






一、实验目的
1.掌握关系数据在大数据中的应用
2.掌握关系数据可视化方法
3. python 程序实现图表
二、实验原理
在传统的观念里面,一般都是致力于寻找一切事情发生的背后的原因。现在要做的是尝试着探索事物的相关关系,而不再关注难以捉摸的因果关系。这种相关性往往不能告诉读者事物为何产生,但是会给读者一个事物正在发生的提醒。关系数据很容易通过数据进行验证的,也可以通过图表呈现,然后引导读者进行更加深入的研究和探讨。分析数据的时候,可以从整体进行观察,或者关注下数据的分布。数据间是否存在重叠是否毫不相干?也可以更宽的角度观察各个分布数据的相关关系。其实最重要的一点,就是数据进行可视化后,呈现眼前的图表,它的意义何在。是否给出读者想要的信息还是结果让读者大吃一惊?
就关系数据中的关联性,分布性。进行可视化,有散点图,直方图,密度分布曲线,气泡图,散点矩阵图等等。本次试验主要是直方图,密度图,散点图。直方图是反应数据的密集程度,是数据分布范围的描述,与茎叶图类似,但是不会具体到某一个值,是一个整体分布的描述。密度图可以了解到数据分布的密度情况。密度图可以了解到数据分布的密度情况。散点图将序列显示为一组点。值由点在图表中的位置表示。散点图
通常用于比较跨类别的聚合数据。
三、实验环境
OS:win11
python:v3.11
四、实验步骤
1.安装seaborn库
Seaborn 是一个基于 Matplotlib 的高级数据可视化库,专门用于创建统计图形。它提供了简洁的 API 和美观的默认样式,能够轻松生成复杂的统计图表。Seaborn 的主要功能包括:
1.高级统计图表接口:内置聚合、分布拟合、误差线计算等功能,无需手动处理数据。
2.美观的默认主题:提供多种内置主题,如 darkgrid、whitegrid 等,一键切换。
3.多变量关系可视化:支持矩阵图、分面网格等复杂关系展示。
4.分类数据可视化:直接处理分类变量,自动对齐坐标轴标签。
5.颜色调色板管理:内置专业调色板,支持连续/离散数据配色。
Seaborn 的绘图函数操作于 Pandas 数据框和 Numpy 数组,能够自动执行语义映射和统计聚合,生成信息丰富的绘图。它特别适合快速探索数据分布和关系,而 Matplotlib 更适合需要像素级控制的复杂可视化任务。
安装指令如下:
pip install seaborn
2.使用seaborn绘制图形
我们使用seaborn模块中的jointplot方法将散点图,密度分布图和直方图合为一体,数据选取murder列及burglary列,探究两种犯罪类型的相关关系。
