






目录
一.数据分析的概念
》数据分析是利用数学、统计学理论与实践相结合的科学统计分析方法,对Excel数据、数据库中
的数据、收集的大量数据、网页抓取的数据进行分析从中提取有价值的信息并形成结论进行展示的
过程。
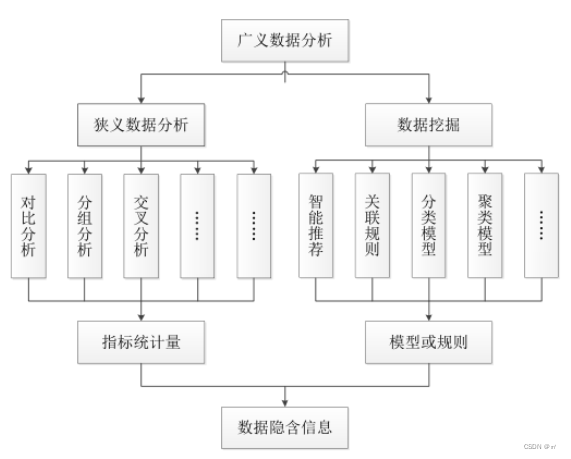
》广义的数据分析包括狭义数据分析和数据挖掘,狭义的数据分析通过数据的统计分析发现数据中
的信息,分析数据结果背后的原因。
》数据挖掘则是通过数学算法和模型挖掘数据潜在规律,还可以预测数据的未来的走向。
二.数据分析流程
典型的数据分析的流程:
熟悉工具→明确目的→获取数据→数据处理→数据分析→验证结果→结果呈现→数据应用

三.Python数据分析环境配置
在Windows系统上安装Anaconda
安装Anaconda官网: https://www.anaconda.com/
安装流程:
安装包——“l agree”——“All Users(requires admin privileges)”——选择安装路径"next”
——“install”——“finish”。
四.掌握JupyterNotebook的基本功能
Jupyter Notebook简介:
⚪一个Anaconda自带的轻量级Python编辑器可以在浏览器中打开
⚪有美观的注释,文字和代码完美结合
⚪可以分步运行代码
⚪善于进行数据分析的结果展示和分析

打开Jupyter Notebook的步骤:
1.在windows中搜索“anaconda”
2.点击“Anaconda Prompt”,进入anaconda环境命令框。
在命令框中输入“jupyter notebook”回车,浏览器中将自动启动jupyter编辑器。
若浏览器中没有直接弹出jupyternotebook的目录,将红色框中的网址复制到浏览器中运行即可。
五.使用jupyter notebook导入外部数据
1.读取excel文件数据
data=pd.read_excel(r'D:\python数据分析与应用\学生数据.xlsx')

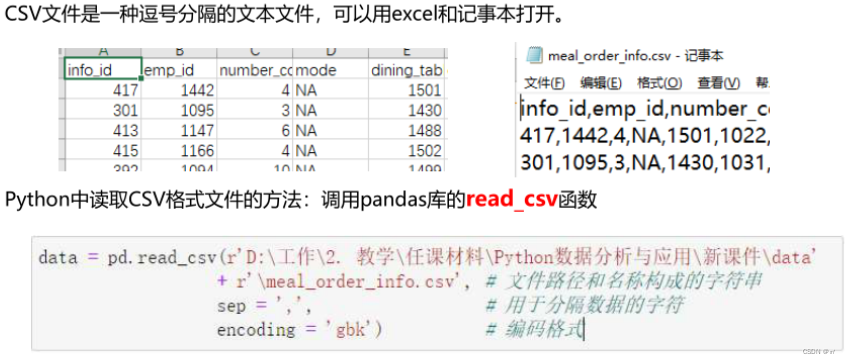
2.读取文本数据(以csv文件为例)
data=pd.read_csv(r'D:\python数据分析与应用\学生数据.csv')
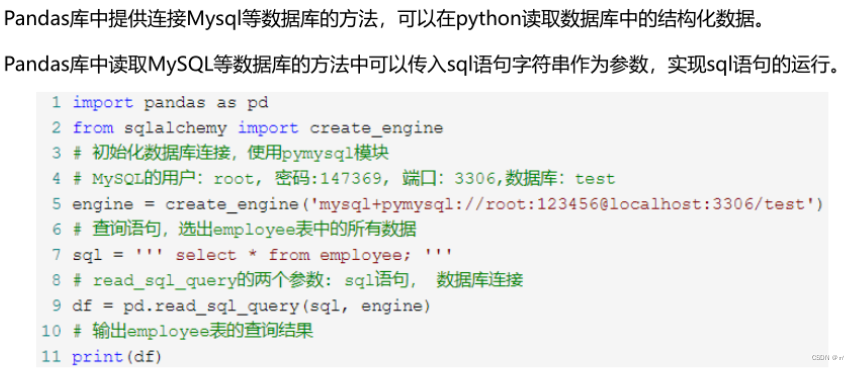
3.读取数据库数据
六.python 数据分析依赖的两个对象
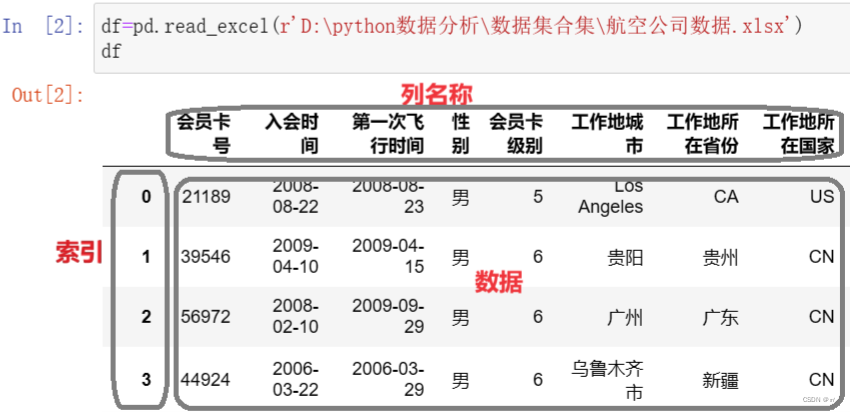
1. DataFrame表格对象
①|概念|
导入数据库表格或者excel数据时形成的数据对象就是表格对象
表格对象的类型:DataFrame
②|表格对象的组成部分|
1.数据(values) 2.索引(index) 3.列名称(columns)
③|创建表格对象的方法|
·可以通过pandas库中的DataFrame()类来创建一个表格对象。
·通过DataFrame()类的参数columns来设置表格对象的列名称。
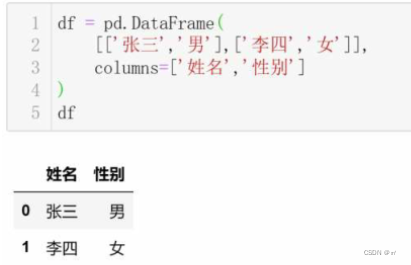
④|表格对象的属性|
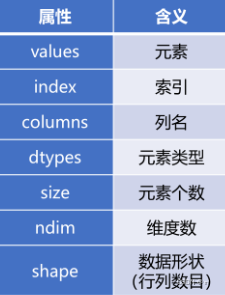

