







1.语言进阶&依赖管理
1.1 语言进阶
从并发编程的视角了解Go高性能的本质。
1.1.1 并发&并行
在单核CPU下,线程实际还是串行执行的。操作系统中有一个组件叫做任务调度器,它将CPU的时间片(window下最小约为15毫秒)分给不同的程序使用,只是由于CPU在线程间的切换非常快,人类一般是感觉不到的,所以会觉得他们是同时运行的。一句话说就是微观串行,宏观并行。
一般将这种线程轮流使用CPU的做法称为并发,concurrent,多核 cpu下,每个 核(core) 都可以调度运行线程,这时候线程可以是并行的。
这里引用Golang语言创造者的Rob Pike的一句描述:
- 并发(concurrent)是同一时间应对(dealing with)多件事情的能力
- 并行(parallel)是同一时间动手做(doing)多件事情的能力
提到高并发,Go也是一大利器。
1.1.2 线程&协程
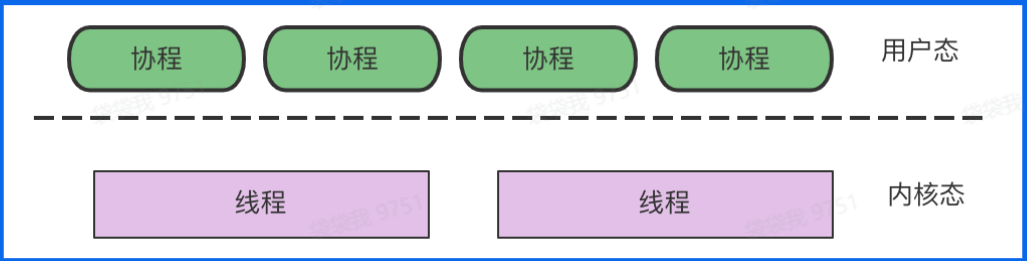
线程
一个进程之内可以分为一到多个线程,一个线程就是一个指令流,指令流的一条条指令按照一定的顺序加载给CPU执行,比如在Java中,线程作为最小的调度单位,进程作为资源分配的最小单位。
协程
协程不是系统线程,很多时候被称为轻量级线程、微线程、纤程等,简单来说可以认为协程是线程里面不同的函数,这些函数之间可以相互快速切换,协程和用户线态线程非常接近,用户态线程之间的切换不需要陷入内核,但这不是绝对的,部分系统中的切换也是需要内核态线程的辅助的。协程是编程语言提供的特性(之间的切换方式与过程可以由程序员确定),属于用户态操作。
小结
线程:内核态、轻量级、栈MB级别
协程:用户态、线程可以跑多个协程、栈KB级别
在Go语言中开启协程只需要在函数调用之前加上go关键字即可。比如下面这段代码,通过协程的方式,打印一段输出。
package main
import (
"fmt"
"time"
)
func main() {
HelloGoRoutine()
}
func hello(i int) {
println("hello goroutine:" + fmt.Sprint(i))
}
func HelloGoRoutine() {
for i := 0; i < 5; i++ {
//开启协程
go func(j int) {
hello(j)
}(i)
}
time.Sleep(time.Second)
}
Go的CSP并发模型
与其他编程语言不同,Go语言除了支持传统语言的 多线程共享内存并发模型之外,还有自己特有的 **CSP(communicating sequential processes)**并发模型,一般情况下,这也是Go语言推荐使用的。
与传统的 多线程通过内存来通信 相比,CSP讲究的是 以通信的方式来共享内存。
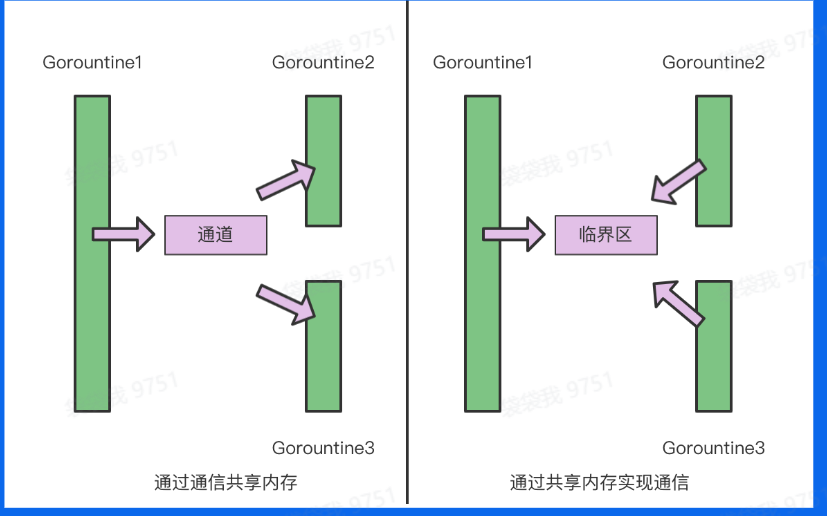
普通的线程并发模型,他们的线程通信一般是通过共享内存的方式来进行的,非常典型的方式就是,在访问共享数据(数组、Map等)的时候是通过锁来访问,因此很多时候会衍生出一种叫做 线程安全的数据结构的东西。
而Go的CSP并发模型则是通过goroutine和channel来实现的。
goroutine是Go语言中并发的执行单位。可以理解为用户空间的线程。channel是Go语言中不同goroutine之间的通信机制,即各个goroutine之间通信的”管道“,有点类似于Linux中的管道。
Channel
channel类似与一个队列,满足先进先出的规则,严格保证收发数据的顺序,每一个通道只能通 过固定类型的数据如果通道进行大型结构体、字符串的传输,可以将对应的指针传进去,尽量的节省空间。
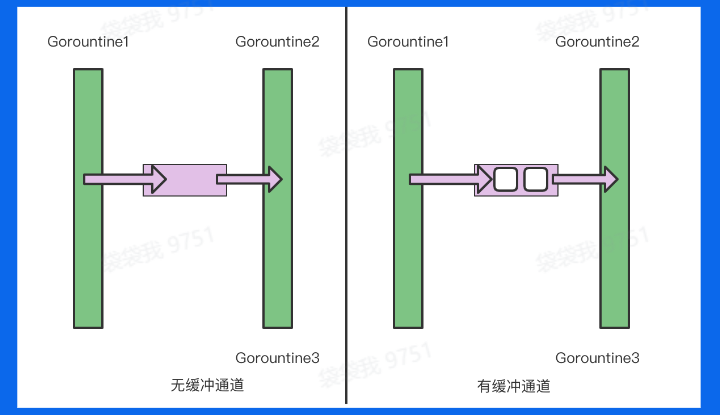
在Go中,可以通过make函数创建通道(channel,后文都简称通道)。
make(chan 元素类型,[缓冲大小])无缓冲:
make(chan int)在发送和接收者之间同步的传递消息,这种方式可以保证消息的顺序和每个消息只被接收一次。
有缓冲:
make(chan int,2)缓冲通道具有固定大小的缓冲区,发生者和接收者之间不再是同步的,可以提高程序的性能,但可能会出现消息的丢失或重复。
基本操作
- 操作符
<-
取出数据使用操作符 <-操作符右边是输入变量,操作符左边是通道代表数据流入通道内.
