






——————————————学习资料和数据来源于B站-Python-学习库——————————
一.待分析问题
- 货品的配送服务有没有问题——交货情况分析
- 有没有具有销售潜力的区域——货品销售情况分析
- 货品质量问题——货品用户反馈情况分析
二.初识数据-清洗数据
data=pd.read_csv("data_wuliu.csv",encoding='gb2312') print(data.info()) print(data.describe())运行结果表明,需要的操作:
1.删除空行
2.数据格式(时间→datetime;销售金额→规整且统一格式、可计算)
3.删除重复值
4.异常值(销售额!=0的行)
清洗数据
#数据清洗
data=data.dropna(axis=0,how='any')#存在空,则删除该行
data=data.drop_duplicates(keep='first')#删除重复值,保留第一个
data=data.drop(columns=['订单行'],axis=1)#删除无用列
data=data[data["销售金额"]!=0]#保留销售金额不为0的数据
data['sale_time']=pd.to_datetime(data['销售时间'])#将销售时间格式转换成datetime格式
data['月份']=data['sale_time'].apply(lambda x:x.month)#对销售时间做映射,提取其中的月份信息,写入“月份”列
#对销售金额进行规整:对于
def amounts_deal(x):
if x.find('万元')!=-1:#说明销售金额中存在万元,转换成以元为单位的浮点型
amounts=float(x[:x.find('万元')].replace(',',''))*10000
else:
amounts=float(x[:x.find('元')].replace(',',''))
return amounts
#调用函数-处理销售金额
data['销售金额']=data['销售金额'].map(amounts_deal)
#重新更新索引
data=data.reset_index(drop=True)三.数据分析及可视化
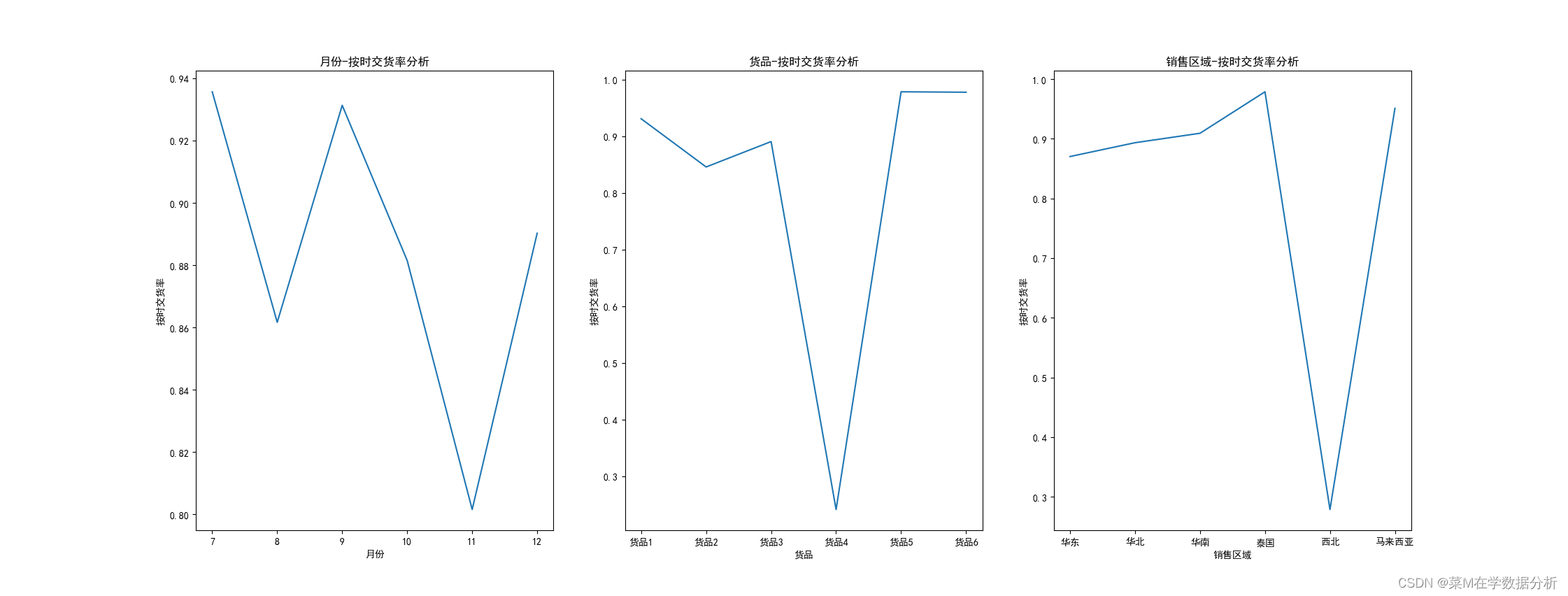
"""1.货品的配送服务有没有问题——交货情况分析""" data['货品交货状况']=data['货品交货状况'].str.strip()#货品交货状况改成字符串的格式,并去除前后空格 #a.时间维度看货品交货状态 data1=data.groupby(by=['月份','货品交货状况']).size().unstack() data1['按时交货率'] = data1['按时交货']/(data1['按时交货']+data1['晚交货']) data1['按时交货率'].plot(kind='line') plt.xlabel('月份') plt.ylabel('按时交货率') plt.title('月份-按时交货率分析') #b.货品维度 data2=data.groupby(by=['货品','货品交货状况']).size().unstack() data2['按时交货率'] = data2['按时交货']/(data2['按时交货']+data2['晚交货']) data2['按时交货率'].plot(kind='line') plt.xlabel('货品') plt.ylabel('按时交货率') plt.title('货品-按时交货率分析') #c.销售区域维度 data3=data.groupby(by=['销售区域','货品交货状况']).size().unstack() data3['按时交货率'] = data3['按时交货']/(data3['按时交货']+data3['晚交货']) data3['按时交货率'].plot(kind='line') plt.xlabel('销售区域') plt.ylabel('按时交货率') plt.title('销售区域-按时交货率分析') #d 货品和销售区域维度 data['货品交货状况']=data['货品交货状况'].str.strip() data2=data.groupby(['货品','销售区域','货品交货状况']).size().unstack() data2['按时交货率']=data2['按时交货']/(data2['按时交货']+data2['晚交货'])
