






在数据驱动的时代背景下,数据分析职位的需求日益增长。为了更好地理解市场上对数据分析人才的需求,我编写了一个Python爬虫程序,自动从招聘网站拉勾网抓取相关职位信息。
1、导入库:
import requests
import json
import csv
import time
requests:用于发送HTTP请求。json:用于处理JSON格式的数据。csv:用于写入CSV文件。time:用于在请求之间添加延迟,避免过于频繁的请求。
2、定义爬取数据函数:
定义一个名为get_lagou_data的函数,接收一个URL作为参数:
def get_lagou_data(url):
# 构建请求头
headers = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88/p-city_0?',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'cookie': 'you cookie'
}
# 用data进行分页爬取
for i in range(1, 1001):
data = {
'first': 'true',
'pn': i,
'kd': '数据分析'
}
# 请求网页
response = requests.post(url=url, headers=headers, data=data, timeout=3)
print(response.text)
time.sleep(3) # 休息一下
# json.loads 用于解码 JSON 数据。该函数返回 Python字段的数据类型
response = json.loads(response.content)
# 获取15条数据
result = response['content']['positionResult']['result']
# 获取每条招聘岗位里面的详细信息
for i in result:
position_name = i['positionName'] # 职位名称
company_full_name = i['companyFullName'] # 公司名称
industryField = i['industryField'] # 行业
city = i['city'] # 城市
salary = i['salary'] # 薪水
work_year = i['workYear'] # 工作年限
education = i['education'] # 教育背景
position_advantage = i['positionAdvantage'] # 岗位优势
skillLables = i['skillLables']
# 存储数据, 先在当前文件下创建一个叫‘lagou_datas.csv’的文件
# 'a' 追加写入,;encoding设置编码格式,防止乱码 ;newline是为了解决写入时新增行与行之间的一个空白行问题
with open('D:/shuju/lagou_datas.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 写入数据
