






数据初步了解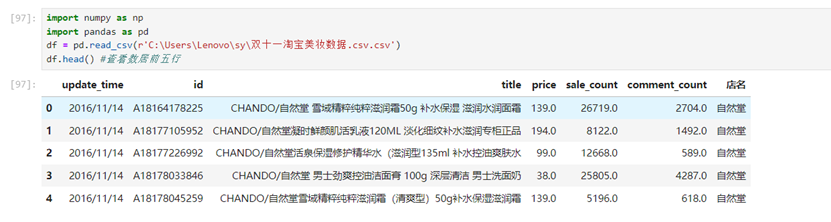
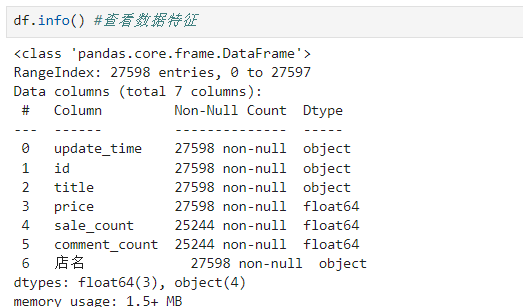
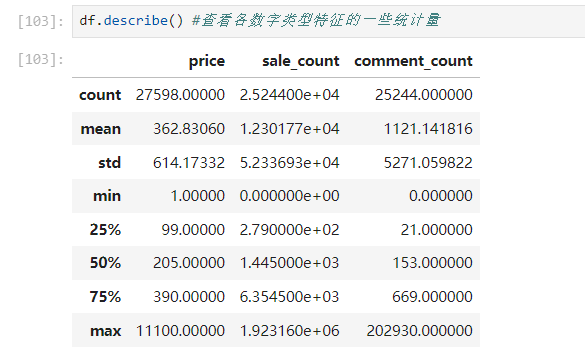
数据有27598条,每条数据有7个特征,都是非空的。
2、数据清洗
重复值处理
