






摘要
本研究旨在通过数据挖掘技术深入分析银行客户流失问题。我们采用了一个包含客户基本信息、财务状况、信用评分及行为偏好等多维度数据的银行客户数据集。经过数据预处理、可视化分析、回归分析、决策树模型、贝叶斯分类、BP神经网络、聚类分析及集成算法等多种方法的综合应用,揭示了影响客户流失的关键因素。研究发现,客户的行为偏好、信用评分、财务状况及与银行的互动频率等因素对流失率有显著影响。通过构建预测模型,我们成功识别出高风险流失客户,为银行提供了有针对性的客户保留策略建议。本研究为银行客户流失管理提供了新的思路和方法,有助于提升银行的客户留存率和市场竞争力。在我们数据集中我们有十三列数据,分别为行号、客户ID、姓氏、地理位置、信用评分、年龄、入会时长、余额、产品数量、是否有信用卡、是否为活跃会员、预估薪资、是否流失。本分析的目标是开发一个模型,以预测客户可能中断服务的概率,并防止客户流失。
关键字:客户流失;信用积分;聚类分析;BP神经网络
一、引言
(一)数据展示
我们使用Python中的pandas库进行可视化我们的数据

结果:
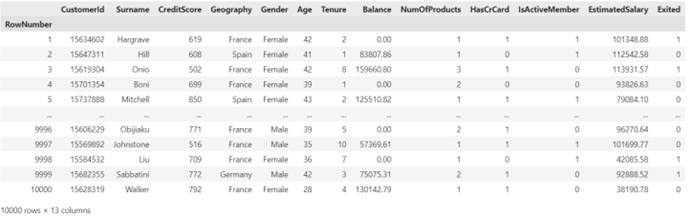
我们看到,我们的数据共十三列,他们分别是RowNumber(行号)、CustomerId(客户 ID)、Surname(姓氏)、CreditScore(信用评分)、Geography(所在地区)、Gender(性别)、Age(年龄)、Tenure(建立关系时长)、Balance(账户余额)、NumOfProducts(购买产品数量)、HasCrCard(是否有信用卡)、IsActiveMember(是否为活跃会员)、EstimatedSalary(预计薪水)、Exited(是否已退出)。
二、数据预处理
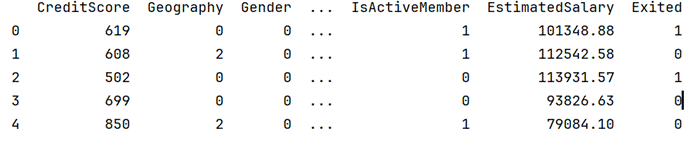
在分析数据后我们发现行号、客户ID、姓氏对于我们的数据分析分析不是必需的,所以我们需要删除这三列,以及对于年龄大于60岁的观测值和信用评分低于400的客户混淆数据也进行删除。最后我们对地理位置和性别这两列数据进行分类编码。由于产品数量是分类变量则不必再处理。
得到的结果如下图所示:
(一)查找缺失值
在将数据进行初步清洗后我们接下来该考虑分析数据是否存在缺失值,以确保数据具有完整的值以供分析。
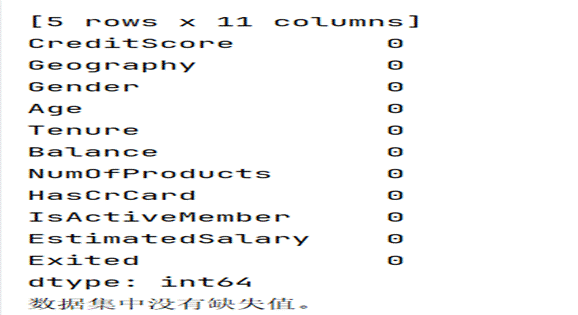
结果显示在给定的数据集中未发现缺失值。这确保了我们不需要为空单元格传递任何平均值或中位数。
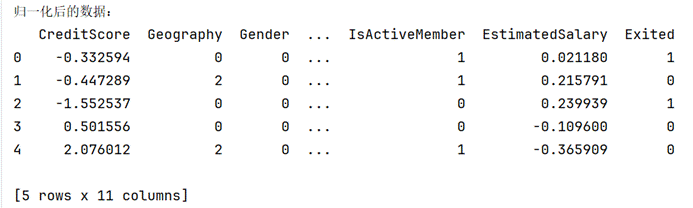
(二)数据归一化
主要在预处理中进行,它对数据的原始范围进行线性变换。
(三)数据分析
经检查,在银行拥有账户的客户数量为7614人,退出银行的客户数量为1903人。执行过采样过程以确保预测模型没有采样误差。我们将数据随机划分为80%的训练集和20%的测试集。分别是select-data.csv和scalar-test.csv。并使用StandardScaler函数对整个数据进行缩放。
三、数据可视化分析
(一)描述性可视化
我们先来分析客户基本信息和流失与否的关系
通过分析我们发现.
(1)客户的流失率高于其他两个国家客户约一倍.