// 声明一个通道
var a chan int
a <- 5
下面通过一段简单的生产-消费模式的代码示例,熟悉channel的基本使用。
package main
func main() {
CalSquare()
}
func CalSquare() {
//无缓冲channel
src := make(chan int)
//有缓冲channel
dest := make(chan int, 3)
//协程A生成0-9数字
go func() {
defer close(src)
for i := 0; i < 10; i++ {
src <- i
}
}()
//协程B计算输入数字的平方
go func() {
defer close(dest)
for i := range src {
dest <- i * i
}
}()
//主线程打印输出最终结果
for i := range dest {
//TODO
println(i)
}
}
程序中,协程A作为生产者角色,生产出数字
0-9以供下面消费者角色的B协程,该协程从src管道取到数字之后,对数字进行平方计算,再将结果最终流入dest通道内,最后使用主线程打印最终处理之后的结果。
并发安全Lock—传统并发模式
考虑下面这个场景:
使用5个协程并发执行,对某变量执行2000次的
+1操作。
package main
import (
"sync"
"time"
)
var (
x int64
lock sync.Mutex
)
func main() {
Add()
}
// 加锁的自增方法
func addWithLock() {
for i := 0; i < 2000; i++ {
lock.Lock()
x += 1
lock.Unlock()
}
}
// 不加锁的自增方法
func addWithoutLock() {
for i := 0; i < 2000; i++ {
x += 1
}
}
func Add() {
x = 0
for i := 0; i < 5; i++ {
go addWithoutLock()
}
time.Sleep(time.Second)
println("没加锁:", x)
x = 0
for i := 0; i < 5; i++ {
go addWithLock()
}
time.Sleep(time.Second)
println("加锁的:", x)
}
上面的程序中,同样都是启用5个协程并发对x自增2000次,一个使用了lock一个没有,在并发情况下,没有加锁的操作可能会引起数据的错误,比如未加锁情况下最终的是8337,而加锁的情况下确实正确结果10000,可见加锁在一定程度上可以防止数据错误,保证了原子性。
- 这里导入了一个名为
sync的库。其中的Mutex类型直接支持互斥锁关系,它的Lock方法能够获取锁和释放锁Unlock。每个goroutine试图访问x变量时,他都会调用mutex的Lock方法来获取一个互斥锁。如果其他goroutine已经获得这个锁的情况下,该操作将会被阻塞,直到其他goroutine调用了Unlock方法释放锁变回可用状态。- 在
Lock和Unlock直接的代码段中的内容goroutine可以随便读取或修改,这个这个代码叫做临界区(注意前面提到的两种并发模式的示意图)。锁的持有者在其他goroutine获取该锁之前需要调用Unlock,任务执行结束之后释放锁是必要的,无论哪一条路径通过函数都需要释放,即使是在出现异常的情况下。- 在上面的代码中,由于变量
x的自增函数中只有短短的一行,没有分支调用,在代码最后调用Unlock就显得更加的直截了当。但在复杂的临界区应用中,尤其是必须要尽早处理错误并返回的情况下,就很难靠认为的去判断对Lock和Unlock的调用是在所有的路径中都是严格配对的了。所以面对这种情况,Go也是有自己独有的应对方法,使用go中的defer,可以使用defer来调用Unlock,临界区会隐式的延伸到函数作用域的最后,这样我们就无需每次都要记得使用Unlock去释放锁,Go会帮我们完成这件事。
WaitGroup
在Go语言中除了使用通道(channel)和互斥锁(lock)进行并发同步之外,还可以使用等待组WaitGroup来完成多个任务的同步,与前面提到的锁不同,等待组可以保证在并发环境中完成指定数量的任务。