实现代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 读取数据
df = pd.read_csv('crimeRatesByState2005.csv')
# 只选取'murder'和'burglary'两列,确保是数值型
data = df[['murder', 'burglary']].apply(pd.to_numeric, errors='coerce')
data = data.dropna()
# 创建 jointplot 图,带回归线
sns.jointplot(
data=data,
x='murder',
y='burglary',
kind='reg', # 加回归线
color='green', # 设置为绿色
marginal_kws=dict(bins=20, fill=True) # 边缘直方图参数
)
# 显示图形
plt.show()
绘制的结果如图所示:
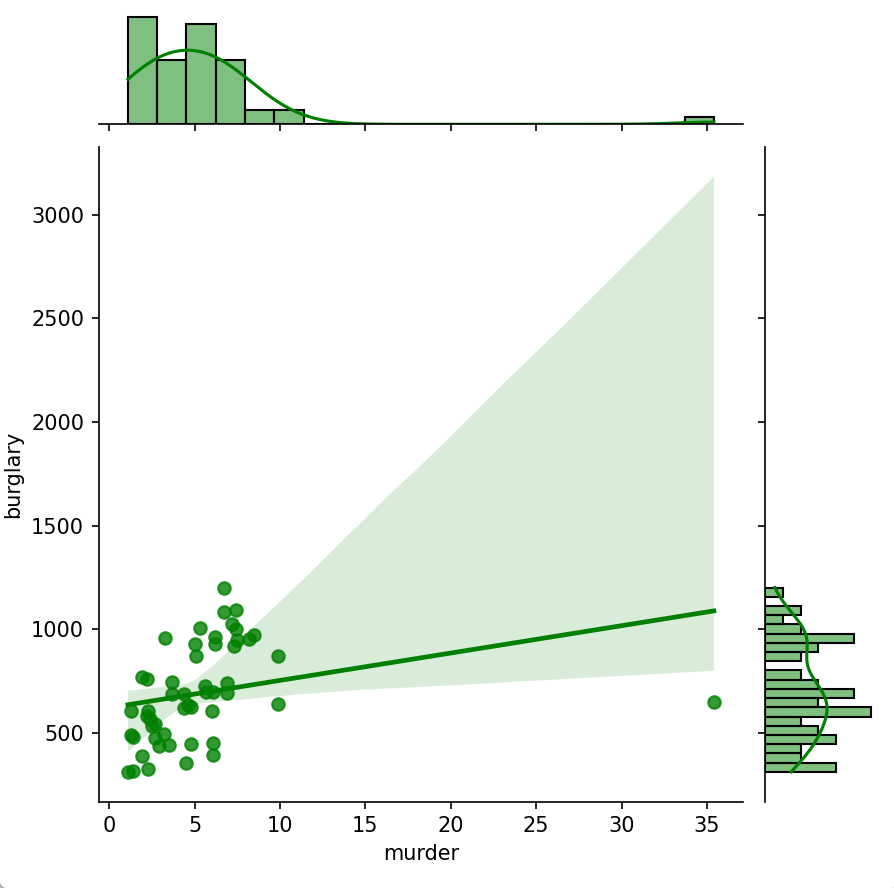
结果分析:
根据绘制的散点图与回归线分析结果,可以看出谋杀率(murder)与入室盗窃率(burglary)之间存在一定的正相关关系,即谋杀率较高的地区,通常入室盗窃率也相对较高。然而,从散点分布较为分散、回归线较为平缓的情况来看,两者之间的相关性较弱,推测皮尔逊相关系数可能在0.2到0.4之间。因此,虽然谋杀率和入室盗窃率之间存在一定联系,但并不足以单独通过谋杀率准确预测入室盗窃率,两种犯罪类型的关联性受多种社会因素共同影响。
3.绘制动态散点图
实现代码如下:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Scatter, Timeline
# 读取数据
df = pd.read_csv('crimeRatesByState2005.csv')
# 选取 'murder' 和 'burglary' 列,清洗数据
data = df[['murder', 'burglary']].apply(pd.to_numeric, errors='coerce')
data = data.dropna()
# 创建一个 Timeline 实例
timeline = Timeline()
# 动态添加数据到 Timeline
for frame in range(1, len(data) + 1):
