






分享前段时间学习的R语言可视化实操作业,主要是对于四份数据集分别处理得到的八份图表。
目录
二、Crime_Data_from_2020_to_Present数据集
三、rice_production_by_country数据集
一、绪论
本文针对给出的四份数据集分别进行了数据预处理与数据挖掘,分别利用其中包含的分类数据,关系数据,地理数据,时间序列数据,分布数据,高维数据,基于规范、简介、专业、美观的基本绘图原则进行可视化分析,绘制了日历图、坡度图、直方图、条形图、散点图矩阵、堆叠柱状图、华夫饼图、着色地图共计八张图表。
二、Crime_Data_from_2020_to_Present数据集
2.1 数据集分析
本份数据是一系列的犯罪报告记录,共计93万2140行数据,数据内容包括犯罪类型、时间、地点、受害者信息、犯罪状态等,对数据中各列含义进行分析,结果如表所示:
表1 Crime_Data_from_2020_to_Present数据集各列含义表
| 列名 | 含义分析 |
| DR_NO | 报告编号,是每份报告的唯一标识符。 |
| Date Rptd | 报告日期,指的是报告被提交的日期和时间。 |
| DATE OCC | 事件发生日期,指的是犯罪发生的日期和时间。 |
| TIME OCC | 事件发生时间,犯罪发生的具体时间。 |
| AREA | 区域代码,可能是用于标识不同警务区域的数字代码。 |
| AREA NAME | 区域名称,具体的地理位置或区域名称。 |
| Rpt Dist No | 报告分局编号,可能是指向特定警察分局报告的编号。 |
| Part 1-2 | 一级或二级犯罪分类,通常用于统计和分类犯罪类型。 |
| Crm Cd | 犯罪代码,用于标识具体犯罪类型的代码。 |
| Crm Cd Desc | 犯罪代码描述,犯罪代码的具体描述。 |
| Mocodes | 犯罪模式或方法的代码,可能包括犯罪的手段或情景。 |
| Vict Age | 受害者年龄,犯罪受害者的年龄。 |
| Vict Sex | 受害者性别,通常用M表示男性,F表示女性,X表示未知或未指定。 |
| Vict Descent | 受害者种族/民族,描述受害者的种族或民族背景。 |
| Premis Cd | 地点代码,用于标识犯罪发生地点的类型。 |
| Premis Desc | 地点描述,犯罪发生地点的具体描述。 |
| Weapon Used Cd | 武器使用代码,如果犯罪中使用了武器,这里会是相关的代码。 |
| Weapon Desc | 武器描述,武器使用代码的具体描述。 |
| Status | 报告状态代码,表示报告的当前状态或处理情况。 |
| Status Desc | 报告状态描述,状态代码的具体描述。 |
| Crm Cd 1 | 附加犯罪代码,可能表示与主犯罪代码相关的其他犯罪或附加信息。 |
| Crm Cd 2 | 附加犯罪代码,可能表示与主犯罪代码相关的其他犯罪或附加信息。 |
| Crm Cd 3 | 附加犯罪代码,可能表示与主犯罪代码相关的其他犯罪或附加信息。 |
| Crm Cd 4 | 附加犯罪代码,可能表示与主犯罪代码相关的其他犯罪或附加信息。 |
| LOCATION | 犯罪发生的具体地址或位置。 |
| Cross Street | 交叉街道,犯罪发生地点附近的交叉街道名称。 |
| LAT | 纬度,犯罪发生地点的地理坐标。 |
| LON | 经度,犯罪发生地点的地理坐标。 |
通过初步分析可知,本数据集中涵盖着大量的信息,其不仅体现在数据量大,也体现在数据中列数多,所蕴含信息丰富,针对这样的大样本数据集,对其进行有效的数据预处理与数据信息挖掘具有着重要的意义。
2.2 数据预处理
