬停提示和标题展示。
- 图例设置:定义图表中哪些部分需要在图例中显示。
- 颜色设置:指定调色盘中的颜色列表,用于不同数据系列着色。
- 主要配置项:包括
- 案例讲解:通过修改官方示例来熟悉配置项是一种很好的学习方法。例如,可以通过调整堆叠折线图的配置来观察不同参数对图表的影响。
- ECharts介绍:ECharts 是一个使用 JavaScript 实现的开源可视化库,可以流畅地运行在 PC 和移动设备上,兼容当前绝大部分浏览器。
综上所述,详细介绍了如何使用 Python 和 JavaScript 进行数据可视化的方法和步骤。在使用这些工具时,还需要注意以下几点以提高可视化的效果和效率:
- 数据准备:在进行数据可视化之前,确保数据已经清洗和预处理完成。这包括填充缺失值、去除异常值、格式化数据等。良好的数据准备是生成有意义可视化的前提。
- 选择合适的图表类型:不同的图表类型适合展示不同类型的数据关系。例如,时间序列数据适合用折线图展示,而类别数据更适合用柱状图或饼图展示。选择合适的图表可以更有效地传达信息。
- 优化视觉呈现:调整图表的颜色、字体、图例等元素,使得图表更加美观和易于理解。同时,避免过多的装饰和不必要的复杂性,保持图表的简洁性。
- 交互式探索:在可能的情况下,使用支持交互功能的库,如 ECharts,可以增加用户的参与度,帮助用户更好地理解数据背后的规律。















 1472
1472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









