






直接插入排序
前言
“排序犹如一把将混乱变为秩序的魔法钥匙,使我们能以更高效的方式理解与处理数据。”
排序算法,用于对一组数据按照特定顺序进行排列。排序算法的应用广泛,因为有序的数据能被更高效地查找和处理。
(阅读本文的前置知识:冒泡排序和堆排序,如果不了解这两个排序算法的可以看我之前的文章。)
正文
我们本文来了解一种排序算法:直接插入排序。
直接插入排序是一种简单的排序算法,工作原理类似我们玩“斗地主”时手动整理一副牌。
直接插入排序(Straight Insertion Sort)的基本操作是在未排序的区间选择一个当前要排序的元素,将这个元素与已排序区间的元素从右到左逐一比较大小,将该元素插入到正确的位置。重复这个过程直到所有元素排到正确位置。
总之,和打牌时理牌的思想确实是一样的,只是我们要用代码的方式来实现。

直接插入排序的实现:

假设我们现在有一个降序的数组,我们要将其排为升序,我们应该怎么做?
首先我们创建两个变量,end与tmp,end首先赋值为第一个数,tmp赋值为第二个数。
可以看到tmp是比end小的,所以此时我们将end的值赋给end+1的位置,然后让end往前走,这时候我们end往前走就越界了。