在数据预处理之前,本文首先针对要进行的可视化任务进行分析,对于本份数据集,本文将主要利用其中的TIME OCC与AREA NAME列分别对不同时间下的犯罪事件数绘制日历图,并对不同地区下的犯罪事件数随时间变化情况绘制坡度图,据此确定了本文主要的数据预处理任务。
2.2.1 缺失值检测
本文首先对于数据中各列数据进行缺失值检测,结果如下表所示:
表2 数据集缺失数据情况表
| 列名 | 缺失值数量 |
| Mocodes | 130610 |
| Vict Sex | 124206 |
| Vict Descent | 124216 |
| Premis Cd | 10 |
| Premis Desc | 562 |
| Weapon Used Cd | 610801 |
| Weapon Desc | 610801 |
| Crm Cd 1 | 11 |
| Crm Cd 2 | 864550 |
| Crm Cd 3 | 929875 |
| Crm Cd 4 | 932076 |
| Cross Street | 786138 |
由表可见,本数据集中存在着大量的缺失值,但通过分析可知其中的缺失值可能由犯罪记录时产生的各种情况所导致,并不对事件发生的记录造成实质影响,固本文不采取相应的处理,而是选择保留这些数据。
2.2.2 重复值检测
为了保证绘图任务中对数据进行统计时不会因重复的记录产生计算错误,固对DR_NO列进行了重复值检测,结果为不存在重复值,说明每一条记录均为唯一值,不存在重复记录情况。
2.2.3 数据类型转换
由于TIME OCC列并非合法的datetime数据对象,固对其数据类型进行转化,将其转换为保留到每天的datetime数据类型。
2.2.4 数据分组统计
根据前文所确定的可视化任务,对不同日期与不同犯罪地点进行分组统计,分别统计不同日期与不同犯罪地点下的犯罪事件数量。
2.3 数据可视化
2.3.1 日历图
日历图将时序数据展示为生活中使用的日历形式,适用于显示不同时间段,以及活动事件的组织情况。本文使用日历图进行可视化以展示不同年份,月份,日期下的犯罪事件发生情况,可视化结果如图所示。
图1 2020-2024犯罪数量日历图
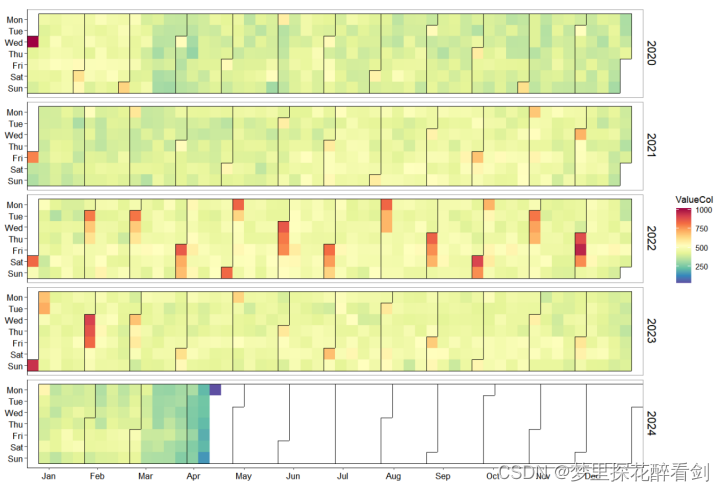
#第一份数据,日历图
library(ggplot2)
library(data.table) #提供data.table()函数
library(ggTimeSeries)
library(RColorBrewer)
library(dplyr)
library(scales)
# 读取CSV文件
dat <- fread("Crime_Data_from_2020_to_Present处理后天数据.csv")
dat$ValueCol <- dat$count
dat$date <- dat$DATEOCC
dat$Year<- as.integer(strftime(dat$date, '%Y')) #年份
dat$month <- as.integer(strftime(dat$date, '%m')) #月份
dat$week<- as.integer(strftime(dat$date, '%W')) #周数
MonthLabels <- dat[,list(meanWkofYr = mean(week)), by = c('month') ]
MonthLabels$month <-month.abb[MonthLabels$month]
ggplot(data=dat,aes(date=date,fill=ValueCol))+
stat_calendar_heatmap()+
scale_fill_gradientn(colours= rev(brewer.pal(11,'Spectral')))+
