







一.目标
爬取拉勾网指定城市的指定职位的一定数据。
二.网站解析
1.url解析
以在拉勾网寻找linux工程师工作为例:
网址是
https://www.lagou.com/jobs/list_linux?labelWords=&fromSearch=true&suginput=
但是详细分析之后可以发现?后面的参数去除也可以得到相应的html,
即 https://www.lagou.com/jobs/list_linux?这个网址也是可以得到想应的网站的
2.分析返回的数据类型是html格式还是json格式
打开chrome的开发者工具,检查网站的详细信息。
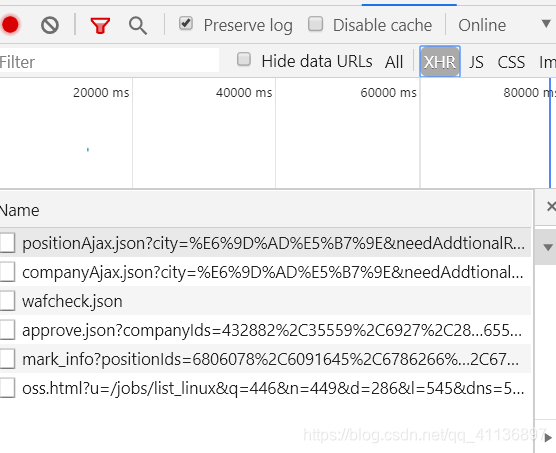
可以看到xhr中有一个positionAjax的json文件,点开preview查看里面的内容,发现了有我们需要的职位信息:
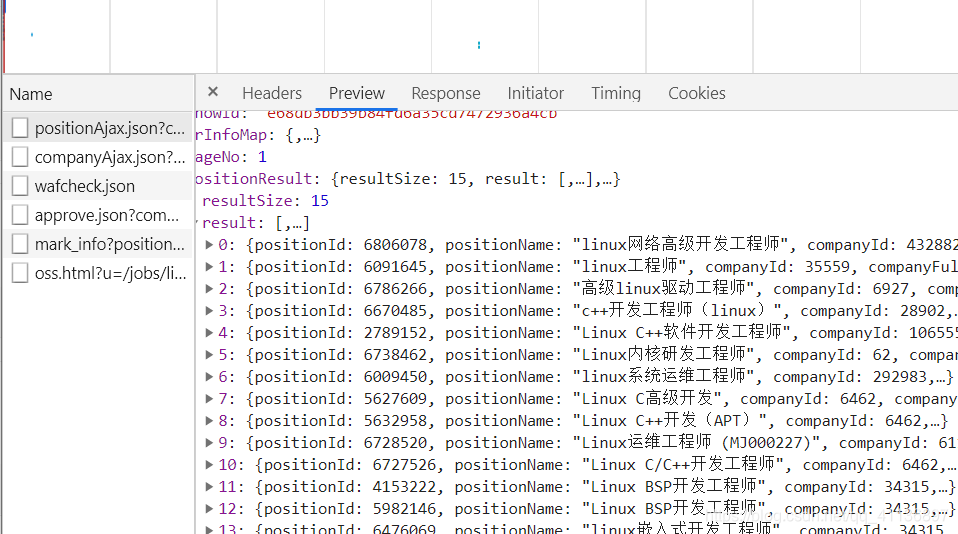
