







2.2 非阻塞的计数器
程序清单 15-2 基于 CAS实现了一个线程安全的计数器。自增操作遵循了经典形式 —取得旧值 ,根据它计算出新值 (加 1),并使用 CAS设定新值。如果 CAS失败 ,立即重试操作 .尽管在竞争十分激烈的情况下 ,更希望等待或者回退 ,以避免重试造成的活锁 ,但是 ,通常反复重试都是合理的策略。但在一些竞争很激烈的情况下,更好的方式时在重试之前首先等待一段时间或者回退,从而避免造成或锁问题。
程序清单 15-2 基于CAS实现的非阻塞计数器
@ThreadSafepublic
public class CasCounter {
private SimulatedCAS value;
public int getValue() {
return value.get();
}
public int increment() {
int v;
do {
v = value.get();
} while (v != value.compareAndSwap(v, v + 1));
return v + 1;
}
}
初看起来,虽然 Java语言的锁定语法比较简洁,基于 CAS的计数器看起来也比基于锁的计数器性能差一些 : 它具有更多的操作和更复 杂的控制流 ,表面看来还依赖于复 杂的 CAS的操作。但是 ,实际上基于 CAS的计数器 ,性能上 远远胜过了基于锁的计数器 ,而在没有竞争时甚至更高。原因有二:
i。 JVM和 OS管理锁的工作却并不简单 .加锁需要遍历 JVM中整个复 杂的代码路径 ,并可能引起系统级的加锁、线程挂起以及上下文切换。在最优的情况下 ,加锁需要至少一个 CAS,所以使用锁时没有用到 CAS ,但实际上也不能节省任何执行开销。
ii。另一方面 ,程序内部执行 CAS不会调用到 JVM的代码、系统调用或者调度活动。在应用级看起来越长的代码路径 ,在考 虑到 JVM和 OS的时候 ,事实上会变成更短的代码。
一个很管用的经验法则是,在大多数处理器上,在无竞争的锁获取和释放上的开销,大约是 CAS开销的两倍。
CAS最大的缺点 :它强迫调用者处理竞争问题 (通过重试、回退 ,或者放弃 );然而在锁中可以通过阻塞自动处理竞争问题, CAS最大的缺陷在于难以正确地构建外围算法。
2.3 JVM 对 CAS 的支持
在 Java 5.0中引入了底层的支持,在 int、 long和对象的引用等类型上都公开了 CAS操作,并且 JVM把它们编译为底层硬件提供的最有效方法。在支持 CAS的平台上,运行时把它们编译为相应的(多条) 机器指令 。在最坏的情况下,如果不支持 CAS指令,那么 JVM将使用 自旋锁 。
在原子变量类(如java.util.conncurrent.atomic 中的AtomicXxx )中使用了这些底层的JVM 支持为数字类型和引用类型提供一种高效的CAS 操作,而且在java.util.concurrent 中大多数类在实现时则直接或间接的使用这些原子变量类。
15.3 原子变量类
原子变量比锁的粒度更细,量级更轻,并且对于在多处理器系统上实现高性能的并发代码来说是非常关键的。原子变量将发生竞争的范围缩小到单个变量上,这是获得粒度最细的情况。更新原子变量的快速 (非竞争 )路径 ,并不会比获取锁的快速路径差 ,并且通常会更快 ;而慢速路径肯定比锁的慢速路径快 ,因为它不会引起线程的挂起和重新调度。在使用基于原子变量而非锁的算法中,线程在执行时更不易出现延 迟,并且如果遇到竞争,也更容易恢复过来。
原子变量类相当于一个泛化的 volatile变量,能够支持原子的和有条件的读 -改 -写操作。以 AtomicInteger为例,该原子类表示一个 int类型的值,并提供 get和 set方法,这些 volatile类型的 int变量在读取和写入上有着相同的语义。它还提供了一原子的 compareAndSet方法,以及原子的添加、递增和递减等方法。 AtomicInteger在发生竞争的情况下能提供更高的可伸缩性,因为它直接利用了硬件对并发的支持。