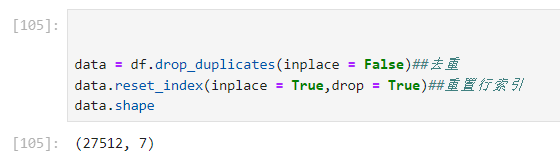
看出有86条重复数据,删除后得到新的数据
缺失值处理
通过上面观察数据发现sale_count,comment_count 存在缺失值,先观察存在缺失值的行的基本情况
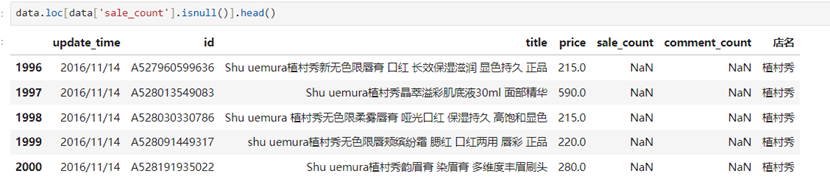

存在的缺失值很可能意味着售出的数量为0或者评论的数量为0,所以我们用0来填补缺失值。
数据挖掘寻找新的特征
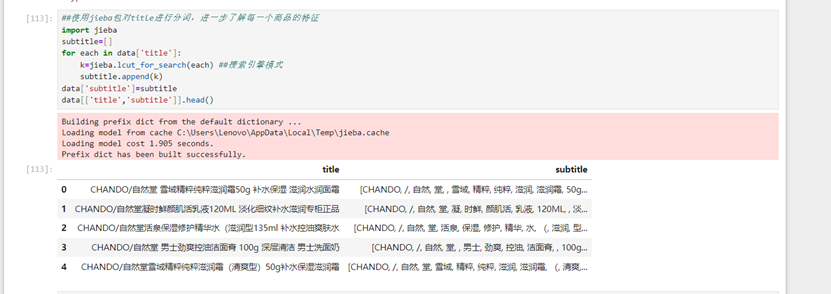


给出各个关键词的分类类别
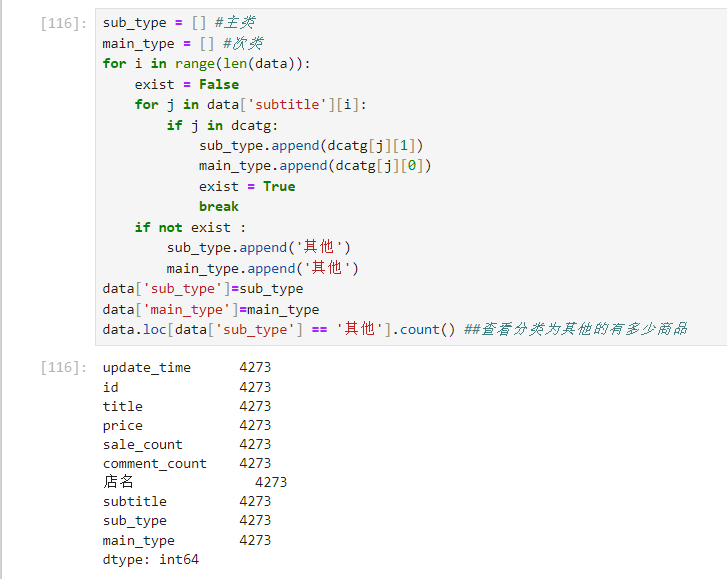
由title新生成两列类别
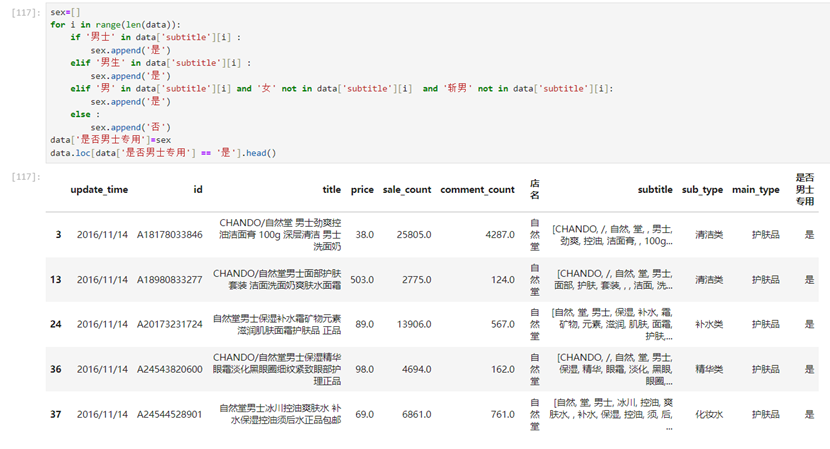