在WaitGroup类型中,每个sync.WaitGroup内部维护了一个计数器,初始默认值为0,详情见上图所示。计数器计数逻辑如下:
- 开启协程+1
- 执行结束-1
- 主协程阻塞直到计数器为0
修改之前 使用协程打印输出的代码:
package main
import (
"fmt"
"sync"
"time"
)
func main() {
//HelloGoRoutine()
ManyGWaitGroup()
}
func hello(i int) {
println("hello goroutine:" + fmt.Sprint(i))
}
func ManyGWaitGroup() {
var wg sync.WaitGroup
//增加5个等待组数量
wg.Add(5)
for i := 0; i < 5; i++ {
go func(j int) {
//当一个goroutine完成之后,减少一个等待组
defer wg.Done()
hello(j)
}(i)
}
//直到所有的操作都完成
wg.Wait()
}
func(*WaitGroup) Add(delta int)
Add方法向内部计数加上delta,delta可以是负数;如果内部计数器变为0,Wait方法阻塞等待的所有线程都会释放,如果计数器小于0,方法panic。注意Add加上正数的调用应在Wait之前,否则Wait可能只会等待很少的线程。一般来说本方法应在创建新的线程或者其他应等待的事件之前调用。
func(*WaitGroup) Done
Done方法减少WaitGroup计数器的值,应在线程的最后执行,Done的执行应标志着一个goroutine的结束
func(*WaitGroup) Wait
Wait方法阻塞直到WaitGroup计数器减为0。如果WaitGroup不为0,那么程序就会一直阻塞在Wait函数这里
1.2 依赖管理
了解Go语言依赖管理的演进路线。
1.2.1 GOPATH
目前为止,Go的依赖管理主要经历了三个阶段:
GOPATH->Go Vender->Go Module
整个路线主要围绕着实现下面两个目标来迭代发展的:
- 不同环境(项目)依赖版本不同
- 控制依赖库的版本
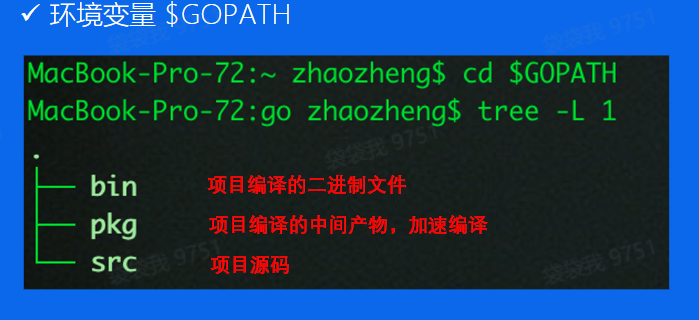
所有工程代码要求放在GOPATH/src目录下
工程本身也将作为一个依赖包,可以被其它 GOPATH/src 目录下的工程引用
在 $GOPATH/src 下进行 .go 文件或源代码的存储,我们可以称其为 GOPATH 的模式
弊端
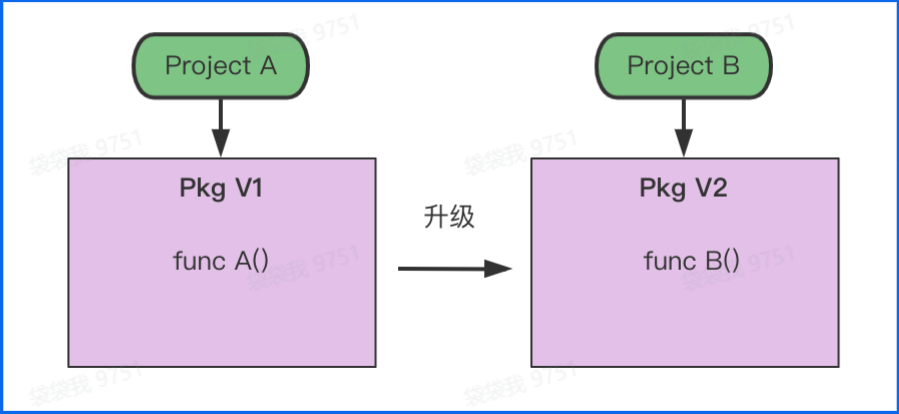
- 没有版本控制的概念
- 所有的项目需要存放在
$GOPATH/src目录下,否则就不能编译。
1.2.2 Go Vender
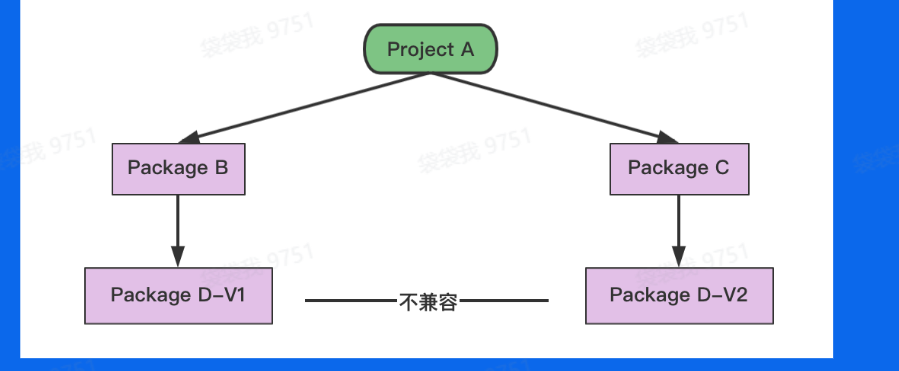
- 解决
GOPATH模式 所有项目都在$GOPATH/src目录的问题,可以随处可以创建项目,不用扎堆src目录下。- 通过每个项目引入一份依赖的副本,解决了多个项目需要同一个
package依赖开的冲突问题。
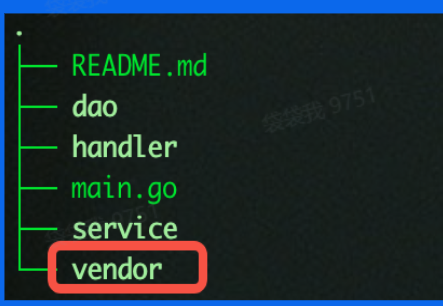
- 项目目录西卡增加了
vender文件,所有的依赖包副本形式存放在ProjectRoot/vender下。 - 依赖的寻址方式:
vender->GOPATH
不足
- 无法控制依赖版本
- 更新项目又可能出现依赖冲突,导致编译出错
1.2.3 GoModule
- 通过
go.mod文件管理依赖包版本- 通过
go get/go mod指令工具管理依赖包- 实现定义版本规则和管理项目依赖关系,类比Java中的
Maven。
核心三要素
- 配置文件,描述依赖-
go.mod - 中央仓库管理依赖库-
Proxy - 本地工具-
go get/mod
go.mod
启用了 Go modules 的项目,初始化项目时,会生成一个 go.mod 文件。描述了当前项目(也就是当前模块)的元信息。
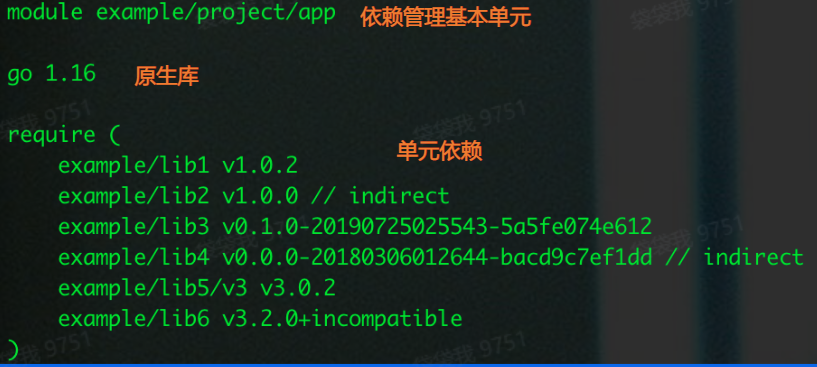
首先模块路径用来标识一个模块,从模块路径可以看出来从哪里找到该模块,如果是clone自
github,则前缀就是Github仓库,依赖包的源代码由github托管。如果项目的子包想被单独的引用,就需要通过单独的
init go。mod文件进行管理。