facet_wrap(~Year, ncol = 1,strip.position = "right")+
scale_y_continuous(breaks=seq(7, 1, -1),labels=c("Mon","Tue","Wed","Thu","Fri","Sat","Sun"))+
scale_x_continuous(breaks = MonthLabels[,meanWkofYr], labels = MonthLabels[, month],expand = c(0, 0)) +
xlab(NULL)+
ylab(NULL)+
theme(panel.background = element_blank(),
panel.border = element_rect(colour="grey60",fill=NA),
strip.background = element_blank(),
strip.text = element_text(size=13,face="plain",color="black"),
axis.line=element_line(colour="black",size=0.25),
axis.title=element_text(size=10,face="plain",color="black"),
axis.text = element_text(size=10,face="plain",color="black")) 由图可知,从2020到2023年犯罪事件数量呈现上升趋势,而在2024年的前三个月出现了一定减少趋势,且在2022年出现了多天数犯罪事件频发的现象,而对于各月份的犯罪事件则分布的较为平均,并未出现某月份犯罪事件发生极为频繁的现象。
2.3.2 坡度图
坡度图可以看成是一种多数据系列的折线图,可以很好地用于比较在两个不同时间或者两个不同实验条件下,某些类别变量的数据变化关系。而对于本文,可以利用坡度图分析在不同区域下犯罪事件数量的变化,可视化结果如图所示:
图2 2020-2023各地区犯罪数量坡度图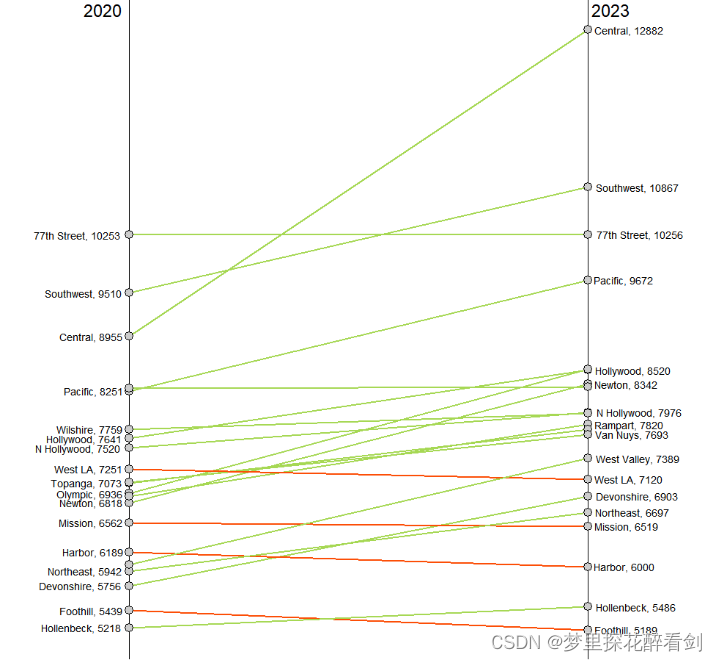
#第一份数据,坡度图
df <- fread("Crime_Data_from_2020_to_Present处理后年地区数据.csv",skip=1)
colnames(df) <- c("continent", "2020", "2023")
left_label <- paste(df$continent, round(df$`2020`),sep=", ")
right_label <- paste(df$continent, round(df$`2023`),sep=", ")
df$class <- ifelse((df$`2020` - df$`2023`) < 0, "green","red")
p <- ggplot(df) +
geom_segment(aes(x=1, xend=2, y=`2020`, yend=`2023`, col=class), linewidth=.75, show.legend=F) + #连接线
geom_vline(xintercept=1, linetype="solid", size=.1) + # 1952 年的垂直直线
geom_vline(xintercept=2, linetype="solid", size=.1) + # 1957 年的垂直直线
geom_point(aes(x=1, y=`2020`), size=3,shape=21,fill="grey80",color="black") + # 1952 年的数据点
