






以上是我们需要处理的数据,这个数据是和物流运输有关的。
数据来源于随机生成,不具有参考性。
目录:
目录
---数据介绍及需求:
有多个客户id对不同的类别进行了交互,要求我们:
1.对数据进行清洗,使其的数据类型和其他条件可以用来进行编程分析。
2.对时间维度进行分析。
3.对空间维度进行分析
4.对自身维度(自身投诉率)进行分析
5.对消费潜力维度进行分析
6.检查商品是否存在质量问题
--代码后端实现
-数据清洗
import pandas as pd
import matplotlib.pyplot as plt
#01.进行数据清洗(去除重复值,空值,格式调整,以及处理异常值)
data=pd.read_excel(r"E:\python练习库\xlsx\物流管理数据练习.xlsx",sheet_name='Sheet1')
#提前设置数据可视化的字体
plt.rcParams['font.sans-serif']='SimHei'
#按行删除缺失值和重复数据(0行1列)
data=data.dropna(axis=0,how='any')
data.drop_duplicates(keep='first',inplace=True)
#删除无关列(订单行再这里用不到)
data.drop(columns='订单行',inplace=True,axis=1)
#更新索引(这里drop=True表示将原来的索引全部删除,然后在重新排序。)重置索引的作用在于将原来的索引列(通常是整数序列)转换为数据框的普通列,并重新生成默认的整数索引。
data.reset_index(drop=True,inplace=True)
#销售金额格式不对,将格式转换修改(将单位统一:万元改为元[int flot形式都可以];有些金额的小数点错打为逗号:将,改为小数点.)
#取出金额该列,对每个数据进行清洗(map函数)
#编写自定义函数,删除逗号,转化为float形式,删除元/万元,如果是万元,将原数值*10000
def data_deal(number):
if number.find('万元')!=-1: #找到带有万元的数据,取出数字,去掉逗号,转换为float,*10000
#利用find函数和切片的特性(切片配合find函数查找索引可以很好的实现单位删除)
number_new=float(number[:number.find('万元')].replace(',','.'))*10000
else: #找到带元的数据,删除元,删除逗号,转换为float形式
number_new=float(number[:number.find('元')].replace(',','.'))
return number_new
data['金额']=data['金额'].map(data_deal)#将自定义更改应用到源数据
#数据异常清洗——异常值处理和偏态分布(有时候源数据会出现:销售金额=0的情况,数量和销售金额的标准差都在均值以上的8倍)
#print(data.describe())通过data.describe()函数来寻找异常情况,它会显示四分位数来帮助你判断数据是左偏还是右偏。
#销售金额为0的情况(未输入数据),用删除方法 前提:数据量相对较小
data=data[data['金额']!=0]#通过切片套布尔值的方法清洗数据
#数据规整——增加辅助列:月份
#主要是想以月份为单位衡量服务的满意度,是否存在潜力区域,商品自身问题
#从销售时间取出月份并新建列,为后续度量做准备
data['销售时间']=pd.to_datetime(data['销售时间'])#通过to_datetime函数将源数据转化为时间格式
