






 本文介绍了如何使用Labelimg进行图像数据标注,步骤包括创建标注文件voc-classes.txt,以及如何使用YOLO模型进行目标检测。详细讲解了训练过程,包括所需库的安装、VOC数据集处理、训练和预测的代码实现。结果显示模型对person类别有良好标注能力。
本文介绍了如何使用Labelimg进行图像数据标注,步骤包括创建标注文件voc-classes.txt,以及如何使用YOLO模型进行目标检测。详细讲解了训练过程,包括所需库的安装、VOC数据集处理、训练和预测的代码实现。结果显示模型对person类别有良好标注能力。
一、labelimg进行数据标注
第一步:打开labelimg.exe
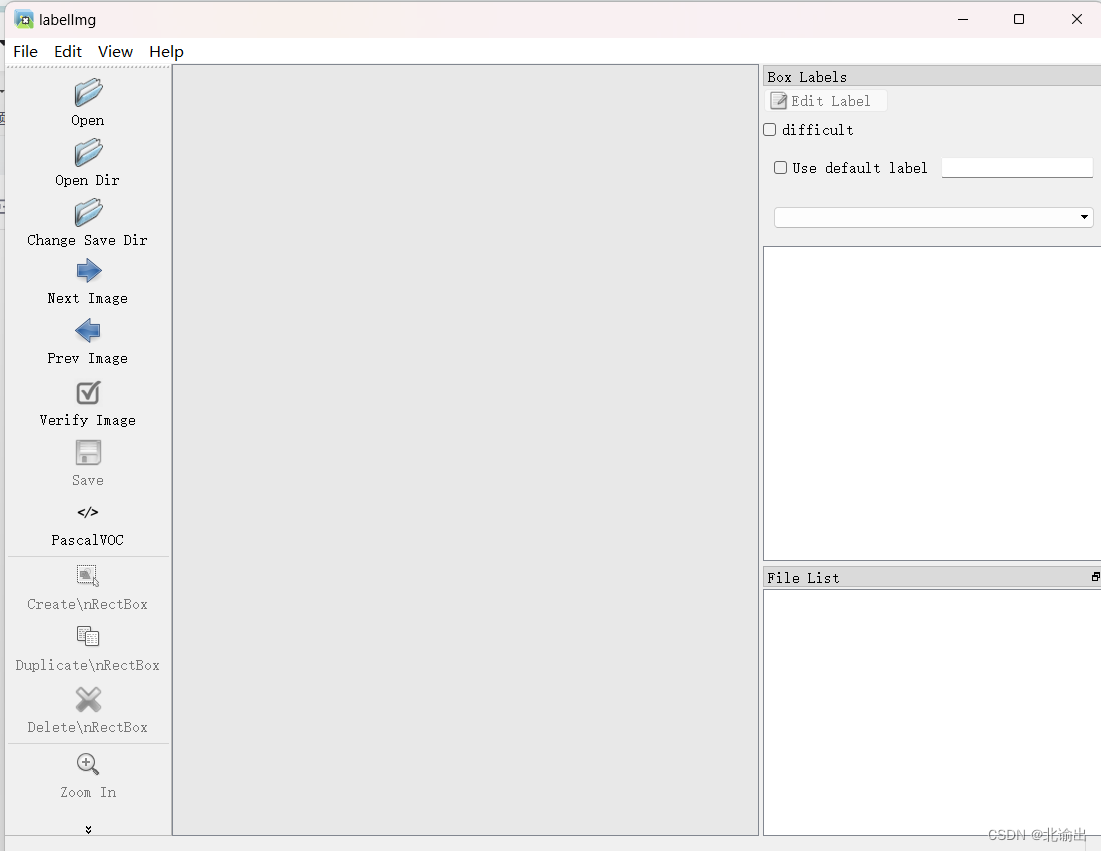
第二步:点击open dir,打开一个数据集文件夹(JPEGimages),里面放着进行训练标注的图片
第三步:点击change save dir,选择一个空文件夹(annotations),用来放置标注后图片的标注内容和具体信息
注--pascalVOC指的是标注图片后的文件类型是.xml(一般用),yolo指的是.txt格式