(2)客户的流失率要高于男客户
(3)失客户的平均年龄约为45岁,而非流失客户的平均年龄约为36岁,可能年龄越大就容易流失。
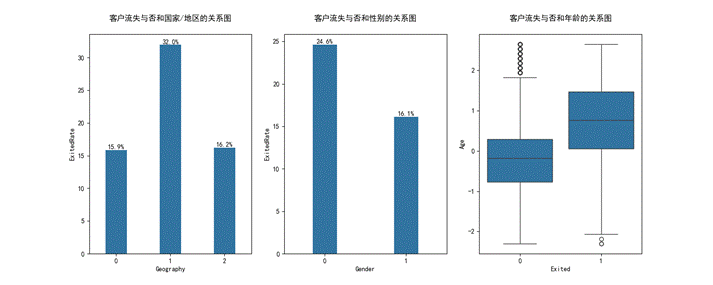
(图3.1 客户基本信息和流失与否关系图)
(二)客户的财务情况与流失与否的关系
1.流失客户的卡上余额高于非流失客户的
2.流失客户和非流失客户的预估工资差别不大,可能相关性不高。
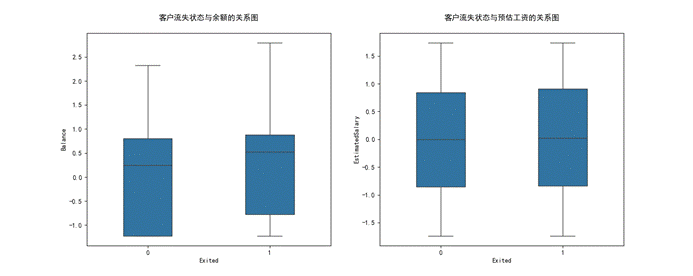
(图3.2 客户的财务情况与流失与否关系图)
(三)分析顾客的信用与关系流失与否的关系
1.流失客户和非流失客户的信用评分差不多,可能相关性不高。
2.拥有3-4个产品的客户流失率高,可能是银行产品的实际效用未达到客户的期望,导致客户感觉投资回报低。
3.不同合作年限的客户有不同程度的流失率,但差别不是很大,流失率最低为17.2%,最高为23.0%。
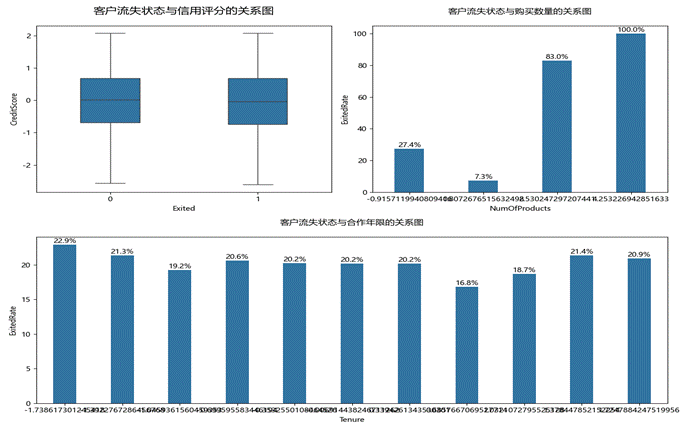
(图3.3 分析顾客的信用与关系流失与否关系图)
(四)分析客户的行为与偏好和流失与否的关系
1.是否拥有信用卡的客户的流失率比较接近
2.非活跃会员的客户流失率较大
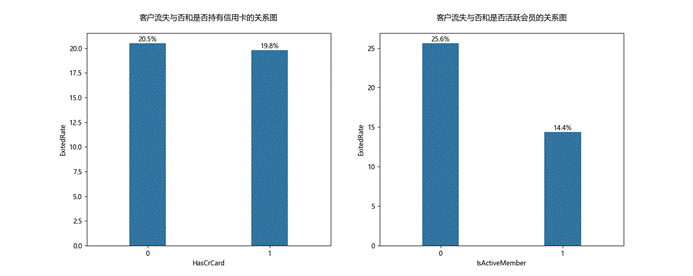
(图3.4 分析客户的行为与偏好和流失与否的关系)
(五)总结分析
数据中包含三个国家:法国、西班牙和德国。在这里,“已退出”表示客户已离开银行。法国在数据中的客户数量最多。尽管法国和德国的流失人数相同,但与另外两个国家的总客户数相比,德国的流失率最高。流失客户的比例与客户数量成反比,这间接表明银行在客户较少的地区可能存在问题。
男性客户数量多于女性。比较男性和女性客户的流失数据,女性客户比男性客户更容易流失。
目前拥有银行账户但一段时间没有进行任何交易的客户被视为不活跃,反之亦然。比较已退出和未退出的客户数量,不活跃的客户退出数量更多。比较未退出与活跃成员(蓝色条)时,我们可以看到超过40%的客户处于不活跃状态,这意味着他们很可能流失。
产品是指客户在银行拥有的服务数量。至少注册了2项服务的客户数量较多,且他们的流失率非常低。但只注册了一项服务的客户流失率很高。
我们可以看到人们退出银行时的年龄分布。大多数客户从40多岁开始流失。同时,我们可以看到30至40岁之间的客户数量最多。似乎年轻客户更倾向于留在公司,而老年客户则更容易流失。
四、回归分析
(一)回归分析的概念
回归分析是一种统计方法,用于研究一个或多个自变量(X)与一个因变量(Y)之间的依赖关系。它的主要目的是建立一个数学模型,该模型可以描述自变量对因变量的影响,并基于这些自变量预测因变量的值。在您的代码中,CreditScore、Age、Tenure、Balance、NumOfProducts、EstimatedSalary和IsActiveMember是自变量,而Exited是因变量。
