






朋友指派写一个爬虫,需要爬取携程网指定起点和终点的所有汽车票信息
网页分析
访问https://www.ctrip.com/, f12进入开发者界面
监测网络活动
点击汽车票,输入起点和终点后点击搜索
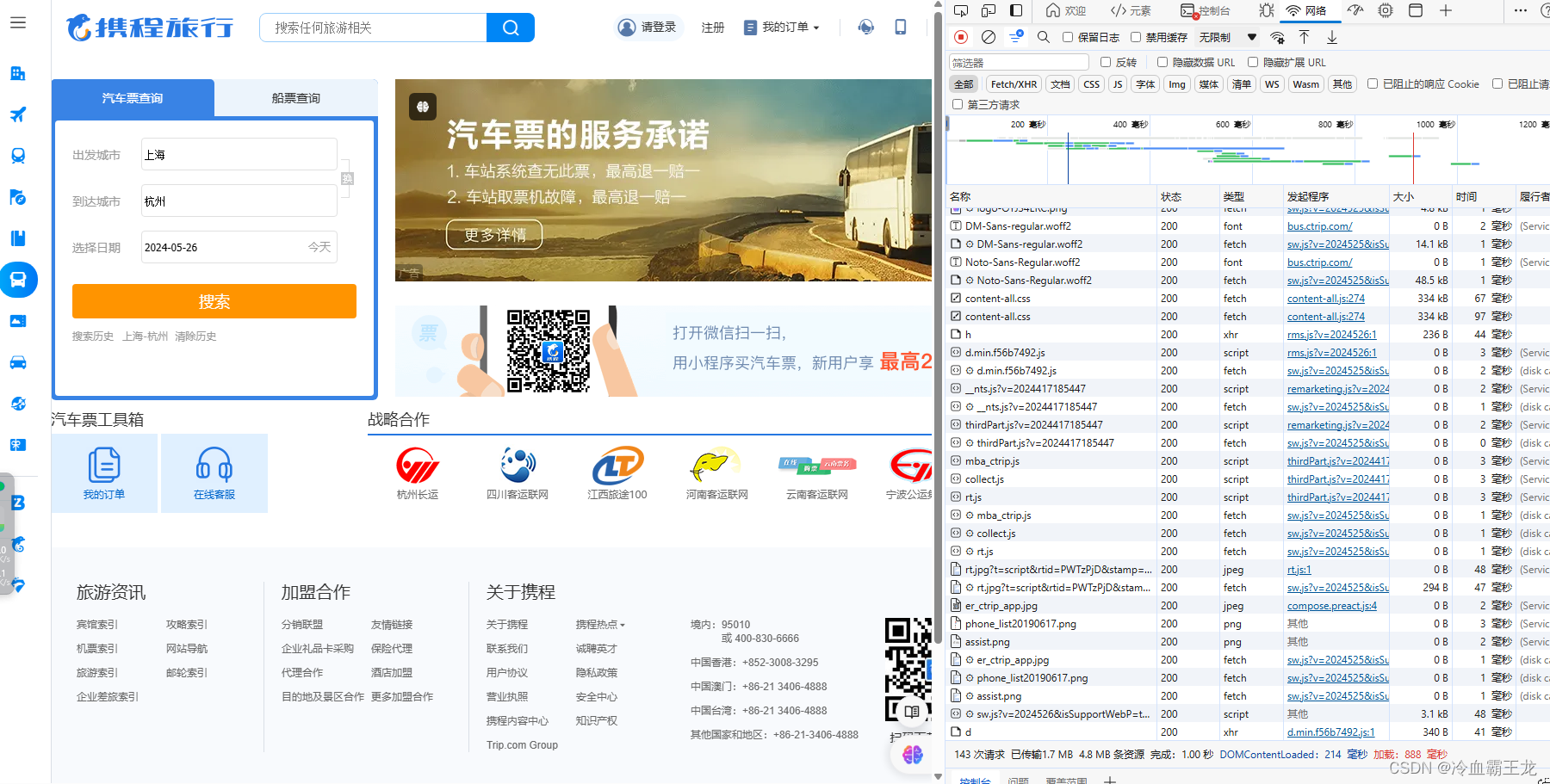
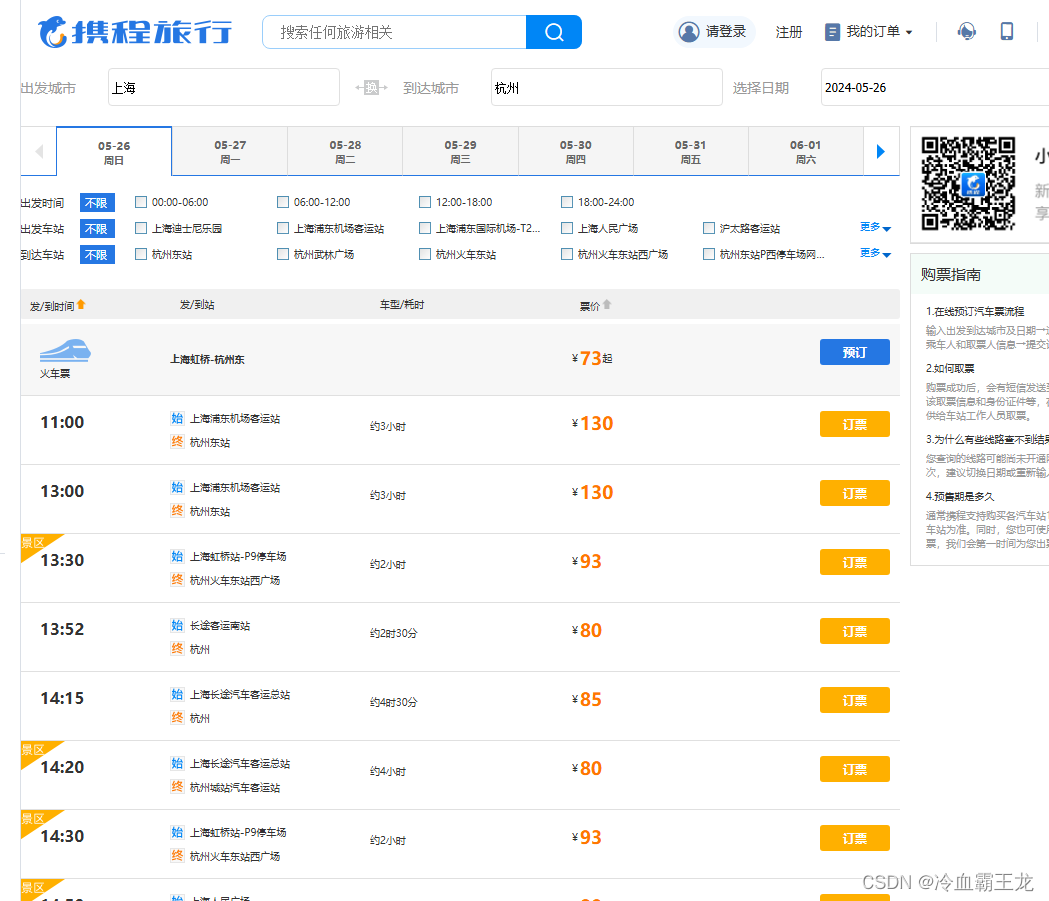
查看页面,所需信息就是下列汽车的发/到时间、起点和终点数据
重新查询,筛选通过Fetch/XHR交互的数据包
查找数据包,发现名为busListV2的POST包内负载列车数据信息
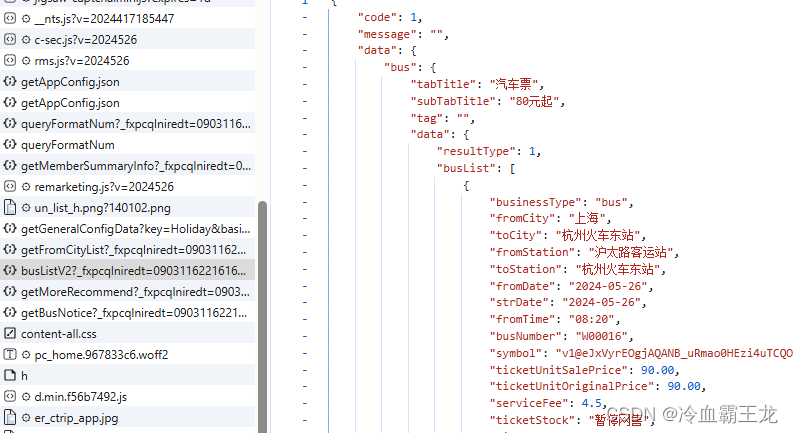
查看请求头
获取user-agent、cookie等headers信息
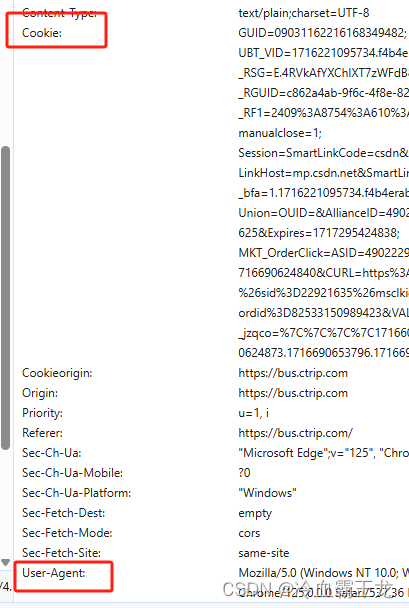
查看请求url
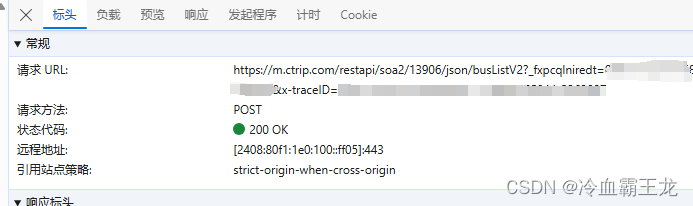
猜测请求url中包含两个动态生成的参数,需要JS逆向出参数的构造函数,从而构造请求url
查看传递参数
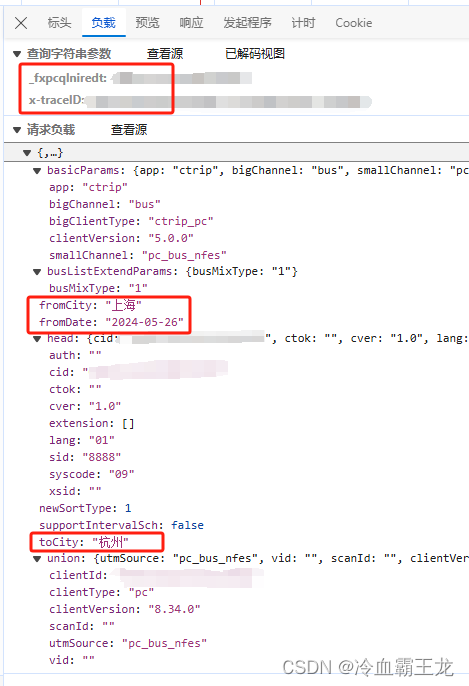
多次查询后观察此包,发现有以下必需参数
_fxpcqlniredt (静态) 识别用户身份
x-traceID (动态) 追踪用户
fromCity 起点城市
toCity 终点城市
fromDate 出发日期
查看数据部分
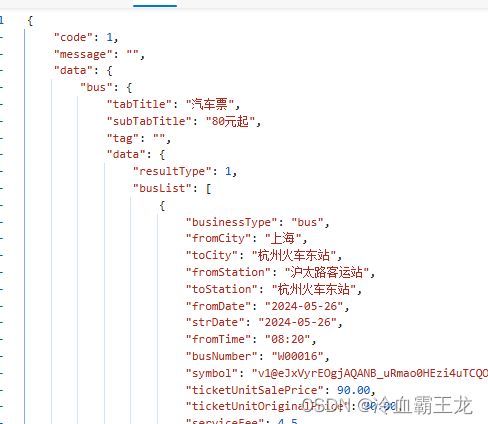
可见["data"]["bus"]["data"]["busList"]字段内储存了一个列表,包含所需数据信息
JS逆向
接下来对web进行逆向,看看能不能查找出参数_fxpcqlniredt的来源和参数x-traceID的构造函数
点击此包的发起程序,进入源代码界面
ctrl+f搜索,查找_fxpcqlniredt参数
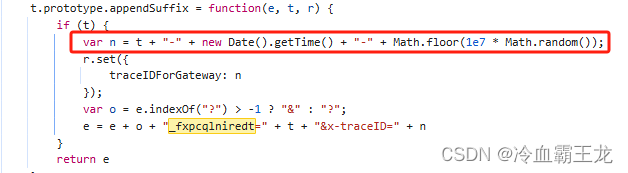
这里在function的函数下未发现_fxpcqlniredt的来源,却找到x-traceID的构成函数,它由t(即_fxpcqlniredt)、请求时间的时间戳和一个七位的随机整数构成,继续寻找_fxpcqlniredt来源

发现_fxpcqlniredt参数和cookie中的GUID字段始终保持统一,推测来源于cookie
至此逆向过程完毕
程序编写
程序主要包含以下部分:
1.读取文件
2.解码参数,请求服务器
3.获取数据,处理数据
4.数据写入文件
第三方库
requests 网络请求
pandas 数据分析
xlrd、xlwt 读写xls、xlsx类型文件