共有12 个原子变量类,可分为四组:标量类(Scalar )、更新器类、数组类及复合变量类。最常用的原子变量就是标量类:AtomicInteger 、AtomicLong 和AtomicBoolean 以及AtomicReference 。所有这些类都支持CAS ,此外AtomicInteger 和AtomicLong 还支持算术运算。
原子数组类中的元素可以实现原子更新。原子数组类为数组的元素提供了 volatile类型的访问语义,这是普通数组所不具备的特性。 volatile类型的数组仅在数组引用上具有 volatile语义,而在其元素上没有。
尽管原子的标量类扩展了 Number类,但并没有扩展一些基本的包装类,这是因为:基本类型的包装类是不可修改的,而原子变量类是可修改的。在原子变量类中同样没有重新定义 hashCode或 equals方法,每个实例都是不同的。与其他可变对象相同,他们也不宜用做基于散列的容器中的键值对。
3.1 性能比较:锁与原子变量
为了说明锁和原子变量之间的可伸缩性差异,我们构造了一个测试基准,其中将比较伪随机数生成器( PRNG )的几种不同的实现,在 PRNG中,在生成一个随机数时需要用到一个数字,所以在 PRNG中必须记录前一个数值并将其作为状态的一部分。
在程序清单 15-4和 15-5中给出了线程安全的 PRNG的两种实现,一种使用 ReentrantLock ,另一种使用 AtomicInteger。测试程序反复调用他们,在每次迭代中将随机生成一个数字,并执行一些仅在线程本地数据上执行的 “繁忙 ”迭代。这是一种典型的操作模式,以及在一些共享状态以及线程本地状态上的操作。
程序清单 15-4 基于ReentrantLock实现的随机数生成器
@ThreadSafe
public class ReentrantLockPseudoRandom {
private final Lock lock = new ReentrantLock();
private int seed;
public ReentrantLockPseudoRandom(int seed) {
this.seed = seed;
}
public int nextInt(int m) {
lock.lock();
try {
int s = seed;
seed = calculateNext(s);
int remainder = s % n;
return remainder > 0 ? remainder : remainder + n;
} finally {
lock.unlock();
}
}
}
程序清单 15-5 基于AtomicInteger实现的随机数生成器
@ThreadSafe
public class AtomicPseudoRandom {
private AtomicInteger seed;
public AtomicPseudoRandom(int seed) {
this.seed = new AtomicInteger(seed);
}
public int nextInt(int m) {
while (true) {
int s = seed;
int nextSeed = calculateNext(s);
if (seed.compareAndSet(s, nextSeed)) {
int remainder = s % n;
return remainder > 0 ? remainder : remainder + n;
}
}
}
}
图 15-1和图 15-2给出了在媒体迭代中工作量较低以及适中情况下的吞吐量。如果线程本地的计算较少,那么在锁和原子变量上的竞争将非常激烈。如果线程本地的计算量较多,那么在锁和原子变量上的竞争就会降低,因为在线程中访问锁和原子变量的频率将降低。
