






通过本文可以了解:LoRA模型加速原理、peft包使用、Autocust自动混合精度、Accelerate和deepspeed加速、多GPU分布式训练等大模型加速训练和微调的方法和代码应用示例。

近期大模型层出不穷,大家对于大模型的微调也在跃跃欲试,像斯坦福的Alpaca[1], 清华的ChatGLM[2],中文的Chinese-Vicuna[3],让我这样的普通玩家也能训练自己的微调模型。
在微调和推理的时候仍然需要加速,有哪些方法可以加速微调呢?
Part1LoRA
低秩矩阵分解 LoRA[4]原理:冻结预训练模型权重,并将可训练的秩分解矩阵注入到Transformer层的每个权重中,大大减少了下游任务的可训练参数数量。LoRA 开源代码[5]见文末。
原理图: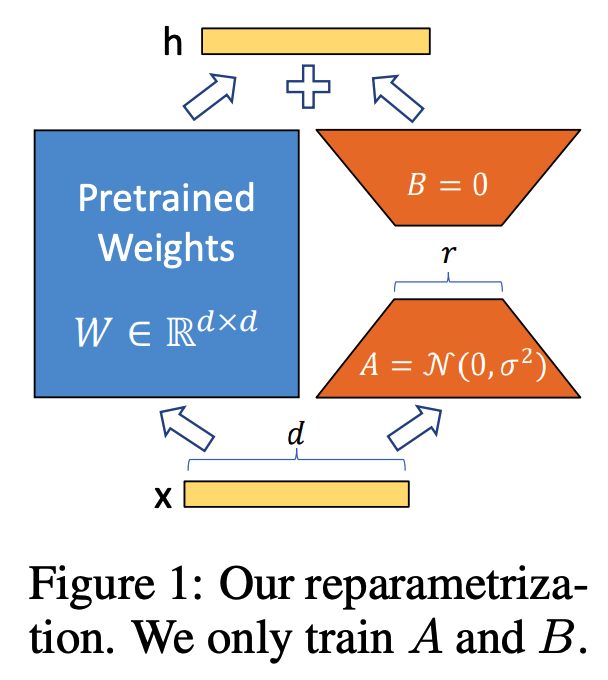
公式: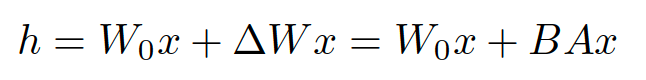
结合原理图和公式,我们可以很容易明白LoRA了:
左侧是预训练模型的权重,输入输出维度都是d,在训练期间被冻结,不接受梯度更新。
右侧,对A使用随机的高斯初始化,B在训练开始时为零,r是秩,会对△Wx做缩放 α/r。
HuggingFace的包peft[6]对LoRA做了封装支持,几步即可使用:

论文中提到了LoRA的诸多优点:
Part2Accelerate 和 deepspeed
Accelerate[7]库提供了简单的 API,使我们可以在任何类型的单节点或分布式节点(单CPU、单GPU、多GPU 和 TPU)上运行,也可以在有或没有混合精度(fp16)的情况下运行。
这里是我用 Accelerator 和 DeepSpeedPlugin 做个示例:
需要提前知道梯度累积步骤 gradient_accumulation_steps 和 梯度累积计算


Part3Autocast 自动混合精度
autocast是在GPU上训练时一种用于降低显存消耗的技术。原理是用更短的总位数来保存浮点数,能够有效将显存消耗降低,从而设置更大的batch来加速训练。但会造成精度的损失,导致收敛效果也会变差。
PyTorch的AMP有2种精度是torch.FloatTensor和torch.HalfTensor。
使用方法:
from torch.cuda.amp import autocast as autocast, GradScaler
dataloader = ...
model = model.cuda()
optimizer = ...
scheduler = ...
# scaler的大小在每次迭代中动态估计,为了尽可能减少梯度,scaler应该更大;
# 但太大,半精度浮点型又容易 变成inf或NaN.
# 动态估计原理就是在不出现if或NaN梯度的情况下,尽可能的增大scaler值。
scaler = GradScaler()
for epoch in range(epochs):
for batch_idx, (data, targets) in enumerate(train_dataloader):
optimizer.zero_grad()
data = data.cuda(0)
with autocast(dtype=torch.bfloat16): # 自动混精度
logits = model(data)
loss = loss(logits, targets)
# 反向传播梯度放大
scaler.scale(loss).backward()
# 首先 把梯度值unscale回来, 优化器中的值也需要放缩
# 如果梯度值不是inf或NaN, 则调用optimizer.step()来更新权重,否则,忽略step调用,从而保证权重不更新。
scaler.step(optimizer)
# 看是否要增大scaler, 更新scaler
scaler.update()
Part4单机多GPU
如果条件允许的话,可以使用单机多卡和分布式训练。
那么:
- 模型怎么同步参数与梯度?
- 数据怎么划分到多个GPU中?
pytorch框架给我们封装了对应的接口函数:

PyTorch提供的torchrun命令以及一些API封装了多进程的实现。我们只要在普通的单进程程序前后加入:开头 setup()和 结尾 cleanup():

就能用多个进程来运行训练程序,每个进程分配一个GPU,我们可以用dist.get_rank()来查看当前进程的GPU号的。

1数据并行:
只要在生成Dataloader时,把DistributedSampler的实例传入sampler参数就行了,DistributedSampler会自动对数据采样,并放到不同的进程中。这里需要注意的是:sampler自动完成了打乱数据集的作用,所以在定义DataLoader时,不用再开启shuffle选项。
一机多GPU,使用一个进程管理一个GPU,每个进程共享模型参数,但是使用不同的数据,每次训练数据量 = batch size * GPU个数。PyTorch提供的torchrun命令以及一些API封装了多进程的实现:
https://pytorch.org/docs/stable/elastic/run.html#launcher-api
数据处理部分的示例代码,MyDataset具体内部实现,可以参考之前的自定义数据集的文章:
[

2分布式数据并行
在并行训练时,各个进程并行,每个模型使用同一份模型参数 weights。在梯度下降时,各个进程会同步一次,致使每个进程的模型都更新相同的梯度。
做法也很简单,只需要把Model套一层DistributedDataParallel,就可以实现backward的自动同步梯,其他的操作都照旧,把新模型ddp_model当成旧模型model调用就行。

训练流程照常:
在每个新epoch中,要用sampler.set_epoch(epoch)更新sampler打乱数据集。训练流程和普通深度学习训练流程一样。

3模型保存和读取:
在保存的时候,我们只需要保存一个进程下的模型即可,另外使用barrier()确保进程1在进程0保存模型之后加载模型。
存储参数时会保存设备信息。由于刚刚只保存了0号GPU进程的模型,所有参数的device都是cuda:0。而读取模型时,每个设备上都要去加载这个模型,device要做一个调整。

使用DistributedDataParallel把model封装成ddp_model后,模型的参数名称里多了一个module,这是因为原来的模型model被保存到了ddp_model.module这个成员变量中。
在混用单GPU和多GPU的训练代码时,要注意这个参数名不兼容的问题,包括上面我们使用LoRA加载模型的时候,也会出现模型层名称变换了的情况。最好的做法是每次存取ddp_model.module,这样单GPU和多GPU的checkpoint可以轻松兼容。

大模型快速微调和训练是我们做自然语言处理必备技能之一,尤其现在大语言模型及其微调模型不断涌现,只有掌握了这些技能才能跟上AI的浪潮。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