版本管理

gopath和govender都是源码副本方式依赖,没有版本规则的概念,而gomod为了方便管理定义了版本规则,分为语义化版本和 基于commit的伪版本。- 在语义化版本规则中,不同的MAJOR版本表示不兼容的API,所以即使是同一个库,
MAJOR版本不同也不会被认为为是不同的模块;MINOR版本通常是新增函数或者功能,向后兼容;而PATCH版本一般是修复BUG;- 基于
commit的版本中,基础版本前缀和语义化版本一样,时间戳(yyyymmddhhmmss)也就是该提交Commmit的时间,最后的校验码部分包含了12位的哈希前缀,每次提交commit后go都会默认生成一个伪版本号。
indirect
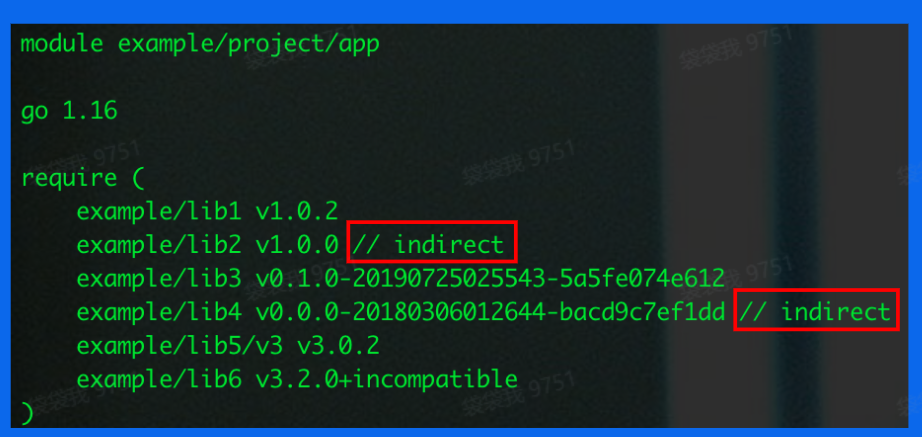
indirect是依赖单元中的特殊标识符之一,以后缀的形式存在,表示go.mod对应的当前模块,没有直接导入该依赖的包,也就是非直接依赖,标识间接依赖,如:

- 在执行命令
go mod tidy时,Go module 会自动整理go.mod文件,如果有必要会在部分依赖包的后面增加// indirect注释。一般而言,被添加注释的包肯定是间接依赖的包,而没有添加// indirect注释的包则是直接依赖的包,即明确的出现在某个import语句中。
依赖图

