






 本文介绍了归并排序的基本思想、递归和非递归实现,以及计数排序的工作原理和应用场景,重点讨论了它们的时间复杂度和空间复杂度。
本文介绍了归并排序的基本思想、递归和非递归实现,以及计数排序的工作原理和应用场景,重点讨论了它们的时间复杂度和空间复杂度。
归并排序
你们知道高考每个省的一本、二本、专科分数线是如何划分出来的吗?简单地说,就是根据全省的成绩排名来的。所谓全省排名,就是每个市、每个县、每个学校、每个班级的排名合并后在排名得到的。注意我这里用到了合并一词。
我们两个学生的成绩高低是很容易的,比如甲比乙分数低,丙比丁分数低。那么我们也就很容易得到甲乙丙丁合并后的成绩排名,同样的,戊己庚辛的排名也很容易得到,由于他们两组已经分别有序了,把他们八个学生成绩合并有序,也是很容易可以做到的,继续下去……最终完成全省学生的成绩排名,此时的省高考状元也就诞生了。
基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
请结合图示理解:
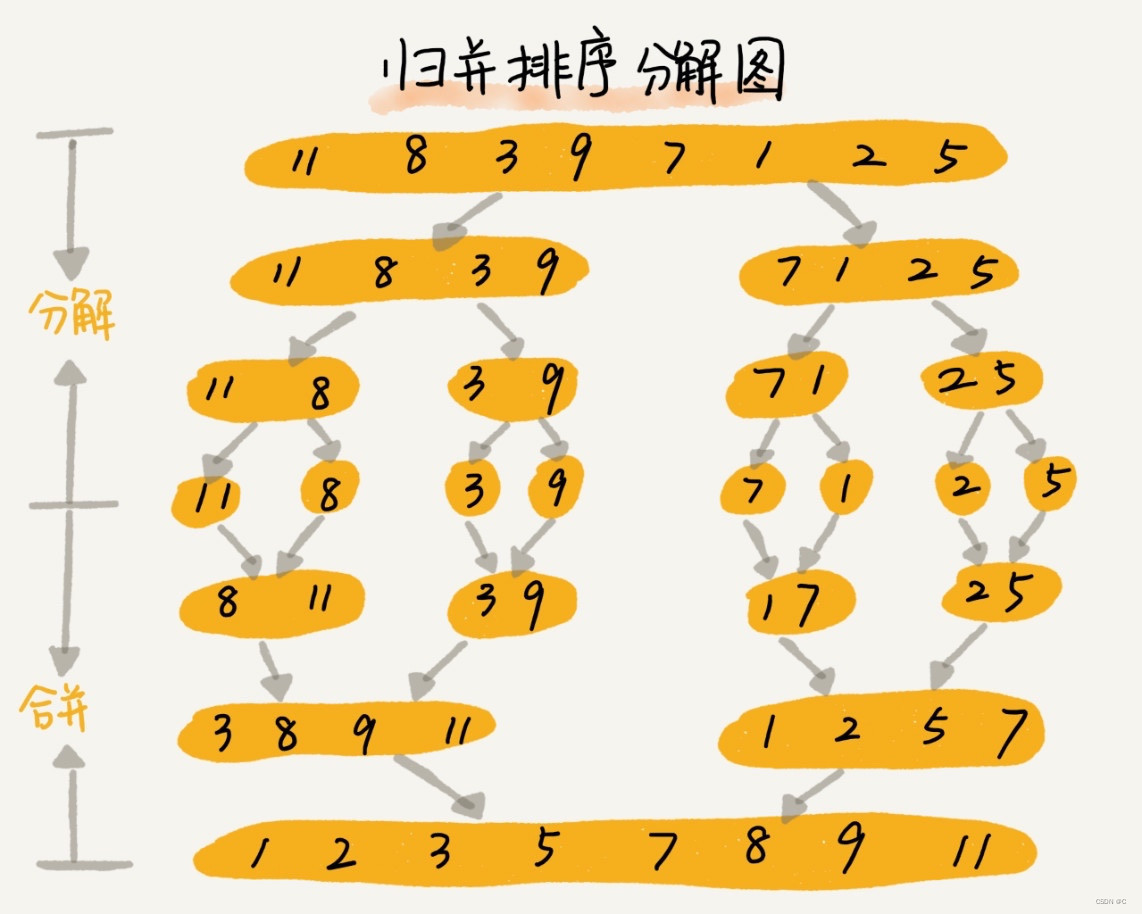
再来看一组动图
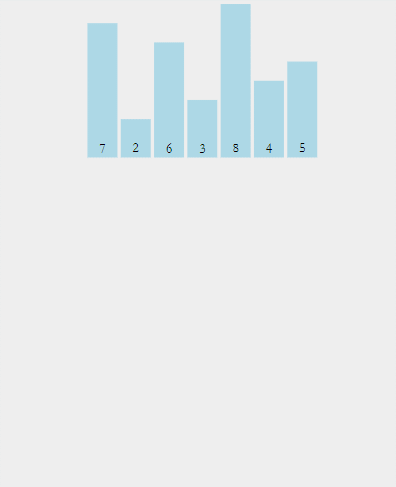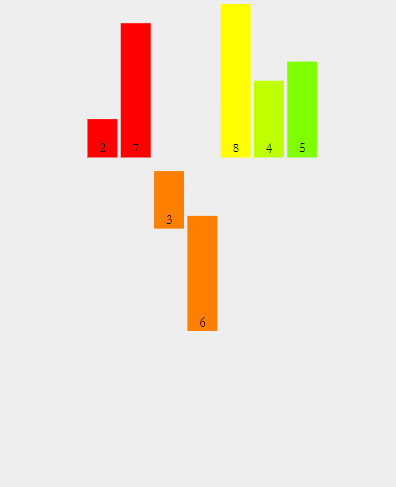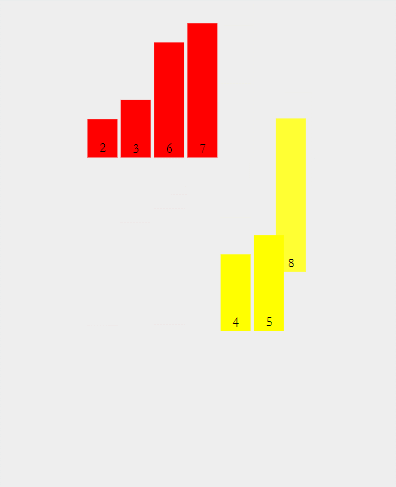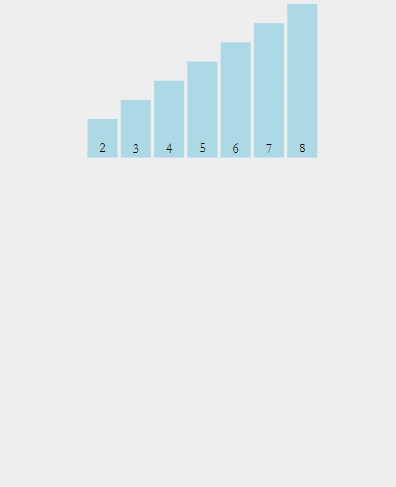
下面结合代码再来理解亿遍
代码演示
递归
void _MergeSort(int* arr, int left, int right, int* tmp)
{
//如果区间内只有一个数据,则说明数据有序,直接返回
if (left == right)
return;
int mid = (left + right) / 2;
//分治递归
//[left,mid] [mid + 1,right]
_MergeSort(arr, left, mid, tmp);
_MergeSort(arr, mid + 1, right, tmp);
//归并
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = begin1;
