







目录
内存四区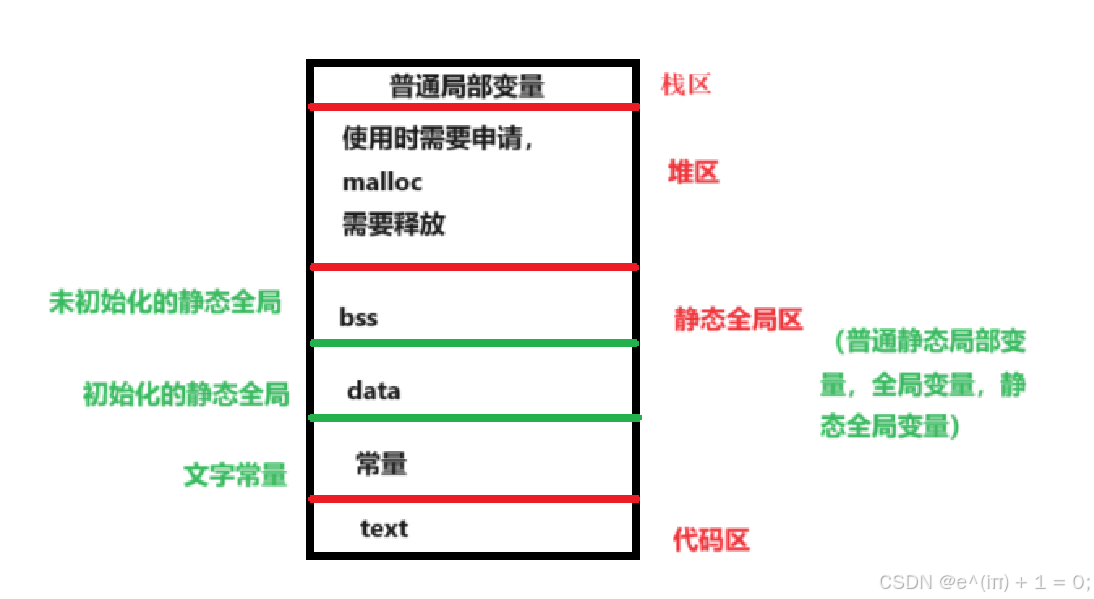
内存四区 程序运行前
1. 代码区
1.1 共享
1.2 只读
2. 数据区
2.1 静志变量、全局变量、常量
2.2 已初始化 data
2.3 未初始化 bss
内存四区 程序运行后
3. 栈区
3.1 先进后出
3.2 编译器管理数据开辟 释放
3.3 容量有限 ,不要将大量数据开辟到栈区
4. 堆区
4.1 容量远远大于栈区
4.2 程序员手动开辟数据,手动释放数据
4.3 malloc、calloc、realloc
4.4 free
栈区注意事项
不要返回局部变量的地址,局部变量在函数体执行完毕过后会被释放,再次操作就是非法操作,结果未知!


堆区注意事项
如果给主调函数中 一个空指针分配内存,利用同级的指针是分配失数的,解决方式:利用高级指针修饰低级指针


或者


const 修饰
全局const常量
直接修改失败
#include <stdio.h>
const int a = 10;//全局const常量,放在常量区,受到常量区保护
int main()
{
a = 100;
printf("%d\n",a);
return 0;
} 

间接修改失败
#include <stdio.h>
const int a = 10;//全局const常量,放在常量区,受到常量区保护
int main()
{
int *p = &a;
*p = 100;
printf("%d\n",a);
return 0;
}局部const常量
直接修改失败
#include <stdio.h>
int main()
{
const int a = 10;//数据存放在栈区
a = 100;
printf("%d\n",a);
return 0;
}间接修改成功
#include <stdio.h>
int main()
{
const int a = 10;//数据存放在栈区
int *p = &a;
*p = 100;
printf("%d\n",a);
return 0;
} ![]()
const使用场景
加入const修饰函数形参,防止误操作
#include <stdio.h>
struct stu
{
char name[128];
char age;
int id;
double score;
};
void printfperson(const struct stu *person)
{
printf("%s\n",person->name);
}
int main()
{
struct stu person = {"tom", 18, 01, 66.6};
printfperson(&person);
return 0;
}malloc、calloc、realloc
malloc
malloc 是C语言中的一个函数,用于动态分配内存空间。
void *malloc(size_t size);
calloc
calloc 是C语言中的另一个内存分配函数,与 malloc 类似但功能略有不同。

malloc与calloc的区别
使用 malloc 分配的内存块中,内容是未初始化的,即分配的内存中的值是未知的,可能是任意的。而使用 calloc 分配的内存块中,所有的字节都会被初始化为零。这意味着,分配的内存中的每一个比特(或字节)都被设置为0。
realloc