data['月份']=data['销售时间'].apply(lambda x:x.month) #用lambda函数对每个销售时间的数据取月份时间数据,并赋予在新建“月份”列上我们可以看到,再该项目中,主要进行的操作是在有空值的数据量较小的情况下,对缺失值按行进行删除,然后对特殊列进行正规模式的更改。最后通过删除有空值的数据解决统计偏态的问题。
在我们进行数据清洗的过程中,可以提前把辅助列添加到大数据集中,以便于后面操作。
-货物配送服务分析
(1)时间维度:
#(1)时间维度
data['货品交货状态'] = data['商品交货状态'].astype(str).str.strip()#str.strip()函数去除字符串两端的空格,规整数据
#按照月份和交货状况分组,储存在data1中,并用size()函数进行频数统计,来查看每个月份的交货情况。data1可以更方便的进行时间维度的数据分析
data1=data.groupby(['月份','货品交货状态']).size().unstack()
#unstack()函数规整显示的数据形式(不是压缩的形式),用数据框的形式显示。在多重分组的情况要用unstack()函数来将原表格转换为数据框,才可以进行数据可视化
#进行按时交货率的计算:按时交货数量/总交货数量,存储到data1的新建列中
data1['按时交货率']=data1['按时交货']/(data1['按时交货']+data1['晚交货'])
#之后可以根据data1中的按时交货率来分析时间维度对交货率的影响
def sj(data1):
data1.plot(kind='bar', fontsize=13)
plt.title('时间维度订单分析', fontsize=20)
plt.xlabel('月份', fontsize=16)
plt.ylabel('订单交货率', fontsize=16)
plt.xticks(rotation=180,color='b')
plt.show()
print(sj(data1))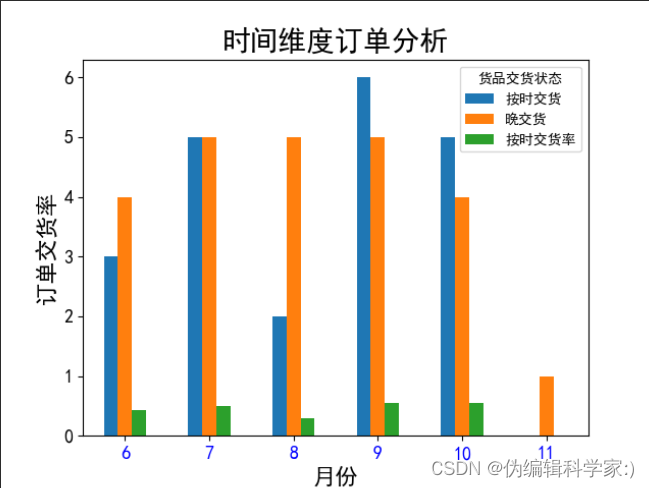
可见8月份的按时交货率最低,而11月份都是晚交货。物流管理公司可以根据该数据在这两个月执行对策。
(2)空间维度:
#(2)空间维度:判断在不同地域的交货情况,可以判断哪个地区延迟收货最严重
#这里分组我们直接将月份改为销售区域即可,这也就是这个案例简单的原因。
data2=data.groupby(['销售区域','货品交货状态']).size().unstack()
data2['商品交货率']=data2['按时交货']/(data2['按时交货']+data2['晚交货'])
data2=data2.sort_values(by='商品交货率',ascending=False)#根据商品交货率进行排序
def dy(data2):
data2.plot(kind='bar', fontsize=13)
plt.title('地域维度订单分析', fontsize=20)
plt.xlabel('销售区域', fontsize=16)
plt.ylabel('订单交货率', fontsize=16)
plt.xticks(rotation=0,color='b')
plt.show()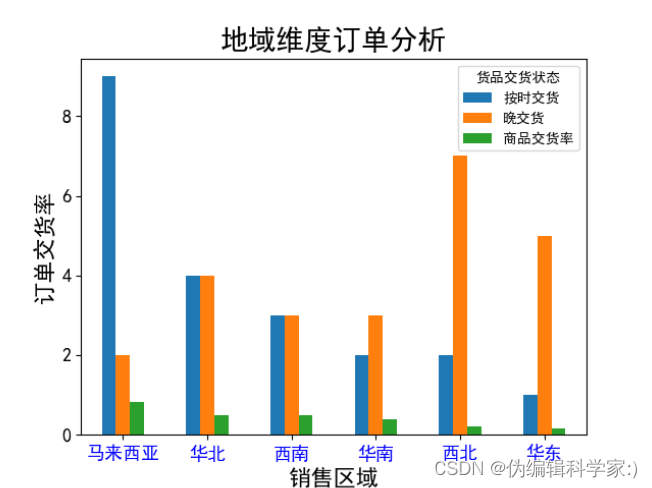
,可见在马来西亚的交货率最高,而在其他地方晚交货率都出奇的高,尤其是西北和华东。
(3)货品维度:
#(3)货品维度:可以判断哪个货品存在交收货问题
data3=data.groupby(['商品','货品交货状态']).size().unstack()
data3['商品交货率']=data3['按时交货']/(data3['按时交货']+data3['晚交货'])
