







1.Cluster集群介绍
-
背景
- Sentinel解决了主从架构故障自动迁移的问题
- 但是master主节点的写能力和存储能力依旧受限
- 使用Redis的集群Cluster就是为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器
-
什么是集群Cluster
- 是一组相互独立的、通过告诉网络互联的计算机,它们构成了一个组,并以单一系统的模式加以管理
- 容易和分布式弄混,分布式系统简单的理解为一个庞大的系统进行拆分多个小系统。同样的功能部署多台为集群;一个大系统拆分成每个独立小系统,每个小系统都处理独立的功能为分布式
-
Redis集群模式介绍
-
Cluster模式是Redis3.0开始推出
-
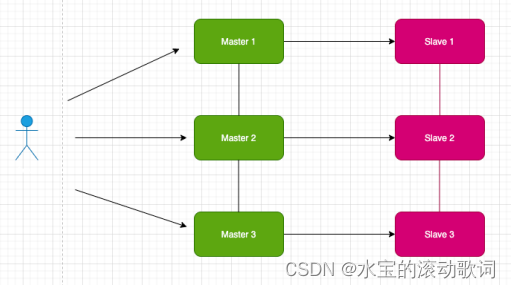
采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接
-
官方要求:至少6个节点才可以保证高可用,即3主3从;扩展性强、更好做到高可用
-
各个节点会互相通信,采用gossip协议交换节点元数据信息
-
数据分散存储到各个节点上
-
2.Cluster数据分片和虚拟哈希槽介绍
- 背景
- 主节点的写能力和存储能力受限
- 单台机器无法满足需求,因此把数据分散存储到多个机器
- 类似案例:mysql分库分表
- 常见的数据分区算法
- 哈希取模:对选择的partitioning key计算其哈希值,得到的哈希值就是对应的分区
- 范围分片:通过确定分区键是否在某个范围内来选择分区
- 一致性hash分区
- Redis Cluster集群没有采用一致性哈希方案,而是采用数据分片中的哈希槽来进行数据存储与读取的
- 什么是Redis的哈希槽slot
- Redis集群预分好16384个槽,当需要在Redis集群中放置一个key-value时,根据CRC16(key) mod 16384的值,决定将一个key放到哪个桶中
- 大体流程
- 假设主节点的数量为3,将16384个槽位按照【用户自己的规则】去分配这3个节点,每个节点复制一部分槽位
- 节点1的槽位区间范围为0-5460
- 节点2的槽位区间范围为5461-10922
- 节点3的槽位区间范围为10923-16383
- 注意:从节点是没有槽位的,只有主节点才有
- 存储查找
- 对要存储查找的键进行CRC16哈希运算,得到一个值,并取模16384,判断这个值在哪个节点的范围区间
- 假设CRC16(“test_key”) % 16384 = 3000,就是节点一
- CRC16算法不是简单的hash算法,是一种校验算法
- 假设主节点的数量为3,将16384个槽位按照【用户自己的规则】去分配这3个节点,每个节点复制一部分槽位
- 使用哈希槽的好处就在于可以方便的添加或移除节点
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了
3.Cluster集群搭建
-
说明
- 旧版本的需要使用Ruby语言进行构建,新版5之后直接用redis-cli即可
- 6个节点,三主三从,主从节点会自动分配,不是人工指定
- 主节点故障后,从节点会替换主节点
-
配置
# 是否开启集群 cluster-enabled yes # 生成的node文件 cluster-config-file nodes-6381.conf # 节点连接超时时间 cluster-node-timeout 15000 # 集群节点的IP,当前节点的IP cluster-announce-ip 192.168.1.12 # 集群节点映射端口 cluster-announce-port 6381 # 集群节点总线端口,节点之间互相通信,常规端口+1万 cluster-announce-bus-port 16381 -
创建6个配置文件,注意修改配置端口号和日志文件
bind 0.0.0.0 port 6381 daemonize yes requirepass 123456 logfile "/usr/local/redis6/log/redis1.log" dbfilename redis1.rdb dir /usr/local/redis6/data appendonly yes appendfilename "appendonly1.aof" masterauth 123456 cluster-enabled yes cluster-config-file nodes-6381.conf cluster-node-timeout 15000 cluster-announce-ip 192.168.1.12 cluster-announce-port 6381 cluster-announce-bus-port 16381 -
启动6个节点
/usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis1.conf /usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis2.conf /usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis3.conf /usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis4.conf /usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis5.conf /usr/local/redis6/bin/redis-server /usr/local/redis6/data/redis6.conf -
加入集群(其中一个节点执行即可)
- –cluster构建集群全部节点信息
- –cluster-replicas 1主从节点的比例,1表示1主1从的方式
/usr/local/redis6/bin/redis-cli -a 123456 --cluster create 192.168.1.12:6381 192.168.1.12:6382 192.168.1.12:6383 192.168.1.12:6384 192.168.1.12:6385 192.168.1.12:6386 --cluster-replicas 1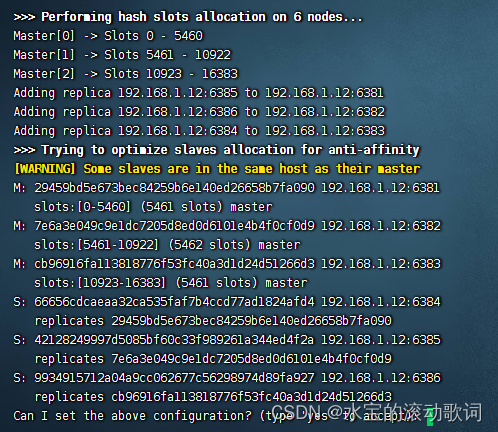
-
检查状态信息(其中一个节点执行即可)
/usr/local/redis6/bin/redis-cli -a 123456 --cluster check 192.168.1.12:6381 -
集群状态
# 连接客户端 /usr/local/redis6/bin/redis-cli -c -a 123456 -p 6381 # 集群信息 cluster info # 节点信息 cluster nodes -
测试集群读写命令set/get
- key哈希运算计算槽位
- 槽在当前节点的话直接插入/读取,否则自动转向到对应的节点
-
操作都是主节点操作,从节点只是备份
-
流程解析
- 启动应用
- 加入集群
- 从节点请求复制主节点(主从复制一样)
- 先全量
- 再增量
4.Redis Cluster集群整合SpringBoot
-
配置文件
spring: redis: password: 123456 cluster: # 最多转发次数 max-redirects: 3 nodes: 192.168.1.12:6381,192.168.1.12:6382,192.168.1.12:6383,192.168.1.12:6384,192.168.1.12:6385,192.168.1.12:6386
5.高可用架构总结
- 主从模式:读写分离、备份,一个master可以有多个slave
- 哨兵Sentinel:监控、自动转移,哨兵发现主服务器挂了后,就会从slave中重新选举一个主服务器
- 集群Cluster:为了解决单机Redis容量有限的问题,将数据按一定的规则分配到多台机器,内存/QPS不受限于单机,提高并发量















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











