







word2vec的高速化
1.CBOW模型的学习代码
import sys
sys.path.append('..')
from common import config
# 在用GPU运行时,请打开下面的注释(需要cupy)
# ===============================================
#config.GPU = True
# ===============================================
from common.np import *
import pickle
from common.trainer import Trainer
from common.optimizer import Adam
from cbow import CBOW
from skip_gram import SkipGram
from common.util import create_contexts_target, to_cpu, to_gpu
from dataset import ptb
# 设定超参数
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 读入数据
corpus, word_to_id, id_to_word = ptb.load_data('train') #加载熟练数据
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size) #
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 生成模型等
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 开始学习
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 保存必要数据,以便后续使用
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)
2.create_contexts_target(生成上下文和目标词的函数)
def create_contexts_target(corpus, window_size=1):
'''生成上下文和目标词
:param corpus: 语料库(单词ID列表)
:param window_size: 窗口大小(当窗口大小为1时,左右各1个单词为上下文)
:return:
'''
target = corpus[window_size:-window_size]
contexts = []
for idx in range(window_size, len(corpus)-window_size):
cs = []
for t in range(-window_size, window_size + 1):
if t == 0:
continue
cs.append(corpus[idx + t])
contexts.append(cs)
return np.array(contexts), np.array(target)
CBOW模型的实现代码:
import sys
sys.path.append('..')
from common.np import * # import numpy as np
from common.layers import Embedding
from ch04.negative_sampling_layer import NegativeSamplingLoss
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 初始化权重
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 生成层
self.in_layers = []
for i in range(2 * window_size): #创建 2 * window_size 个Embedding 层
layer = Embedding(W_in) # 使用Embedding层,输入层-隐藏层
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 将所有的权重和梯度整理到列表中
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 将单词的分布式表示设置为成员变量
self.word_vecs = W_in
#contexts, target如图所示
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target) #实现负采样,NegativeSamplingLoss,并返回损失函数
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None
forward:contexts(文本)是目标词的上下文的关联词,target(目标)是我们需要预测的值
这里我们先给出正确解题思路:(思维框架)
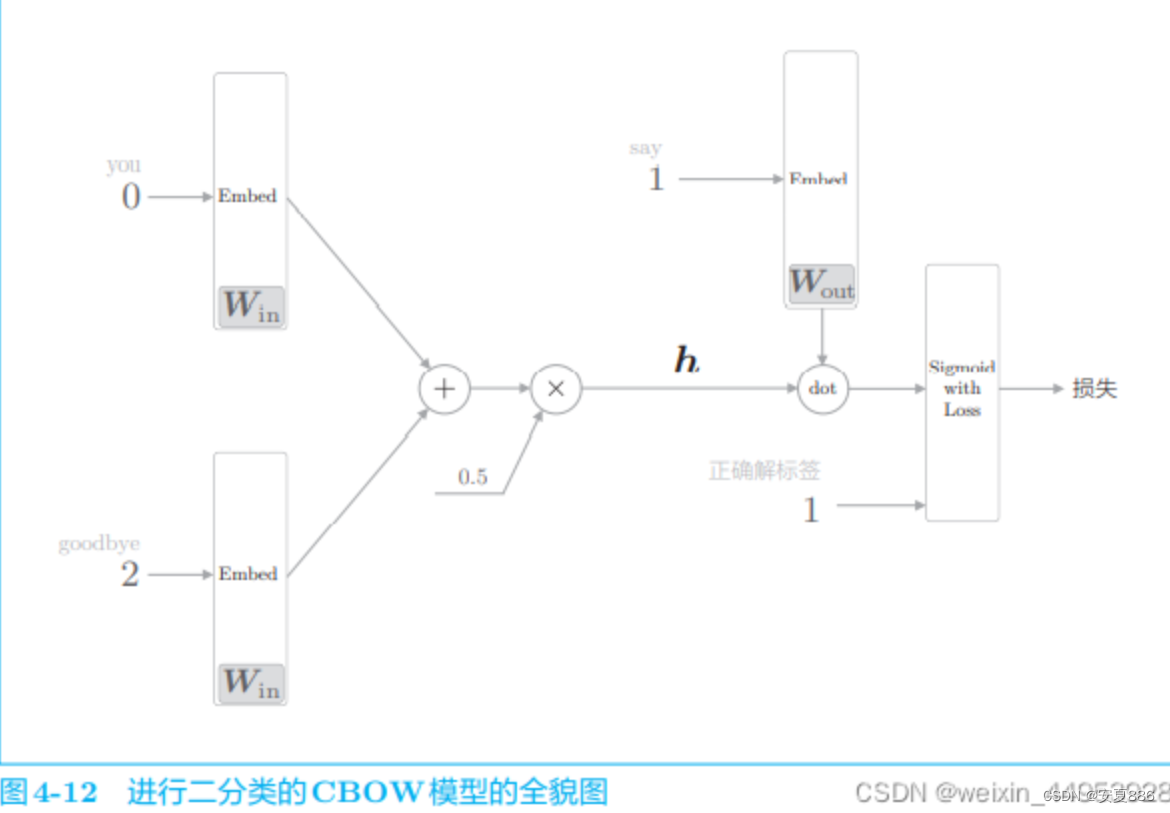
我们首先要调用输入层的Embedding,相关词经过Embedding(也就是降低数据处理量,简化),然后,再相加,再除以相关词的数量,得到平均数,这就求出了隐藏层
然后再调用损失函数,即可求出损失值啦。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