data3=data3.sort_values(by='商品交货率',ascending=False)
def hp(data3):
data3.plot(kind='bar', fontsize=13)
plt.title('货品维度订单分析', fontsize=20)
plt.xlabel('用户反映', fontsize=16)
plt.ylabel('订单交货率', fontsize=16)
plt.xticks(rotation=0,color='b')
plt.show()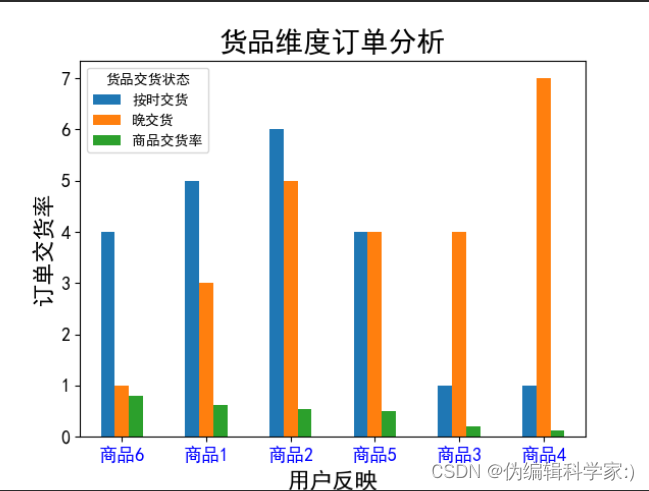
可见商品4和商品3出现了严重的问题。
(4)货品和销售区域结合分析:
#(4)货品和销售区域结合
data4=data.groupby(['商品','销售区域','货品交货状态']).size().unstack()
data4['商品交货率']=data4['按时交货']/(data4['按时交货']+data4['晚交货'])
data4=data4.sort_values(by='商品交货率',ascending=False)[:10]#数据太多,这里我只取前十
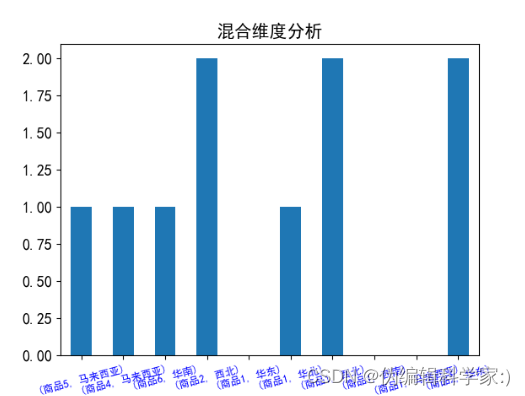
def hh(data4):
a=input()#输入晚交货或按时交货,即货品交货状态,查询商品在不同地域时间的交货情况
data4[a].plot(kind='bar', fontsize=13)
plt.title('混合维度分析', fontsize=15)
plt.xticks(rotation=15,color='b',fontsize=9)
plt.show()当我们输入按时交货后:

当我们输入晚交货后:
-消费潜力的维度分析
(1)按月份维度分析:
#(1)以月份维度查看货品的数量,得到商品的订单数量每月的变化趋势和幅度(折线图)
data5=data.groupby(['月份','商品'])['数量'].sum().unstack() #将data按照月份和商品进行分组,最后去除数量列放入新建变量data5中
#上面的数据是以列的形式来处理每个变量的,读起来很不方便,使用 .unstack() 列转行的方式处理数据
def yfqs(data5):
data5.plot(kind='line')
plt.show()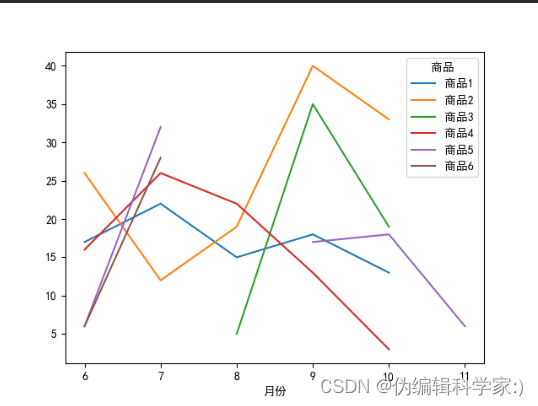
看起来数据乱七八糟的,毕竟这个数据是我随机生成的。不过就算随机生成的数据也可以看出来每个商品的分布情况。
(2)不同消费维度分析:
#(2)不同区域维度潜力分析,可以得出哪个商品在哪个地区更受欢迎
data6=data.groupby(['销售区域','商品'])['数量'].sum().unstack()
def yfqs(data6):
data6.plot(kind='bar')
plt.show()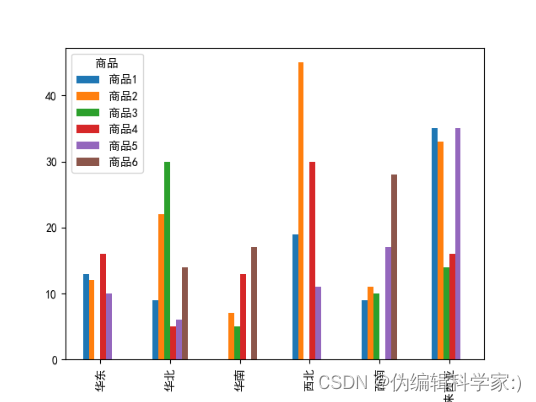
(3)月度和区域结合分析:
#(3)月份和区域维度分析,查看不同商品在不同月份的不同区域的销售情况
data7=data.groupby(['月份','销售区域','商品'])['数量'].sum().unstack()
def hhfx(data7):
a=input()#设立空值,以便后续特定商品查询
data7[a].plot(kind='bar')
plt.xticks(rotation=40,color='b',fontsize=9)
plt.show()我们输入商品2:

-商品是否存在质量问题?
