






目录
一.搭建伪分布式实验环境准备
1.完成Linux系统安装的VMware虚拟机
2.Hadoop3.0以上版本的安装压缩包
3.jdk1.8版本的环境安装包
虚拟机搭建准备工作
关闭防火墙
#查看防火墙状态
systemctl status firewalld
#关闭防火墙
systemctl stop firewalld
#设置关闭防火墙开机自启动
systemctl disable firewalld关闭selinux
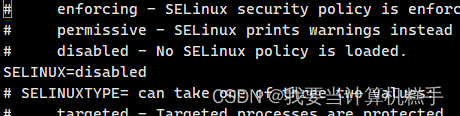
[root@localhost ~]# vi /etc/selinux/config将SELINUX属性的值改为disabled
查看主机IP
[root@hadoop01 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:bd:67:1f brd ff:ff:ff:ff:ff:ff
inet 192.168.1.20/24 brd 192.168.1.255 scope global noprefixroute ens32
valid_lft forever preferred_lft forever
inet6 fe80::8402:2a83:abdb:3e7e/64 scope link noprefixroute
valid_lft forever preferred_lft forever修改主机名
[root@hadoop01 ~]# vi /etc/hostname 这里修改主机名为hadoop01
修改IP与主机映射
[root@hadoop01 ~]# vi /etc/hosts
192.168.1.20 hadoop01
SSH免密登录
[root@localhost ~]# ssh-keygen -t rsa # 生产密钥
# 连续三次回车
# 将密钥发送给需要登陆本机的机器,这里只有一台机器 所以发给自己
[root@localhost ~]# ssh-copy-id root@IP
# 测试ssh
[root@localhost ~]# ssh root@IP
Last login: Fri Apr 26 02:18:54 2024 from 192.168.1.1
二.Hadoop伪分布式搭建
JDK配置
安装包解压
指定解压在/opt/install目录下,目录需自己创。
[root@localhost ~]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C /opt/install/配置环境变量
[root@hadoop01 ~]# vi /etc/profile
# 加入配置,文章末尾
export JAVA_HOME=/opt/install/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
# 保存后刷新环境变量
[root@hadoop01 ~]# source /etc/profile验证jdk是否配置成功
[root@hadoop01 ~]# java -version
java version "1.8.0_152"
Java(TM) SE Runtime Environment (build 1.8.0_152-b16)
Java HotSpot(TM) 64-Bit Server VM (build 25.152-b16, mixed mode)
Hadoop配置
安装包解压
指定解压在/home/software目录下,目录需自己创。
[root@hadoop01 ~]# tar -zxvf hadoop-3.1.3.tar.gz -C /home/software/修改配置文件
#先cd到配置目录下
[root@hadoop01 ~]# cd /home/software/hadoop-3.1.3/etc/hadoophadoop-env.sh文件
vim hadoop-env.sh
#在文件中添加JAVA_HOME,值是JDK的安装路径
export JAVA_HOME=/opt/install/jdk1.8.0_152
保存退出,重新生效这个文件
source hadoop-env.shcore-site.xml文件
tmp文件夹没有需自己创建
[root@hadoop01 hadoop-3.1.3]# vim core-site.xml
#添加以下部分
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-3.1.3/tmp</value>
</property>
hdfs-site.xml文件
[root@hadoop01 hadoop-3.1.3]# vim hdfs-site.xml
#添加以下部分
<property>
<name>dfs.replication</name>
<value>1</value>
</property>mapred-site.xml文件
[root@hadoop01 hadoop-3.1.3]# vim mapred-site.xml
#添加以下部分
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml文件
[root@hadoop01 hadoop-3.1.3]# vim yarn-site.xml
#添加以下部分
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
配置Hadoop环境变量
[root@hadoop01 hadoop-3.1.3]# vim /etc/profile
# 加入
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
验证环境变量配置
# 刷新环境变量
[root@hadoop01 hadoop-3.1.3]# source /etc/profile三.格式化namenode节点,启动hdfs,启动yarn
注意这里不能⽤root账号启动进程,需要在环境变量中配置
vim /etc/profile
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
source /etc/profile格式化namenode
hdfs namenode -format执行
start-dfs.sh
start-yarn.sh再执行
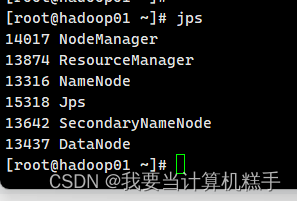
jps
像这样就算是完成了















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