回归分析有多种类型,包括线性回归、多项式回归、逻辑回归等。在您的代码中,使用的是线性回归模型,即假设自变量与因变量之间存在线性关系。
(二)回归分析的实现过程
数据准备:
使用Pandas库读取CSV文件中的数据。提取自变量X(多个特征)和因变量Y。
数据拆分:
使用train_test_split函数将数据集拆分为训练集和测试集。训练集用于训练模型,测试集用于评估模型性能。
模型训练:
创建一个线性回归模型实例。使用训练集中的数据训练模型。
模型预测:
使用训练好的模型对测试集中的自变量进行预测,得到预测的因变量值。
模型评估:
计算并输出均方误差(MSE)和决定系数(R2反映了模型对数据的拟合程度。
模型参数:
输出模型的截距和系数。这些参数是线性回归模型的关键组成部分,它们描述了自变量对因变量的影响程度。
代码及实现
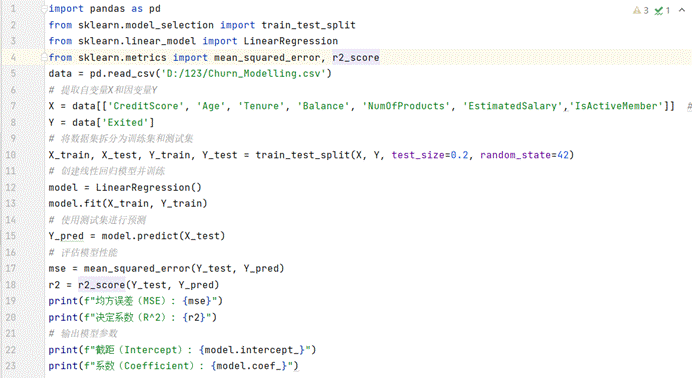
结果:

五、决策树模型
(一)模型简介
决策树是一种基于树结构的分类和回归模型。它由节点和边组成,节点分为内部节点和叶节点。内部节点表示对一个特征的测试,根据测试结果将数据划分到不同的子节点;叶节点表示最终的决策或预测结果。从根节点开始,根据数据的特征值沿着不同的分支向下传递,直到到达叶节点,从而得到预测类别或数值。
在客户流失预测的决策树中,根节点可能是根据客户的信用评分进行划分,如果信用评分大于某个阈值,则数据流向一个子节点,否则流向另一个子节点。在子节点上,可能继续根据其他特征(如年龄、地区等)进行进一步的划分,直到到达叶节点,叶节点可能标记为 “流失” 或 “未流失”。
1.具体算法选择
ID3算法:基于信息增益来选择最优特征进行划分。信息增益衡量了划分数据集前后信息熵的减少量。
C4.5算法:ID3算法的改进版,使用信息增益率(增益比)来选择最优特征,能够处理连续值和缺失值,并对树进行剪枝。
CART(分类与回归树)算法:使用基尼指数来选择最优特征进行划分,基尼指数衡量了数据的不纯度。CART算法既可以用于分类任务,也可以用于回归任务。
随机森林算法:基于多个决策树的集成学习方法,通过训练多个决策树并综合其预测结果来提高模型的准确性和稳定性。
梯度提升决策树(GBDT):通过构建多个弱分类器(通常是决策树),每次训练都针对前一轮分类器的错误进行修正,最终组合成一个强分类器。
我在这使用的是CART(Classification and Regression Trees)算法的一个变种,专门用于分类任务。CART算法本身可以基于基尼指数或信息增益(通过设置criterion参数为"entropy")来构建决策树。
参数设置:
criterion="gini":指定使用基尼指数作为分裂节点的标准。