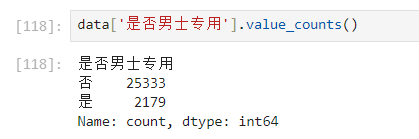
对是否是男性专用进行分析并新增一列
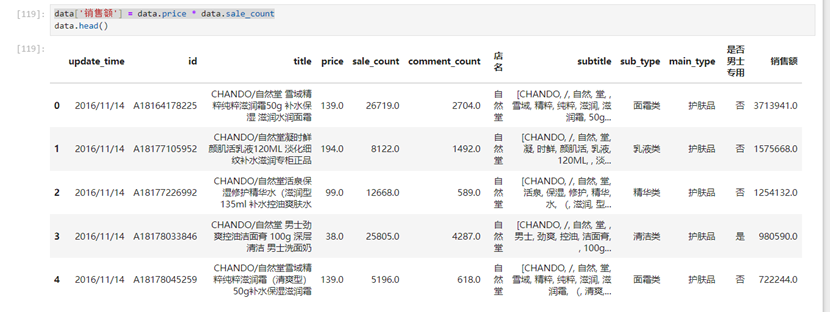
对每个产品总销量新增销售额这一列
3、数据分析及可视化
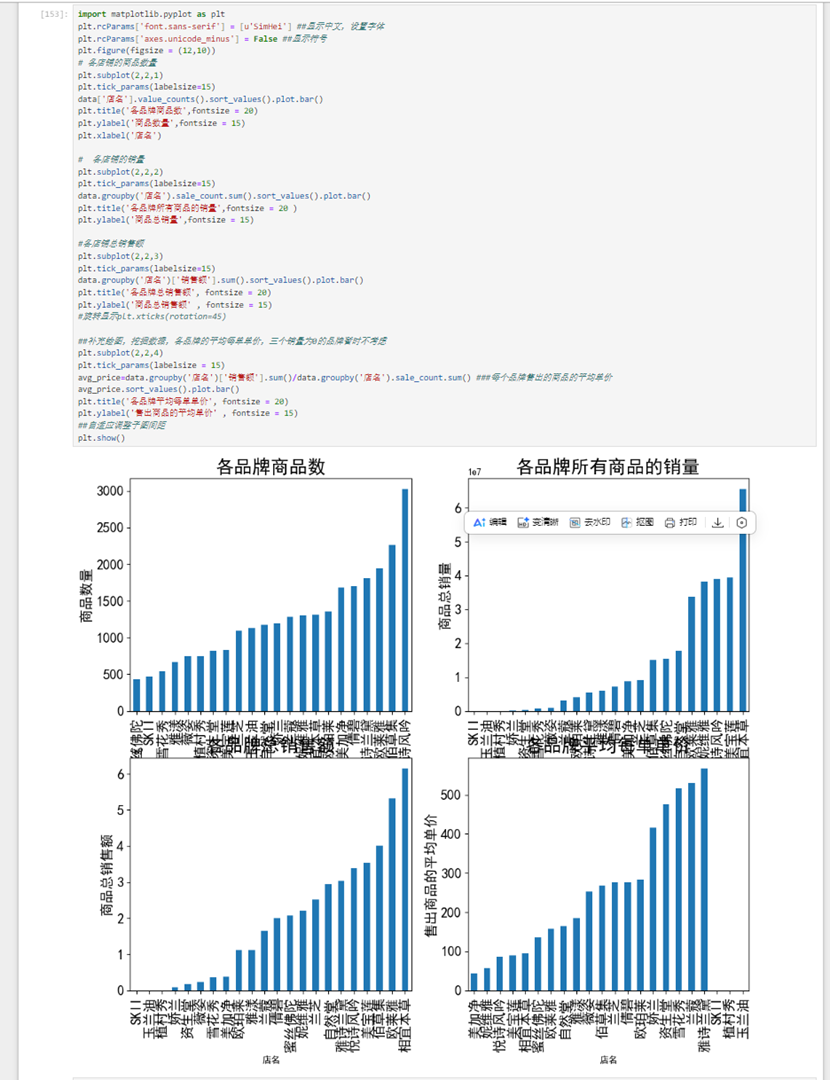
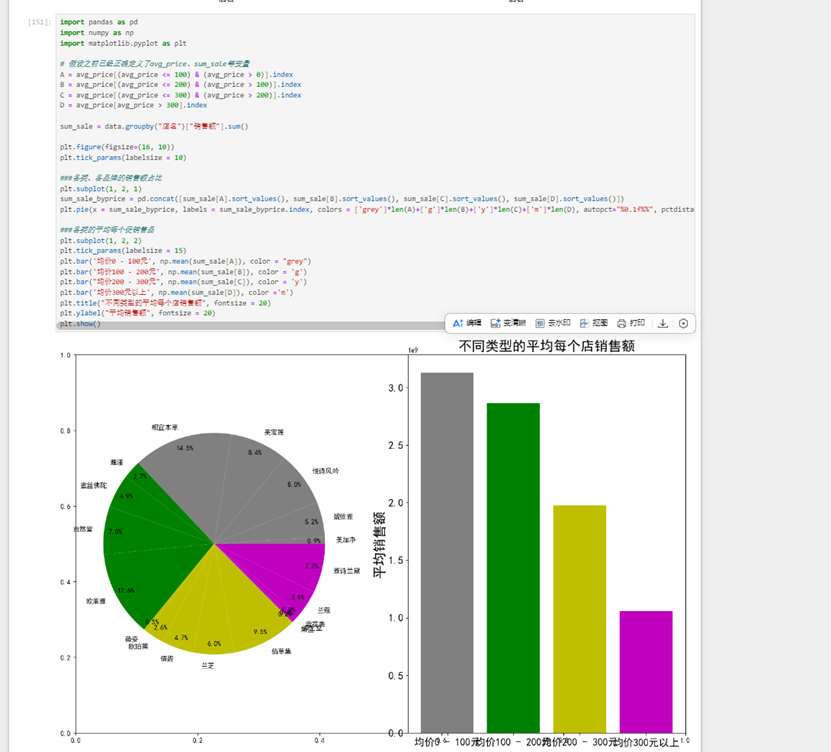