依赖分发&回源
就是我从哪里来,怎么来的问题。
github是比较常见的代码托管平台,而Go Modules系统中定义的依赖,最终可以对应到多版本代码管理系统中某一个项目的特定提交版本,这样的话,对于go mod中定义的依赖,则直接可以从对应仓库中下载指定的软件依赖,从而完成依赖分发。
但是直接使用版本管理仓库下载依赖,会存在一些问题,比如无法保证构建确定性,软件作者可以直接在代码平台对软件的版本进行增删改查,导致下次构建使用的是另外一个版本依赖,或者找不到依赖版本,无法保证依赖的可用性,依赖软件作者可以直接在平台删除软件,导致依赖不可用,大幅度增加第三方代码托管平台的压力。 基于此,可以使用下面的Proxy的方式解决这些问题。
Proxy

go proxy是一个服务站点,他会缓存源站中的软件名称,缓存的软件版本不会改变,并且在源软件删除之后依然可以用,从而实现了供immutability和available的依赖分发;使用proxy之后,构建时会直接从proxy站点拉取依赖。
变量GOPROXY
GOPROXY="https://proxy1.cn,https://proxy2.cn,direct"服务站点URL列表,"direct”表示源站。
go module通过goproxy环境变量控制如何使用go proxy;goproxy是一个goproxy站点的URL列表,可以使用direct表示源站。对于示例配置,整体的依赖寻找路径,会优先从proxy下载依赖,如果proxy1不存在,会从proxy2继续寻找,如果proxy2z中不存在则会返回到源站直接下载依赖,缓存到proxy站点中。
go get

get命令用来解决go模块及其依赖项目的下载、创建和安装问题。实际该命令线执行从在线仓库(BitBucket、GitHub、Google ``Code、国内的gitee等)下载模块(包),再执行Go Install命令。
get命令是依赖git。
get会先下载相关依赖项目模块,下载时每个包或包的部分模块,下载的版本默认遵从以下顺序:最新
release版 > 最新pre-release版 >其他可用的较高版本。
go mod

2.测试&项目实战
2.1 测试
从单元测试实践出发,提升质量意识。
- 单元测试
Mock测试- 基准测试
什么?你写代码不用测试?不要钱了是吧!
- 营销配置错误,导致非预期用户享受权益,资金损失
10w+- 用户体现,幂等失效,短时间可以多次体现,资金损失
20w+- 代码逻辑错误,广告位被占,无法出广告,收入损失
500w+- 代码指针使用错误,导致
APP不可用,损失kw+
所以,测试就成了避免事故的最后一道屏障。

如上图所示,从上到小,覆盖率逐层变大,成本却逐层降低。
- 回归测试一般是
QA同学手动通过终端回归的一些固定的主流程场景。 - 集成测试是对系统功能维度做的测试验证;
- 单元测试测试开发阶段,开发者对单独的函数、模块做功能的测试,层级从上至下,测试成本逐渐减低,而覆盖率逐步上升,所以单元测试的覆盖率一定程度上决定着代码的质量
2.1.1 单元测试

单元测试主要包括输入、测试单元。输出以及校对,单元测试的概念比较广,包括了接口、函数、模块等;用最后的校对来保证代码的功能与我们的预期相符;一方面可以保证质量,在整体覆盖率足够的情况下,一定程度上既保证了新功能本身的正确性,也不会破坏原有代码的正确性。另一方面可以提升效率,在代码有bug的情况下,通过编写单元测试,可以在一个较短的周期内定位和修复问题。
单元测试规则
下面是单元测试的一些基本规范,这样从文件上就很好的区分源代码和测试代码,以Test开头,且理解的第一个字母大写。
- 所有测试文件以
_test.go结尾;func TestXxx(*testing.T);- 初始化逻辑放到
TestMain中;
package test
import "testing"
func HelloTom() string {
return "Jerry"
}
func TestHelloTom(t *testing.T) {
output := HelloTom()
expectOutput := "Tom"
if output != expectOutput {
t.Errorf("Expected %s do not match actual %s", expectOutput, output)
}
}
在上面的测试代码中,我们调用
HelloTom()分方法,我们的正确预期是希望测试输出Tom,但实际函数输出一个Jerry,明显这是不符合预期的,所以测试不予通过。