max_depth=6:限制决策树的最大深度为6层。这有助于防止模型过拟合。
min_samples_split=100:指定一个节点必须包含至少100个样本才能被分裂。这同样有助于防止过拟合,因为它限制了树的生长。
模型训练:通过调用fit方法,您使用feature_train(特征训练集)和target_train(目标训练集)来训练决策树模型。
模型评估:使用score方法评估模型在feature_test(特征测试集)和target_test(目标测试集)上的准确度。
预测:通过调用predict方法,您可以使用训练好的模型对feature_test中的样本进行预测。
(二)决策树的构建过程
1、数据处理
由于原始数据集数据有非数值型比如地址等等,因此需要对这些特征数值化并将结果保存在一个新的文件中
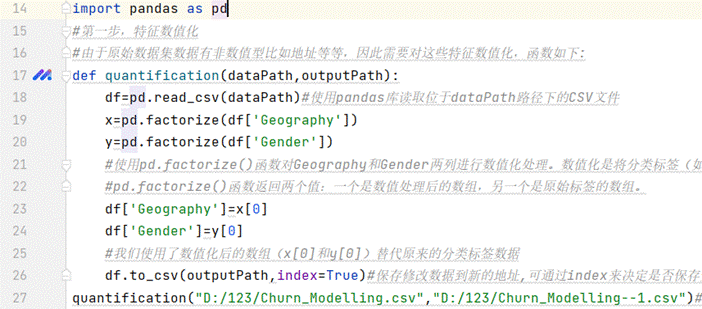
(图5.1 特征数值化)
决策树需要的是离散型数据,而原本的数据集中比如年龄,收入等是连续型数据,因此如果想要处理,需要转化为离散型数据。
具体如何离散化,每个特征列分为几等分根据实际情况判断,如下函数:
信用分数划分成四等份,根据计算设置为:584,652,718
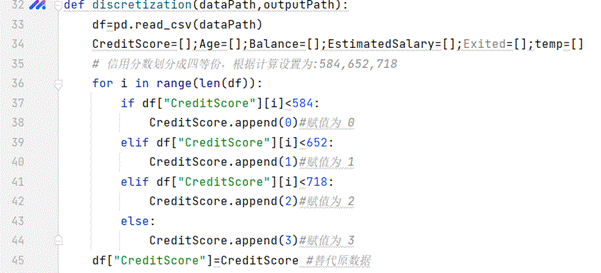
(图5.2 信用分数划分)
年龄,按照不同年龄段进行分类

(图5.3 年龄划分)
存款情况,存款为0的单独列出来

(图5.4 存款划分)
估计收入
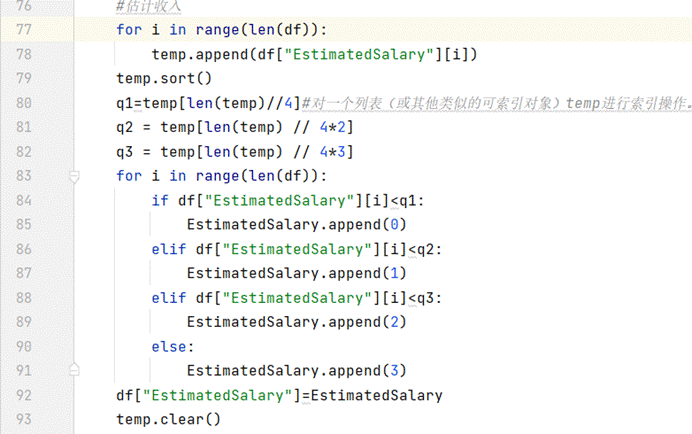
(图5.5 估计收入)
保存我们的新数据
![]()
(图5.6 存储数据)
2、数据筛选
删除无用的特征列,比如编号等等,并筛选数据用欠采样解决类别不均衡问题,它从原始数据集中选取一定数量的样本,使得在输出的数据集中
代码如下函数所示:
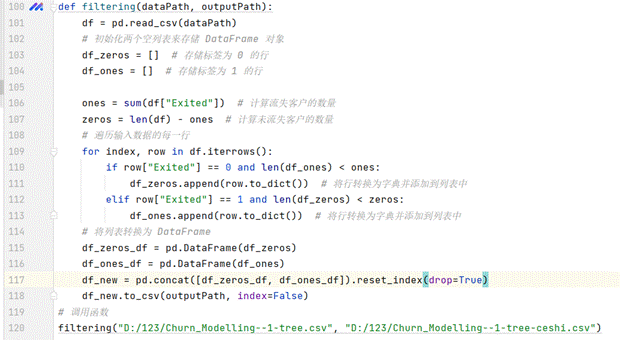
(图5.7 整理数据)
划分训练集及测试集

(图5.8 划分数据)
3、训练模型
我们开始数据建模并将我们的数据模型保存下来。

(图5.9 数据建模)
最后将我们生成的决策树的文本模型bank_trees.dot文件使用vctl命令转成图片格式
dot -Tpng D:/123/decision_trees/bank_tree.dot -o D:123/decision_tre
es/bank_tree.png
得到我们的决策树的图如下所示
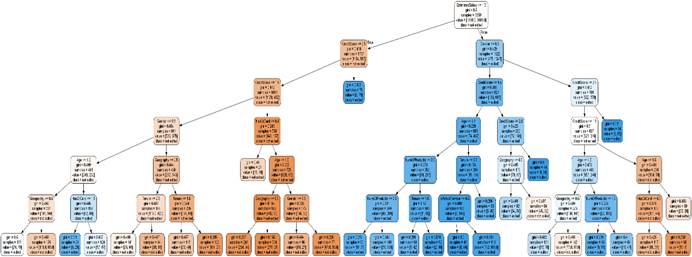
(图5.10 决策树模型)
4、ROC曲线