json 解析数据
程序代码
def decode(headers, parameter, n):
p = "-" + str(int(time.time() * 1000)) + "-" + str(random.randint(0, 9999999))
parameter['_fxpcqlniredt'] = n
parameter['x-traceID'] = n + p
headers['path'] = '/restapi/soa2/13906/json/busListV2?_fxpcqlniredt=' + parameter['_fxpcqlniredt'] + '&x-traceID=' + parameter['x-traceID']解码函数
_fxpcqlniredt = cookie.GUID
x-traceID = _fxpcqlniredt - 当前时间的时间戳(精确到毫秒)- 0~9999999之间的随机整数
def read_xls(filename):
list = []
df = pd.read_excel(filename)
column_values = df['始发地'].values
for item in column_values:
list.append(item.rstrip("\n"))
return list读取xls文件并获取城市列表
def out_to_xls(from_station, to_station, number, filename): # 将获取到的列车数目写入xls文件内
try:
df = pd.read_excel(filename)
df.loc[df["始发地"] == from_station, to_station] = number
df.to_excel(filename, index=False)
print(f"正在处理{from_station}-->{to_station}, 数量 {number}")
# print(df)
except PermissionError as e:
print("请关闭.xls文件后重试")
quit()
数据写入xls文件内
def run():
decode(headers, parameter, '***************') # 隐藏部分为GUID
request_url = url + urlencode(parameter)
station_list = read_xls('file.xls')
for i in range(0, len(station_list)):
for j in range(0, len(station_list)):