单测-assert
前面测试直接使用的是比较运算符,除此之外,还有很多现有的aeert包可以帮助我们实现测试中的比较操作。
package test
import (
"github.com/stretchr/testify/assert"
"testing"
)
func HelloTom() string {
return "Tom"
}
func TestHelloTom(t *testing.T) {
output := HelloTom()
expectOutput := "Tom"
assert.Equal(t, expectOutput, output)
/*if output != expectOutput {
t.Errorf("Expected %s do not match actual %s", expectOutput, output)
}*/
}
单测-覆盖率
package test
import (
"github.com/stretchr/testify/assert"
"testing"
)
func JudgePassLine(score int16) bool {
if score >= 60 {
return true
}
return false
}
func TestJudgePassLineTrue(t *testing.T) {
isPass := JudgePassLine(80)
assert.Equal(t, true, isPass)
}
这是一个判断成绩是否合格的程序,返回bool,输入分数为80,执行测试之后发现只有%66.7左右的覆盖率。因为用例为80的时候,只是跑了程序的前面两行,也就是分数大于60的逻辑,而剩下的返回false部分的逻辑并没有得到测试,所有覆盖率自然不会是100%。
所以,我们新增一个测试如下:这样就可以做到测试覆盖率百分百。
func TestJudgePassLineTrue(t *testing.T) {
isPass := JudgePassLine(80)
assert.Equal(t, true, isPass)
}
func TestJudgePassLineFail(t *testing.T) {
isPass := JudgePassLine(40)
assert.Equal(t, false, isPass)
}
单测-Tips
- 一般覆盖率:
50%-60%,较高可达80%- 测试分支相互独立,全面覆盖
- 测试单元粒度足够小,函数单一职责
单测-依赖
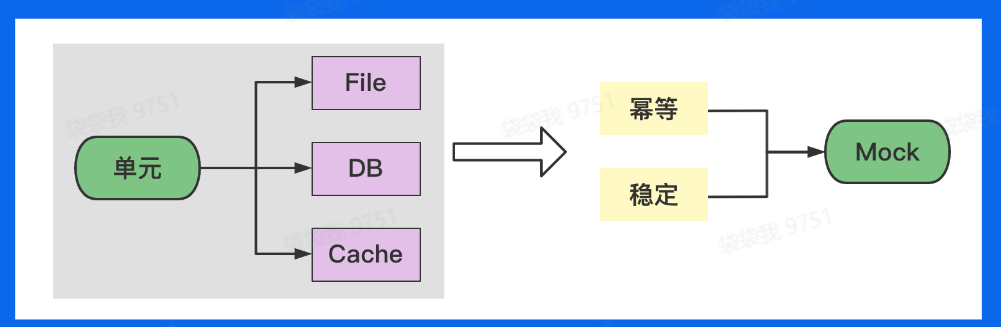
实际工程中,复杂的项目一般都会有依赖,而我们单元测试需要保证稳定性和幂等性,稳定性是指相互隔离,能在任何环境、任何时间运行测试。
幂等性指的是每一次测试运行都因该产生与之前一样的结果,而要实现这一目的就要用到Mock机制。
示例-文件处理
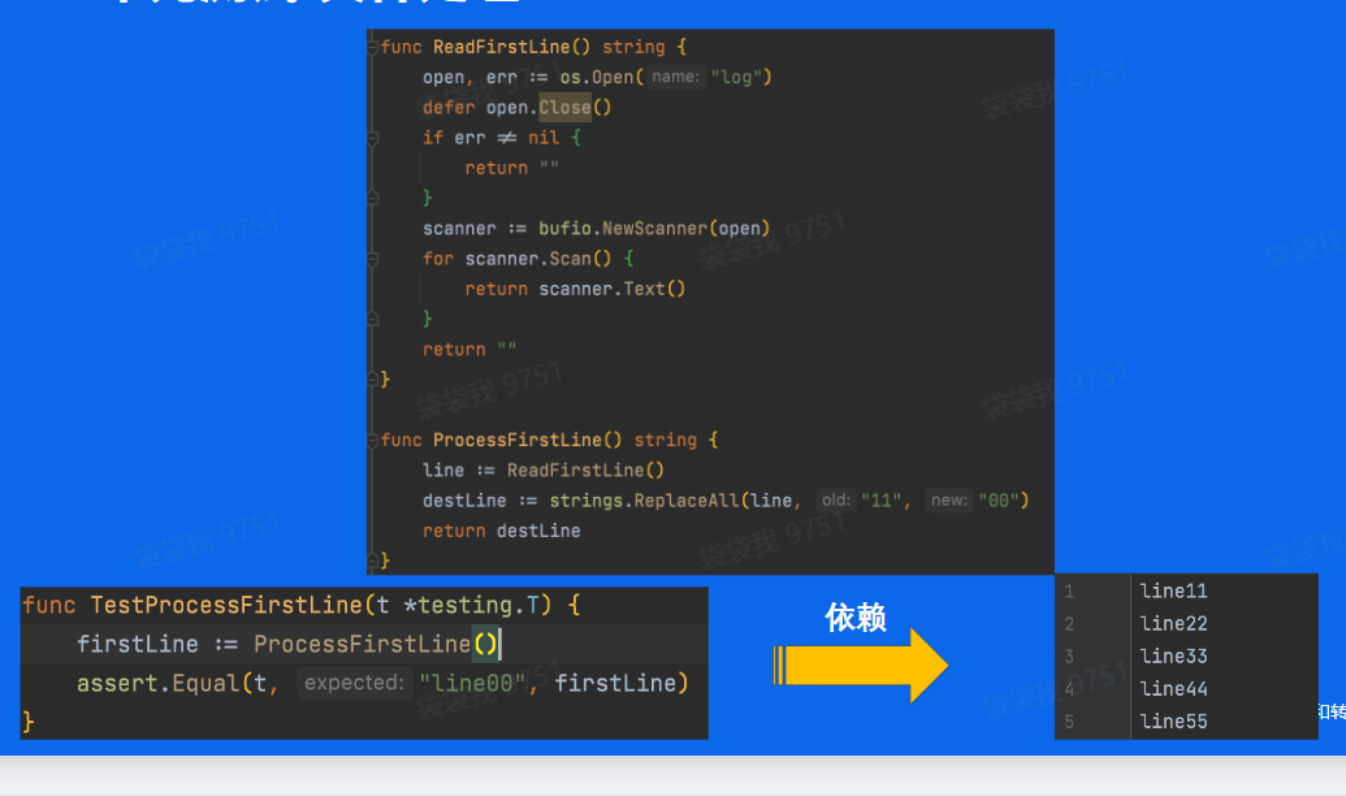
如图,这个例子中,我们将文件中的第一行字符串中的11替换为00,执行单元测试并通过单元测试,而我们的单元测试需要依赖本的文件,如果文件被修改或者删除,测试就会出现fail。为了保证测试case的稳定性,就需要对读取文件的函数进行mock屏蔽对于文件的依赖。
2.1.2 Mock测试
我们可以使用Monkey,这个开源的mock测试库,对method或者实例的方法进行mock,Mockey Patch的作用域在Runtime,在运行时通过Go的unsafe包,能够将内存中的函数地址替换为运行时函数地址。

