






朋友指派写一个爬虫,需要爬取12306指定起点和终点的所有列车数据信息
网页分析
访问https://www.12306.cn/index/,f12进入开发者界面
监测网络活动
输入起点终点后,点击查询
载入新页面
重新查询后发现GET响应数据包
发现其中响应JSON中的result字段是我们所需的列车数据信息
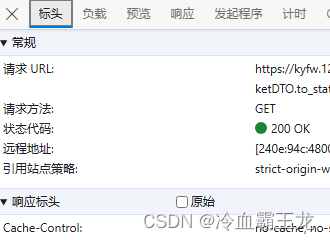
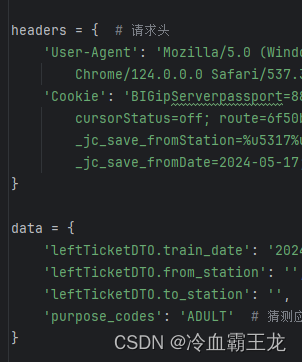
查看请求头部分
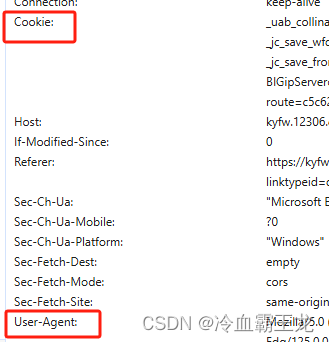
获取user-agent、cookie等标头信息
查看负载传递参数部分
根据以下params构造url
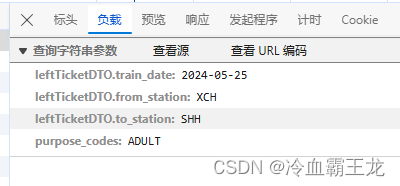
leftTicketDTO.train_date=2024-05-18 查询日期
leftTicketDTO.from_station=BJP 始发站代码
leftTicketDTO.to_station=XCH 终点站代码
purpose_codes=ADULT 车票类型
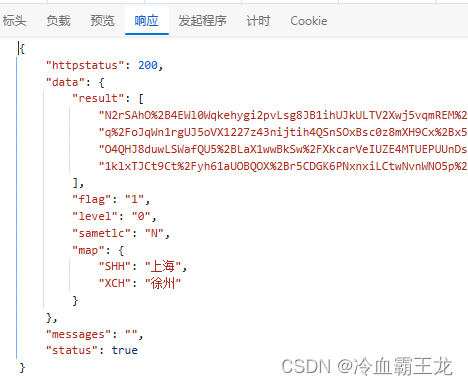
查看响应JSON数据部分
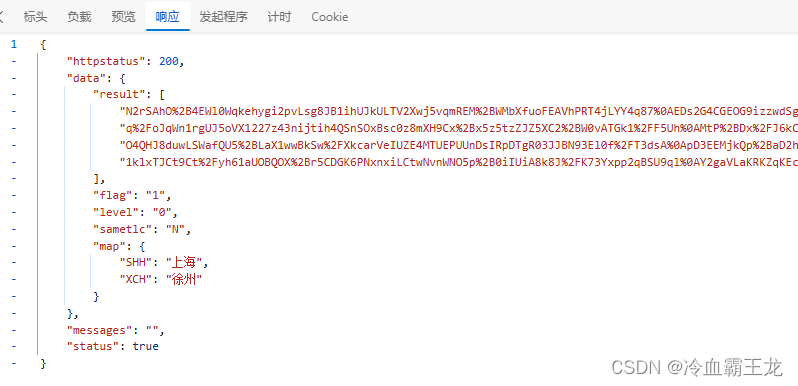
[”data”][“result”]内对应数据是所需的列车信息
[”data”][“map”]内为途径站点
摘取一段进行分析

