






在本篇中有些步骤在单机版已经配置过,因此在本篇中有所省略,如果遇到问题,可以看单机版内容,也可以私信我。
文章目录
前言
嗨害嗨,来啦!
在搭建了hadoop单机版之后·,我们进一步学习,集群的搭建,多台机器之间联通和配置。
提示:以下是本篇文章正文内容,下面案例可供参考
一、配置SSH免密登陆,机群互通(虚拟机需为桥接模式)
//打开命令窗口
$sudo apt-get install openssh-server //下载ssh客户端,两台机器都需下载
$ssh localhost //登陆本地
$exit //退出
$cd ~/.ssh/
$ssh-keygen -t rsa //生成密钥
$cat ./id_rsa.pub >> ./authorized_keys //将生成的密钥追加到指定文件内
$ssh localhost //此时登陆不需要密码了
$sudo vim /etc/hostname //打开客户端名称,修改localhost为master,另一台机器需对应改为slave,打开客户端名称,修改为master , 按键esc,再:wq 保存退出
$ifconfig //查看网络,查看自己的网络ip,待会添加
$sudo vim /etc/hosts //打开客户端信息,注释掉localhost,加上master和slave的ip地址,打开节点信息,注释掉127.0.1,例:#127.0.1 localhost,添加例如:10.130.224.185 master 10.130.224.184 slave01
//在master节点上进行以下操作
$cd ~/.ssh //如果提示找不到文件或路径,先执行一次ssh localhost
$rm ./id_rsa* //如果有,则删除之前的公钥
$ssh-keygen -t rsa //一路回车生成公钥
$cat ./id_rsa.pub >> ./authorized_keys //将公钥放到autiorized_keys中
$scp ~/.ssh/id_rsa.pub hadoop@slave:/home/hadoop //将meter节点到公钥复制到slave节点中
//在slave节点上进行以下操作
$cat ~/id_rsa.pub>>~/.ssh/authorized_keys //将从master传来的公钥放置在authorized_keys中
$rm ~/id_rsa.pub //删除传来的公钥
此时基本可以互通了,可以在节点上ping一下另一台机器。
二、hadoop安装与配置
1.下载安装包(本次采用hadoop2.10)
2.解压安装包到指定目录


3.修改目录名称和权限

4.查看版本信息

5.配置文件
四个文件core-site.xml,hdfs-site.xml,yarn-sit.xml,mapred-site.xml,和slaves
$cd /usr/local/hadoop/etc/hadoop //切到hadoop配置文件的目录
$sudo vim core-site.xml //其中master为节点名称,131072是默认块大小,128MB(这里可以详看后面hdfs中的内容)
//usr/local/hadoop/tmp为新创建的目录;
添加如下
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
//然后esc ,再:wq即可保存退出
$sudo vim hdfs-site.xml //hdfs-site是对hdfs(hadoop distributed file system)的配置,设置了名称节点、第二名称节点、数据节点以及备份信息等。其中/usr/local/hadoop/dfs/name和/usr/local/hadoop/dfs/data为新建目录,这些目录会在Hadoop集群运行后,记录相关数据;
添加如下
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
$sudo vim yarn-site.xml //对资源调度的管理
添加如下
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
$ cp mapred-site.xml.template mapred-site.xml //复制mapred-site.xml.template并重命名为mapred-site.xml
$sudo vim mapred-site.xml
添加如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
$sudo vim slaves //需要修改当前目录下的slaves文件,slaves是用来设置datanode节点。slaves文件默认为localhost,即默认情况下,namanode和datanode都被部署在同一个节点上,而我们要做伪分布式Hadoop环境,所以,需要将slaves中的内容修改为slave节点名称。
6.将配置内容打包发送到slave节点
将master节点中/usr/local/hadoop中的内容打包压缩,然后发送到slave节点中
$cd /usr/local
$sudo rm -r ./hadoop/tmp //删除Hadoop路径下的临时文件
$sudo rm -r ./hadoop/logs //删除Hadoop路径下的日志文件
$tar -zcf ~/hadoop.master.tar.gz ./hadoop //将hadoop目录下的内容打包复制到~/hadoop.master.tar.gz
$scp ~/hadoop.master.tar.gz slave:/home/hadoop //将打包内容复制到slave节点
在slave节点上解压hadoop.master.tar.gz文件,并给予授权
$sudo rm -r /usr/local/hadoop //删除之前版本
$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local //解压文件到 /usr/lcoal
$sudo chown -R hadoop /usr/local/hadoop //授权
如果有更多slave节点,对集群中的其他slave节点做同样的操作即可
三、hadoop的启动与使用
1.初始化hadoop
$cd /usr/local/hadoop
$./bin/hdfs namenode -format /初始化名称节点
2.启动hadoop
$cd /usr/local
$./sbin/start-all.sh
3.启动展示
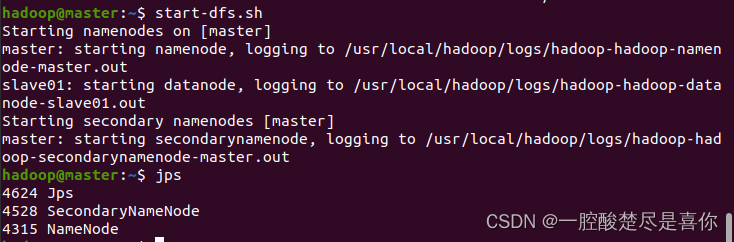

Hadoop的启动:
在master节点上依次执行start-dfs.sh、start-yarn.sh等命令,可以分别在master节点和slave节点上看到对应调起的线程,用jps命令查看如下图所示;也可以直接执行start-all.sh命令;
Hadoop的停止:
在master节点对应执行stop-yarn.sh、stop-dfs.sh命令即可,也可直接执行stop-all.sh命令
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了hadoop伪分布式的搭建,而hadoop提供了许多的功能供我们去学习和使用,后续我也会继续更新,希望大家能点赞收藏转发,谢谢大家了
。
















 5680
5680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











