








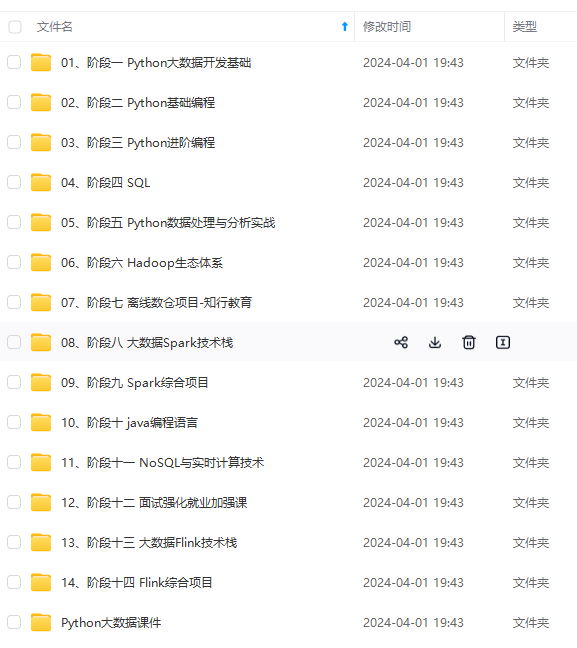
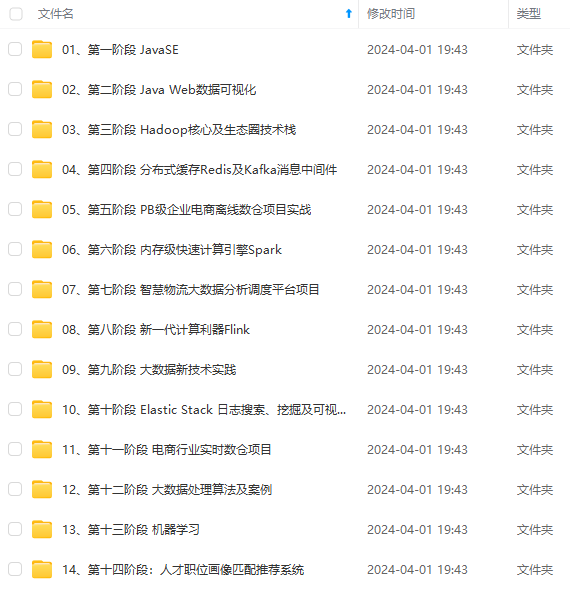
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

**第4章ZooKeeper原理及应用;**ZooKeeper是一个分布式协调服务,其设计的初衷是为分布式软件提供一致性服务。ZooKeeper提供了一个类似Linux文件系统的树形结构,ZooKeeper的每个节点既可以是目录也可以是数据,同时,ZooKeeper提供了对每个节点的监控与通知机制。基于ZooKeeper的一致性服务,可以方便地实现分布式锁、分布式选举、服务发现和监控、配置中心等功能。

**第5章Kafka原理及应用;**Kafka是一种高吞吐、分布式、基于发布和订阅模型的消息系统,最初由LinkedIn公司开发,使用Scala编写,目前是Apache 的开源项目。Kafka用于离线和在线消息的消费。Kafka将消息数据按顺序保存在磁盘上,并在集群内以副本的形式存储以防止数据丢失。
Kafka依赖ZooKeeper进行集群的管理,Kafka 与Storm、Spark能够非常友好地集成,用于实时流式计算。

**第6章Hadoop原理及应用;**Hadoop是一个大数据解决方案,提供了一套分布式系统基础架构,核心内容包含HDFS ( Hadoop Distributed File System,分布式文件系统)、MapReduce计算引擎和YARN ( Yet Another Resource Negotiator,另一种资源协调者)统一资源管理调度。
其中,HDFS分为NameNode和DataNode,NameNode负责保存元数据的基本信息,DataNode负责具体数据的存储。MapReduce分为JobTracker和TaskTracker,JobTracker负责任务的分发,TaskTracker负责具体任务的执行。
Hadoop集群是Master/Slave (M/S)架构,NameNode和JobTracker运行在Master节点上,DataNode和 TaskTracker运行在Slave节点上。

**第7章HBase原理及应用;**HBase是一个开源的分布式Key-Value数据库,其主要作用是面向数十亿级数据的实时人库和快速随机访问。HBase底层存储基于HDFS实现,集群的管理基于ZooKeeper实现。HBase良好的分布式架构设计为海量数据的快速存储、随机访问提供了可能,基于数据副本机制和分区机制可以轻松实现在线扩容、缩容和数据容灾,是大数据领域中Key-Value数据结构存储最常用的数据库方案。