可见所需信息位置,用split(“|”)对字符串进行分割可得信息字符串列表
程序编写
爬虫程序主要由以下部分组成:
1.读取文件,获取所需的城市站点列表
2.将城市站点名根据城市站点代码表转换为城市站点代码
3.根据城市站点代码请求网站,获取列车信息
4.处理列车信息,写入文件
第三方库
requests 网络请求
pandas 数据分析
xlrd、xlwt 读写xls、xlsx类型文件
部分程序代码
请求头和参数部分,本次爬取的日期为2024-5-20
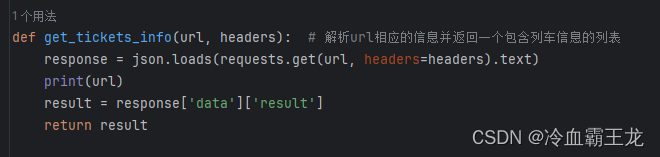
主函数run()中根据始发站和终点站的城市代码构造请求url进行请求,将获取的数据通过json库解析

请求和解析数据
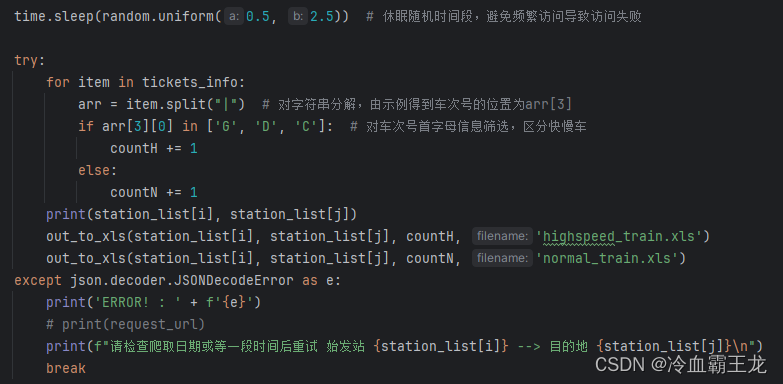
在主函数run()中过滤数据和计数,可以根据自己需求处理列车数据,这里统计了高速(G\D\C)列车和普通列车的数目
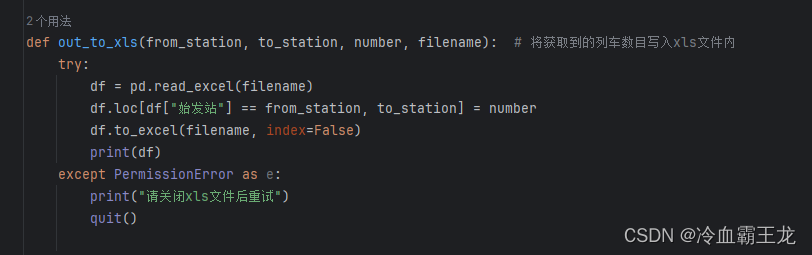
解析文件,将“始发站”列作为索引,定位数据并写入
省略了转换城市代码的部分程序,可参考以下博客,其中转换城市代码部分更为详细简洁
利用Python爬虫,查询12306车次信息_python爬取12306火车票信息-CSDN博客
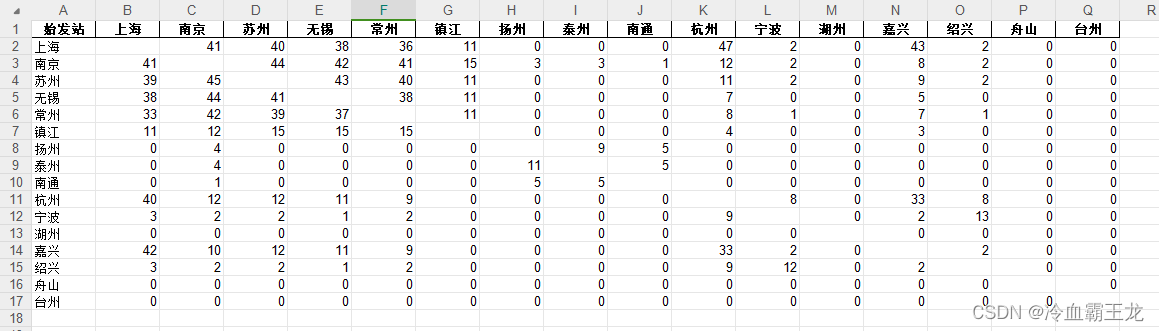
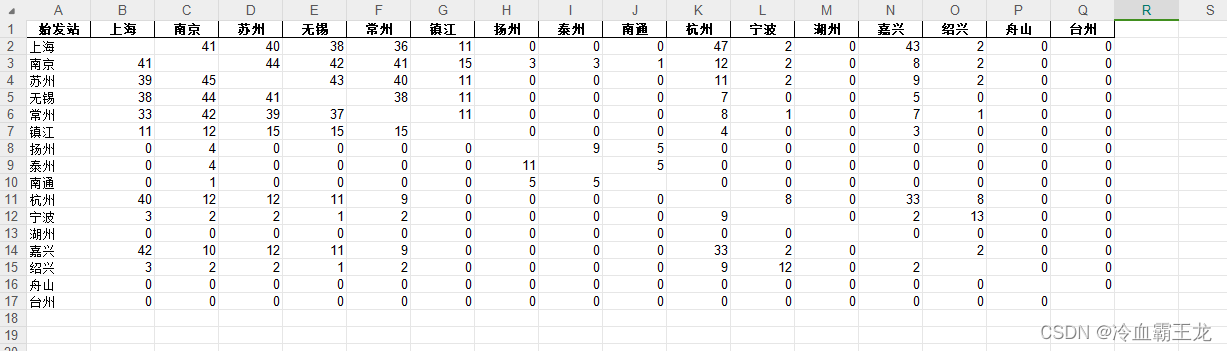
爬取结果
G\D\C开头列车
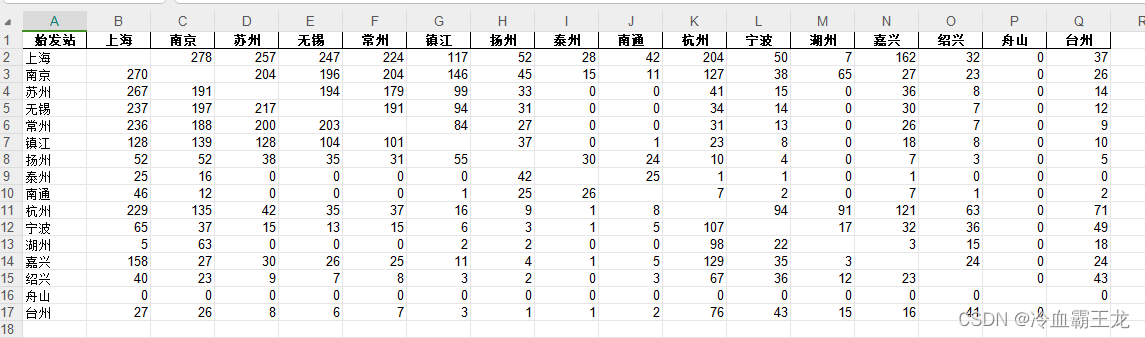
其他类型列车
调试问题
主要讲一下调试中出现的一些问题