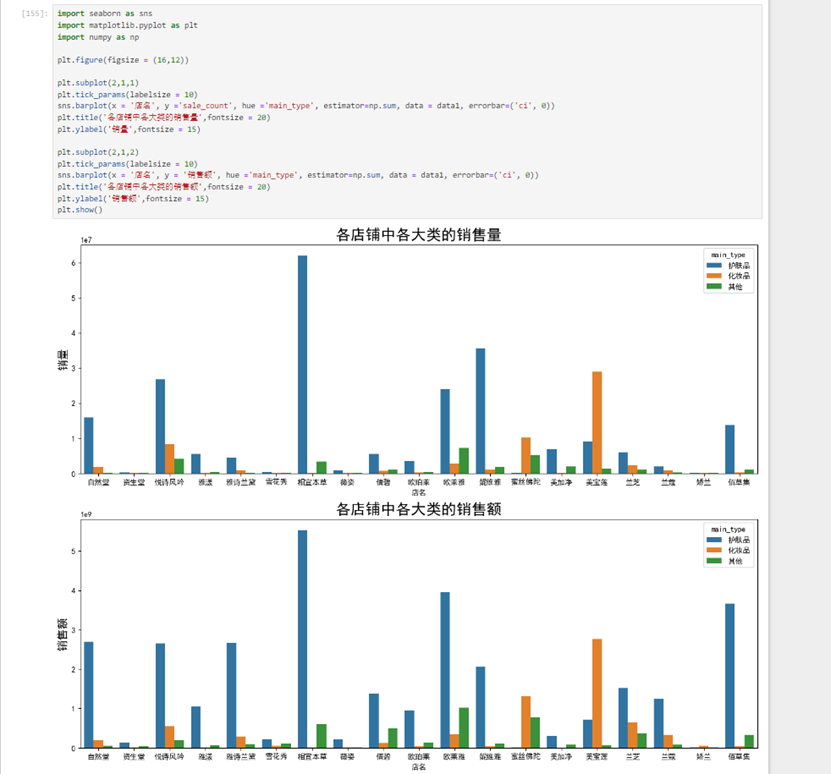
接下来考虑各个类别的销售情况
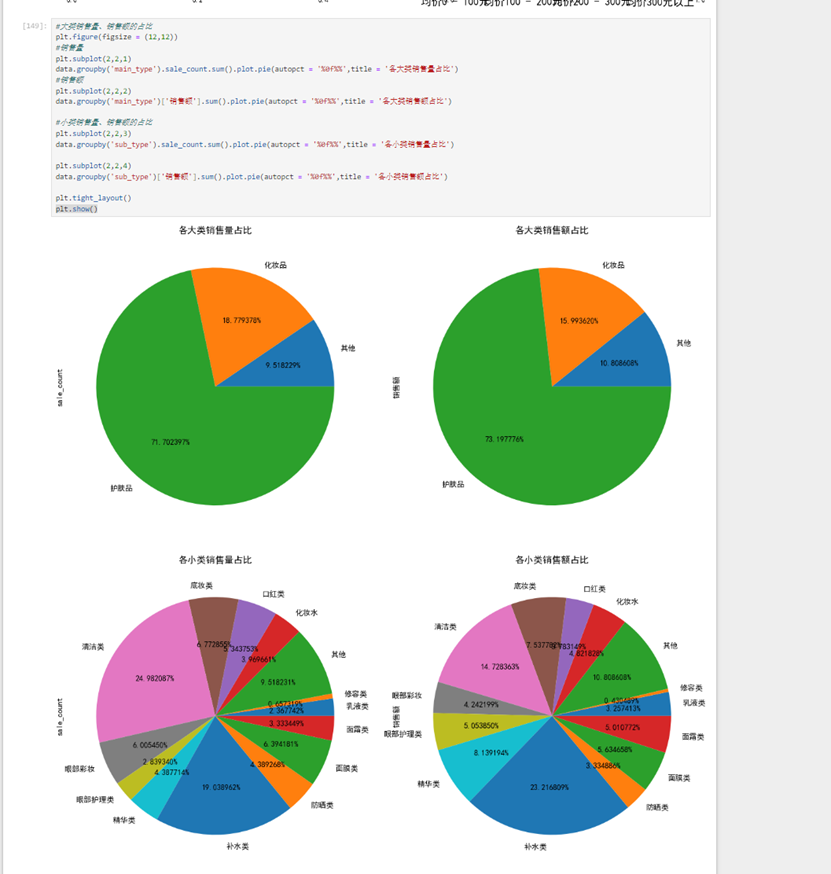
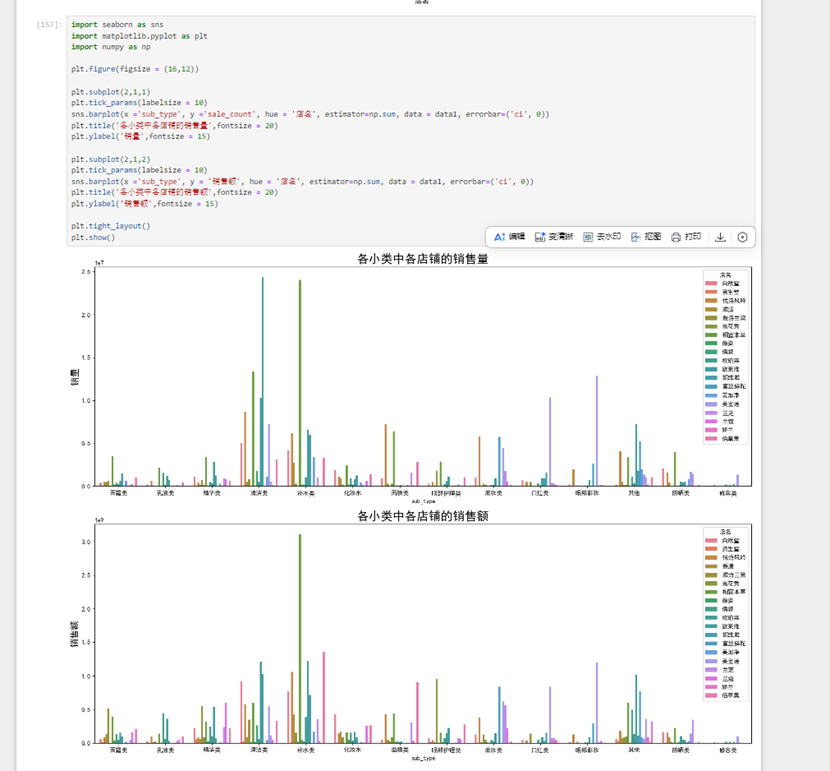
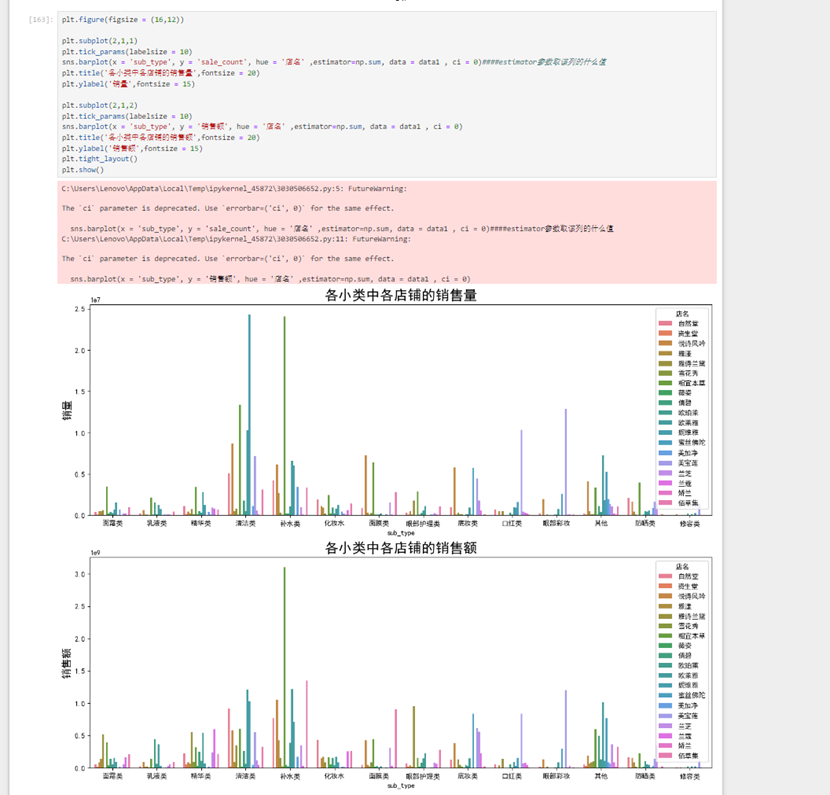