快速Mock函数:
- 为一个函数打桩
- 为一个方法打桩
2.1.3 基准测试
[见]【高质量编程与性能调优】篇
2.2 项目实战
通过项目需求、需求拆解、逻辑涉及、代码实现来感受真实的项目开发基本流程。
2.2.1 需求背景
社区话题页面
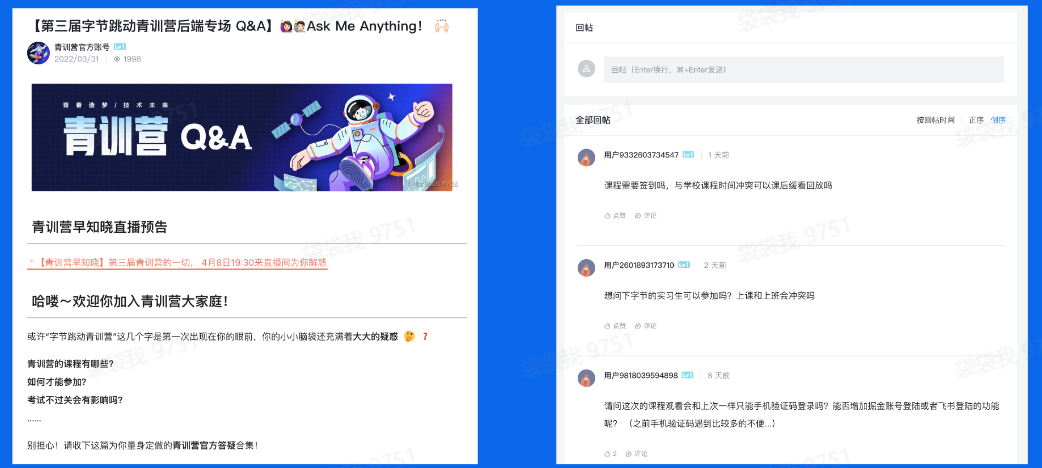
- 展示话题(标题、文字描述)和回帖列表
- 暂不考虑前端页面的实现,仅仅实现一个本地
web服务 - 话题和回帖数据用文件存储,不涉及数据库连接
需求用例

用户浏览页面消费,涉及页面的展示,包括话题内容和回帖列表,从图中可以抽象出来两个实体,以及实体之间的属性与联系,从而定义出对应的结构体。
E-R图
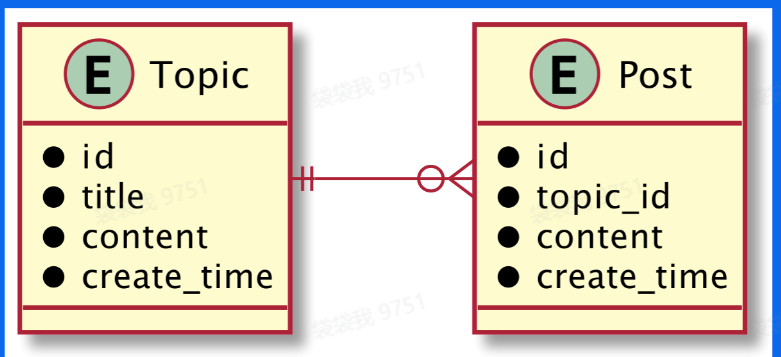
2.2.2 分层结构
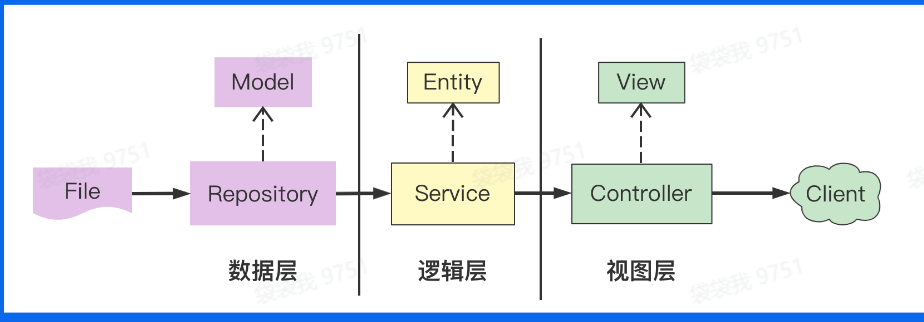
- 数据层:数据
Model,外部数据的增删改查 - 逻辑层:业务
Entity,处理核心业务逻辑输出 - 视图层:视图
View,处理和外部的交互逻辑
整体分为三层,
repository数据层,service逻辑层,controoler视图层。数据层关联底层数据模型,也就是这里的model,封装外部数据的增删改查,我们的数据存储在本地文件,通过文件操作拉取话题,帖子数据;数据层面向逻辑层,对service层透明,屏蔽下游数据差异,也就是不管下游是文件,还是数据库,还是微服务等,对service层的接口模型是不变的。
Service逻辑层处理核心业务逻辑,计算打包业务实体entiy,对应我们的需求,就是话题页面,包括话题和回帖列表,并上送给视图层;Controller视图层负责处理和外部的交互逻辑,以view视图的形式返回给客户端,对于我们需求,我们封装json格式化的请求结果,api形式访问即可。
组件工具
-
这里主要涉及 路由分发
-
go mod
go mod initgo get
初始化
go mod配置文件以及获取gin依赖下载。go get gopkg.in/gin-gonic/gin.v1@v1.3.0如果执行
get命令之后长时间没反应出现超时情况,可以在命令行执行下面的命令之后再次尝试即可下载。go env -w GOPROXY=https://goproxy.cn
2.2.3 开发步骤
Reposity
开发工作准备好之后,首先处理的是数据层逻辑,可以使用
struct定义好结构体,文件中的数据格式如下,实现QueryTopicById以及QueryPostsByParentId两个查询。