csv_write = csv.writer(f)
# csv_write.writerow(["职位名称", "公司名称", "行业", "城市", "薪资", "工作年限", "学历要求", "福利","技能要求"])
# 按照以下行顺序写入,是一个列表
csv_write.writerow([position_name, company_full_name, industryField,city, salary,
work_year, education, position_advantage,skillLables])
time.sleep(3) # 休息一下
在函数内部,首先构建了一个headers字典,包含了一些HTTP请求头信息,如:
-
origin:请求发起的源地址。
-
referer:从哪个页面链接过来的。
-
user-agent:用户代理,即浏览器标识。
使用快捷键Ctrl+Shift+I或F12打开开发者工具
在输入框中输入【职位 (这里的示例为数据分析)】进行搜索,抓包分析,可以看到user-agent信息就包含在其中
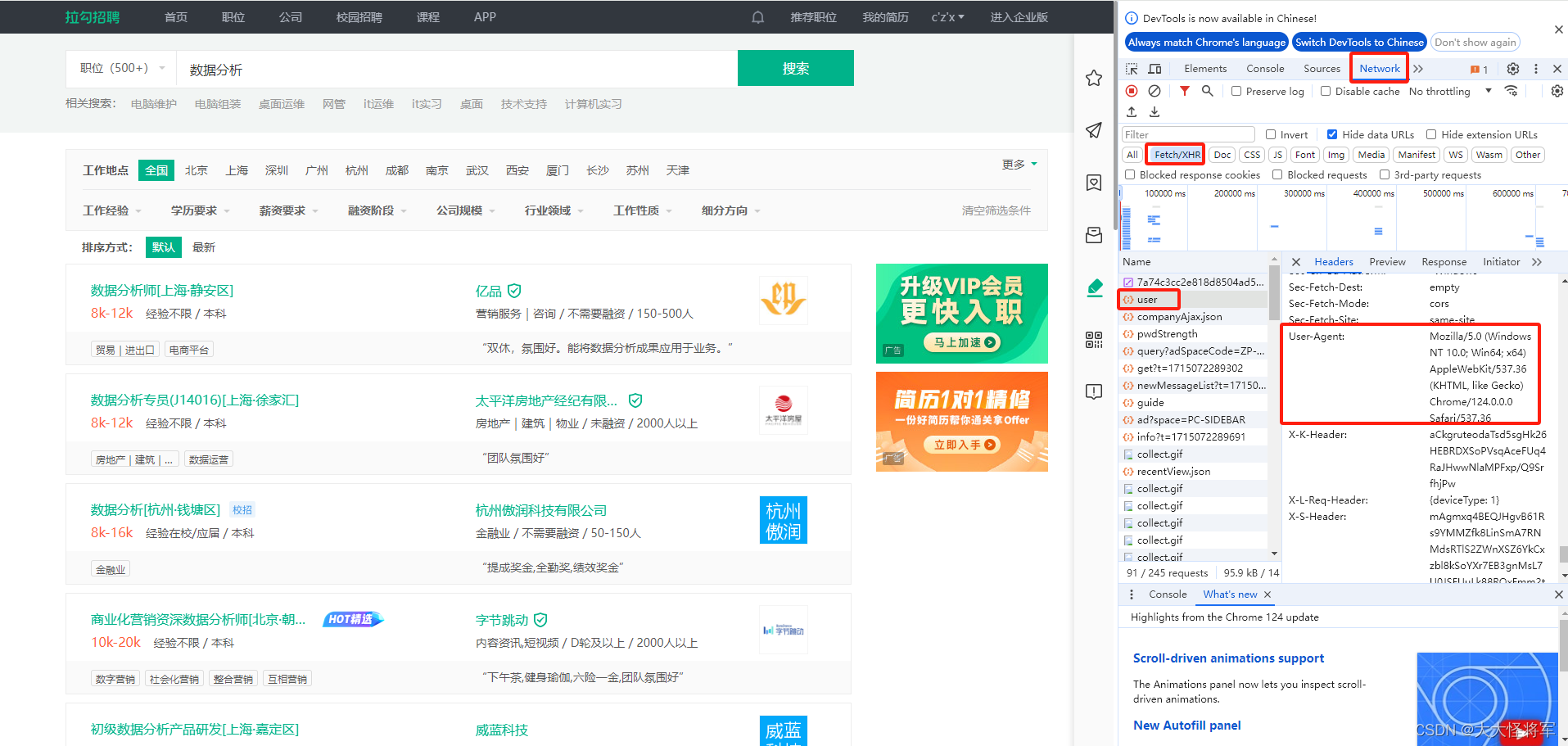
-
cookie:包含了用户会话信息的cookie字符串。
使用快捷键Ctrl+Shift+I或F12打开开发者工具
在输入框中输入【职位 (这里的示例为数据分析)】进行搜索,抓包分析,可以看到cookie信息就包含在其中
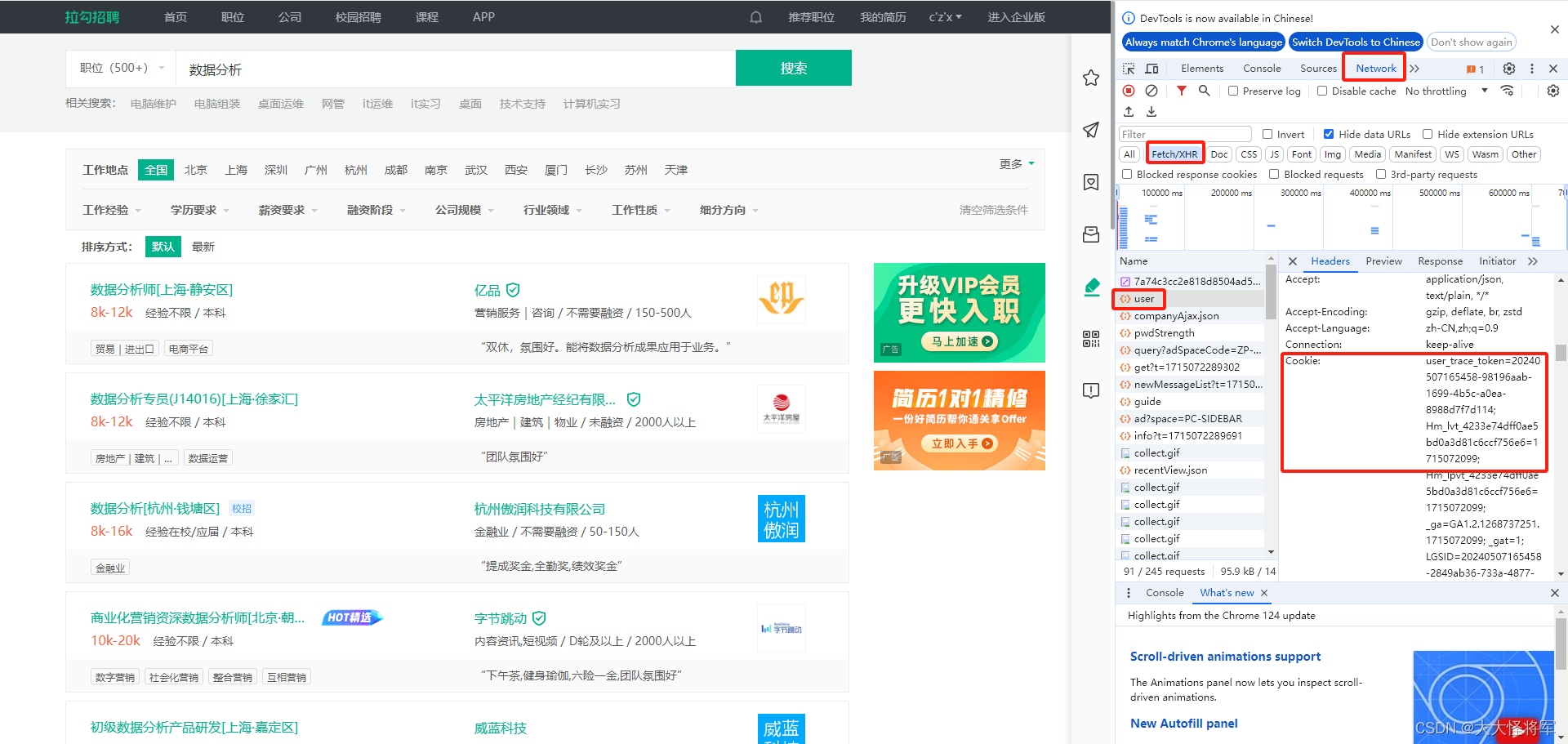
分页爬取:使用一个循环来模拟分页爬取,从第1页到第1000页,循环中使用range(1, 1001)
提取职位信息:从响应中提取所需的职位信息,如职位名称、公司名称、行业、城市、薪水等
保存信息:把爬取下来的职位信息保存在D:/shuju/lagou_datas.csv中
完整代码:
# 导入包
import requests
import json
import csv
import time
def get_lagou_data(url):
# 构建请求头
headers = {
'origin': 'https://www.lagou.com',
'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88/p-city_0?',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'cookie': 'you cookie'
}
# 用data进行分页爬取
for i in range(1, 1001):
data = {
'first': 'true',
'pn': i,
'kd': '数据分析'
}
# 请求网页
response = requests.post(url=url, headers=headers, data=data, timeout=3)