realloc机制
首先在原有空间后查看空闲空间,如果宝闲空间足够大直接在原空间后结开辟新空间大小并且使用
如果空闲空间不够用,在内存中直接找一块足够大的空间将原有空间下的数据拷贝到新空间下,并且释放原有的内存空间将新空间的首地址返回,也就是这个指针可能与 ptr 相同,也可能是一个新分配的地址。
sscanf用法
sscanf 函数是 C 语言中用来从字符串中按照指定格式提取数据的函数。可以用于从文件读取、网络数据解析等场景中提取和处理数据。

str = "sdfhjsh#zhanqu@35413674";
sscanf(str, "%*["#]%["@]", buf);%*["#]:这部分指示忽略任何以#开头的字符序列。%["@]":这部分匹配@"。- 因此,最终
buf中存储的内容将是"zhanqu"
str1 = "jhsfdjshfghjs@hfjkahjkfhdjfh.com";
sscanf(str1, "%[a-z]%*[@]%s", buf1, buf2);%[a-z]:匹配字符串中的小写字母序列。%*[@]:忽略以@开头的字符序列。%s:匹配非空格字符序列。- 因此,最终
buf1的内容是"jhsfdjshfghjs"。buf2的内容是"hfjkahjkfhdjfh.com"。
主要用法总结:
-
基本匹配:
%d,%f,%s等格式说明符用来匹配整数、浮点数、字符串等。- 例如:
"%d %f %s"可以用来匹配一个整数、一个浮点数和一个字符串。
-
宽度匹配:
%*d,%*f等表示忽略匹配的内容。- 例如:
"%*d"可以忽略一个整数的匹配结果。
-
字符集匹配:
[a-z],[0-9]等表示匹配指定范围内的字符。- 例如:
"%[a-zA-Z]"可以匹配任意大小写字母序列。
-
字符序列匹配:
@,#,@",@]"等可以匹配具体的字符序列。- 例如:
"%@"可以匹配@字符。
-
存储和忽略:
%s,%d等用来存储匹配的结果。%*s,%*d等用来忽略匹配的结果。
示例总结:
-
基本示例:
sscanf("123 4.5 test", "%d %f %s", &num, &fnum, buf);这里会将字符串
"123 4.5 test"按照"%d %f %s"的格式解析,并将结果存储到num、fnum和buf中。 -
宽度匹配示例:
sscanf("123 456 789", "%*d %d", &num);这里会忽略第一个整数
123,然后将第二个整数456存储到num中。 -
字符集匹配示例:
sscanf("abc123", "%[a-z]%d", buf, &num);这里会匹配字符串中的小写字母序列
"abc"和后面的整数123,分别存储到buf和num中。 -
字符序列匹配示例:
sscanf("name: John", "name: %s", buf);这里会匹配
"name: "后面的字符串"John",并将"John"存储到buf中。
直接定义数组指针变量
#include <stdio.h>
int main() {
int arr[5] = {1, 2, 3, 4, 5};
int (*ptr)[5]; // 定义一个指向包含5个整数的数组的指针
ptr = &arr; // 指针ptr现在指向数组arr
// 使用指针访问数组元素
for (int i = 0; i < 5; ++i)
{
printf("Element %d: %d\n", i, (*ptr)[i]);
}
return 0;
} 
左移与右移
左移
低位(右侧)补0
右移
逻辑右移:高位(左侧)补0
算术右移:高位(左侧)补原该值的符号位
到底是逻辑右移还是算术右移取决于编译器
文件加密与解密
这段代码可以作为简单加密和解密文件的起点,实际应用中需根据具体需求和安全性要求选择更合适的加密算法和实现方式。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void File_encrypted(const char *inputFileName, const char *outputFileName);
void File_decrypted(const char *inputFileName, const char *outputFileName);
int main()
{
File_encrypted("./记录文件.txt", "./加密文件.txt");
File_decrypted("./加密文件.txt", "./解密文件.txt");
return 0;
}
void File_encrypted(const char *inputFileName, const char *outputFileName)
{
FILE *inputFile = fopen(inputFileName, "r");
FILE *outputFile = fopen(outputFileName, "w");
if (inputFile == NULL || outputFile == NULL)
{
perror("打开文件失败\n");
return;
}
char ch;
srand(time(NULL));
while (1)
{
if(feof(inputFile))
break;
ch = fgetc(inputFile);
short temp = (short)ch;
temp <<= 4;
temp |= 0x8000;
temp += rand() % 16;
fprintf(outputFile, "%hd", temp);
}
fclose(inputFile);
fclose(outputFile);
}
void File_decrypted(const char *inputFileName, const char *outputFileName)
{
FILE *inputFile = fopen(inputFileName, "r");
FILE *outputFile = fopen(outputFileName, "w");
if (inputFile == NULL || outputFile == NULL)
{
perror("打开文件失败\n");
return;
}
short temp = 0;
while (1)
{
if(feof(inputFile))
break;
fscanf(inputFile,"%hd",&temp);
temp <<= 1;
temp >>= 5;
char ch = (char)temp;
fprintf(outputFile,"%c",ch);
}
}
加密
void File_encrypted(const char *inputFileName, const char *outputFileName)
{
FILE *inputFile = fopen(inputFileName, "r");
FILE *outputFile = fopen(outputFileName, "w");
if (inputFile == NULL || outputFile == NULL)
{
perror("打开文件失败\n");
return;
}
char ch;
srand(time(NULL));
while (1)
{
ch = fgetc(inputFile);