//比较两个区间的大小,小元素尾插到tmp
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
tmp[i++] = arr[begin1++];
else
tmp[i++] = arr[begin2++];
}
//如果begin1 <= end1,直接把区间里的剩余元素全部拷贝到tmp
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
//如果begin2 <= end2,直接把区间里的剩余元素全部拷贝到tmp
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//把tmp数组的内容拷贝到arr数组
for (int j = left; j <= right; j++)
{
arr[j] = tmp[j];
}
}
void MergeSort(int* arr, int sz)
{
int* tmp = (int*)malloc(sizeof(int) * sz);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
//调用子函数
_MergeSort(arr, 0, sz - 1, tmp);
free(tmp);
tmp = NULL;
}参考代码已奉上,希望大家能够理解
非递归
我们常说,“没有最好,只有更好”。递归排序大量引用了递归,尽管代码上比较清晰,容易理解 ,但这会造成空间上的损耗。那我们能不能叫递归转化成迭代呢?结论肯定是可以的。来看代码。
void MergeSortNonR(int* arr, int sz)
{
int* tmp = (int*)malloc(sizeof(int) * sz);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
//gap为归并每组的数据个数
int gap = 1;
while (gap < sz)
{
//这里的j每次加上一对区间的大小
for (int j = 0; j < sz; j += 2 * gap)
{