绘制ROC曲线 可用来评估模型分类性能,绘制的图片曲线下面积越大,代表准确度越高fpr, tpr, thresholds = roc_curve(target_test, predict_results, pos_label=1)使用roc_curve函数从sklearn.metrics库计算ROC曲线的各个点。target_test是真实的目标标签(通常是二进制的,例如0和1)。predict_results是模型预测的标签结果,pos_label=1指定正类标签的值为1。
函数返回三个值:
fpr:假正类率(False Positive Rate)tpr:真正类率(True Positive Rate)thresholds:用于计算上述率的阈值

(图5.11 roc曲线代码)
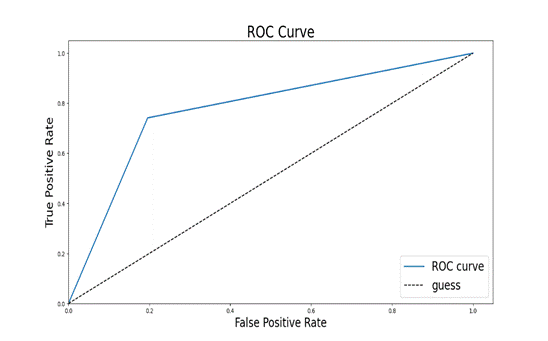
(图5.12 roc曲线图)
5、混淆矩阵
混淆矩阵上的4个数字,从左到右,从上到下依次是真正例,假正例,真反例,假反例的数量
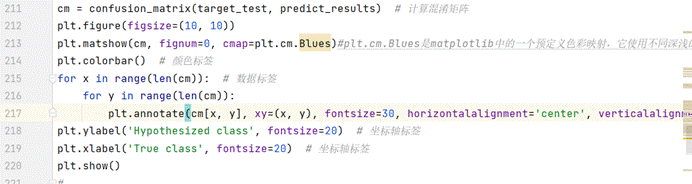
(图5.13 混淆矩阵代码)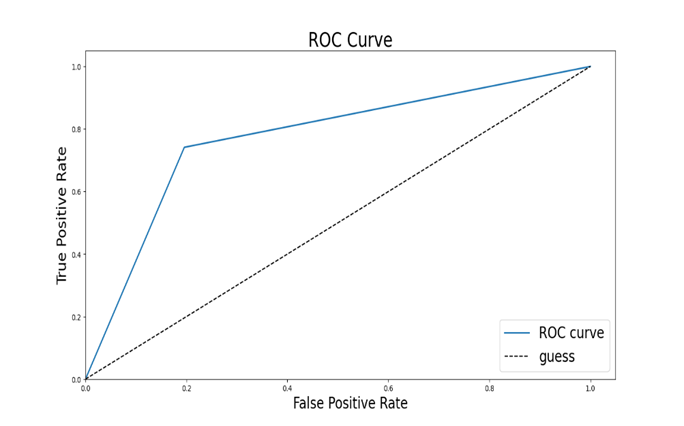
(图5.14 混淆矩阵图)
(三)决策树意义
整个流程涵盖了数据预处理、模型训练与评估以及决策树可视化三个主要部分。通过数据预处理将原始数据转换为适合模型训练的格式,然后训练决策树模型并评估其性能,最后可视化决策树以直观理解模型的决策逻辑,帮助分析哪些因素对客户流失的预测影响较大。在实际应用中,可根据具体需求进一步优化模型参数、特征选择等,以提高模型的准确性和可解释性。
六、贝叶斯
贝叶斯分类器是一种基于概率的分类方法,其核心原理是贝叶斯定理。该定理通过计算样本属于某类别的后验概率,选择概率最大的类别作为预测结果。在计算过程中,假设特征之间条件独立,这一假设简化了计算过程,使得贝叶斯分类器在处理大规模数据时具有较高的效率。
贝叶斯公式(Bayes' theorem)是概率论中的一个重要公式,用于描述在已知某些条件下某事件发生的概率(即条件概率),如何根据这些条件以及该事件和条件之间的关联来更新这个事件发生的概率。
(一)贝叶斯定理
贝叶斯公式的一般形式为:
P(A∣B)=[P(B)P(B∣A)⋅P(A)]/ P(B)
其中:
P(A∣B) 是在事件B发生的条件下,事件A发生的概率(条件概率)。
P(B∣A) 是在事件A发生的条件下,事件B发生的概率(条件概率)。
P(A) 是事件A发生的先验概率(即不考虑任何条件时,事件A发生的概率)。
P(B) 是事件B发生的先验概率(即不考虑任何条件时,事件B发生的概率)。
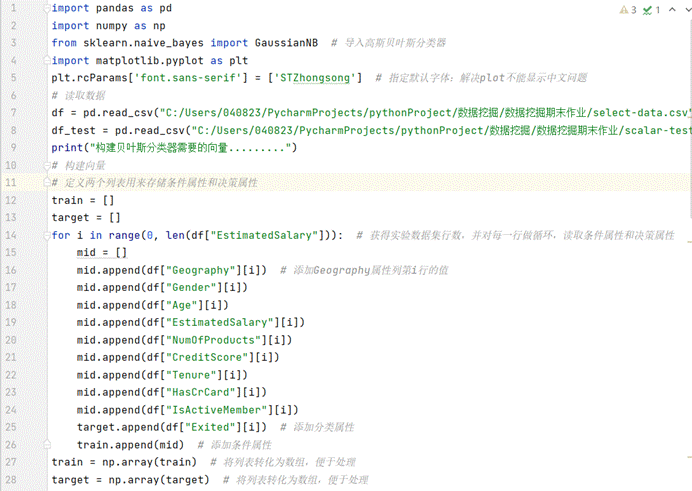
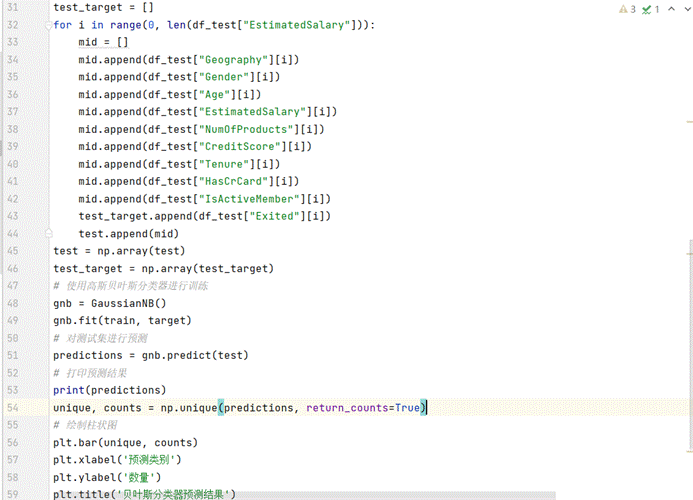
(图6.1 贝叶斯分类代码)
结果:
构建贝叶斯分类器需要的向量.........