结果:不同维度下交货率
从月份上来看, 11月份按时交货率最低,第四季度的按时交货率普遍低于第三季度;
从货品上来看,货品4的按时交货率极低,急需该货品的更多数据进行分析和提出改善意见;
从销售区域上看,西北地区的按时交货率极低,需要针对该区域的物流信息做出分析和调整
从货品和销售区域多维分析,货品2在马来西亚的按时交货率极低,货品1和货品2在西北的交货率也很低;
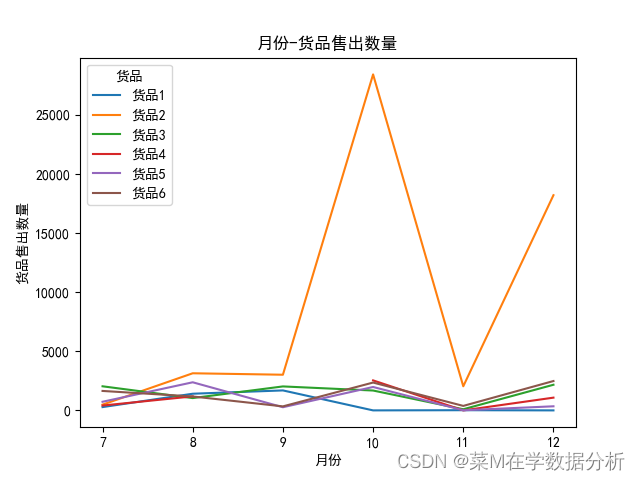
"""2.有没有具有销售潜力的区域——货品销售情况分析""" #a.时间-货品销售数量(判断哪里可以增加宣传力度) data4=data.groupby(by=['月份','货品'])['数量'].sum().unstack()#分组后对不同货品数量进行求和,进而分析 data4.plot(kind='line') plt.xlabel('月份') plt.ylabel('货品售出数量') plt.title('月份-货品售出数量') plt.show() #b.时间-货品销售数量(判断什么时间可以增加宣传力度) data5=data.groupby(by=['销售区域','货品'])['数量'].sum().unstack()#分组后对不同货品数量进行求和 print(data5)
结果:货品销售维度分析
从月份上来看,货品2在十月和十二月销量猛增猜测可能的原因有三:
1.加大了营销力度
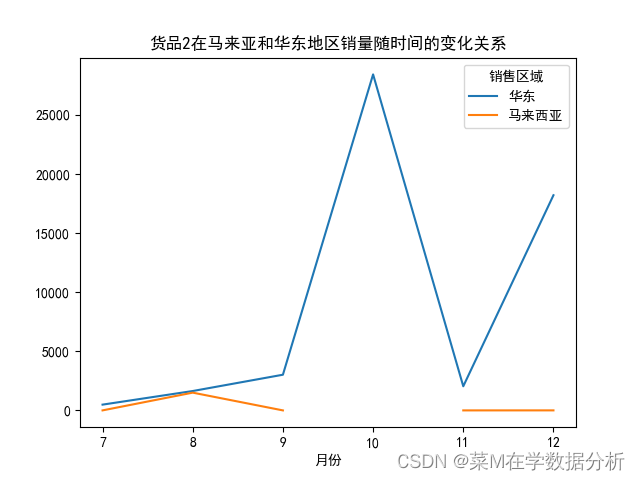
2.开辟了新市场——验证货品2在马来西亚和华东地区销量随时间的变化,发现,十月份和十二月份,马来西亚的货品2销售并没有提高,说明十月、十一月销量的增大和开辟新市场可能无关,可能是增大了在华东地区的营销力度
#单独分析货品2在华东和马来西亚的销量随时间变化的关系 data1=data[data['货品']=='货品2'] data2=data1.groupby(by=['月份','销售区域'])['数量'].sum().unstack() print(data2) data2.plot(kind='line') plt.title('货品2在马来亚和华东地区销量随时间的变化关系') plt.show()
3.十月份是货品2需求量较高的时期,但考虑到十一月销量猛然下降,可能不是自然原因导致,该猜测力降低。
为验证猜测,分析不同月份和地区下,货品2在不同销售区域的销量
分析不同区域下不同货品的销量结果
销售区域 货品1 货品2 货品3 货品4 货品5 货品6 华东 NaN 53812.0 NaN NaN NaN NaN 华北 2827.0 NaN 9073.5 NaN NaN NaN 华南 579.0 NaN NaN NaN NaN NaN 泰国 NaN NaN NaN NaN 5733.0 NaN 西北 11.0 NaN NaN 5229.0 NaN NaN 马来西亚 NaN 1510.0 NaN NaN NaN 8401.0 可以看出,货品1具有三个销售区域,其中华北销量较好,华南销量较低,西北销量最低,需要加大影响力度;
货品2有两个销售区域,华东和马来西亚,其余都是只有一个销售力度