//区间1
int begin1 = j, end1 = begin1 + gap - 1;
//区间2
int begin2 = end1 + 1, end2 = begin2 + gap - 1;
int i = j;
//非递归要特别注意这里,修正每个区间的值,避免越界的情况
//上面已经说明begin1是小于sz的,所以begin1无需修正
//如果end1大于等于sz或者begin2大于等于sz,就不需要继续归并,
//因为那时区间里的数据已经有序,所以直接跳出本次循环就可以
//但是如果end2大于等于sz,就需要修正end2的值,继续归并
if (end1 >= sz || begin2 >= sz)
break;
if (end2 >= sz)
end2 = sz - 1;
//比较大小,小的尾插tmp
while (begin1 <= end1 && begin2 <= end2)
{
if (arr[begin1] < arr[begin2])
tmp[i++] = arr[begin1++];
else
tmp[i++] = arr[begin2++];
}
while (begin1 <= end1)
{
tmp[i++] = arr[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = arr[begin2++];
}
//每归并完一组,就拷贝一次
for (int y = j; y <= end2; y++)
arr[y] = tmp[y];
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}参考代码已经奉上,上面代码的注释特别详细,希望大家能够理解。
复杂度分析
一趟归并排序需要将相邻的两个区间进行归并,并且要将tmp数组的元素拷贝到arr数组中,这需要将待排序序列中的所有记录扫描一遍,要耗费O(N)时间,而由完全二叉树的深度可知,整个归并排序需要进行logN次,因此,总的时间复杂度为O(N * logN),而且这是归并排序算法中最好、最坏、平均的时间性能。
另外,由于递归需要额外开辟栈空间,所以空间复杂度为O(N)。并且归并排序是一种稳定的排序算法。
计数排序
基本思想