[0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 1 0 0 0 0 0 1 0 0 0 1 0 1 0 1 1 1 0 0 0 1
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 1 0 0 1 0 0 0 1 1 0 0 1 0
…
0 1 0 1 0 1 0 0 0 0 0 0 1 0 1 0 0 0 0 0 0 1 0 0 0 0 1 1 0 0 0 1 0 1 1 0 1
0 0 0 0 1 1 0 0 1 1 0 1 1 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0 0 0 0 1 0 0 0
0 0 1 0 1 0 1 0 0 1 1 0 1 1 1 1 0 1 0 1 0 0 1 0 0 1 0 1 0 1 0 0 1 0 1 0 0
1 0 0 1 0 1 0 0 0 1 1 0 1 1 0 0 0 1 1 0 1 0 0 1 0 1 1 0 1 0 0 0 1 0 1 1 0]
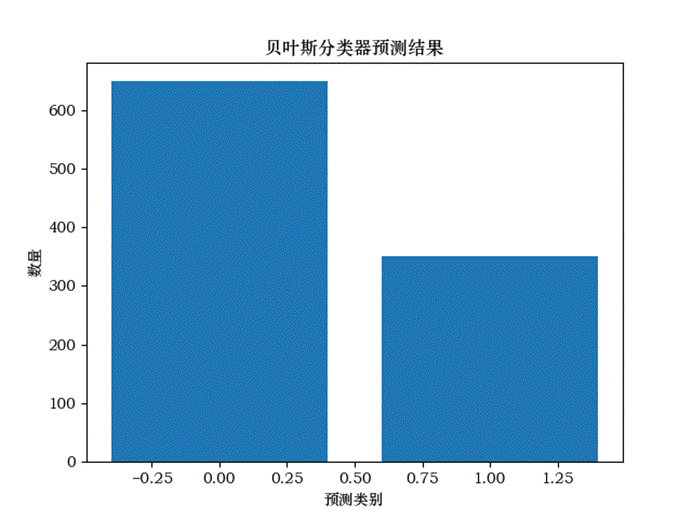
(图6.2 贝叶斯分类结果图)
七、BP神经网络
(一)神经网络模型概述
BP(Back Propagation)神经网络是一种多层前馈神经网络,其训练过程使用反向传播算法,按照误差逆向传播算法进行训练。以下是对BP神经网络的详细简述:
1、网络结构
BP神经网络通常由以下几层组成:
输入层:负责接收外部数据。每个神经元对应一个特征值,数据通过这些神经元进入网络。输入层没有计算功能,仅作为数据的传递通道。
隐藏层:BP神经网络的核心,负责从输入数据中提取特征并进行非线性变换。每个隐藏层由多个神经元组成,每个神经元对前一层的输出进行加权求和,并通过激活函数转换。激活函数的选择对网络性能有重要影响,常用的激活函数包括Sigmoid函数、Tanh函数和ReLU函数等。隐藏层的数量是任意的,尽管实践中通常只用一层,但增加隐藏层可以提高网络的非线性映射能力。
输出层:负责产生最终的预测结果。对于分类问题,输出层通常使用Softmax激活函数;对于回归问题,则不使用激活函数或使用线性激活函数。
2、算法原理
BP神经网络的算法原理主要包括前向传播和反向传播两个过程:
前向传播:信息从输入层经过隐藏层到输出层的过程。在这个过程中,输入数据通过权重矩阵与偏置向量进行线性组合,然后通过激活函数转换成非线性表达。输出层的输出即为网络的预测值。
反向传播:用于计算损失函数关于网络参数的梯度,并根据梯度更新网络的权重和偏置。这个过程从输出层开始,逆向通过网络的每一层,直到输入层。损失函数的梯度通过链式法则逐层计算。一旦得到了梯度,就可以使用梯度下降算法更新网络的权重和偏置,以减小损失函数值,提高网络的预测能力。
3、模型构建
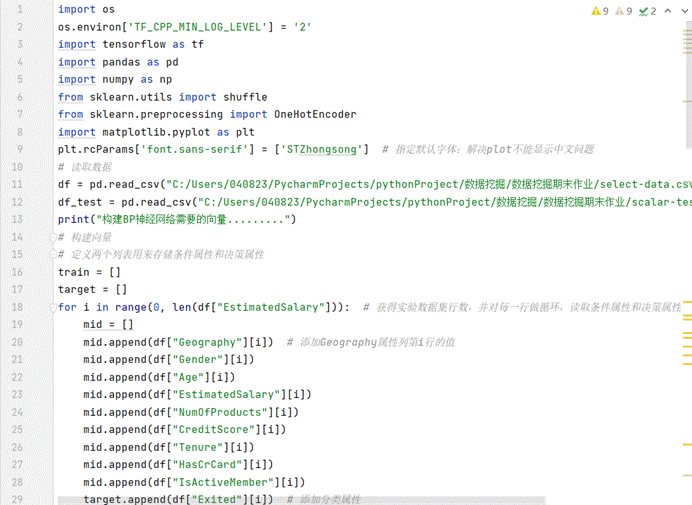
模型定义:
1.输入层:您定义了输入层的形状为(9,),这对应于您从数据集中提取的9个条件属性。
2.隐藏层:您定义了两个隐藏层,每层都有256个神经元,并使用sigmoid激活函数。此外,您还使用了Dropout层来减少过拟合。
3.输出层:您定义了一个输出层,有2个神经元(对应于两个类别),并使用softmax激活函数。
(二)模型编译与训练
编译模型:我选择了Adam优化器,并设置了学习率为1e-3。损失函数选择了categorical_crossentropy,这是多分类问题的常用损失函数。