geom_point(aes(x=2, y=`2023`), size=3,shape=21,fill="grey80",color="black") + # 1957 年的数据点
scale_color_manual(labels = c("Up", "Down"), values = c("green"="#A6D854","red"="#FC4E07")) +
xlim(.5, 2.5)
# 添加文本信息
p <- p + geom_text(label=left_label, y=df$`2020`, x=rep(1, NROW(df)), hjust=1.1, size=3,check_overlap = TRUE)
p <- p + geom_text(label=right_label, y=df$`2023`, x=rep(2, NROW(df)), hjust=-0.1, size=3,check_overlap = TRUE)
p <- p + geom_text(label="2020", x=1, y=1.02*(max(df$`2020`, df$`2023`)), hjust=1.2, size=5,check_overlap = TRUE)
p <- p + geom_text(label="2023", x=2, y=1.02*(max(df$`2020`, df$`2023`)), hjust=-0.1, size=5,check_overlap = TRUE)
p<-p+theme_void()
p由图可知,大部分地区在2020年到2023年间犯罪数量上升,其中Central地区尤为显著,而只有四个地区的犯罪数量下降。
三、rice_production_by_country数据集
3.1 数据集分析
本数据包含了不同国家关于稻米生产的数据,数据内容涉及不同国家的稻米产业情况,包括总产量、人均产量、种植面积和产量效率等关键指标。每一行代表一个国家的数据,对数据中各列含义进行分析,结果如表所示:
表3 rice_production_by_country数据集各列信息表
| 列名 | 含义分析 |
| Country | 国家名称,表示数据对应的 国家。 |
| Rice Production (Tons) | 稻米产量,以吨为单位,表示一个国家生产的稻米总量。 |
| Rank of Rice Production | 稻米产量排名,表示该国家在全球稻米产量排名中的位置。 |
| Rice Production Per Person (Kg) | 人均稻米产量,以千克为单位,表示平均每人生产的稻米量。 |
| Rank of Rice Production Per Person | 人均稻米产量排名,表示该国家在全球人均稻米产量排名中的位置。 |
| Rice Acreage (Hectare) | 稻米种植面积,以公顷为单位,表示用于种植稻米的总面积。 |
| Rank of Rice Acreage | 稻米种植面积排名,表示该国家在全球稻米种植面积排名中的位置。 |
| Rice Yield (Kg / Hectare) | 稻米产量(公顷产量),以每公顷千克数表示,反映了稻米生产的效率。 |
| Rank of Rice Yield | 稻米产量(公顷产量)排名,表示该国家在全球稻米产量(公顷产量)排名中的位置。 |
3.2 数据预处理
在数据预处理之前,本文首先针对要进行的可视化任务进行分析,对于本份数据集,由于各统计数据间量纲差异较大,不适宜对多数据列进行多数据图表的绘制,固本文采取绘制单数据系列图标,并将主要利用其中的Rice Production (Tons)与Rice Acreage (Hectare)列分别对各国家的稻米产量进行排序并绘制条形图,并对稻米种植面积绘制直方图,以展示不同国家具有的稻米种植地面积分布情况,据此确定了主要的数据预处理任务。