从图中可以看出,在高度竞争的情况下,锁的性能将超过原子变量的性能。原因是,使用原子变量时, CAS算法在遇到竞争时将立即重试,通常这是一种正确的方法,但是在竞争激烈的环境下却导致了更多的竞争。
而在竞争适中的情况下,原子变量的性能将 远超过锁的性能,这是因为锁在发生竞争时会挂起线程,从而降低了 CPU的使用率和共享内存总线上的同步通信量。
注意,我们应该意识到,图 15-1中的竞争级别过高而有些不切实际:任何一个真实程序都不会出了竞争锁或原子变量,其他设么工作都不做。
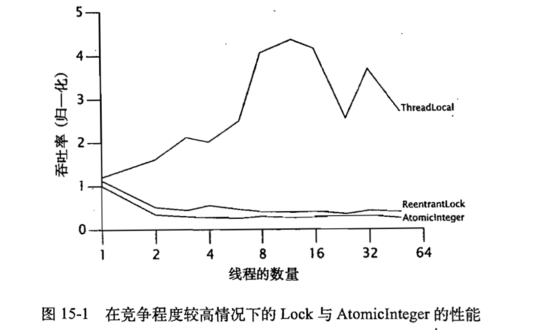
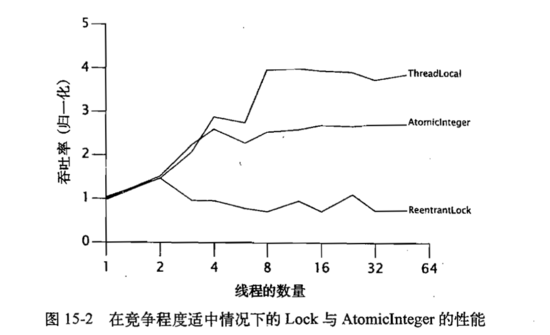
锁与原子变量在不同竞争程度上的性能差异很好的说明了各自的优势和劣势。在中低程度的竞争下,原子变量能提供更高的可伸缩性,而在高强度的竞争下,锁能更有效的避免竞争。
在图 15-1和图 15-2中都包含了第三掉曲线,他是一个使用 ThreadLocal来保存 PRNG状态的 PseudoRandom。这种实现方法改变类的行为,即每个线程都只能看到自己私有的,而不是共享的伪随机数字序列,这说明了能够避免使用共享状态,开销将会更小。
15.4 非阻塞算法
基于锁的算法会带来一些活跃度的风险 . 如果线程在持有锁的时候因为阻塞 I/O,页面错误 ,或其他原因发生延 迟 ,很可能所有线程都不能继续执行下去。如果在某种算法中,一个线程的失败或挂起不应该影响其他线程的失败或挂起 ,这样的算法被称为非阻塞 (nonblocking)算法。如果在算法的每一步骤中都有一些线程能够继续执行 ,那么这样的算法称为无锁 (lock-free)算法。
如果在算法中仅将 CAS用于协调线程之间的操作,并且能构建正确的话 ,那么它既是非阻塞的 ,又是无锁的。
在非阻塞算法中,通常不会出现死锁和优先级反转问题 (但可能会出现饥饿和活锁 ,因为他们允许重进入 )。在许多常见的数据结构中都可以使用非阻塞算法,包括栈、队列、优先级队列以及散列表等,而要设计一些新的这种数据结构,最好还是由专家们来完成。
15.5 ABA 问题
ABA问题是一种异常现象:如果在算法中的节点可以被循环使用,那么使用 “比较并交换 ”指令就可能会出现这种问题。在某些算法中,如果 V的值首先由 A变成 B ,再由 B变成 A ,那么仍然被认为是发生了变化,并需要重新执行算法中的某些步骤。
如果在算法中采用自己的方式来管理节点对象的内存,那么可能出现 ABA问题。一种相对简单的解决方案是:不是更新某个引用的值,而是更新两个值,包括一个引用和一个版本号。即使这个值由 A变为 B ,然后又变为 A ,版本号也将是不同的。
AtomicStampedReference (以及AtomicMarkableReference )支持在两个变量上执行原子的条件更新。AtomicStampedReference 将更新一个“ 对象- 引用” 二元组,通过在引用上加上“ 版本号” ,从而避免ABA 问题。类似的,AtomicMarkableReference 将更新一个“ 对象引用- 布尔值” 二元组,,在某些算法中将通过它将节点保存在链表中同时又将其标记为“ 已删除的节点” 。
小结
非阻塞算法通过底层的并发原语来保证线程的安全性,如CAS比较交换而不是使用锁。这些底层原语通过原子变量类向外公开,这些类也用做一种“更好的volatile变量”,从而为整数和对象引用提供原子的更新操作。
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
-1714852676110)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 274
274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