print(response.text)
time.sleep(3) # 休息一下
# json.loads 用于解码 JSON 数据。该函数返回 Python字段的数据类型
response = json.loads(response.content)
# 获取15条数据
result = response['content']['positionResult']['result']
# 获取每条招聘岗位里面的详细信息
for i in result:
position_name = i['positionName'] # 职位名称
company_full_name = i['companyFullName'] # 公司名称
industryField = i['industryField'] # 行业
city = i['city'] # 城市
salary = i['salary'] # 薪水
work_year = i['workYear'] # 工作年限
education = i['education'] # 教育背景
position_advantage = i['positionAdvantage'] # 岗位优势
skillLables = i['skillLables']
# 存储数据, 先在当前文件下创建一个叫‘lagou_datas.csv’的文件
# 'a' 追加写入,;encoding设置编码格式,防止乱码 ;newline是为了解决写入时新增行与行之间的一个空白行问题
with open('D:/shuju/lagou_datas.csv', 'a', encoding='utf_8_sig', newline='') as f:
# 写入数据
csv_write = csv.writer(f)
# csv_write.writerow(["职位名称", "公司名称", "行业", "城市", "薪资", "工作年限", "学历要求", "福利","技能要求"])
# 按照以下行顺序写入,是一个列表
csv_write.writerow([position_name, company_full_name, industryField,city, salary,
work_year, education, position_advantage,skillLables])
time.sleep(3) # 休息一下
# 主程序
if __name__ == '__main__':
# Ajax的URL
url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
# 传入URL,调用函数
get_lagou_data(url)
注意事项
- 该爬虫程序可能受到拉勾网反爬虫机制的限制。
- 网站的结构变化可能导致解析路径失效。
- 使用的
cookie需要是有效的用户会话信息。















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