if i == j: # 当始发站和目的地相同时跳过
continue
data["fromCity"] = station_list[i]
data["toCity"] = station_list[j]
time.sleep(random.uniform(0.5, 2.5))
try:
rest = requests.post(request_url, headers=headers, json=data)
trans_dict = json.loads(rest.text)
result_type = trans_dict["data"]["bus"]["data"]["resultType"]
print(result_type)
if result_type == 3:
out_to_xls(station_list[i], station_list[j], 0, 'file.xls')
continue
elif result_type == 2:
out_to_xls(station_list[i], station_list[j], 'error', 'file.xls')
bus_list = trans_dict["data"]["bus"]["data"]["busList"]
number = len(bus_list)
# print(number)
out_to_xls(station_list[i], station_list[j], number, 'file.xls')
except json.decoder.JSONDecodeError:
print(json.decoder.JSONDecodeError)
except KeyError:
print(KeyError)针对返回数据中resultType字段的标号对数据进行处理,1表示查询到数据信息,3表示未查询到信息或信息数为0,2未知
完整代码
crawler.py(请自行构造headers和data部分)
import json
import requests
from urllib.parse import urlencode
from function import *
url = ('https://m.ctrip.com/restapi/soa2/13906/json/busListV2?') # url
parameter = {
'_fxpcqlniredt': '',
'x-traceID': ''
} # 加密参数
headers = {} # 请求头
data = {} # json
def run():
decode(headers, parameter, '***************')