#商品对应销售区域,以及用户的反馈情况来分析
data['货品用户反应'] = data['货品用户反应'].str.strip()#先进行首位空字符串的消除
data8=data.groupby(['商品','销售区域'])['货品用户反应'].value_counts().unstack()#这里总结的是字符串,用数量统计函数
#使data8按列求和,使反应总数按照销售区域和商品划分,然后求出相关比率,复制给data8
data8['拒货率']=data8['拒货']/data8.sum(axis=1)
data8['合格率']=data8['商品合格']/data8.sum(axis=1)
data8['返修率']=data8['返修']/data8.sum(axis=1)
data8.sort_values(['合格率','返修','拒货'],ascending=False)#按照先后顺序进行排序
print("可见生成了\n", data8)
'''
可见生成了
货品用户反应 商品合格 拒货 返修 拒货率 合格率 返修率
商品 销售区域
商品1 华东 1.0 NaN NaN NaN 1.000000 NaN
华北 1.0 NaN NaN NaN 1.000000 NaN
西北 NaN 1.0 1.0 0.500000 NaN 0.400000
西南 NaN NaN 1.0 NaN NaN 1.000000
马来西亚 NaN NaN 3.0 NaN NaN 1.000000
商品2 华东 1.0 1.0 NaN 0.500000 0.400000 NaN
华北 NaN NaN 2.0 NaN NaN 1.000000
华南 NaN 1.0 NaN 1.000000 NaN NaN
西北 1.0 2.0 NaN 0.666667 0.272727 NaN
西南 NaN NaN 1.0 NaN NaN 1.000000
马来西亚 NaN 2.0 NaN 1.000000 NaN NaN
商品3 华北 2.0 NaN NaN NaN 1.000000 NaN
华南 NaN NaN 1.0 NaN NaN 1.000000
西南 1.0 NaN NaN NaN 1.000000 NaN
马来西亚 1.0 NaN NaN NaN 1.000000 NaN
商品4 华东 NaN 1.0 NaN 1.000000 NaN NaN
华北 1.0 NaN NaN NaN 1.000000 NaN
华南 NaN NaN 1.0 NaN NaN 1.000000
西北 1.0 1.0 1.0 0.333333 0.300000 0.275229
马来西亚 1.0 1.0 NaN 0.500000 0.400000 NaN
商品5 华东 1.0 NaN 1.0 NaN 0.500000 0.400000
华北 1.0 NaN NaN NaN 1.000000 NaN
西北 NaN NaN 1.0 NaN NaN 1.000000
西南 NaN 1.0 NaN 1.000000 NaN NaN
马来西亚 2.0 1.0 NaN 0.333333 0.600000 NaN
商品6 华北 1.0 NaN NaN NaN 1.000000 NaN
华南 1.0 NaN 1.0 NaN 0.500000 0.400000
西南 2.0 NaN NaN NaN 1.000000 NaN
'''--总结:
该项目我们完成了不同维度的分析,通过更换groupby函数的参数,以及简单的数据可视化代码,只要我们完成一个维度的分析,剩下维度发分析就可以迎刃而解了。代码编写的有些冗余,混合维度分析中输入错误的分支我也还没有来得及做,未来我会继续完善这个的,未来也会为各位带来更多的简单数据分析的小项目,谢谢大家支持。🌹🌹🌹















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