第四步:点击create/nrectbox对图片进行标注,出现一个直角坐标

从左上拉到右下角,保证框内存在完整的目标且没有多余的部分,后添加符合的标注
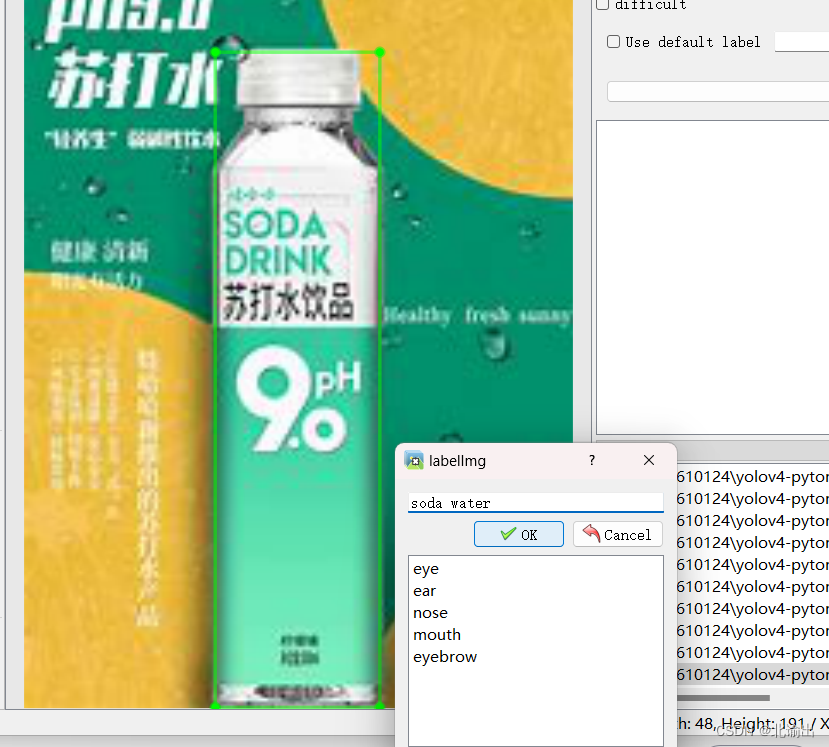

图中有几个目标则进行依次标注

第五步:单击“D”键进行保存生成.xml文件,并进入下一张图片
第六步:不断标注目标图像,图像角度越多数量越多训练效果越好,损失率越小
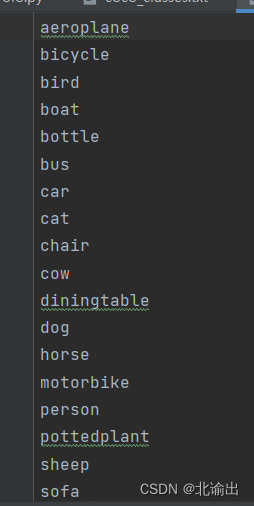
二、编写目标集文件voc-classes.txt
在文件里加入所有label,按行排列
三、yolo简介
YOLO是目标检测模型。用来在一张图篇中找到某些特定的物体,目标检测不仅要求我们识别这些物体的种类,同时要求我们标出这些物体的位置。类别是离散数据,位置是连续数据。
当想要准确标注一张图片所有的目标时,我们可能会因为目标过小、目标位置过偏或者种类过多而导致错误率更大,使图片不易标注。
