






MD5信息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。MD5由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)设计,于1992年公开,用以取代MD4算法。这套算法的程序在 RFC 1321 标准中被加以规范。1996年后该算法被证实存在弱点,可以被加以破解,对于需要高度安全性的数据,专家一般建议改用其他算法,如SHA-2。2004年,证实MD5算法无法防止碰撞(collision),因此不适用于安全性认证,如SSL公开密钥认证或是数字签名等用途。
- 中文名:消息摘要算法
- 外文名:Message Digest Algorithm MD5
- 别名:摘要算法
- 提出者:罗纳德·李维斯特
- 提出时间:1994年
MD5曾是世界上最先进的密码算法,人们一度认为即使使用最先进的计算机,也要百万年才能破解。但在2004年,中国密码学家王小云靠着一支笔、一沓稿纸,就用手算推演这种最“原始”的方式,解开了MD5的秘密。在国际密码大会上,主委会破例给了王小云比其他人多5倍的时间分享成果,汇报一度被掌声打断。会后,美国国家标准与技术研究院紧急召开研讨会,宣布“MD5已经死了,赶快撤出使用”。
发展历史
1992年8月,罗纳德·李维斯特向互联网工程任务组(IETF)提交了一份重要文件,描述了这种算法的原理。由于这种算法的公开性和安全性,在90年代被广泛使用在各种程序语言中,用以确保资料传递无误等。
MD5由MD4、MD3、MD2改进而来,主要增强算法复杂度和不可逆性。MD5算法因其普遍、稳定、快速的特点,仍广泛应用于普通数据的加密保护领域。
MD2
Rivest在1989年开发出MD2算法[3]。在这个算法中,首先对信息进行数据补位,使信息的字节长度是16的倍数。然后,以一个16位的校验和追加到信息末尾,并且根据这个新产生的信息计算出散列值。后来,Rogier和Chauvaud发现如果忽略了校验和MD2将产生冲突。MD2算法加密后结果是唯一的(即不同信息加密后的结果不同)。
MD4
为了加强算法的安全性,Rivest在1990年又开发出MD4算法[3]。MD4算法同样需要填补信息以确保信息的比特位长度减去448后能被512整除(信息比特位长度mod 512 = 448)。然后,一个以64位二进制表示的信息的最初长度被添加进来。信息被处理成512位damgard/merkle迭代结构的区块,而且每个区块要通过三个不同步骤的处理。Den boer和Bosselaers以及其他人很快的发现了攻击MD4版本中第一步和第三步的漏洞。Dobbertin向大家演示了如何利用一部普通的个人电脑在几分钟内找到MD4完整版本中的冲突(这个冲突实际上是一种漏洞,它将导致对不同的内容进行加密却可能得到相同的加密后结果)。
MD5
1991年,Rivest开发出技术上更为趋近成熟的MD5算法。它在MD4的基础上增加了"安全带"(safety-belts)的概念。虽然MD5比MD4复杂度大一些,但却更为安全。这个算法很明显的由四个和MD4设计有少许不同的步骤组成。在MD5算法中,信息-摘要的大小和填充的必要条件与MD4完全相同。Den boer和Bosselaers曾发现MD5算法中的假冲突(pseudo-collisions),但除此之外就没有其他被发现的加密后结果了。
原理
MD5算法的原理可简要的叙述为:MD5码以512位分组来处理输入的信息,且每一分组又被划分为16个32位子分组,经过了一系列的处理后,算法的输出由四个32位分组组成,将这四个32位分组级联后将生成一个128位散列值。
总体流程如下图所示,每次的运算都由前一轮的128位结果值和当前的512bit值进行运算。
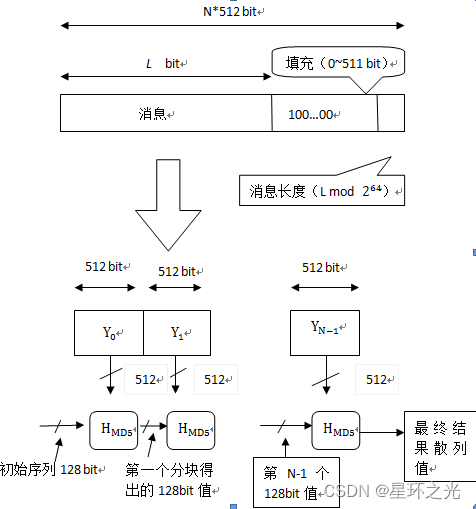
算法步骤
按位补充数据
在MD5算法中,首先需要对信息进行填充,这个数据按位(bit)补充,要求最终的位数对512求模的结果为448。也就是说数据补位后,其位数长度只差64位(bit)就是512的整数倍。即便是这个数据的位数对512求模的结果正好是448也必须进行补位。补位的实现过程:首先在数据后补一个1 bit; 接着在后面补上一堆0 bit, 直到整个数据的位数对512求模的结果正好为448。总之,至少补1位,而最多可能补512位[8]。