request_url = url + urlencode(parameter)
station_list = read_xls('file.xls')
for i in range(0, len(station_list)):
for j in range(0, len(station_list)):
if i == j: # 当始发站和目的地相同时跳过
continue
data["fromCity"] = station_list[i]
data["toCity"] = station_list[j]
time.sleep(random.uniform(0.5, 2.5)) # 休眠随机时间
try:
rest = requests.post(request_url, headers=headers, json=data)
trans_dict = json.loads(rest.text) # 请求并解析数据
result_type = trans_dict["data"]["bus"]["data"]["resultType"]
if result_type == 3: # 根据result_type处理数据信息
out_to_xls(station_list[i], station_list[j], 0, 'file.xls')
continue
elif result_type == 2:
out_to_xls(station_list[i], station_list[j], 'error', 'file.xls')
bus_list = trans_dict["data"]["bus"]["data"]["busList"]
number = len(bus_list) # 获取汽车票数目
# print(number)
out_to_xls(station_list[i], station_list[j], number, 'file.xls')
except json.decoder.JSONDecodeError: # 处理异常
print(json.decoder.JSONDecodeError)
except KeyError:
print(KeyError)
if __name__ == '__main__':
run()function.py
import random
import time
import pandas as pd
def decode(headers, parameter, n):
p = "-" + str(int(time.time() * 1000)) + "-" + str(random.randint(0, 9999999))
parameter['_fxpcqlniredt'] = n