原理:YOLO 的预测是基于整个图片的,并且它会一次性输出所有检测到的目标信息,包括类别和位置。YOLO的第一步是分割图片,它将图片分割为个grid,每个grid的大小都是相等的;它不需要设计非常非常大的框,只需要让物体的中心在这个框中就可以了,而不是必须要让整个物体都在这个框中;让
个框预测出b个bounding box,其中bounding box有5个量,分别是物体的中心位置(x,y)和它的高(h)和宽(w),以及预测的置信度;bounding box中有的边框比较粗,有的比较细,这是置信度不同的表现,置信度高的比较粗,置信度低的比较细。
四、测试运行代码
第一步:安装所需库
numpy: 用于在Python中进行科学计算,特别是对多维数组进行操作。- torch: PyTorch深度学习框架,用于构建和训练神经网络模型。
- OpenCV: 用于图像处理和计算机视觉任务,如加载、显示和处理图像。
PIL: 用于图像处理,包括图像的加载、保存和绘制。tqdm: 在 Python 中显示进度条的库,可以在循环和迭代过程中显示进度条.- TensorBoard : 用于可视化深度学习模型训练过程和结果的工具。
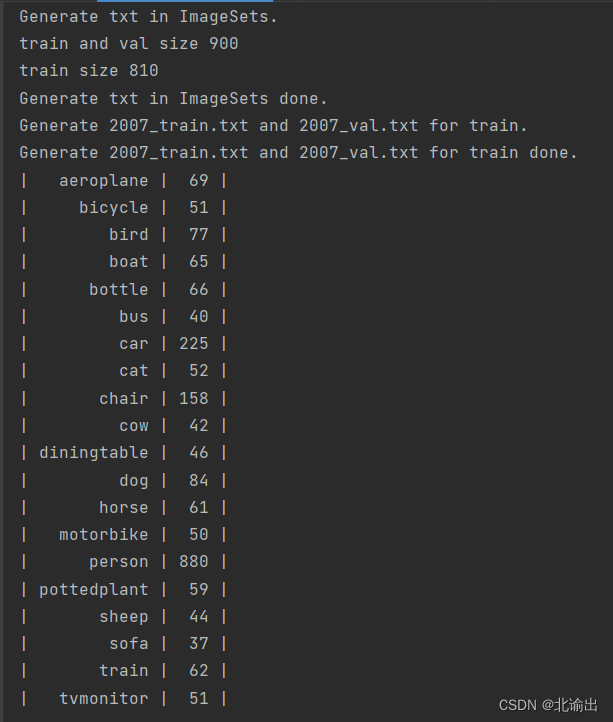