扩展长度
在完成补位工作后,又将一个表示数据原始长度的64 bit数(这是对原始数据没有补位前长度的描述,用二进制来表示)补在最后。当完成补位及补充数据的描述后,得到的结果数据长度正好是512的整数倍。也就是说长度正好是16个(32bit) 字的整数倍[8]。
初始化MD缓存器
MD5运算要用到一个128位的MD5缓存器,用来保存中间变量和最终结果。该缓存器又可看成是4个32位的寄存器A、B、C、D,初始化为[8]:
A : 01 23 45 67
B: 89 ab cd ef
C: fe dc ba 98
D: 76 54 32 10
处理数据段
首先定义4个非线性函数F、G、H、I,对输入的报文运算以512位数据段为单位进行处理。对每个数据段都要进行4轮的逻辑处理,在4轮中分别使用4个不同的函数F、G、H、I。每一轮以ABCD和当前的512位的块为输入,处理后送入ABCD(128位)[8]。
输出
信息摘要最终处理成以A, B, C, D 的形式输出。也就是开始于A的低位在前的顺序字节,结束于D的高位在前的顺序字节。
应用
用于密码管理
当我们需要保存某些密码信息以用于身份确认时,如果直接将密码信息以明码方式保存在数据库中,不使用任何保密措施,系统管理员就很容易能得到原来的密码信息,这些信息一旦泄露, 密码也很容易被破译。为了增加安全性,有必要对数据库中需要保密的信息进行加密,这样,即使有人得到了整个数据库,如果没有解密算法,也不能得到原来的密码信息。MD5算法可以很好地解决这个问题,因为它可以将任意长度的输入串经过计算得到固定长度的输出,而且只有在明文相同的情况下,才能等到相同的密文,并且这个算法是不可逆的,即便得到了加密以后的密文,也不可能通过解密算法反算出明文。这样就可以把用户的密码以MD5值(或类似的其它算法)的方式保存起来,用户注册的时候,系统是把用户输入的密码计算成 MD5 值,然后再去和系统中保存的 MD5 值进行比较,如果密文相同,就可以认定密码是正确的,否则密码错误。通过这样的步骤,系统在并不知道用户密码明码的情况下就可以确定用户登录系统的合法性。这样不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度[8]。
电子签名
MD5 算法还可以作为一种电子签名的方法来使用,使用 MD5算法就可以为任何文件(不管其大小、格式、数量)产生一个独一无二的“数字指纹”,借助这个“数字指纹”,通过检查文件前后 MD5 值是否发生了改变,就可以知道源文件是否被改动。我们在下载软件的时候经常会发现,软件的下载页面上除了会提供软件的下载地址以外,还会给出一串长长的字符串。这串字符串其实就是该软件的MD5 值,它的作用就在于下载该软件后,对下载得到的文件用专门的软件(如 Windows MD5 check 等)做一次 MD5 校验,以确保我们获得的文件与该站点提供的文件为同一文件。利用 MD5 算法来进行文件校验的方案被大量应用到软件下载站、论坛数据库、系统文件安全等方面[8]。
垃圾邮件筛选
在电子邮件使用越来越普遍的情况下,可以利用 MD5 算法在邮件接收服务器上进行垃圾邮件的筛选,以减少此类邮件的干扰,具体思路如下:
建立一个邮件 MD5 值资料库,分别储存邮件的 MD5 值、允许出现的次数(假定为 3)和出现次数(初值为零)。
对每一封收到的邮件,将它的正文部分进行MD5 计算,得到 MD5 值,将这个值在资料库中进行搜索。
如未发现相同的 MD5 值,说明此邮件是第一次收到,将此 MD5 值存入资料库,并将出现次数置为1,转到第五步。
如发现相同的 MD5 值,说明收到过同样内容的邮件,将出现次数加 1,并与允许出现次数相比较,如小于允许出现次数,就转到第五步。否则中止接收该邮件。结束。接收该邮件。
文件完整性校验
常用Web服务器本身缺乏页面完整性验证机制,无法防止站点文件被篡改。为确保文件的完整性,防止用户访问页面被篡改,可采用MD5算法校验文件完整性的Web防篡改机制,计算目标文件的数字指纹,运用快照技术恢复被篡改文件,以解决多数防篡改系统对动态站点保护失效及小文件恢复难的问题 。
安全性分析
MD5相对MD4所作的改进:
增加了第四轮。
每一步均有唯一的加法常数。
减弱第二轮中函数的对称性。