if(feof(inputFile))
break;
short temp = (short)ch;
temp <<= 4;
temp |= 0x8000;
temp += rand() % 16;
fprintf(outputFile, "%hd", temp);
}
fclose(inputFile);
fclose(outputFile);
}
解密
void File_decrypted(const char *inputFileName, const char *outputFileName)
{
FILE *inputFile = fopen(inputFileName, "r");
FILE *outputFile = fopen(outputFileName, "w");
if (inputFile == NULL || outputFile == NULL)
{
perror("打开文件失败\n");
return;
}
short temp = 0;
while (1)
{
if(feof(inputFile))
break;
fscanf(inputFile,"%hd",&temp);
temp <<= 1;
temp >>= 5;
char ch = (char)temp;
fprintf(outputFile,"%c",ch);
}
}
链表
数组的缺点:一旦分配好了内存,就不可以动态扩展一旦分配过多,导致资源浪费,对于头部插入和删除,效率低。
利用链表,解決数组缺点链表由节点构成,节点由数据域和指针域构成,数据域:链表维护的数据,指针域:指向下一个节点的地址
数组优点:访问元素速度快,每个元素占用空间相对于节点比较少,节点有指针域
#include <stdio.h>
#include <stdlib.h>
struct Node
{
int data;
struct Node *next;
};
void insertAtEnd(struct Node **head, int newData);
void printList(struct Node *node);
void insertAfter(struct Node **head, int preData, int newData);
void deleteNode(struct Node **head, int key);
void clearList(struct Node **head);
void reverseList(struct Node **head);
int main()
{
struct Node *head = NULL;
insertAtEnd(&head, 1);
insertAtEnd(&head, 2);
insertAtEnd(&head, 3);
insertAfter(&head,2,4);
printList(head);
reverseList(&head);
printList(head);
deleteNode(&head,4);
printList(head);
clearList(&head);
insertAfter(&head,2,4);
printList(head);
return 0;
}
void insertAtEnd(struct Node **head, int newData)
{
struct Node *newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
perror("分配失败");
return;
}
// 新节点将成为链表中的最后一个节点
newNode->data = newData;
newNode->next = NULL;
// 如果链表为空,直接将新节点作为头节点
if (*head == NULL) {
*head = newNode;
return;
}
// 找到链表的末尾节点
struct Node *last = *head;
while (last->next != NULL) {
last = last->next;
}
// 将新节点连接到链表的末尾
last->next = newNode;
}
void printList(struct Node *node)
{
while (node != NULL) {
printf("%d -> ", node->data);
node = node->next;
}
printf("NULL\n");
}
void insertAfter(struct Node **head, int preData, int newData)
{
struct Node *newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
perror("分配失败");
return;
}
//创建新节点
newNode->data = newData;
newNode->next = NULL;
// 如果链表为空,直接将新节点作为头节点
if (*head == NULL)
{
*head = newNode;
return;
}
struct Node *previous = *head;
struct Node *current = (*head)->next;
// 寻找preData节点
while (current != NULL && previous->data != preData)
{
previous = current;
current = current->next;
}
// 如果找到了preData节点
newNode->next = current;
previous->next = newNode;
}
void deleteNode(struct Node **head, int key)
{
struct Node *temp = *head;
struct Node *prev = NULL;
// 如果要删除的节点是头节点
if (temp != NULL && temp->data == key) {
*head = temp->next; // 更改头指针
return;
}
// 找到要删除的节点
while (temp != NULL && temp->data != key) {
prev = temp;
temp = temp->next;
}
// 如果key不存在
if (temp == NULL) {
return;
}
// 重新连接链表
prev->next = temp->next;
}
void clearList(struct Node **head)
{
struct Node *current = *head;
struct Node *next;
while (current != NULL)
{
next = current->next; // 保存下一个节点的指针
free(current); // 释放当前节点
current = next; // 移动到下一个节点
}
// 头指针置为NULL,表示链表已被释放
*head = NULL;
}
void reverseList(struct Node **head)
{
struct Node *prev = NULL;