对于越界我们的处理方式是将tmp的值赋给end+1的位置。这样我们的9和10就排为有序的序列了。

接下来我们让end走到当前10的位置(下标为1的位置),也就是已排序区间的最后一个位置。此时让tmp为8,将8与已排好的9和10进行比较,将其排到正确的位置。

将tmp(8)与end(10)比较,tmp更小,将end的值赋给end+1的位置,end–,此时end来到9的位置,将tmp(8)与end(9)比较,tmp更小,将end的值赋给end+1的位置,end–。
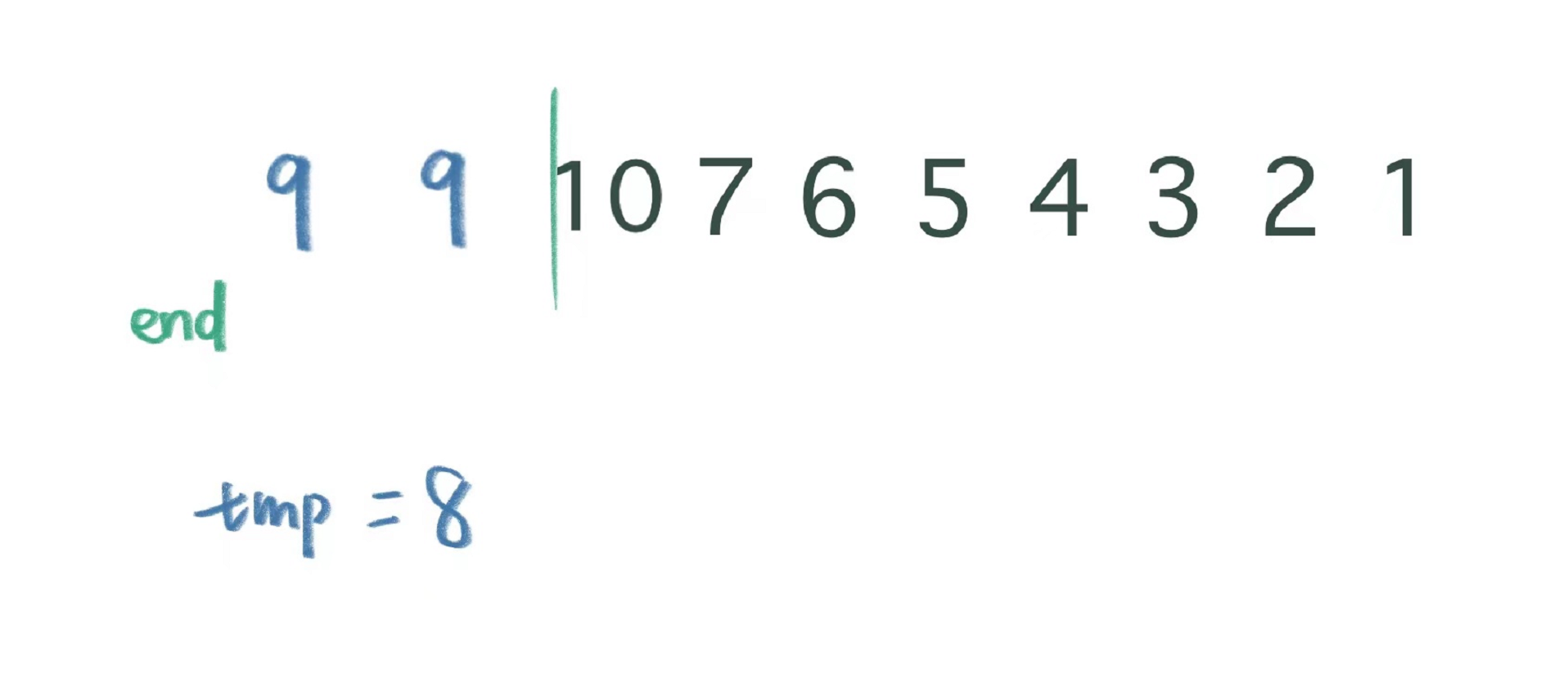
此时end越界了,越界就将tmp的值赋给end+1的位置。这样,我们的8 、9 、10就有序了。
(可以看到上文中紫色加粗部分的行为是重复的,不难明白这应该是循环的代码)
就这样循环下去,最后让所有数据都去到正确的位置。
:🐙:可以理解,我们创建tmp这个变量的作用在于将end的值赋给end+1时,end+1值被覆盖后仍能保存在tmp里,以供向前找到正确位置后放入;上面我们讲的刚好都是end的值大于tmp也就是要交换的情况,而当tmp并没有小于end时就不需要交换,我们就会用到break。
(其实上面这个完全降序的数组排成升序不利于我们思考代码如何写全面,还要找无序的例子观察,这里省略具体讲解)
代码
首先我们在头文件中去声明这个直接插入排序的函数:
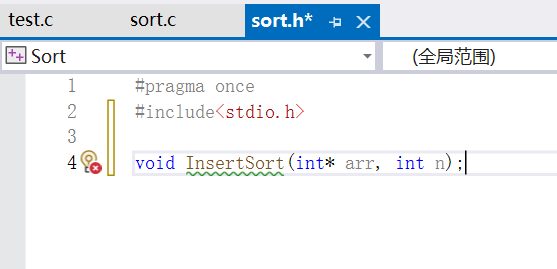
可以看到我们需要的参数是需要排序的数组以及数据个数。
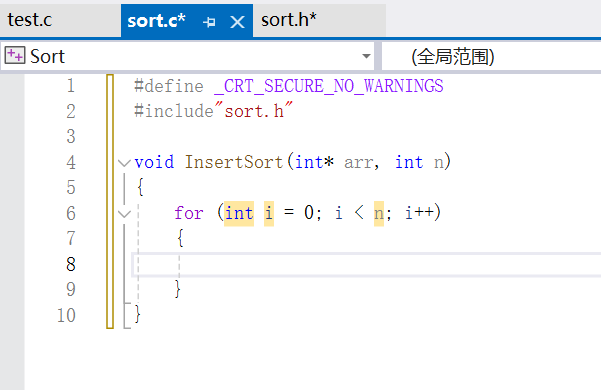