current_data = data.iloc[:frame]
# 构建散点图
scatter = (
Scatter()
.add_xaxis(current_data['murder'].tolist())
.add_yaxis("Burglary", current_data['burglary'].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title="Dynamic Scatter Plot of Murder vs Burglary"),
xaxis_opts=opts.AxisOpts(name="Murder Rate"),
yaxis_opts=opts.AxisOpts(name="Burglary Rate"),
tooltip_opts=opts.TooltipOpts(trigger="item")
)
)
# 将该帧添加到时间轴
timeline.add(scatter, f"Frame {frame}")
# 渲染图表到 HTML 文件
timeline.render("dynamic_scatter_plot.html")
绘制结果如图:
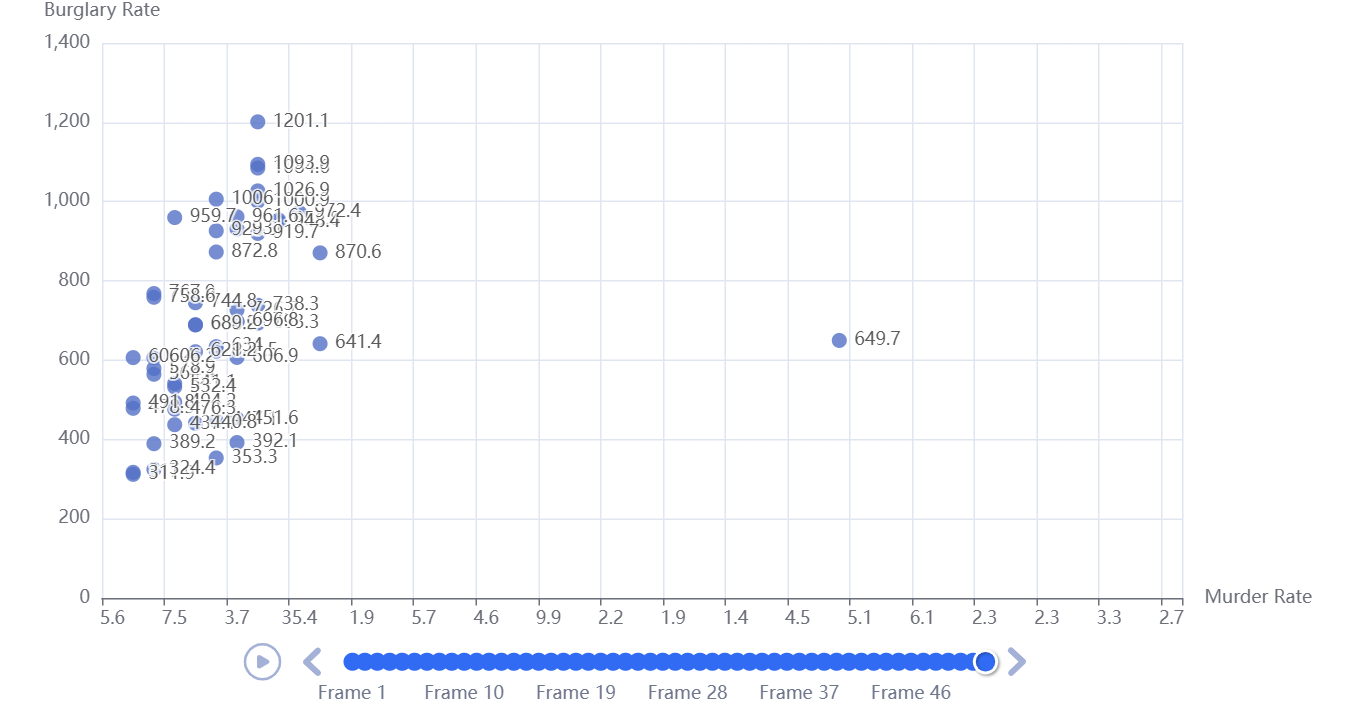
4.绘制矩阵图
我们使用矩阵图表示数据集中七种犯罪类型之间的相关关系,并剔除UnitedStates和DistrictofColumbia两行表示均值和异常的数据。
实现代码如下:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 加载CSV数据文件
crime_data = pd.read_csv('crimeRatesByState2005.csv')
# 剔除United States和District of Columbia两行
crime_data_filtered = crime_data[(crime_data['state'] != 'United States') & (crime_data['state'] != 'District of Columbia')]
# 选择包含犯罪类型的列
crime_columns = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
# 提取相关的犯罪数据
crime_data_selected = crime_data_filtered[crime_columns]