parameter['x-traceID'] = n + p
headers['path'] = '/restapi/soa2/13906/json/busListV2?_fxpcqlniredt=' + parameter['_fxpcqlniredt'] + '&x-traceID=' + parameter['x-traceID']
def read_xls(filename):
list = []
df = pd.read_excel(filename)
column_values = df['始发地'].values
for item in column_values:
list.append(item.rstrip("\n"))
return list
def out_to_xls(from_station, to_station, number, filename): # 将获取到的列车数目写入xls文件内
try:
df = pd.read_excel(filename)
df.loc[df["始发地"] == from_station, to_station] = number
df.to_excel(filename, index=False)
print(f"正在处理{from_station}-->{to_station}, 数量 {number}")
# print(df)
except PermissionError as e:
print("请关闭.xls文件后重试")
quit()
调试问题
报错:requests.exceptions.InvalidHeader: Invalid leading whitespace, reserved character(s), or returncharacter(s) in header name: ':authority'
解释:无法解析请求头,前几个字段为http2的请求,作为RFC 描述,Http 请求头不能以分号开头,这部分我也不是很清楚,查询了几个博客
措施:直接把前几个有问题的字段删掉,也能正常请求不报错
报错:KeyError: 'data'
解释:没有获取到数据,这个报错困扰了非常久,最后发现是在post请求时将参数json写成了params的低级错误导致无法正常传递json参数

措施:改为rest = requests.post(request_url, headers=headers, json=data)
爬取结果
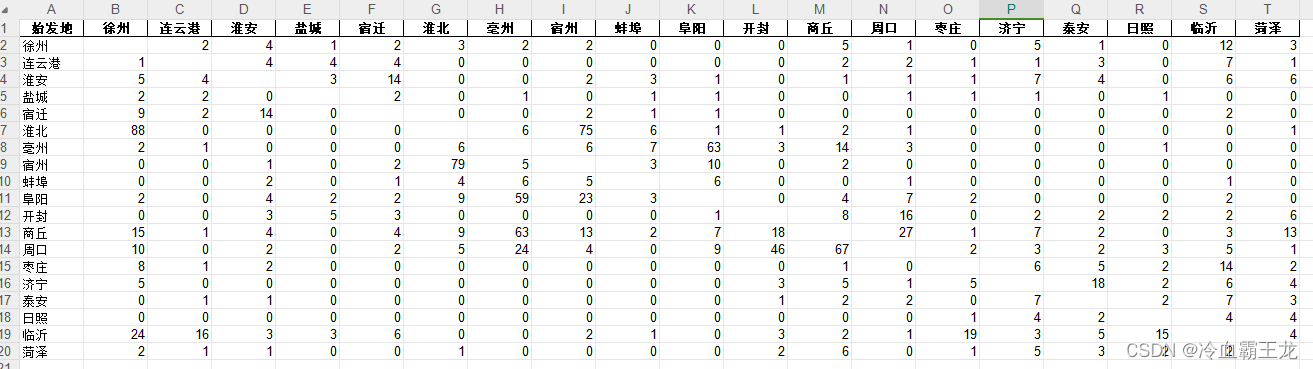
xls格式如上图

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