**第8章Cassandra原理及应用;**Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,于2008年开源。Cassandra由于良好的可扩展性、高性能和PP去中心化的设计,迅速成为分布式存储中十分流行的数据存储方案。

**第9章ElasticSearch原理及应用;**ElasticSearch是一个分布式、基于RESTful风格的数据搜索和分析引擎,由Elastic公司开发并基于Apache许可条款发布源码。ElasticSearch的底层全文检索基于Lucene实现,其灵活的数据存取和分析方式、良好的性能和稳定性使其在大数据存储和分析领域被广泛使用。

**第10章Spark原理及应用;**Apache Spark是通用的分布式大数据计算引擎。Spark是UC Berkeley AMPLab(美国加州大学伯克利分校的AMP实验室)开源的通用并行框架。Spark拥有HadoopMapReduce所具有的优点,但不同于Hadoop MapReduce的是,Hadoop每次经过Job执行的中间结果都存储到HDFS等磁盘上,而Spark的Job中间输出结果可以保存在内存中,而不再需要读写HDFS。因为内存的读写速度与磁盘的读写速度不在一个数量级上,所以Spark利用内存中的数据能更快速地完成数据的处理。
Spark启用了弹性分布式数据集(Resilient Distributed Dataset,RDD),除了能够提高交互式查询效率,还可以优化迭代器的工作负载。由于弹性分布式数据集的存在,使得数据挖掘与机器学习等需要迭代的MapReduce的算法更容易实现。

**第11章Flink原理及应用;**Flink是一个分布式计算引擎,主要用于有界数据流和无界数据流的有状态的数据分析和处理。Flink擅长处理有界数据流和无界数据流,其精确的时间控制和状态化使Flink能够安全并快速地处理海量数据。
Flink 将数据抽象为有界数据流和无界数据流。
Flink 由Job Manager、Task Manager和客户端组成。Job Manager是管理节点,负责集群任务的提交、分配和资源管理;Task Manager是具体执行任务的计算节点﹔客户端用于作业的提交。

这份【java面试核心知识点核心篇】共有399页,需要完整版的朋友,可以转发此文关注小编,扫码获取!!!

专家对本文的热评
========

Java程序员很大部分从事Web方向和大数据应用开发方向,对于后者来说,除了编程语言等基础知识,了解大数据组件也是一个重要的部分。本文涵盖了常用大数据组件的重要基础知识,对于相关从业人员是很好的读物。
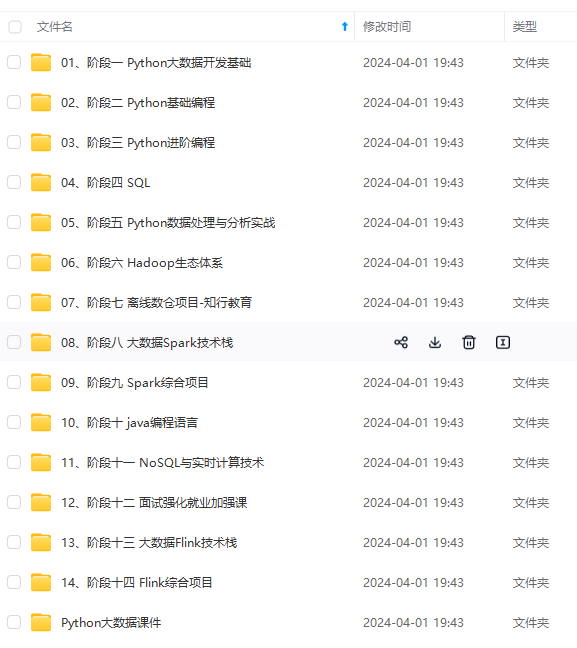
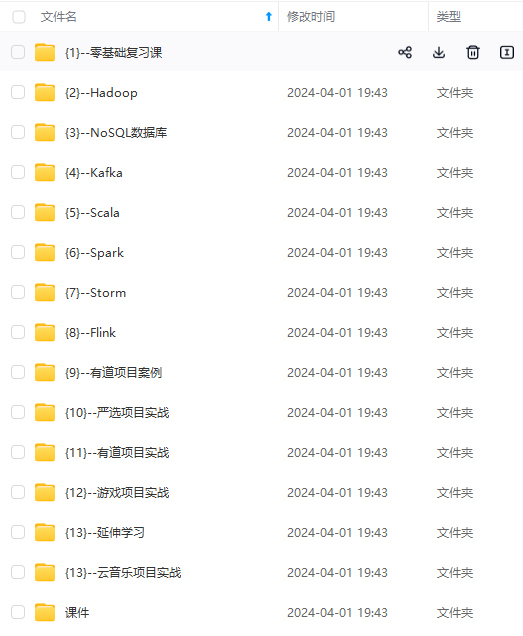
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
csdn.net/topics/618545628)**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