我们可以先把代码写成这样,联想一下冒泡排序,外层循环控制的是内层循环的次数。
然后根据我们上面所分析的,可以先得到这样的直接插入排序代码:
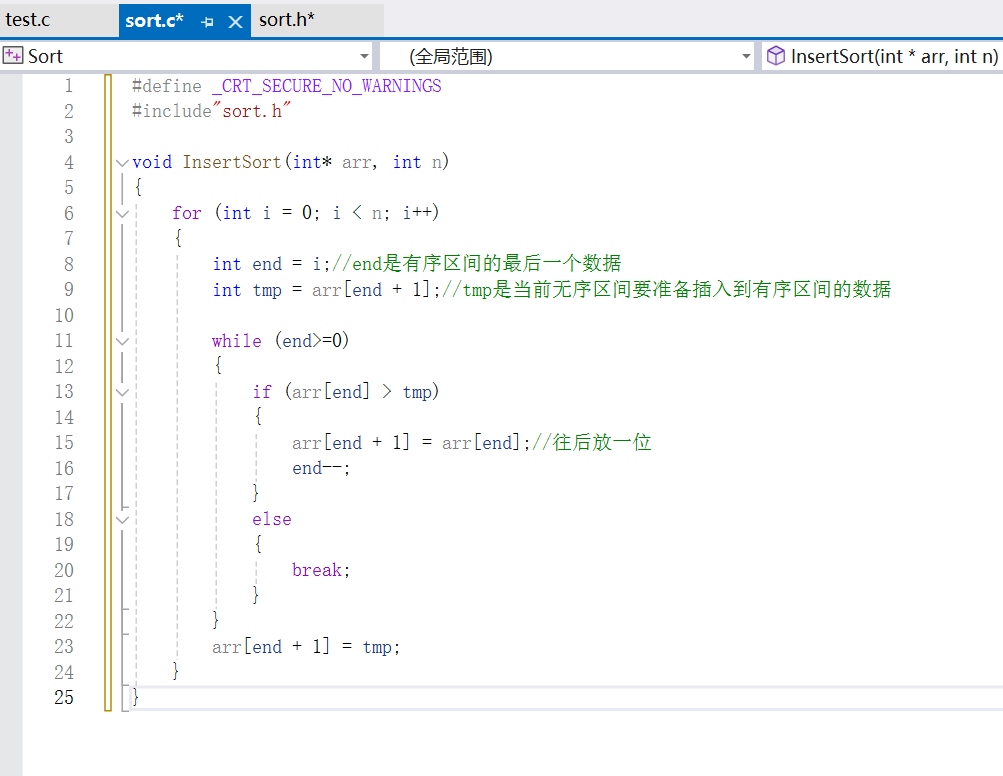
但是这个代码是存在问题的。我们看看我们外层循环写的控制条件,我们的n最后一次取值为n-1,那么我们下面写的int tmp = arr[end + 1];中tmp就会变为n,而数组元素个数为n,下标为n也就是越界了。所以我们的外层循环要改为i<n-1。
改完这一点后我们再写一个打印方法来看看情况。
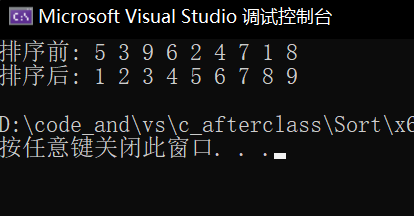
可以看到没有问题。
:🐙:再次回顾,第一次循环就像我们取每一张牌,每一张牌都需要排到正确的位置。然后每在未排序区间取一个要排序的数时我们都需要将其与已排序区间从后往前一一比较,这就是为什么会有内层循环。
直接插入排序算法的时间复杂度
提到算法我们逃不了要讨论时间复杂度,那么我们来看看直接插入排序算法的时间复杂度是什么。
外层循环为O(n)可以一眼看出来,而内层循环执行次数的计算,最后发现是一个等差数列。都是最差情况,end往后走的过程中交换次数逐渐变大,1+2+3+…+(n-1),所以也是O(n),所以直接插入排序算法的时间复杂度就为O(n²)。直接插入排序最差的情况也就是降序的情况。
而最好的情况也就是我们要排升序而恰好已经是升序,这种情况下每次我们都直接break,所以时间复杂度为O(n)。
与其他排序算法的对比
我们知道堆排序的时间复杂度为O(nlogn),冒泡排序最坏情况的时间复杂度为O(n²),最好情况下为O(n)。