3.2.1 缺失值检测
本文首先对于数据中Rice Production (Tons)与Rice Acreage (Hectare)列数据进行缺失值检测,发现并无缺失值存在,但在一些相应的排名列本文发现了缺失值存在,对此本文选择根据具体数值重新进行排序,而不使用数据中的排名列数据。
3.2.2 重复值检测
为了保证绘图任务中对数据频数进行统计时不会因重复的记录产生计算错误,固对Country列进行了重复值检测,结果为不存在重复值。
3.2.3 数据类型转换
对数据内容进行观察可知在Rice Production (Tons)与Rice Acreage (Hectare)列中均存在字符串与数字并存的情况,据此本文进行了数值与文本的分离,并根据数值后的K与M进行了单位转化。
3.2.4 数据排序
由于要绘制各国稻米产量的条形图,固对Rice Production (Tons)列数据进行了排序操作。
3.3 数据可视化
3.3.1 条形图
在条形图中,类别型或序数型变量映射到纵轴的位置,数值型变量映射到矩形的宽度。条形图的柱形变为横向,与柱形图相比,条形图更加强调项目之间的大小。对于本份数据,使用条形图能够更好的展示各国稻米产量间差异并展示不同国家稻米产量的排名,可视化结果如图所示:
图3 排名前20各国稻米产量条形图
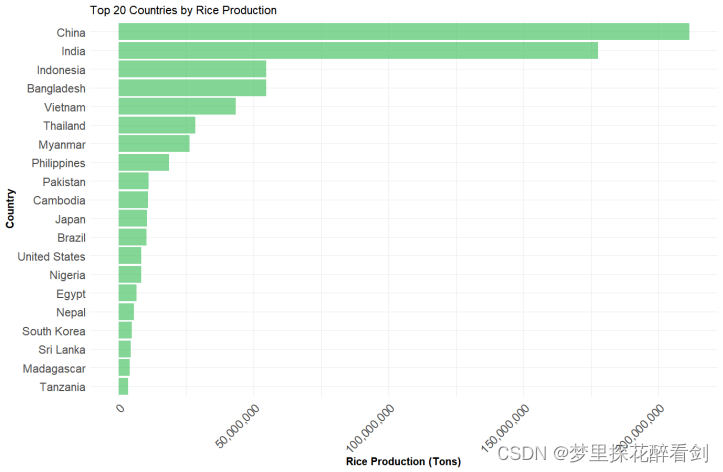
#第二份数据,条形图
df_sorted <- df[order(df$Rice_Production, decreasing = TRUE), ]
# 选择排序后的前20个国家的数据
top20 <- head(df_sorted, 20)
ggplot(top20, aes(x = reorder(Country, +Rice_Production), y = Rice_Production)) +
geom_bar(stat = "identity", fill = "#4FC46AFF",alpha=0.7) + # 使用实际值绘制条形图
theme_minimal() + # 使用简洁主题
scale_y_continuous(labels = scales::label_comma()) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) + # 如果需要,旋转x轴标签以便阅读
xlab("Country") + # x轴标签
ylab("Rice Production (Tons)") + # y轴标签
coord_flip()+
ggtitle("Top 20 Countries by Rice Production") # 图表标题如图所示,可以直观的看到稻米产量排名前20的国家,并且可以得出在稻米产量排名前20的国家中不同国家仍存在着很大的产量差异。
3.3.2 直方图
直方图在平面直角坐标系中,横轴标出每个组的端点,纵轴表示频数,每个矩形的高代表对应的频数,其能够显示各组频数或数量分布的情况且易于显示各组之间频数或数量的差别。对于本文通过绘制直方图,可以很好的看出世界上不同国家占有的稻米种植面积分布在怎样的区间且可以直观的看出不同国家稻米种植面积间的差异,其可视化结果如图所示:
图4 各国稻米种植面积直方图
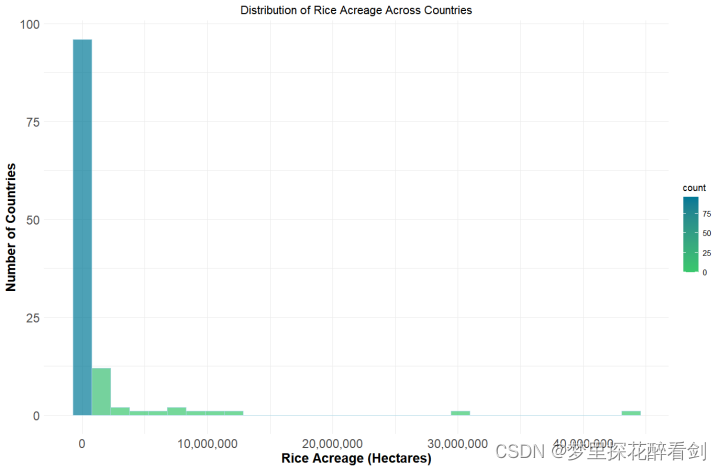
#第二份数据,直方图
df <- read.csv('rice_production_by_country处理后数据.csv', header = TRUE)
head(df)
ggplot(df, aes(Rice_Acreage.Hectare.)) +