报错:pandas.errors.InvalidIndexError:"You can only assign a scalar value not a <class “ ”>
解释:这个错误信息表示在尝试给Pandas DataFrame的某个索引位置赋值时,你提供了一个非标量(scalar)值,但Pandas期望的是一个标量值。
措施:混淆了pandas中的at()和loc()函数,当查找索引时at返回的是单值,而loc可以返回dataframe或者series类型的对象,将at()函数换成loc()解决
报错:pandas.errors.ValueError: No engine for filetype: 'xls''
解释:缺少处理excel文件的引擎,是pandas和xlwt版本不兼容的原因,新版本的pandas由于不再维护xlwt包,需要重新下载低版本的pandas才能兼容
措施:下载低版本的pandas,博客中使用库各版本为pandas 1.5.3,xlrd 2.0.1,xlwt 1.3.0
报错:json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
解释:json解析数据时缺少值,这个问题困扰了非常久,爬取数据的时候会持续报此错误然后停止爬取,检查和调试其他函数也没有问题,直到我重新访问12306时发现

应该是因为过于请求过于频繁,导致服务器拒绝访问,导致数据解析报错
措施:在请求前取范围内随机长度时间休眠进程,避免被监测为爬虫

目前取0.5~2.5秒范围内解决问题(低数据量)
其他参考博客

















 1435
1435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