那也就是说这个页面的职位信息应该是通过Ajax请求然后服务器返回的json数据通过js渲染而成的。我对于Ajax请求的理解是:传统的网页更新时,需要刷新页面,使用Ajax后,通过js文件向服务器发送请求,然后得到的数据动态的渲染更新页面。(如果后面发现理解错了,会及时来这里更新)
3.分析headers,拿到json数据
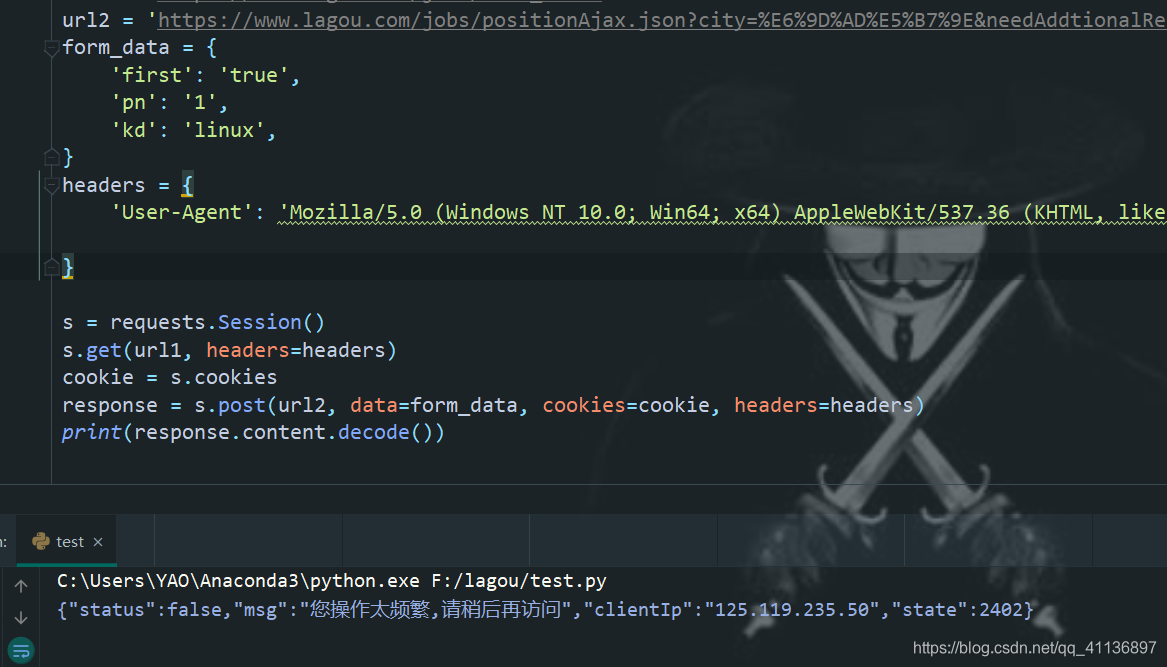
点击headers,可以看到这是一个post类型的请求,表单数据form data可以下拉到最下面得到,查看request url,可以试着再另外的标签页中打开url,会发现和往常的json文件不同,这个链接打开后得不到我们想要的数据,并且会返回一个您的访问次数过多的错误。
这里可能就是触发了网站的反爬机制,常见的反爬措施就是cookies校验,请求头的验证什么的,我们在python中使用requests包的session模块尝试一下后会发现要想拿到这个网站的数据,一个是要得到起始搜索页面的cookies,然后还要定制请求头。
(1)得到cookies并不能得到要的数据