"""3.货品质量问题——看退货情况""" #从货品和销售区域维度看 data['货品用户反馈']=data['货品用户反馈'].str.strip() data5=data.groupby(['货品','销售区域'])['货品用户反馈'].value_counts().unstack() data5['拒货率']=data5['拒货']/data5.sum(axis=1) data5['返修率']=data5['返修']/data5.sum(axis=1) data5['合格率']=data5['质量合格']/data5.sum(axis=1) data5.sort_values(['合格率','返修率','拒货率'],ascending=False,inplace=True) print(data5)结果:
货品用户反馈 拒货 质量合格 返修 拒货率 返修率 合格率 货品 销售区域 货品3 华北 31.0 188.0 19.0 0.130252 0.079788 0.789219 货品6 马来西亚 56.0 246.0 14.0 0.177215 0.044279 0.777936 货品5 泰国 14.0 144.0 29.0 0.074866 0.155018 0.769108 货品2 华东 72.0 184.0 51.0 0.234528 0.165997 0.598568 货品1 华南 5.0 4.0 2.0 0.454545 0.174603 0.343963 西北 NaN 1.0 2.0 NaN 0.666667 0.272727 华北 NaN 3.0 12.0 NaN 0.800000 0.189873 货品4 西北 NaN 9.0 49.0 NaN 0.844828 0.152945 货品2 马来西亚 6.0 1.0 3.0 0.600000 0.283019 0.091886 结果看来
货品3.6.5合格率均较高,返修率比较低,说明质量还可以
货品1.2.4合格率较低,返修率较高,质量存在一定的问题,需要改善
货品2在马拉西亚的拒货率最高,同时货品2在马来西亚的按时交货率较低,为0.100000。猜测:马来西亚人对送货的时效性要求较高,如果达不到,则往往考虑拒货。
考虑到货品2主要在华东地区销售量大,可以考虑增大在华东的投资,适当减小马来西亚的投入。
四.数据分析报告
综合数据分析报告
数据来源于某企业销售的6种商品所对应的送货及用户反馈结果数据,分别在货品按时交货率、货品销量、货品质量上进行了分析
1.按时交货率
从月份上来看, 11月份按时交货率最低,第四季度的按时交货率普遍低于第三季度,说明货品运送情况可能与季节、温度有关;
从货品上来看,货品4的按时交货率极低,急需该货品的更多数据进行分析,以指导得出按时交货率低的主要原因并提出改善意见;
从销售区域上看,西北地区的按时交货率极低,需要针对该区域的物流信息做出分析和调整;
2.货品销量
六种货品除货品2外整体波动不大,货品2在十月和十二月销量猛增,该货品共有两个销售区域,分别为华东和马来西亚,对华东和马来西亚区域货品2的销量分析得,货品2在华东地区的销量较好,在马来西亚销量较低,需要做出措施,且在十月份,华东地区销量猛增,可能加大了营销力度。
3.货品质量
货品3.6.5合格率均较高,返修率比较低,说明质量还可以
货品1.2.4合格率较低,返修率较高,质量存在一定的问题,需要改善
货品2在马拉西亚的拒货率最高,同时,在货品2在马拉西亚的按时交货率也非常低。猜测:马来西亚人对送货的时效性要求较高,如果达不到,则往往考虑拒货。考虑到货品2主要在华东地区销售量大,可以考虑增大在华东的投资,适当减小马来西亚的投入。
五.知识点get√
- 格式object→datetime
- python中find()函数
- 删除空/重复/列
- apply() 函数,自由度较高,可以直接对 Series(带标签的一位数组) 或者 DataFrame (表格型的数据结构,既有行索引,也有列索引,可看做Series组成的字典)中元素进行逐元素遍历操作,方便且高效,具有类似于 Numpy 的特性。
- unstack():将DataFrame格式中行转换成列,便于清晰显示。















 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