(三)训练模型
使用fit函数训练模型,设置了1000个训练轮次(epochs)和32的批量大小(batch_size)。此外,还使用了验证数据集来监控模型在训练过程中的性能。


(图7.1 BP神经网络)
结果: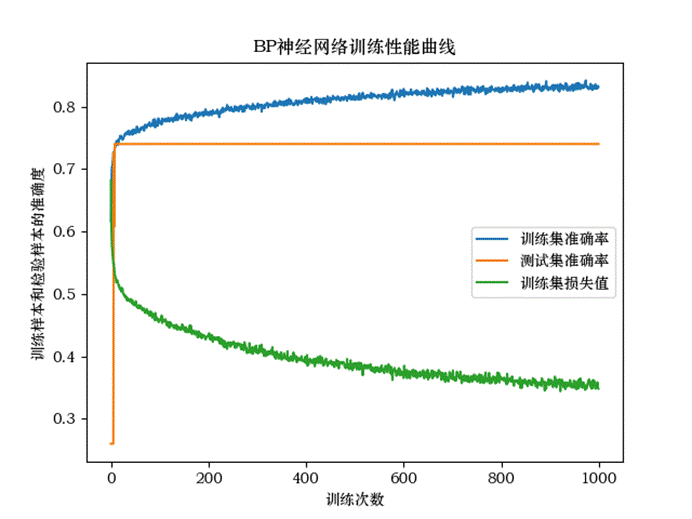
(图7.2 BP神经网络训练性能曲线)
经过一千次的迭代我们发现模型的准确率为:accuracy: 0.8304 loss为: 0.3459
八、聚类分析
聚类是一种无监督学习方法,用于将一组数据点划分为若干个有意义的子集,即聚类。聚类的主要目的是发现数据中的自然分组结构,使得同一聚类内的数据点具有较高的相似度,而不同聚类之间的数据点具有较高的差异度。
以下是聚类的一些基本概念:
数据点:聚类分析中的基本单位,通常表示为一个向量或一个对象。
相似度度量:用于衡量数据点之间的相似程度的方法,常用的相似度度量包括欧几里得距离、曼哈顿距离、余弦相似度等。
聚类中心:每个聚类的代表点,通常是聚类内数据点的均值或中心点。
聚类算法:用于将数据点分配到不同聚类的算法,常见的聚类算法包括 K 均值聚类、层次聚类、DBSCAN 等。
聚类评估指标:用于评估聚类结果的质量的指标,常用的评估指标包括轮廓系数、Calinski-Harabasz 指数、Davies-Bouldin 指数等。
这里我直接采用KMeans方法聚类,我们选择我们的初始数据中的七列。
实验与结果分析 :
代码:
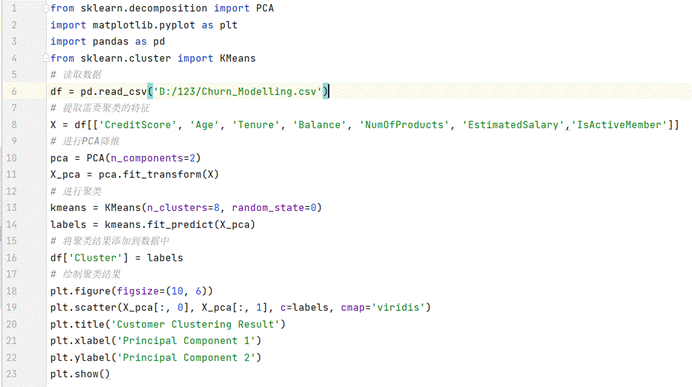
(图8.1 聚类分析代码图)
结果:
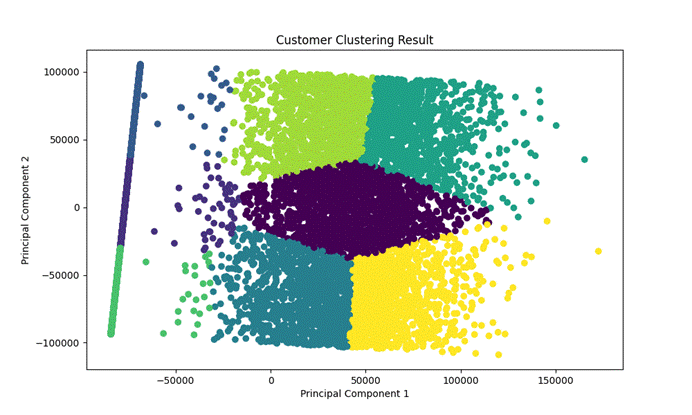
(图8.2 聚类结果图)
九、集成算法
Adaboost(Adaptive Boosting)和randomforst都是集成学习中的重要算法,用于提高分类或预测模型的准确性和鲁棒性。
(一)Adaboost算法
1、Adaboost算法简介
Adaboost 是一种迭代算法,其基本思想是通过训练一系列弱分类器(通常是决策树),并将它们组合成一个强分类器。在每一轮迭代中,Adaboost 会根据前一轮分类器的错误率调整样本的权重,使得被误分类的样本在下一轮中得到更多的关注。最终,通过加权投票的方式将所有弱分类器的结果组合起来,得到最终的分类结果。
2、Adaboost算法优劣
Adaboost 的优点包括:
对于噪声数据和异常值有较好的鲁棒性。
能够处理高维数据。
可以使用各种类型的弱分类器,如决策树、神经网络等。
然而,Adaboost 也存在一些缺点:
容易过拟合,特别是在训练数据较少或噪声较大的情况下。
训练时间较长,尤其是对于复杂的弱分类
代码及实现
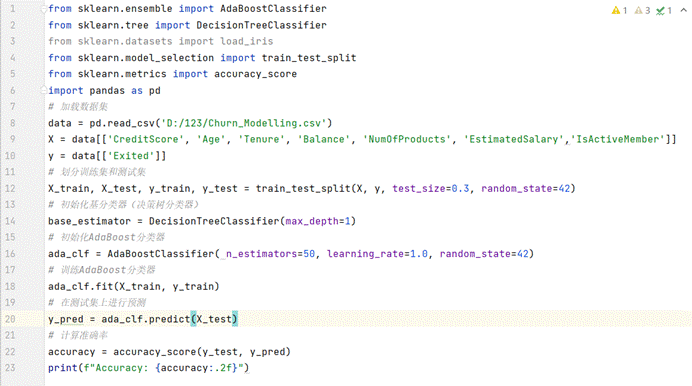
(图9.1 Adaboot算法实现)
结果:
准确率:Accuracy: 0.85
(二)Random Forest 算法
1、Random Forest算法简介
Random Forest(随机森林)是一种集成学习方法,它基于决策树算法构建多个决策树,并通过投票或平均的方式综合这些决策树的预测结果,以提高模型的准确性和鲁棒性。在随机森林中,每棵决策树都是在训练数据的一个随机子集上独立训练的,同时,在构建每棵决策树时,会随机选择一部分特征进行分裂,这有助于减少模型之间的相关性,提高整体的泛化能力。