struct Node *current = *head;
struct Node *next;
while (current != NULL) {
next = current->next; // 保存下一个节点的指针
current->next = prev; // 当前节点指向前一个节点,完成翻转
prev = current; // prev 指针向后移动
current = next; // current 指针向后移动
}
*head = prev; // 更新头指针,即原链表的最后一个节点变为新链表的头节点
}带头节点的链表
带头节点的链表是指链表的头部有一个额外的节点,这个节点不存储数据,仅用来简化链表的操作。通常头节点的指针指向第一个真正存储数据的节点。
头节点 -> 节点1 -> 节点2 -> 节点3 -> ... -> 节点n -> NULL
void insertAtEnd(struct Node **head, int newData)
{
struct Node *newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
perror("分配失败");
return;
}
// 新节点将成为链表中的最后一个节点
newNode->data = newData;
newNode->next = NULL;
// 如果链表为空,直接将新节点作为头节点
if (*head == NULL) {
*head = newNode;
return;
}
// 找到链表的末尾节点
struct Node *last = *head;
while (last->next != NULL) {
last = last->next;
}
// 将新节点连接到链表的末尾
last->next = newNode;
}链表节点的插入
void insertAfter(struct Node **head, int preData, int newData)
{
struct Node *newNode = (struct Node*)malloc(sizeof(struct Node));
if (newNode == NULL) {
perror("分配失败");
return;
}
//创建新节点
newNode->data = newData;
newNode->next = NULL;
// 如果链表为空,直接将新节点作为头节点
if (*head == NULL)
{
*head = newNode;
return;
}
struct Node *previous = *head;
struct Node *current = (*head)->next;
// 寻找preData节点
while (current != NULL && previous->data != preData)
{
previous = current;
current = current->next;
}
// 如果找到了preData节点
newNode->next = current;
previous->next = newNode;
}链表节点的删除
void deleteNode(struct Node **head, int key)
{
struct Node *temp = *head;
struct Node *prev = NULL;
// 如果要删除的节点是头节点
if (temp != NULL && temp->data == key) {
*head = temp->next; // 更改头指针
return;
}
// 找到要删除的节点
while (temp != NULL && temp->data != key) {
prev = temp;
temp = temp->next;
}
// 如果key不存在
if (temp == NULL) {
return;
}
// 重新连接链表
prev->next = temp->next;
}清空链表
void clearList(struct Node **head)
{
struct Node *current = *head;
struct Node *next;
while (current != NULL)
{
next = current->next; // 保存下一个节点的指针
free(current); // 释放当前节点
current = next; // 移动到下一个节点
}
// 头指针置为NULL,表示链表已被释放
*head = NULL;
}翻转链表
void reverseList(struct Node **head)
{
struct Node *prev = NULL;
struct Node *current = *head;
struct Node *next;
while (current != NULL) {
next = current->next; // 保存下一个节点的指针
current->next = prev; // 当前节点指向前一个节点,完成翻转
prev = current; // prev 指针向后移动
current = next; // current 指针向后移动
}
*head = prev; // 更新头指针,即原链表的最后一个节点变为新链表的头节点
}回调函数
回调函数指的是一个函数,它作为参数传递给另一个函数,并在特定事件发生时由另一个函数调用。简单来说,回调函数就是在某个条件满足时被调用的函数。在C语言中,回调函数通常通过函数指针实现。典型的应用场景包括事件处理、异步操作完成通知等。
函数指针定义
void (*指针名称)(参数列表);
void (*ptr)(int) = fun;
函数指针做参数
#include <stdio.h>
void printInt(void *data)
{
int *value = (int *)data;
printf("%d\n", *value);
}
void printFloat(void *data)
{
float *value = (float *)data;
printf("%f\n", *value);
}
void printString(void *data)
{
char *value = (char *)data;
printf("%s\n", value);
}
void printData(void *data, void (*printFunc)(void *))
{
printFunc(data);
}
int main() {
int intValue = 10;
float floatValue = 3.14;
char *stringValue = "Hello, world!";
// 打印整数
printData(&intValue, printInt);
// 打印浮点数
printData(&floatValue, printFloat);
// 打印字符串
printData(stringValue, printString);
return 0;
}
















 2134
2134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