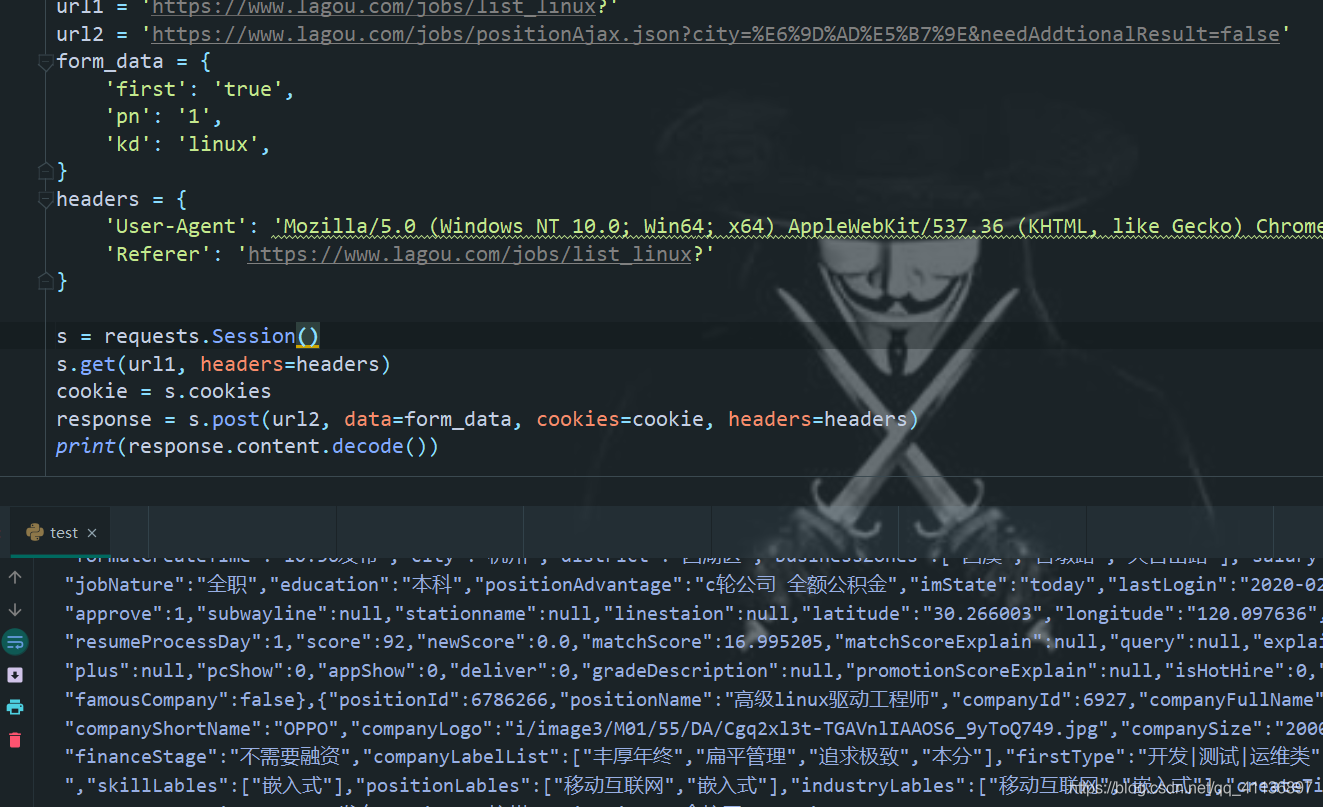
(2)修改headers后添加referer后,可以拿到数据
请求头中rederer的作用就是标识这个请求从哪里来的,服务器可以拿到这个信息并做相应的处理,这里就说明了这个请求是从搜索页面来的,所以单独打开一个标签去访问那个request url拿不到结果。
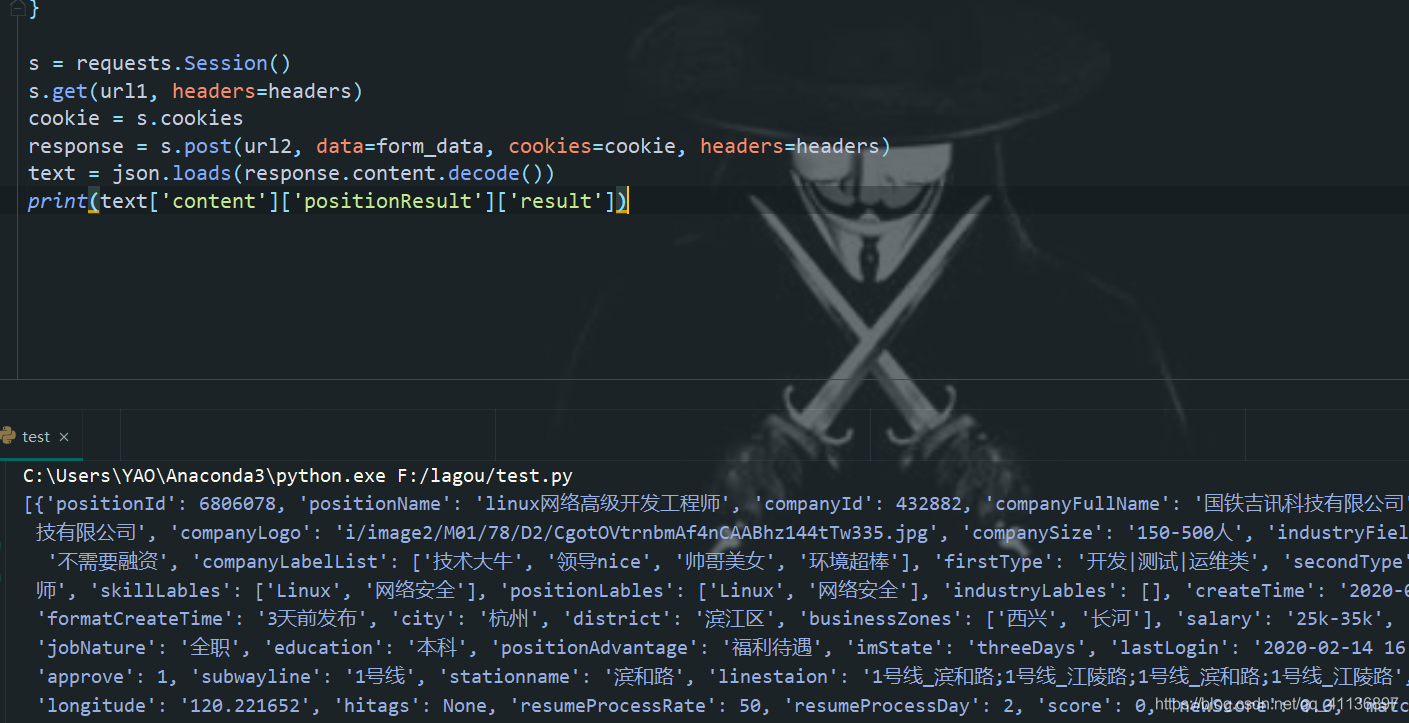
4.分析拿到的json数据,取出我们想要的数据
通过json包的loads()方法来得到数据,至此单个页面的数据分析差不多就结束了。
三.代码实现
# /usr/env/bin/python3
# -*-coding: utf-8 -*-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2054
2054











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