第一步加上了上一步的结果,这将引起更快的雪崩效应(就是对明文或者密钥改变 1bit 都会引起密文的巨大不同)。
改变了第二轮和第三轮中访问消息子分组的次序,使其更不相似。
近似优化了每一轮中的循环左移位移量以实现更快的雪崩效应,各轮的位移量互不相同。
MD5 算法自诞生之日起,就有很多人试图证明和发现它的不安全之处,即存在碰撞(在对两个不同的内容使用 MD5算法运算的时候,有可能得到一对相同的结果值)。2009年,中国科学院的谢涛和冯登国仅用了2²0.96的碰撞算法复杂度,破解了MD5的碰撞抵抗,该攻击在普通计算机上运行只需要数秒钟。
代码
C++实现
#include<iostream>
#include<string>
using namespace std;
#define shift(x, n) (((x) << (n)) | ((x) >> (32-(n))))//右移的时候,高位一定要补零,而不是补充符号位
#define F(x, y, z) (((x) & (y)) | ((~x) & (z)))
#define G(x, y, z) (((x) & (z)) | ((y) & (~z)))
#define H(x, y, z) ((x) ^ (y) ^ (z))
#define I(x, y, z) ((y) ^ ((x) | (~z)))
#define A 0x67452301
#define B 0xefcdab89
#define C 0x98badcfe
#define D 0x10325476
//strBaye的长度
unsigned int strlength;
//A,B,C,D的临时变量
unsigned int atemp;
unsigned int btemp;
unsigned int ctemp;
unsigned int dtemp;
//常量ti unsigned int(abs(sin(i+1))*(2pow32))
const unsigned int k[]={
0xd76aa478,0xe8c7b756,0x242070db,0xc1bdceee,
0xf57c0faf,0x4787c62a,0xa8304613,0xfd469501,0x698098d8,
0x8b44f7af,0xffff5bb1,0x895cd7be,0x6b901122,0xfd987193,
0xa679438e,0x49b40821,0xf61e2562,0xc040b340,0x265e5a51,
0xe9b6c7aa,0xd62f105d,0x02441453,0xd8a1e681,0xe7d3fbc8,
0x21e1cde6,0xc33707d6,0xf4d50d87,0x455a14ed,0xa9e3e905,
0xfcefa3f8,0x676f02d9,0x8d2a4c8a,0xfffa3942,0x8771f681,
0x6d9d6122,0xfde5380c,0xa4beea44,0x4bdecfa9,0xf6bb4b60,
0xbebfbc70,0x289b7ec6,0xeaa127fa,0xd4ef3085,0x04881d05,
0xd9d4d039,0xe6db99e5,0x1fa27cf8,0xc4ac5665,0xf4292244,
0x432aff97,0xab9423a7,0xfc93a039,0x655b59c3,0x8f0ccc92,
0xffeff47d,0x85845dd1,0x6fa87e4f,0xfe2ce6e0,0xa3014314,
0x4e0811a1,0xf7537e82,0xbd3af235,0x2ad7d2bb,0xeb86d391};
//向左位移数
const unsigned int s[]={7,12,17,22,7,12,17,22,7,12,17,22,7,
12,17,22,5,9,14,20,5,9,14,20,5,9,14,20,5,9,14,20,
4,11,16,23,4,11,16,23,4,11,16,23,4,11,16,23,6,10,
15,21,6,10,15,21,6,10,15,21,6,10,15,21};
const char str16[]="0123456789abcdef";
void mainLoop(unsigned int M[])
