






目录
引言
我们将介绍Seaborn的基本绘图功能,包括如何加载数据、设置图形参数以及使用Seaborn的不同绘图函数。我们将通过具体的示例和代码,展示如何使用Seaborn绘制散点图、箱线图、热力图等常见的图形类型,并探讨如何通过Seaborn的样式和调色板选项来定制图形的外观。
Matplotlib 网格线
参数说明:
- b:可选,默认为 None,可以设置布尔值,true 为显示网格线,false 为不显示,如果设置 **kwargs 参数,则值为 true。
- which:可选,可选值有 'major'、'minor' 和 'both',默认为 'major',表示应用更改的网格线。
- axis:可选,设置显示哪个方向的网格线,可以是取 'both'(默认),'x' 或 'y',分别表示两个方向,x 轴方向或 y 轴方向。
- **kwargs:可选,设置网格样式,可以是 color='r', linestyle='-' 和 linewidth=2,分别表示网格线的颜色,样式和宽度。
以下实例添加一个简单的网格线,参数使用默认值:

显示结果如下:
安装 Seaborn:

Seaborn 提供了多种内置主题和颜色调色板,可以通过设置来改变图形的外观。

通过设置 sns.set_theme() 函数,可以选择不同的主题和模板,以下是 Seaborn 内置的一些主题和模板:
主题(Theme)
darkgrid(默认):深色网格主题。

whitegrid:浅色网格主题。

dark:深色主题,没有网格。

white:浅色主题,没有网格。

ticks:深色主题,带有刻度标记。

模板(Context)
paper:适用于小图,具有较小的标签和线条。

notebook(默认):适用于笔记本电脑和类似环境,具有中等大小的标签和线条。

talk:适用于演讲幻灯片,具有大尺寸的标签和线条。

poster:适用于海报,具有非常大的标签和线条。

通过设置不同的主题和模板,可以调整 Seaborn 图形的大小、线条的粗细、颜色等属性,以适应不同的绘图场景。这些内置的主题和模板使得用户能够更轻松地创建美观且具有一致性的图形。
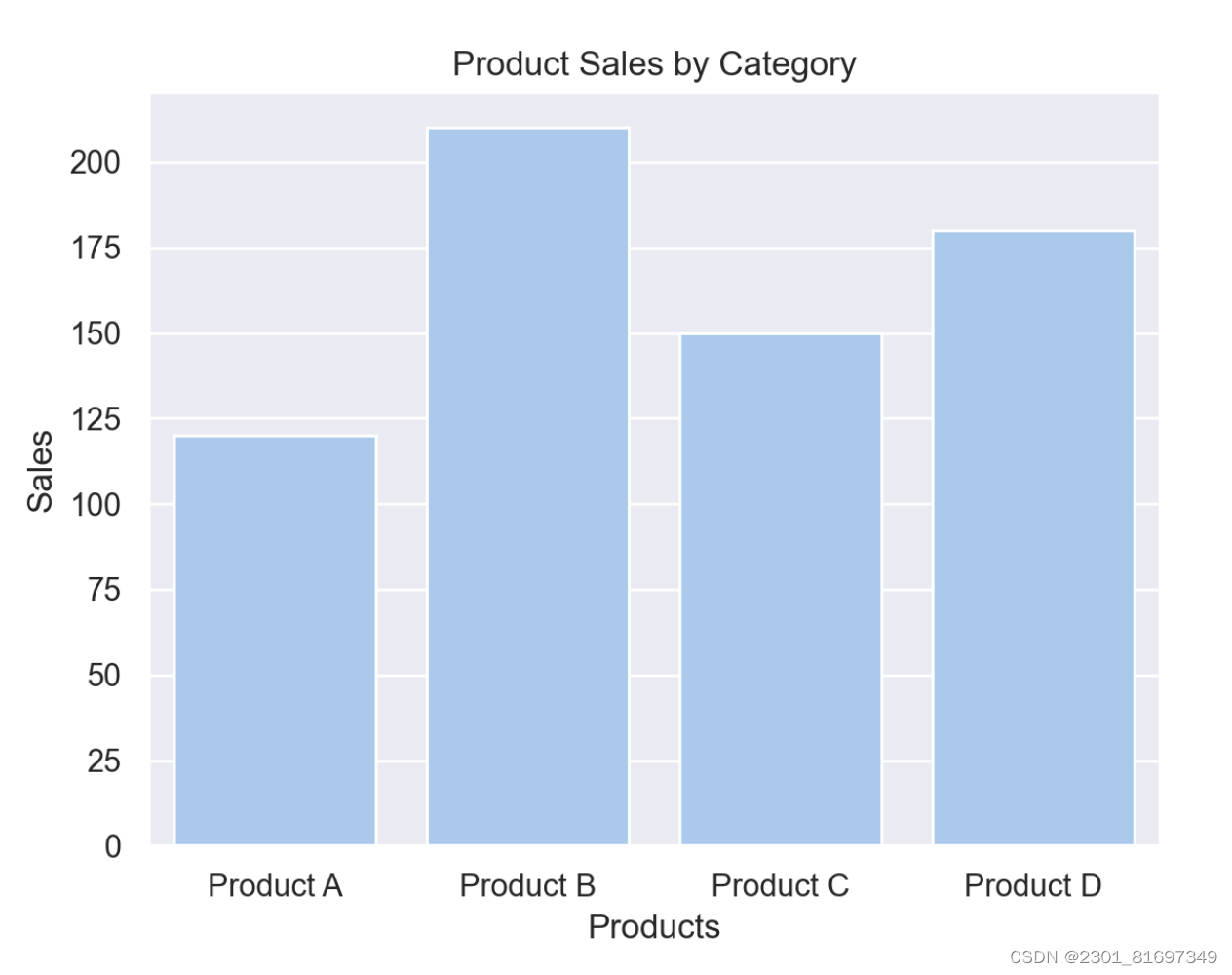
以下实例使用 Seaborn 和 Matplotlib 绘制了一个简单的柱状图,用于展示不同产品的销售情况:

结果如下图所示:
绘图函数
Seaborn 提供了多个绘图函数,用于创建各种统计图形,以下是 Seaborn 主要的几个绘图函数及相应的实例:
一、关系图
1、绘制散点图
用于绘制两个变量之间的散点图,可选择添加趋势线。
- 定义:散点图是一种使用点的集合来表示两个变量之间关系的图形。每个点代表一个观测值,其中x轴表示一个变量,y轴表示另一个变量。
- 用途:
- 展示变量之间的相关性:通过散点图中点的分布趋势,可以观察两个变量之间是否存在正相关、负相关或没有相关性的关系。
- 识别数据中的模式:散点图可以帮助识别数据中的趋势、集群或异常值。
- 预测建模:在回归分析中,散点图可以用于初步探索自变量和因变量之间的关系,为选择合适的回归模型提供依据。
绘制散点图代码如下:
 运行结果如下:
运行结果如下:
2、绘制线图
用于绘制变量随着另一个变量变化的趋势线图。
定义
线图是一种用线段的升降来表示数值大小变化的图形。在线图中,通常横轴代表时间或其他连续性变量,纵轴代表统计指标。线图能够清晰地展示数据的变化趋势,帮助人们快速理解数据的动态变化。
绘制简单的线图代码如下:

运行结果如下:
二、分类图
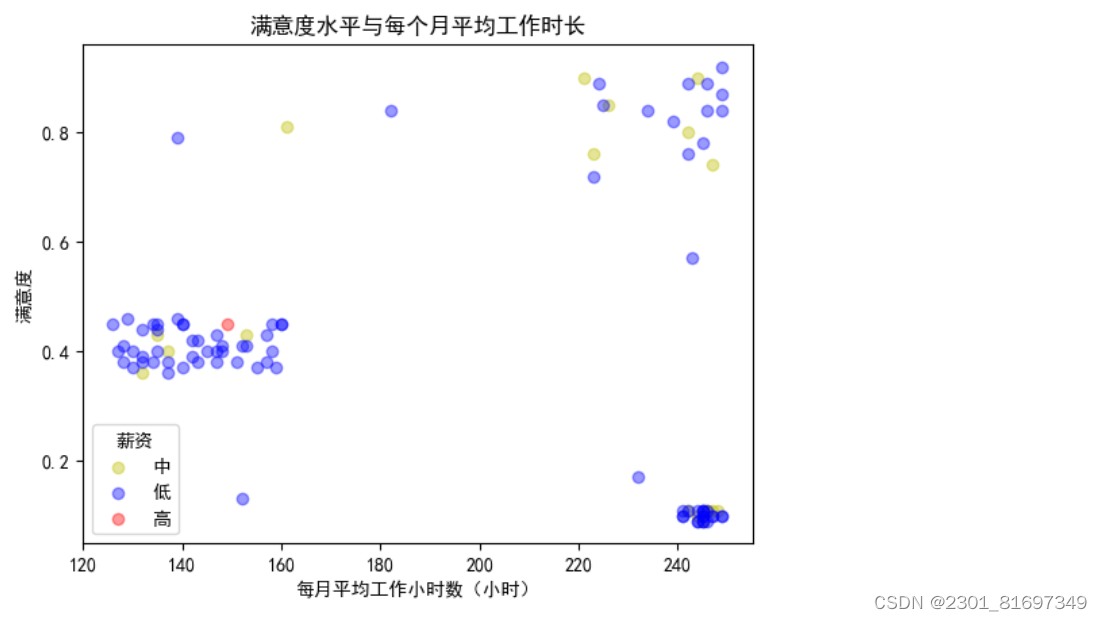
1、分类散点图
- 函数说明:
stripplot()函数用于绘制分类散点图。- 它将数据点沿着分类轴(通常是x轴)分布,并根据分类变量的值进行散开,以避免重叠。
- 适用于小型数据集或分类变量的取值不太密集的情况。
绘制分类散点图代码如下:

运行结果如下:
2、分布图
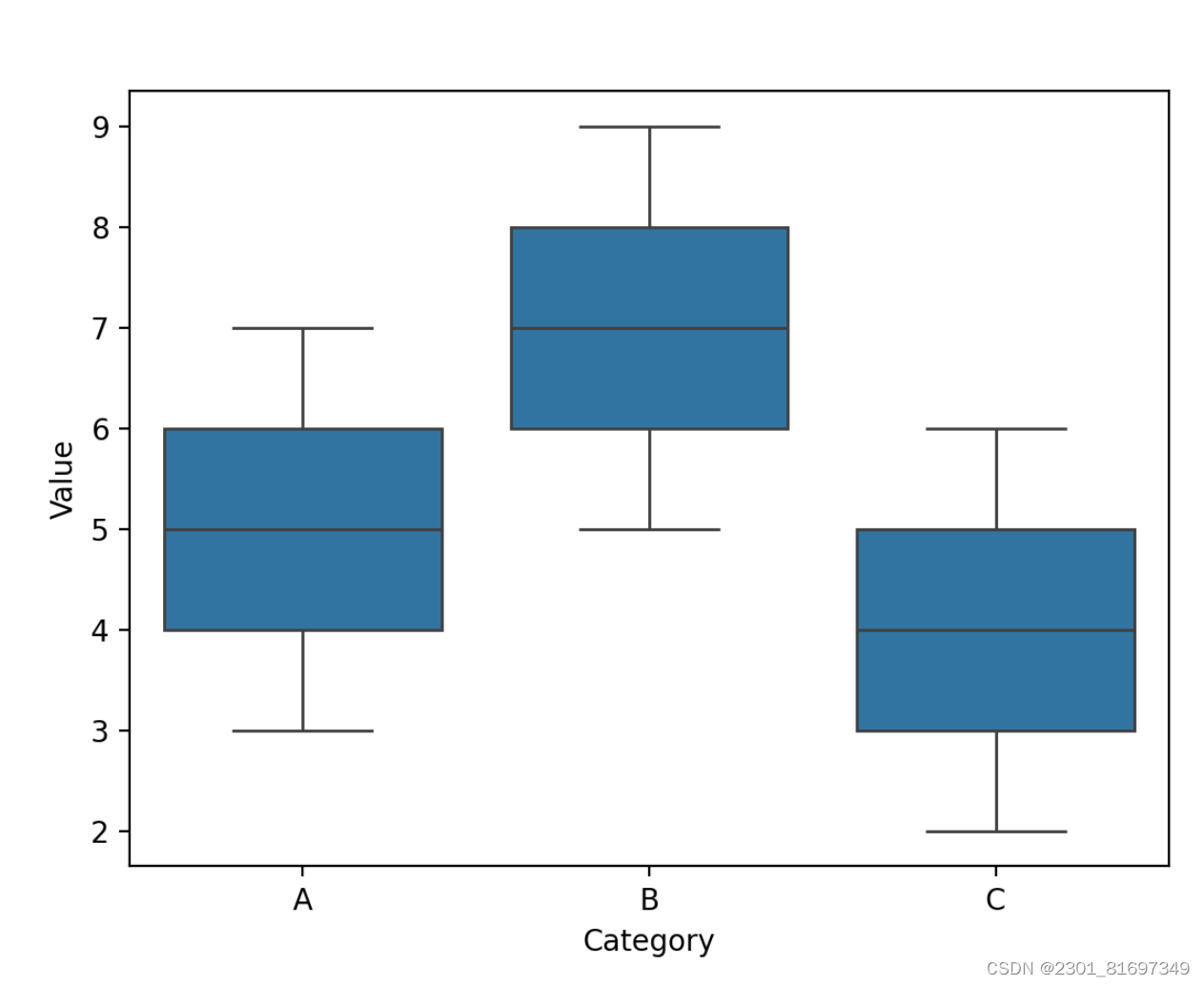
(1)绘制箱线图
用于绘制变量的分布情况,包括中位数、四分位数等。
- 特点:
- 箱线图能够清晰展示数据的中心位置(中位数)、分散程度(箱体长度)、以及数据的分布形状和对称性。
- 箱线图可以很容易地识别出异常值。
- 用途:
- 展示数据的集中趋势:箱线图的中位数可以反映数据的集中趋势。
- 展示数据的分散程度:箱体的长度(即Q3与Q1的间距)展示了数据的分散程度,箱体长度越长,说明数据越分散。
- 显示异常值:箱线图延伸出去的须表示正常范围内的最大值与最小值,超出正常范围的数据点则是异常值。
- 显示数据的对称性与偏态:箱体的对称性可以反映数据的对称性,而须线长短不一或箱体偏斜则可能表示数据分布呈现偏态。
绘制箱线图代码如下:

运行结果如下:
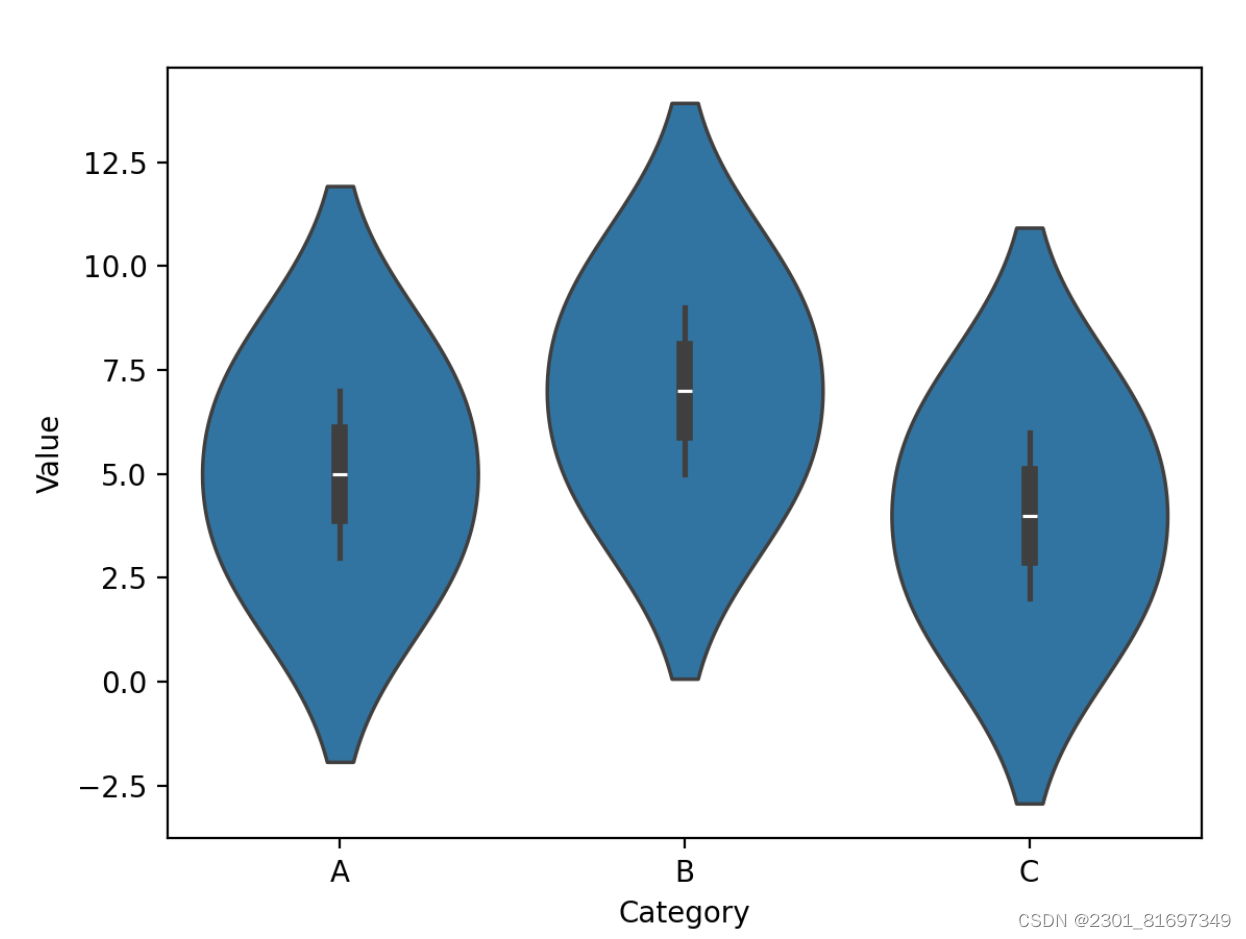
(2)绘制小提琴图
用于显示分布的形状和密度估计,结合了箱线图和核密度估计。
- 定义:小提琴图是一种结合了箱线图和核密度图的数据可视化方法,用于展示多组数据的分布状态以及概率密度。
- 用途:
- 数据分布比较/多变量分析:通过观察小提琴图的形状、宽度和长度,可以比较不同组别或类别的数据分布,直观了解数据密度和范围,发现其中的差异性和相似性。
- 异常值检测:快速识别数据集中的异常值或离群点,为后续分析处理提供指导。
- 探索因素影响:研究一个因素对另一个因素的影响。按一个因素分组,观察另一个因素的小提琴图,了解两者之间的关系和影响。
- 时间序列分析:适用于观察随时间变化的数据分布。通过比较不同时间点的数据分布,识别趋势和模式。
绘制小提琴图代码如下:

运行结果如下:
三、分布图
1、直方图
绘制直方图或核密度估计图,用于展示数据的分布。
- 函数说明:
histplot()函数用于绘制直方图,它可以展示连续变量的分布情况。- 它提供了多种参数来调整直方图的外观和行为,包括颜色、条形样式、数据点的重叠等。
绘制直方图代码如下:
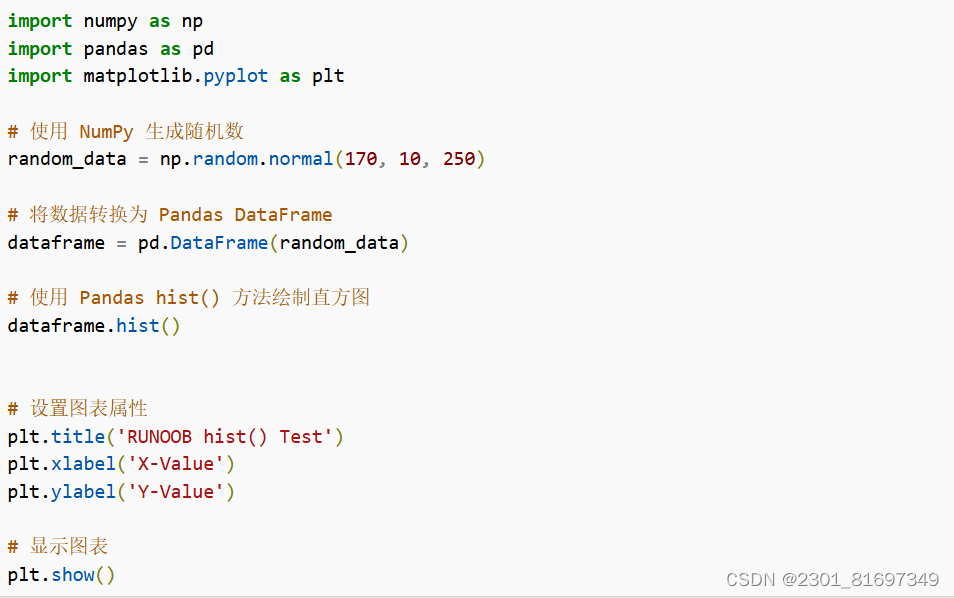
运行结果如下:
2、kdeplot(核密度图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。具体用法如下:
1、seaborn.kdeplot(data, data2=None, shade=False, vertical=False, kernel='gau',
2、bw='scott', gridsize=100, cut=3, clip=None, legend=True, cumulative=False,
3、shade_lowest=True, cbar=False, cbar_ax=None, cbar_kws=None, ax=None, **kwargs)
data、data2:表示可以输入双变量,绘制双变量核密度图;
shade:是否填充阴影,默认不填充;
vertical:放置的方向,如果为真,则观测值位于y轴上(默认False,x轴上);
kernel:{‘gau’ | ‘cos’ | ‘biw’ | ‘epa’ | ‘tri’ | ‘triw’ }。默认高斯核(‘gau’)二元KDE只能使用高斯核。至于什么是核函数,这个学问就大了,建议多看看论文;
bw:{‘scott’ | ‘silverman’ | scalar | pair of scalars }。四类核密度带方法,默认scott (斯考特带宽法),建议下来了解一下这四种方法的区别;
gridsize:这个参数指的是每个格网里面,应该包含多少个点,越大,表示格网里面的点越多(觉得电脑OK的可以试试,有惊喜),越小表示格网里面的点越少;
cut:参数表示,绘制的时候,切除带宽往数轴极限数值的多少,这个参数可以配合bw参数使用;
cumulative:是否绘制累积分布;
shade_lowest:是否有最低值渲染,这个参数只有在二维密度图上才有效;
clip:表示查看部分结果,是一个区间;
cbar:参数若为True,则会添加一个颜色棒(颜色帮在二元kde图像中才有);
有木有觉得参数超多,所以说核密度图还是比较难的(虽然容易画,但原理很复杂)。下面看几个简单的例子:简单生成一个多元正态分布(对numpy随机分布不了解的朋友,可以看我总结的numpy函数)。

