






python-人脸识别
准备test7个图像文件,和train7个图像文件



训练和验证标签

导入需要的工具包
import pandas as pd
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
import numpy as np
from sklearn.preprocessing import LabelBinarizer
import matplotlib.pyplot as plt
import pickle
## 定义超参数
```python
INIT_LR = 0.01
EPOCHS = 10
BS = 32
读取CSV文件
# 读取训练标签CSV文件
train_labels_filename = 'train_labels.csv'
train_labels_df = pd.read_csv(train_labels_filename)
读取测试标签CSV文件
test_labels_filename = 'test_labels.csv'
test_labels_df = pd.read_csv(test_labels_filename)
确保标签是字符串类型
train_labels_df['label'] = train_labels_df['label'].astype(str)
test_labels_df['label'] = test_labels_df['label'].astype(str)
#train_labels_df['label'] = train_labels_df['label'].astype(str):这行代码将train_labels_df DataFrame中的label列的数据类型转换为字符串。astype(str)是Pandas的一个方法,用于将列的数据类型转换为字符串。
#test_labels_df['label'] = test_labels_df['label'].astype(str):这行代码将test_labels_df DataFrame中的label列的数据类型转换为字符串。
显示结构
print(train_labels_df.head())
print(test_labels_df.head())
定义图像处理参数
img_width, img_height = 150, 150
创建图像数据生成器
data_gen = ImageDataGenerator(rescale=1./255, validation_split=0.2)
设置目录路径
train_dir = '/home/gy/桌面/练习/train(2)' # 包含子目录的父目录
test_dir = '/home/gy/桌面/练习/test(2)' # 包含子目录的父目录
加载训练图像数据集
train_data_gen = data_gen.flow_from_dataframe(
dataframe=train_labels_df,
directory=train_dir, # 包含子文件夹的父目录
x_col='image',
y_col='label',
target_size=(img_width, img_height),
batch_size=32,
seed=42,
subset='training',
)
#train_data_gen = data_gen.flow_from_dataframe(...):这行代码创建了一个生成器,用于从DataFrame中加载图像数据。data_gen是一个ImageDataGenerator对象,它配置了数据增强参数。
#dataframe=train_labels_df:这行代码指定了包含图像路径和标签的DataFrame。
#directory=train_dir:这行代码指定了包含子文件夹的父目录,其中每个子文件夹代表一个类别。
#x_col='image':这行代码指定了DataFrame中包含图像路径的列名。
#y_col='label':这行代码指定了DataFrame中包含标签的列名。
#target_size=(img_width, img_height):这行代码指定了加载的图像将被调整到的尺寸。这里使用了之前定义的img_height和img_width。
#batch_size=32:这行代码指定了每个批量的图像数量。
#seed=42:这行代码为数据的划分提供了随机种子,确保每次代码运行时都能得到相同的划分结果。
#subset='training':这行代码指定了您想要加载的数据集部分。在这里,您指定了加载训练集。
加载验证图像数据集
validation_data_gen = data_gen.flow_from_dataframe(
dataframe=test_labels_df,
directory=test_dir, # 包含子文件夹的父目录
x_col='image',
y_col='label',
target_size=(img_width, img_height),
batch_size=32,
seed=42,
subset='validation',
)
validation_data_gen = data_gen.flow_from_dataframe(...):这行代码创建了一个
定义模型
## 构建模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(MaxPooling2D(pool_size=(2, 2)))
## 新增的卷积层
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
## 展平层
model.add(Flatten())
## 全连接层
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
## 输出层
model.add(Dense(7, activation='softmax'))
## 编译模型
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
## 训练模型并收集历史
history = model.fit(train_data_gen, epochs=EPOCHS, validation_data=validation_data_gen, batch_size=BS)
绘制损失和准确率曲线
N = np.arange(0, EPOCHS)
plt.style.use('ggplot')
plt.figure()
plt.plot(N, history.history['loss'], label='train_loss')
plt.plot(N, history.history['val_loss'], label='val_loss')
plt.plot(N, history.history['accuracy'], label='train_acc')
plt.plot(N, history.history['val_accuracy'], label='val_acc')
plt.title("Training Loss And Accuracy (CNN)")
plt.xlabel('Epoch #')
plt.ylabel('Loss/Accuracy')
plt.legend()
plt.axis([0, EPOCHS, 0, 2])
N = np.arange(0, EPOCHS):
plt.savefig('plot.png')
保存模型到本地
print('[INFO] 正在保存模型')
model.save('model.h5')
13.结果演示
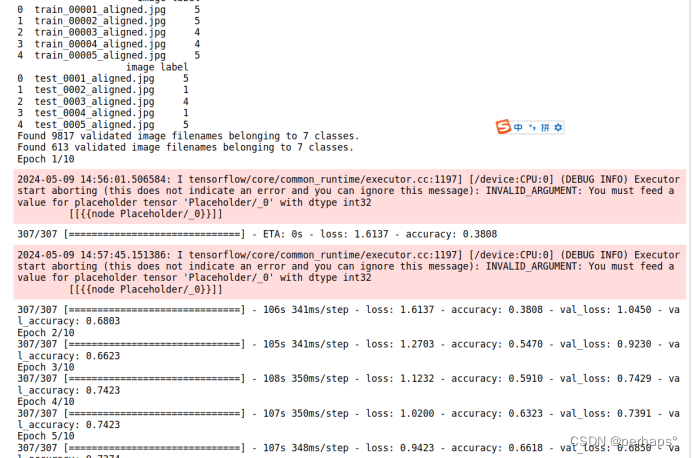
预测模型
import numpy as np
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
## 加载模型
model_path = "model.h5" # 假设模型已保存到这个路径
model = load_model(model_path)
## 加载图片
## 一旦图片上传,我们可以使用以下代码来测试模型
img_path = "/home/gy/桌面/练习/train(2)/train_00036_aligned.jpg" # 替换为上传的图片路径
img = image.load_img(img_path, target_size=(150, 150)) # 图片大小需要与训练时输入模型的大小一致
## 预处理图片
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0) # 因为模型期望输入的是批量的数据,所以需要增加一个维度
img = img / 255.0 # 与训练时的预处理一致
## 使用模型进行预测
predictions = model.predict(img)
## 获取预测结果
predicted_class = np.argmax(predictions, axis=1)[0]
predicted_prob = np.max(predictions, axis=1)[0]
## 显示图片和标签
plt.imshow(img[0])
plt.title(f'Predicted Class: {predicted_class}, Probability: {predicted_prob:.2f}')
plt.axis('off')
plt.show()
14.1结果演示
















 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