数据索引
由于需要根据ID查询到帖子和话题数据,在没有使用数据库的情况下, 我们如何实现呢?最直接的方式就是针对数据文件进行全盘扫描,但显然这是比较耗时的操作,并不是最优的选择,所以这里就用到了 索引的概念。
索引就类似于书本的目录,通过这种方式,我们可以快速的定位到我们所需内容的位置。具体的,这里使用map结构来实现内存索引,在数据服务对外暴露之前,利用文件元数据初始化全局内存索引,这样就可以实现O(1)时间复杂度的查找操作了。
- 初始化话题数据索引
初始化数据话题数据
基本逻辑:打开文件,基于file初始化scanner,通过迭代器方式遍历数据行,转为结构体存储至内存map
func initTopicIndexMap(filePath string) error {
open, err := os.Open(filePath + "topic")
if err != nil {
return err
}
scanner := bufio.NewScanner(open)
topicTmpMap := make(map[int64]*Topic)
for scanner.Scan() {
text := scanner.Text()
var topic Topic
if err := json.Unmarshal([]byte(text), &topic); err != nil {
return err
}
topicTmpMap[topic.Id] = &topic
}
topicIndexMap = topicTmpMap
return nil
}
func initPostIndexMap(filePath string) error {
open, err := os.Open(filePath + "post")
if err != nil {
return err
}
scanner := bufio.NewScanner(open)
postTmpMap := make(map[int64][]*Post)
for scanner.Scan() {
text := scanner.Text()
var post Post
if err := json.Unmarshal([]byte(text), &post); err != nil {
return err
}
posts, ok := postTmpMap[post.ParentId]
if !ok {
postTmpMap[post.ParentId] = []*Post{&post}
continue
}
posts = append(posts, &post)
postTmpMap[post.ParentId] = posts
}
postIndexMap = postTmpMap
return nil
}

- 查询话题数据
有了内存索引,直接根据查询key获得对应的value就可以了,这里用到了一个
sync.once,主要用于适用高并发场景下只执行一次,这里基于once的实现模式就是平常说的单例模式,减少存储的浪费。
func NewTopicDaoInstance() *TopicDao {
topicOnce.Do(
func() {
topicDao = &TopicDao{}
})
return topicDao
}
func (*TopicDao) QueryTopicById(id int64) *Topic {
return topicIndexMap[id]
}
Service

具体的编排流程,通过err控制流程退出,正常会返回页面信息。
func (f *QueryPageInfoFlow) Do() (*PageInfo, error) {
if err := f.checkParam(); err != nil {
return nil, err
}
if err := f.prepareInfo(); err != nil {
return nil, err
}
if err := f.packPageInfo(); err != nil {
return nil, err
}
return f.pageInfo, nil
}
接下来只需要编写对应的每一个实现方法即可。写完controller之后,创建一个服务启动入口server.go
func main() {
if err := Init("./data/"); err != nil {
os.Exit(-1)
}
r := gin.Default()
r.GET("/community/page/get/:id", func(c *gin.Context) {
topicId := c.Param("id")
data := controller.QueryPageInfo(topicId)
c.JSON(200, data)
})
err := r.Run()
if err != nil {
return
}
}
func Init(filePath string) error {
if err := repository.Init(filePath); err != nil {
return err
}
return nil
}
执行下面的命令启动并访问接口:
go run server.gohttp://127.0.0.1:8080/community/page/get/2
项目扩展:
- 帖子发布支持
- 本地Id生成需要保证不重复、唯一性
Append文件,更新索引、注意Map的并发安全问题
2.2.4 项目小结
-
os.Open()Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;open, err := os.Open(filePath + "topic") if err != nil { return err } -
func NewReader(rd io.Reader) *Readerbufio包实现了有缓冲的I/O。它包装一个io.Reader或io.Writer接口对象,创建另一个也实现了该接口,且同时还提供了缓冲和一些文本I/O的帮助函数的对象。bufio.NewReader()使用NewReader读取文件时,首先,我们需要打开文件,接着, 使用打开的文件返回的文件句柄当作 函数参数 传入NewReader。最后,我们使用
NewReader返回的reader对象调用Read来读取文件。文件读取结束的标志是返回的n 等于 0,因此,如果我们需要读取整个文件内容,那么我们需要使用 for 循环 不停的读取文件,直到n 等于 0。注意,在上面的项目中实际使用到的是``func NewReader(rd io.Reader) *Scanner
构造函数。读取数据之后返回一个Scanner,再调用其Scan()方法对文件数据进行逐行扫描读取,直到遇到文件末尾,方法返回false`。
致谢&参考
- 协程的概念
- 《Java并发编程之美》
- 字节内部课
PPT - 使用monkey进行mock
- Go在线手册















 9199
9199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