# 创建散点图矩阵
sns.pairplot(crime_data_selected)
# 设置标题
plt.suptitle('七种犯罪类型之间的关系', y=1.02)
# 显示图表
plt.show()
结果如图所示:
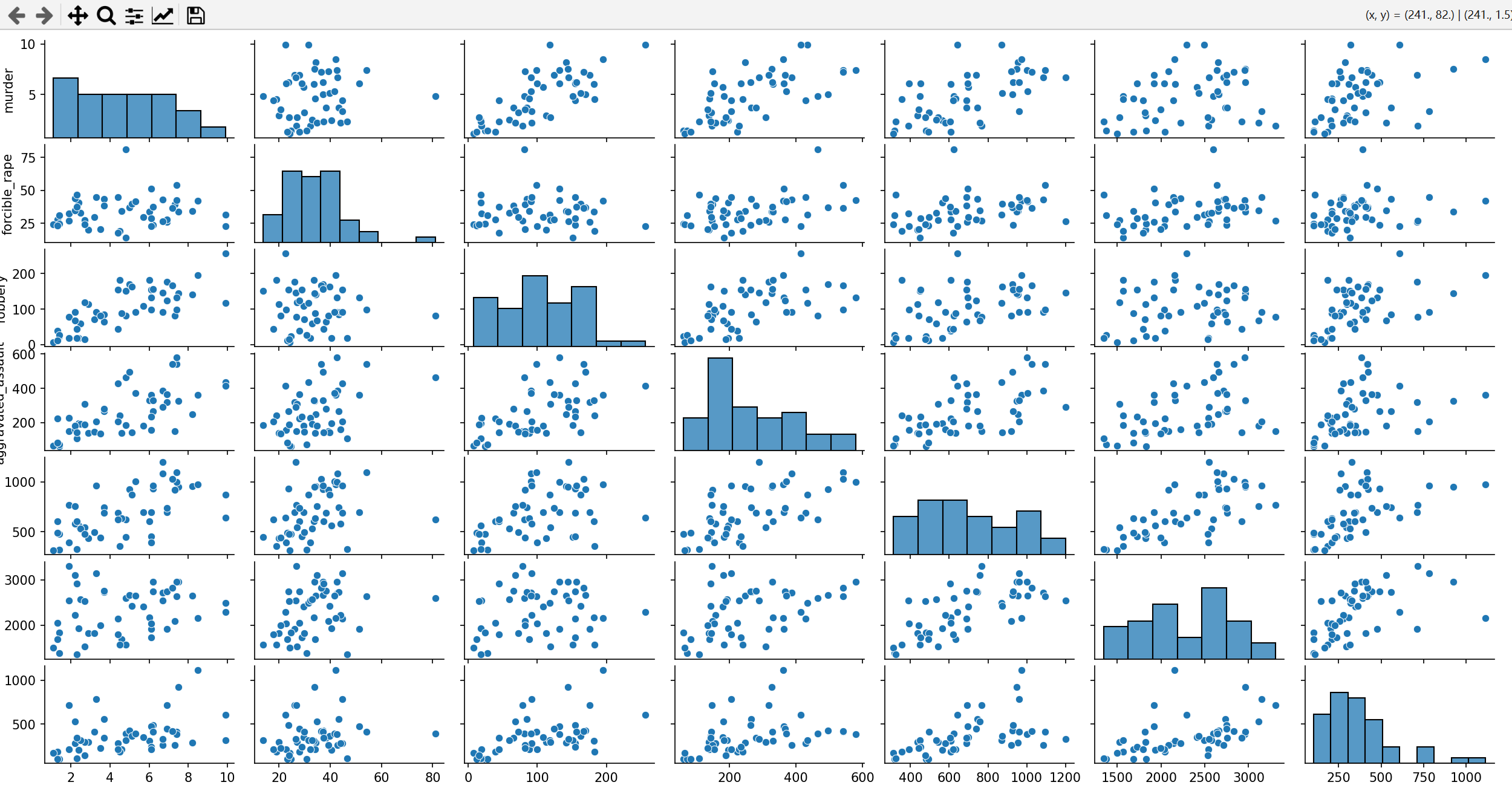
5.热力图加密度分布图
实现代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
# 加载CSV数据文件
crime_data = pd.read_csv('crimeRatesByState2005.csv')
# 剔除United States和District of Columbia两行
crime_data_filtered = crime_data[(crime_data['state'] != 'United States') & (crime_data['state'] != 'District of Columbia')]
# 选择犯罪类型列
crime_columns = ['murder', 'forcible_rape', 'robbery', 'aggravated_assault', 'burglary', 'larceny_theft', 'motor_vehicle_theft']
# 提取相关的犯罪数据
crime_data_selected = crime_data_filtered[crime_columns]
# 使用jointplot绘制变量间的密度和散点图
sns.jointplot(x='murder', y='burglary', data=crime_data_selected, kind='hex')
# 设置标题
plt.suptitle('谋杀与入室盗窃之间的关系(密度图)', y=1.02)
# 显示图表
plt.show()
运行结果如图:

五、实验心得
通过本次实验,我深入理解了关系数据在大数据中的应用,关系数据能够清晰地表示实体之间的关联,为数据挖掘和分析提供了有力支持,在处理复杂数据关系时优势明显。同时,我掌握了多种关系数据可视化方法,如使用节点和边的图结构直观展示数据关系,借助不同颜色、大小和形状增强可视化效果,这些方法帮助我更高效地从大量数据中提取有价值信息。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