2、Random Forest算法优劣
优点:
高精度:随机森林通过构建多个决策树并综合它们的预测结果,能够显著提高分类和回归任务的精度。
鲁棒性强:随机森林对噪声数据和异常值具有较强的鲁棒性,因为每个决策树都是在训练数据的一个随机子集上训练的,这有助于减少个别数据点对整体预测结果的影响。
能够处理高维数据:随机森林能够处理具有大量特征的数据集,因为它在构建每棵决策树时只选择一部分特征进行分裂,这有助于减少计算复杂度和避免过拟合。
易于理解和解释:虽然随机森林是一个复杂的集成模型,但每个决策树都是相对简单的,因此可以通过观察单个决策树的分裂过程来理解模型的决策逻辑。
并行处理能力强:由于每棵决策树都是独立训练的,因此随机森林算法可以很容易地实现并行处理,提高计算效率。
缺点:
模型复杂度较高:随机森林由多个决策树组成,因此模型的复杂度相对较高,需要更多的计算资源和存储空间。
对特征选择敏感:虽然随机森林在构建每棵决策树时只选择一部分特征进行分裂,但如果特征之间存在高度相关性或冗余性,可能会影响模型的性能。
训练时间较长:虽然随机森林可以并行处理,但当数据集非常大或决策树数量非常多时,训练时间仍然可能较长。
过拟合风险:虽然随机森林通过构建多个决策树并综合它们的预测结果来减少过拟合的风险,但如果决策树的数量过多或每棵决策树过于复杂,仍然可能陷入过拟合的困境。不过,与AdaBoost相比,随机森林通常具有更低的过拟合风险,因为它通过随机选择特征和样本子集来减少模型之间的相关性。
代码及实现:
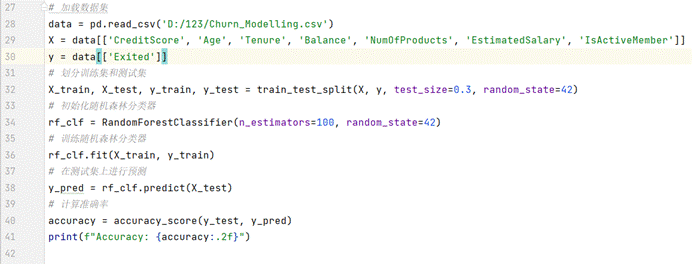
(图9.2 Random Forest 算法实现)
结果:
我们的准确率:Accuracy: 0.86
(三)总结
Adaboost算法通过迭代训练一系列弱分类器,并根据错误率调整样本权重,逐步构建一个强分类器。这种方法对于噪声数据和异常值具有良好的鲁棒性,同时能够处理高维数据,并且支持使用多种类型的弱分类器。然而,Adaboost也存在一些局限性,如容易在训练数据较少或噪声较大的情况下过拟合,以及训练时间较长的问题。尽管如此,通过合理的参数调整和弱分类器选择,Adaboost仍然能够在许多实际应用中取得优异的性能。
相比之下,Random Forest算法则通过构建多个决策树并综合它们的预测结果来提高模型的准确性和鲁棒性。随机森林中的每棵决策树都是独立训练的,且只使用部分特征和样本,这有助于减少模型之间的相关性,提高整体的泛化能力。随机森林不仅具有高精度和强鲁棒性,还能有效处理高维数据,并且易于理解和解释。然而,随机森林也存在模型复杂度较高、对特征选择敏感以及训练时间较长等缺点。尽管如此,由于其出色的性能和广泛的应用场景,随机森林仍然是许多数据科学家和机器学习工程师的首选算法之一。
在代码实现方面,我们通过具体的实验验证了Adaboost和Random Forest算法的性能。实验结果表明,这两种算法在各自的适用场景下都能取得令人满意的准确率。Adaboost在某些特定任务上可能表现出更高的精度,而Random Forest则通常具有更低的过拟合风险和更强的泛化能力。
综上所述,Adaboost和Random Forest作为集成学习中的两大重要算法,各自具有独特的优势和适用场景。在实际应用中,我们应根据具体任务和数据特点选择合适的算法,并通过合理的参数调整和模型优化来充分发挥其性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