{
unsigned int f,g;
unsigned int a=atemp;
unsigned int b=btemp;
unsigned int c=ctemp;
unsigned int d=dtemp;
for (unsigned int i = 0; i < 64; i++)
{
if(i<16){
f=F(b,c,d);
g=i;
}else if (i<32)
{
f=G(b,c,d);
g=(5*i+1)%16;
}else if(i<48){
f=H(b,c,d);
g=(3*i+5)%16;
}else{
f=I(b,c,d);
g=(7*i)%16;
}
unsigned int tmp=d;
d=c;
c=b;
b=b+shift((a+f+k[i]+M[g]),s[i]);
a=tmp;
}
atemp=a+atemp;
btemp=b+btemp;
ctemp=c+ctemp;
dtemp=d+dtemp;
}
/*
*填充函数
*处理后应满足bits≡448(mod512),字节就是bytes≡56(mode64)
*填充方式为先加一个1,其它位补零
*最后加上64位的原来长度
*/
unsigned int* add(string str)
{
unsigned int num=((str.length()+8)/64)+1;//以512位,64个字节为一组
unsigned int *strByte=new unsigned int[num*16]; //64/4=16,所以有16个整数
strlength=num*16;
for (unsigned int i = 0; i < num*16; i++)
strByte[i]=0;
for (unsigned int i=0; i <str.length(); i++)
{
strByte[i>>2]|=(str[i])<<((i%4)*8);//一个整数存储四个字节,i>>2表示i/4 一个unsigned int对应4个字节,保存4个字符信息
}
strByte[str.length()>>2]|=0x80<<(((str.length()%4))*8);//尾部添加1 一个unsigned int保存4个字符信息,所以用128左移
/*
*添加原长度,长度指位的长度,所以要乘8,然后是小端序,所以放在倒数第二个,这里长度只用了32位
*/
strByte[num*16-2]=str.length()*8;
return strByte;
}
string changeHex(int a)
{
int b;
string str1;
string str="";
for(int i=0;i<4;i++)
{
str1="";
b=((a>>i*8)%(1<<8))&0xff; //逆序处理每个字节
for (int j = 0; j < 2; j++)
{
str1.insert(0,1,str16[b%16]);
b=b/16;
}
str+=str1;
}
return str;
}
string getMD5(string source)
{
atemp=A; //初始化
btemp=B;
ctemp=C;
dtemp=D;
unsigned int *strByte=add(source);
for(unsigned int i=0;i<strlength/16;i++)
{
unsigned int num[16];
for(unsigned int j=0;j<16;j++)
num[j]=strByte[i*16+j];
mainLoop(num);
}
return changeHex(atemp).append(changeHex(btemp)).append(changeHex(ctemp)).append(changeHex(dtemp));
}
unsigned int main()
{
string ss;
// cin>>ss;
string s=getMD5("abc");
cout<<s;
return 0;
}
以上便是全部内容,求关注!
【参考资料出处:百度百科】















 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