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用
请看实现过程:
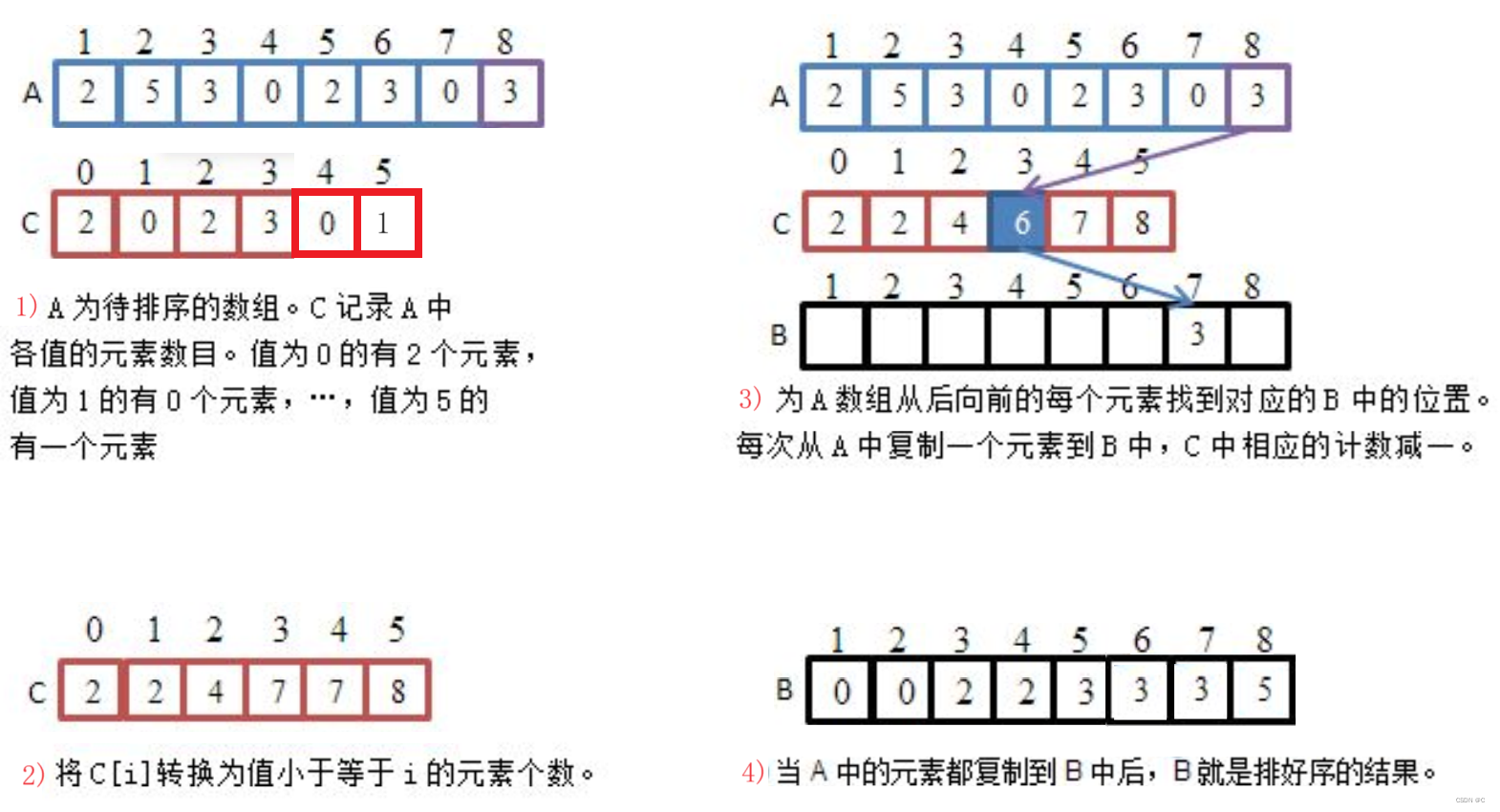
实现过程:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
代码演示
void CountSort(int* arr, int sz)
{
int min = arr[0], max = arr[0];
//选出最大值和最小值
for (int i = 0; i < sz; i++)
{
if (min > arr[i])
min = arr[i];
if (max < arr[i])
max = arr[i];
}
//求出数值范围
int range = max - min + 1;
int* count = (int*)malloc(sizeof(int) * range);
if (count == NULL)
{
perror("malloc fail");
return;
}
//将count数组的内容全部初始化为0
memset(count, 0, sizeof(int) * range);
//遍历arr数组,统计数据出现的次数
for (int i = 0; i < sz; i++)
{
//相对映射,减去最小值
count[arr[i] - min]++;
}
//排序
int j = 0;
for (int i = 0; i < range; i++)
{
//count[i]不为空就继续
while (count[i])
{
//把上面减去的最小值加上,赋值给arr数组
arr[j++] = i + min;
count[i]--;
}
}
}参考代码已奉上,希望大家能够理解
总结
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。只能排序整数
- 时间复杂度:O(MAX(N,range))
- 空间复杂度:O(range)
- 稳定性:稳定



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