接下来用seaborn包给出每个店铺各个大类以及各个小类的销量销售额
关于性别
接下来考虑性别因素,了解各类产品在男性消费者中的销量占比
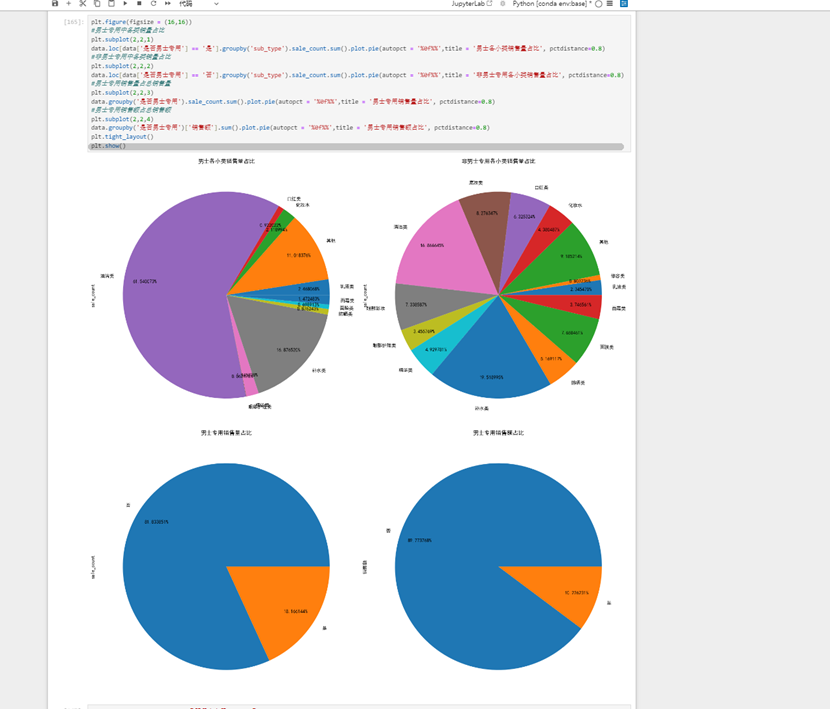
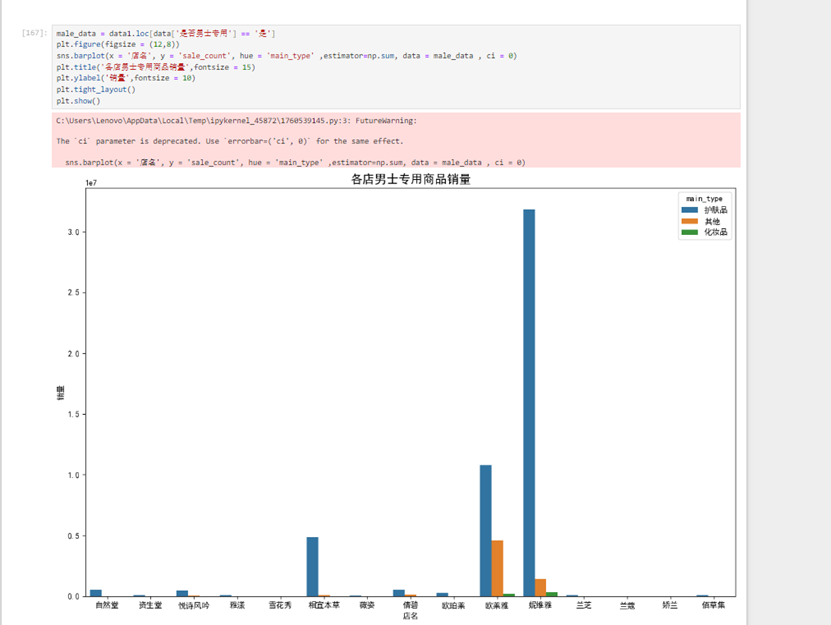
男士专用护肤品的销售量前三名分别是:妮维雅,欧莱雅,相宜本草。所有男士商品主要销量来自于护肤品。