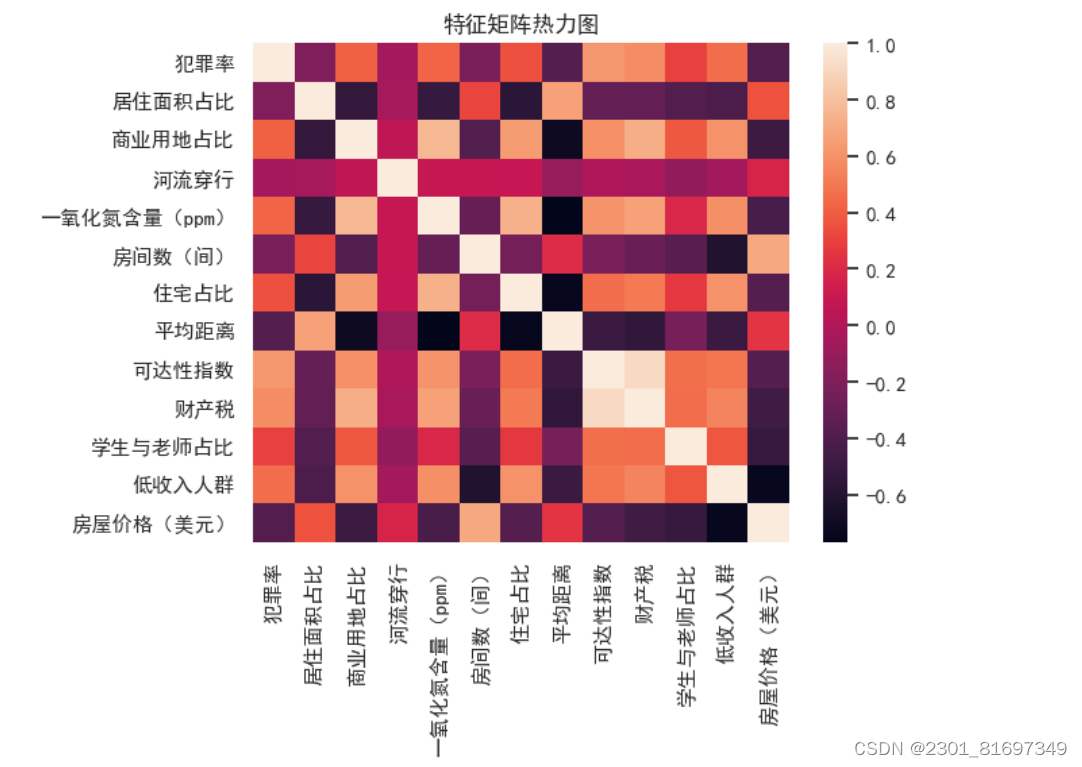
四、绘制热力图
用于绘制矩阵数据的热图,通常用于展示相关性矩阵。
- 定义:
- 热力图在可视化设计中用于展示大量数据的空间分布或趋势,帮助用户快速理解数据的模式和关系。
- 它将数据映射到不同的颜色,以颜色的明暗程度来传达数据的密度或强度。
- 设计原理:
- 基于人眼对颜色的敏感度,不同颜色的深浅或饱和度可以直观地表示数据点的密集程度。
- 一般来说,较亮的颜色(如红色或黄色)表示高密度或高强度的数据,而较暗的颜色(如蓝色或绿色)表示低密度或低强度的数据。
绘制热力图代码如下:

运行结果如下:
总结
-
美观的默认样式:
seaborn提供了丰富的预设样式和配色方案,使得生成的图形既专业又美观。 -
丰富的统计图形:提供了多种统计图形类型,如散点图、箱线图、热力图等,方便展示数据的各种统计特性。
-
集成数据聚合:内置数据聚合功能,可以方便地对数据进行分组和统计,直接用于绘图。
-
与
pandas集成:与pandas库紧密集成,可以直接使用DataFrame进行绘图,无需额外转换。 -
易于定制:在保持美观和易用性的同时,提供了足够的灵活性来定制图形的细节。
seaborn的缺点:
-
定制化能力有限:虽然
seaborn提供了丰富的预设样式和图形类型,但这也导致其在某些方面定制化能力相对较弱。如果需要高度定制化的图形,可能需要结合matplotlib进行更深入的调整。 -
不支持某些特定图形:虽然
seaborn覆盖了大部分常用的统计图形,但它可能不支持某些特定或复杂的图形类型。在这种情况下,用户可能需要使用其他库,如matplotlib或plotly。 -
依赖性强:
seaborn依赖于matplotlib和pandas等库。因此,在使用seaborn之前,需要确保这些依赖库已经被正确安装和配置。 -
学习曲线:虽然
seaborn相对于matplotlib来说更加易用,但对于初学者来说,理解其背后的统计原理和图形类型可能需要一些时间和实践。 -
性能:在处理大型数据集或复杂图形时,
seaborn的性能可能不如一些更底层的库,如matplotlib或plotly。这是因为seaborn在提供高级功能的同时,可能需要进行更多的计算和渲染。















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