第二步:运行voc_annotation.py,是用于处理VOC数据集的标签文件,生成训练和验证过程中需要的txt文件
- 读取类别信息:从给定的
classes_path文件中获取类别信息。 - 遍历XML标注文件:根据指定的VOC数据集路径,遍历每个图片对应的XML标注文件,提取目标的坐标和类别信息。
- 生成训练集和验证集:根据指定的比例,将数据集分割成训练集和验证集,并将每个样本的信息写入对应的txt文件中。
- 根据指定的VOC数据集路径和文件名,生成对应的训练集和验证集的txt文件。其中,遍历了给定的列表,并根据每个元素是否在训练集中进行判断,然后将对应的图片名称写入不同的txt文件中。
- 如果
annotation_mode为0或2,则生成2007年的训练集和验证集的txt文件。这部分代码遍历了VOC数据集中的图片集合,并将图片路径写入txt文件中,同时调用了convert_annotation函数,将标注信息写入txt文件。 - 打印一个表格,显示了类别名称和对应的数量。
- 进行了一些条件判断,例如如果训练集数量小于500,则打印警告信息。另外,如果未获得任何目标,也会打印相应的提示信息。
第三步:运行train.py文件,对数据集进行训练
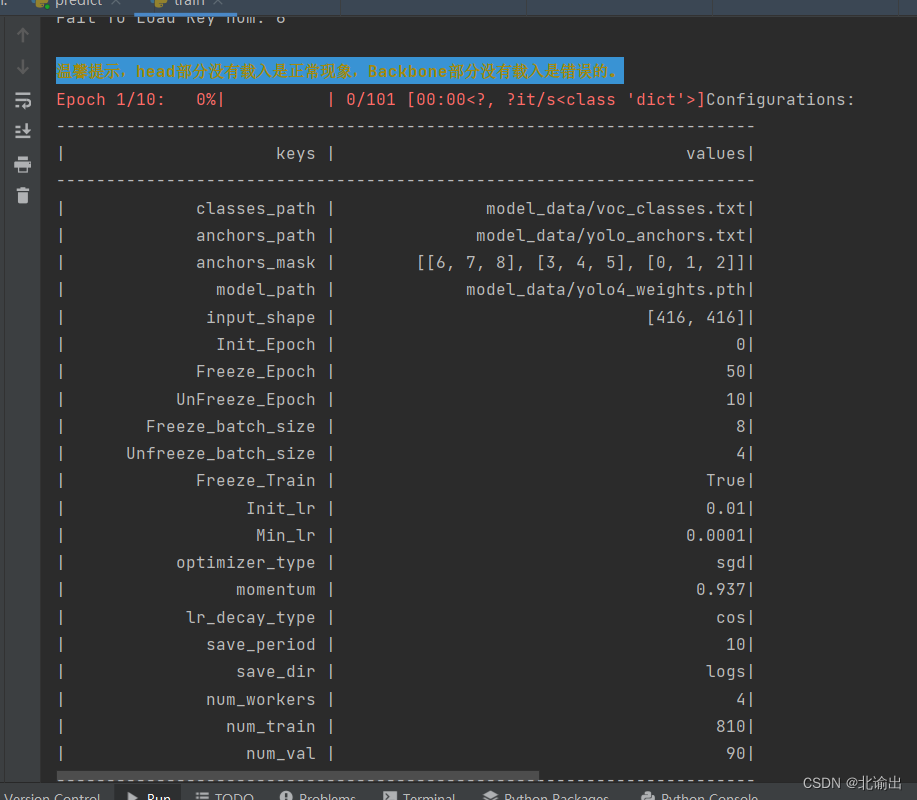
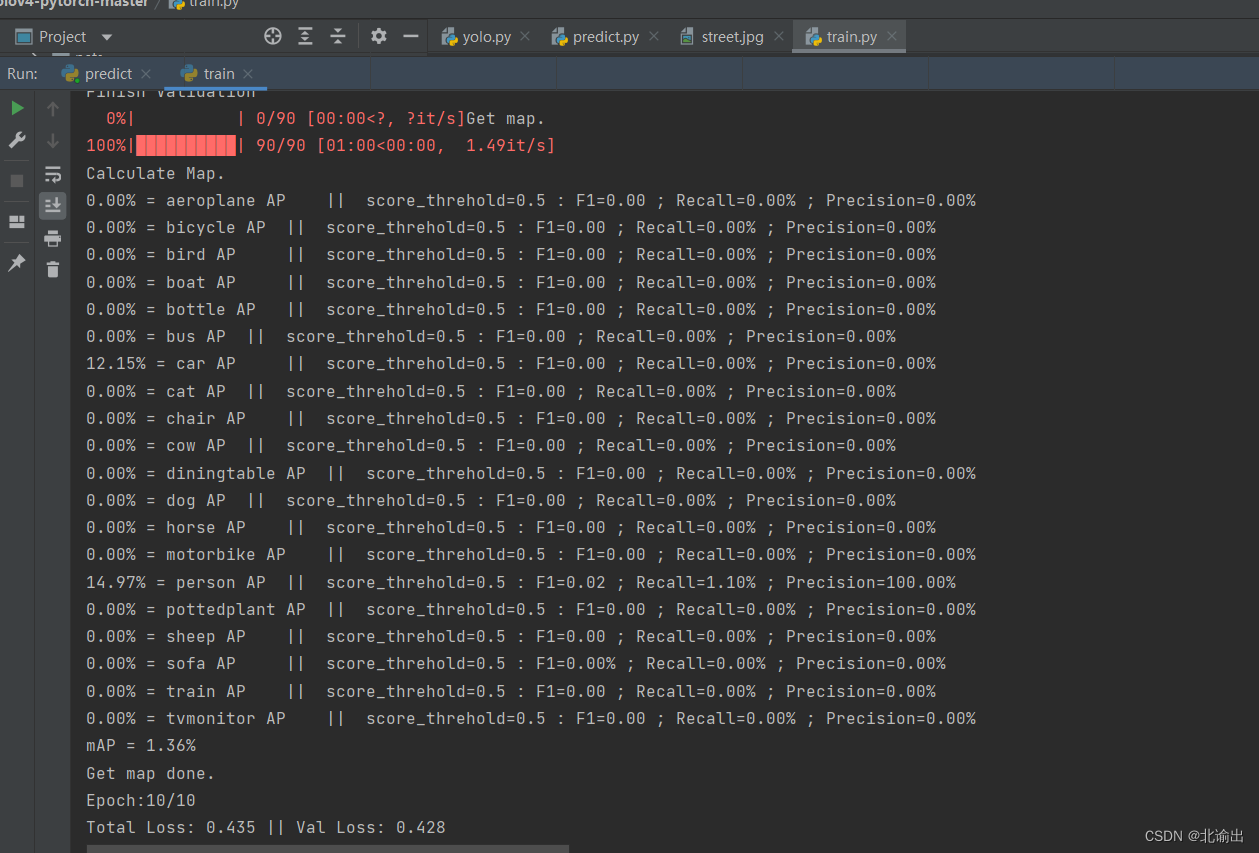
注:使用sgd优化器时,建议将训练总步长设置到50000以上。
为了测试代码,本次迭代次数设置为10,因此本次总训练数量为810,unfreeze_batch_size为4,共训练10个epoch,总步长为2020。
第四步:运行predict.py文件,进行分类预测
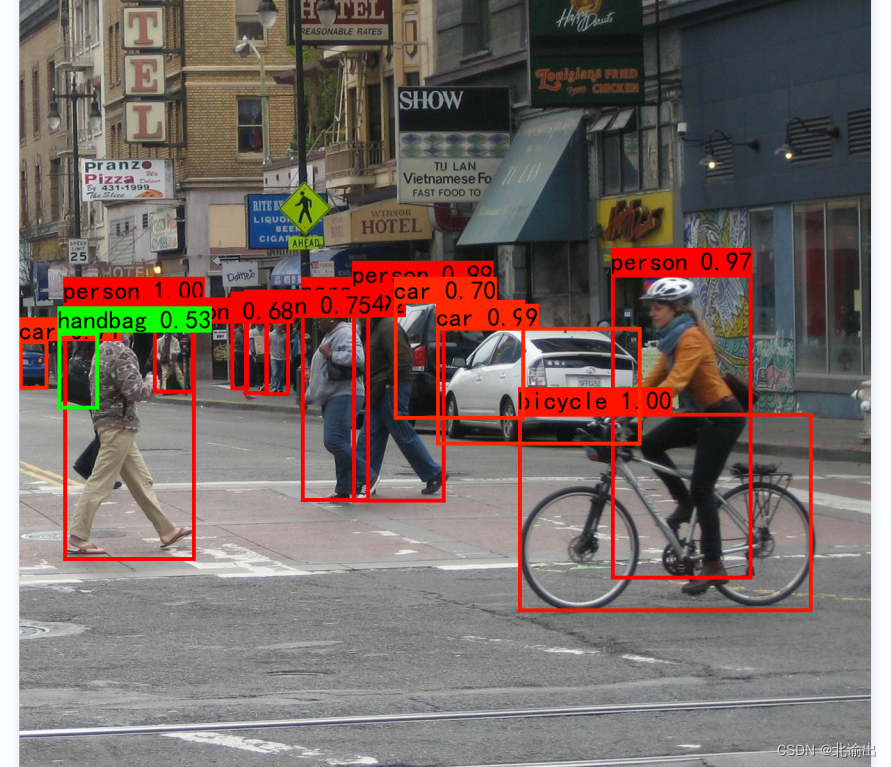
将目标图片放置在img文件夹里并命名为1.jpg,运行代码后输入图片:./img/1.jpg


由上图的标注可以看出,分类器将voc-classes.txt中存在的labelname--person全都准确标注了出来。由此看出,训练的模型效果优秀。















 1697
1697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