对于其他类这里暂时不进行分析,因为其产生大概率是basic_data也就是我们的分类集不完善导致的。观察一下男用化妆品的数据,如下:
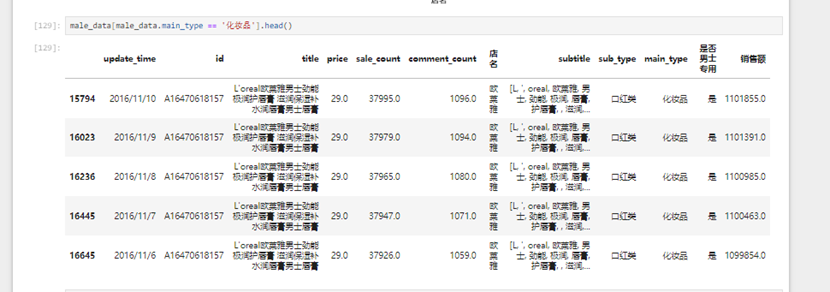
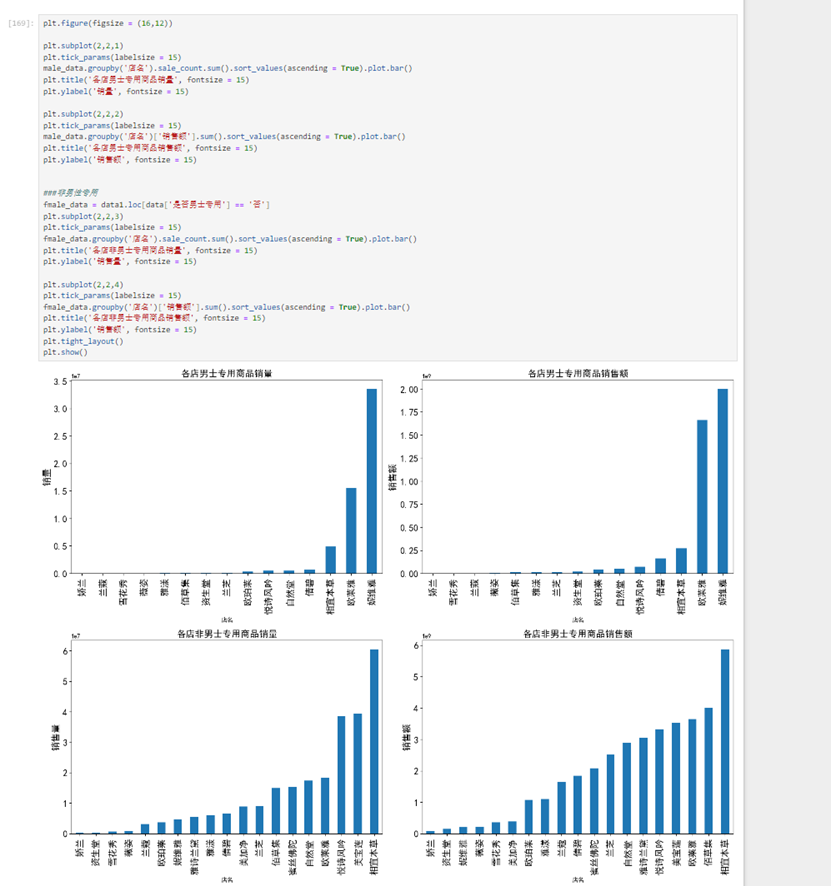
可以看出基本都是男用唇膏。因为将唇膏归于了口红类,而口红类归于了化妆品类。