







 本文详细介绍了如何使用Python的BeautifulSoup库和requests库从Biquge网站爬取小说名称、创建文件夹、解析章节标题和链接,以及下载小说正文的过程。
本文详细介绍了如何使用Python的BeautifulSoup库和requests库从Biquge网站爬取小说名称、创建文件夹、解析章节标题和链接,以及下载小说正文的过程。
from bs4 import BeautifulSoup
url = ‘‘https://www.biquge.com.cn/book/23341/’’
response= requests.get(url) # requests访问网址,获得的内容放入response
获得的内容放入response变量(自定义,可随意取)里。
3、BeautifulSoup解析网页获得内容
用BeautifulSoup解析response变量里的内容,方法为:
import requests
from bs4 import BeautifulSoup
url = ‘‘https://www.biquge.com.cn/book/23341/’’
response= requests.get(url)
soup = BeautifulSoup(response.content, ‘lxml’) # BeautifulSoup解析response里的内容,放入soup里
现在网页内容已经被赋值到变量soup了,此时若打印s,会得到上面图2红框的内容。
4、解析内容爬取小说名,并用其创建一个文件夹,以备放后面下载的小说正文
通过在response里查找,我们发现标题在图3如下位置有出现:
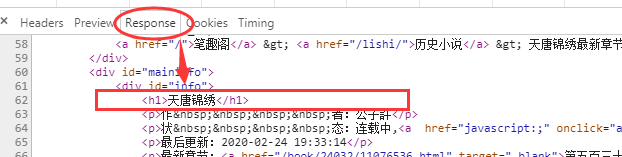
图3
booktitle = soup.find(‘h1’).text
if not os.path.isdir(booktitle): # 判断当前文件夹下是否存在和小说名同名的文件夹
os.makedirs(booktitle) # 若不存在,则创建小说同名文件夹

图4,爬取小说名
5、继续用BeautifulSoup解析soup内容,获得章节标题及网址
继续在图2response里查找,发现章节信息都在dd标签下的a标签里,如图5:
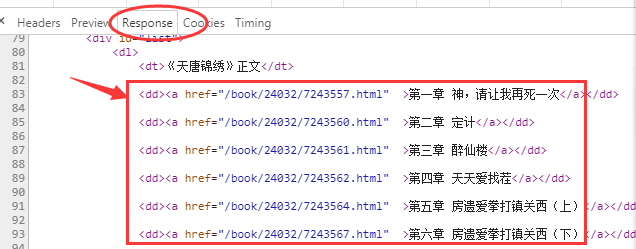
编辑切换为居中
添加图片注释,不超过 140 字(可选)
图5
提取章节标题和链接代码:
import requests
from bs4 import BeautifulSoup
…
…
dd = soup.find_all(‘dd’)
for i in range(len(dd)):
title = dd[i].find(‘a’).text # 获得章节名
chap_url = dd[i].find(‘a’)[‘href’] # 获得章节链接
print(title, ': ", chap_url) # 临时打印查看效果如下图

图6
5、循环遍历访问章节链接,获得小说正文
通过上面的操作,我们获得了每一章节页面的具体网址链接,继续用requests访问链接,就能获得小说的网页页面,接着用BeautifulSoup解析获得小说内容。我们可用简单方法,快速找到小说内容所在位置:在小说页面正文区域右键单击,选择“检查”或“审查元素”,会自动弹出浏览器控制台并高亮显示的正文在网页页面里的位置,分析确定提取参数即可。
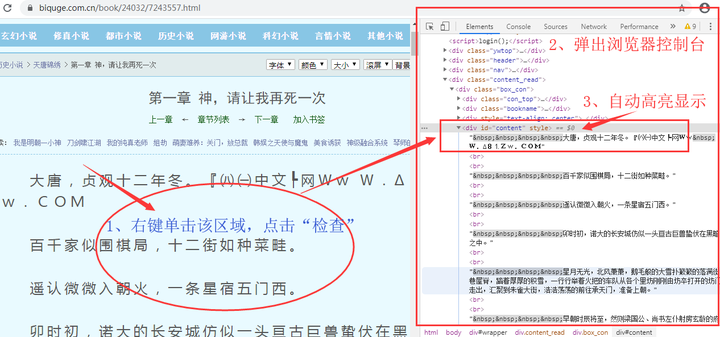
图7

自动高亮显示位置
通过上面的操作,我们能轻松的找到小说文本在网页里的位置,并能知道两个参数,标签:‘div’;id:‘content’,然后通过这两个参数提取出小说文本。
import requests
from bs4 import BeautifulSoup
…
…
for i in range(len(dd)):
if i == 2: # 临时设置只看第3篇文章的打印效果,用于调试
title = dd[i].find(‘a’).text
chap_url = dd[i].find(‘a’)[‘href’]
response1 = requests.get(‘https://www.biquge.com.cn’ + chap_url) #访问链接
soup1 = BeautifulSoup(response1.content, ‘lxml’) # 获得网页
text = soup1.find(‘div’, id=‘content’).text #解析网页获得小说正文
print(text) # 试打印看效果
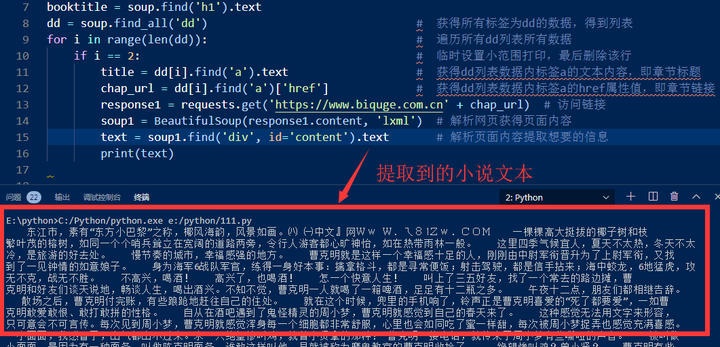
图8,打印第3篇正文成功
6、保存结果
f = open(path + ‘/’ + title + ‘.txt’, ‘a+’, encoding=‘utf-8’) # 设置章节标题为文件名
f.write(text) # 写入小说正文
至此,代码完成,能放心下载了。
7、运行效果
我们在完整代码里,设置一次性下载100章节的代码,来看看下载的效果。完整代码:
import requests, os
from bs4 import BeautifulSoup
url = ‘https://www.biquge.com.cn/book/23341/’
response = requests.get(url)
soup = BeautifulSoup(response.content, ‘lxml’)
booktitle = soup.find(‘h1’).text
if not os.path.isdir(booktitle): # 判断当前文件夹下是否存在和小说名同名的文件夹
os.makedirs(booktitle) # 若不存在,则创建小说同名文件夹
dd = soup.find_all(‘dd’)
for i in range(len(dd)):
if i < 100:
title = dd[i].find(‘a’).text
chap_url = dd[i].find(‘a’)[‘href’]
response1 = requests.get(‘https://www.biquge.com.cn’ + chap_url)
soup1 = BeautifulSoup(response1.content, ‘lxml’)
text = soup1.find(‘div’, id=‘content’).text
f = open(booktitle + ‘/’ + title + ‘.txt’, ‘a+’, encoding=‘utf-8’)
f.write(text)
print("正在下载《 {} 》… {} / {} ".format(title, i+1, len(dd)))
else:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