这都是理论对比,我们也可以用写程序的方式来直观地比较这几种算法的时间复杂度的区别。
测试代码:排序性能对⽐
前置知识:
clock函数是C语言中的一个函数,用于测量程序执行的时间。 它返回程序调用某个进程或函数所花费的时间。clock函数的返回值类型是clock_t,这个类型通常是long类型,表示处理器时间。
通俗来说就是程序运行到这花了多长时间,我们在排序前后各调用一次,相减得到的就是排序所需的时间。
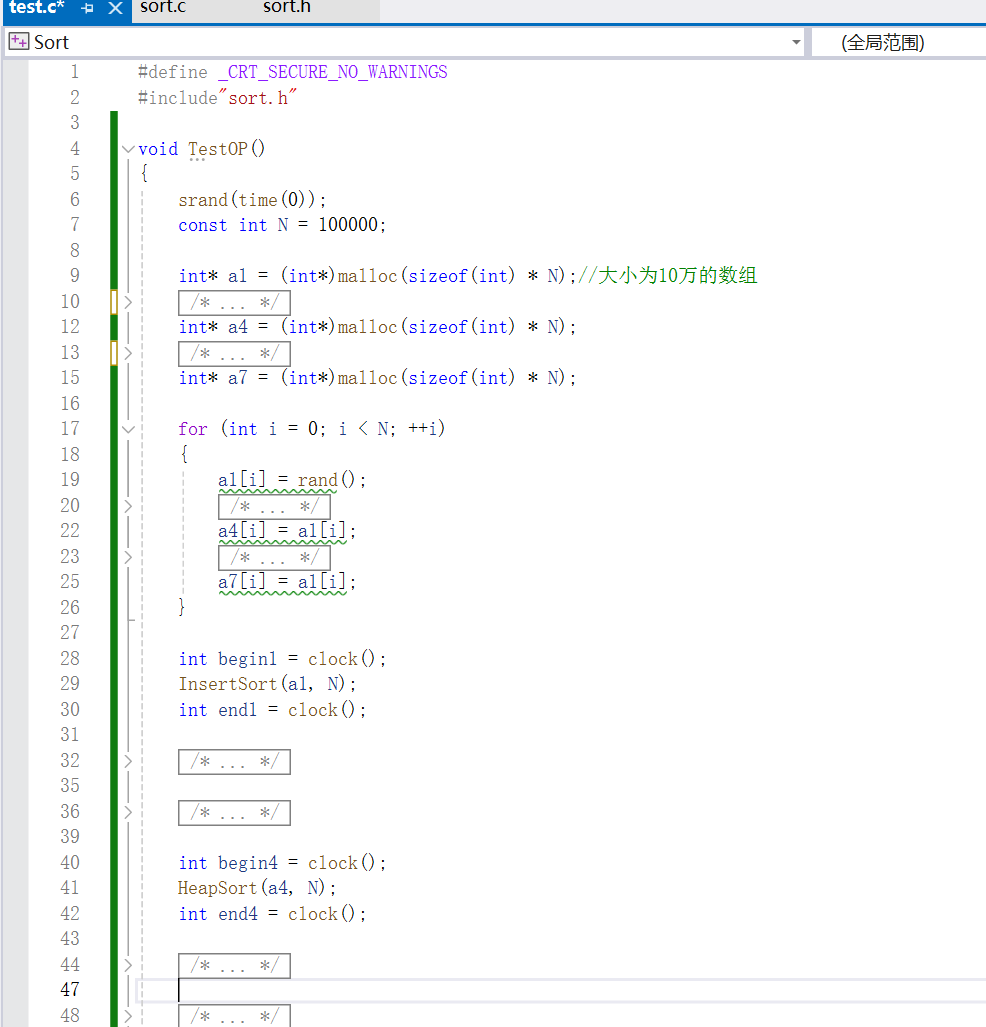
在这个测试代码中我们创建了三个数组a1 a4 a7,生成三组一样的随机数数组(都是10万个数),然后对a1使用直接插入排序,堆a4使用堆排序,对a7使用冒泡排序,然后切换到release环境,打印看看。
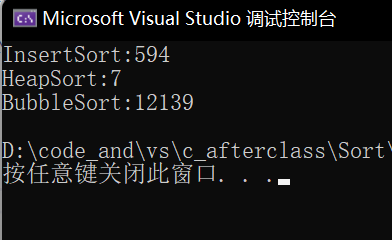
直接插入排序最差为O(n²),堆排序的时间复杂度为O(nlogn),冒泡排序时间复杂度为O(n²)。
这里的单位是ms。可以看到对10万个数据进行排序时,冒泡排序消耗了12秒,堆排序只要7ms,可以看到两者的差距非常大。
而对于直接插入排序来说,最差情况也就是降序情况才会为O(n²),也就是说绝大部分情况下都是小于O(n²)的。冒泡排序最差的情况却很容易达到。所以这就是为什么两者最差情况都为O(n²)但结果却差这么多。
本文到此结束,祝阅读愉快=_=















 1363
1363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