⑤|表格对象的基本方法|
> head0: 返回前5行数据,用于概览
>info():查看表格对象行列数、各列的数据类型和非空值数量
>describe0:对表格对象中的数字型序列进行各类统计量的计算
>rename0):修改表格对象的列名称
>to excel0:将表格对象导出成excel
2.Series序列对象
①|概念|
Series序列对象即DataFrame表格对象中的某一列数据。
Series序列对象简称序列对象,其数据类型是 Series。
②|获取序列对象的方法|
从表格对象中提取序列对象:表格对象['列名称']
手动生成一个序列对象:pd.Series(列表对象)类生成
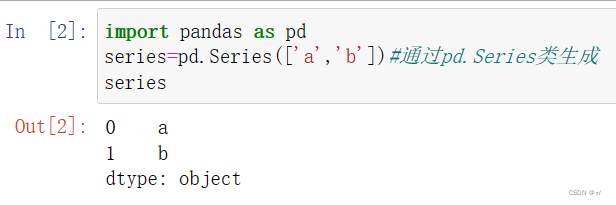
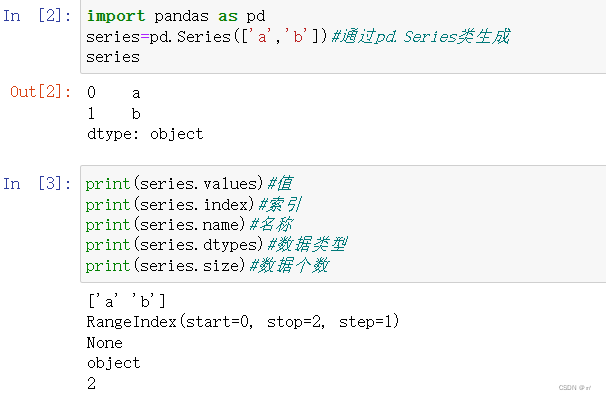
③|Series序列对象的属性|

④|Series序列对象的运算|
序列对象和数字或者另一个序列之间可以进行基本的运算。


⑤|Series序列对象常用方法|
⚪astype()#用来转换序列对象中元素的数据类型。
⚪values_counts()#用于统计序列中每个元素值出现了多少次。注意:返回值也是一个序列对象。
⚪sort_values()#对序列中的数据进行排序。注意:返回的新序列对象中的索引排序被打乱了。
⚪rank()#返回序列中数据大小的排名。注意:返回的是一个序列对象,索引和原序列相同。
⚪round()#控制数字型序列的小数点位。
⚪agg()#对序列对象的元素进行加工的方法。注意:返回序列对象。
语法:1.序列对象.agg(lambda x:关于x的返回值)
2.序列对象.agg(定义好的加工函数)
⚪序列对象.str.方法名()


加油!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