接下来看看各个店铺的男士专用商品的总销量销售额是怎样的
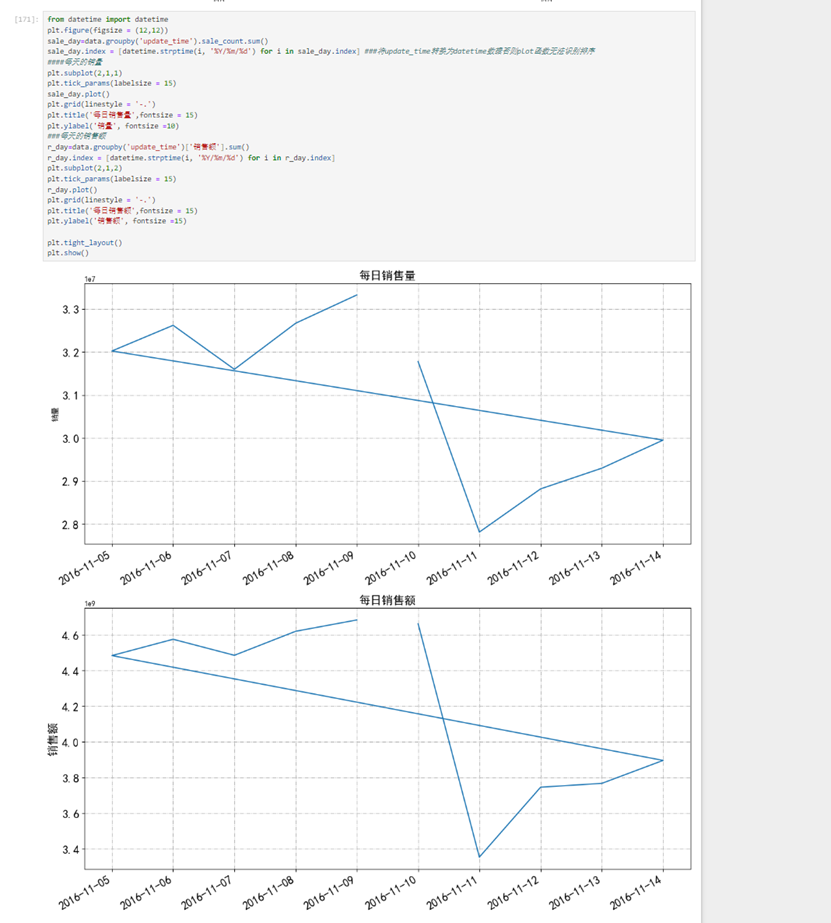
关于时间
对评论数进行分析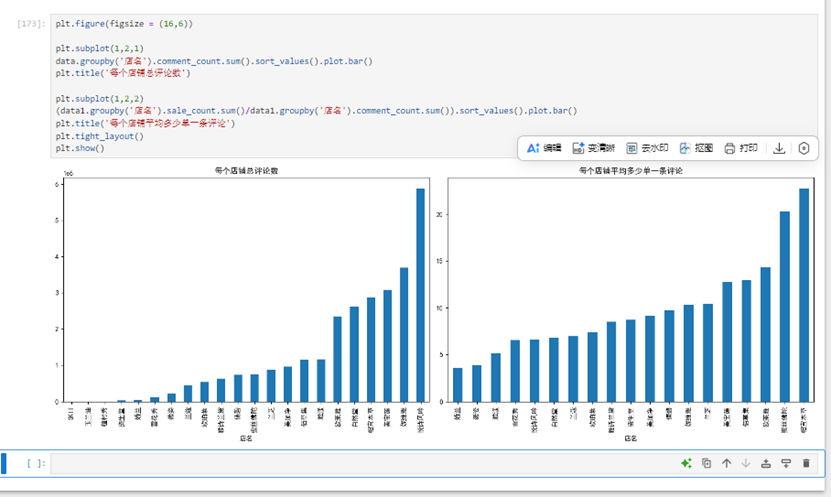


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