geom_histogram(aes(fill = after_stat(count)),color = "lightblue", alpha = 0.7)+
scale_fill_gradient(low = "#3AC96DFF", high = "#007896FF") +
xlab("Rice Acreage (Hectares)") +
ylab("Number of Countries") +
scale_x_continuous(labels = scales::label_comma()) +
ggtitle("Distribution of Rice Acreage Across Countries") +
theme_minimal() +
theme(axis.title.x = element_text(face = "bold", size = 12),
axis.title.y = element_text(face = "bold", size = 12, angle = 90),
plot.title = element_text(hjust = 0.5))由图可知,世界上大部分的国家的稻米种植面积均在0-5000000公顷之间,而极少数国家具有着远超于这些国家的稻米种植面积。
四、war_survival_data数据集
4.1 数据集分析
数据中的每一列代表了一个不同的属性或资源,数据内容是一系列个体的生存资源和情况的记录,每个个体都有一组特定的资源和条件,例如不同数量的食物和水、医疗用品、武器、防御结构、通讯设备等,对数据中各列含义进行分析,结果如表所示:
表4 war_survival_data数据集各列信息表
| 列名 | 含义分析 |
| Name | 参与者的姓名。 |
| Age | 参与者的年龄。 |
| Food Supply (Days) | 食物供应的天数。 |
| Water per Day (Liters) | 每天可用的水量(以升为单位)。 |
| First Aid Kits | 急救包的数量。 |
| Antibiotics | 抗生素的数量。 |
| Painkillers | 止痛药的数量。 |
| Weapons Available | 可用武器的数量。 |
| Defensive Structures | 防御结构的数量。 |
| Training Level | 训练水平。 |
| Radios Available | 可用的收音机数量。 |
| Access to Reliable Information | 是否能够获取可靠信息,列中值为"Yes"或"No"。 |
| Support Groups Available | 是否有支持团体,列中值为"Yes"或"No"。 |
| Entertainment Available | 可用的娱乐类型,列中提供了具体的娱乐项目,如"Books"或"Games"。 |
4.2 数据预处理
在数据预处理之前,本文首先针对要进行的可视化任务进行分析,对于本份数据集,数据维数较多,本文将分别绘制散点图矩阵与分组堆积柱状图,对数据中各列内容间的相关关系进行全面的展示。
4.2.1 缺失值检测
首先对于数据各列进行缺失值检测,发现并无缺失值存在。
4.2.2 重复值检测
对数据中的Name列进行重复值检测,发现其中存在着大量的重复姓名,本文推测这可能源自数据集的来源中大量参与者使用了化名而非真实姓名所导致,且由于确定的可视化任务中不需要使用该列信息,所以对该列不进行处理。
4.2.3 数据分组
由于本文将绘制散点图矩阵,对于Food Supply (Days)列进行分组,以10为间隔进行分组,以展示在不同分组下各列的相关关系。
4.3 数据可视化
4.3.1 散点图矩阵
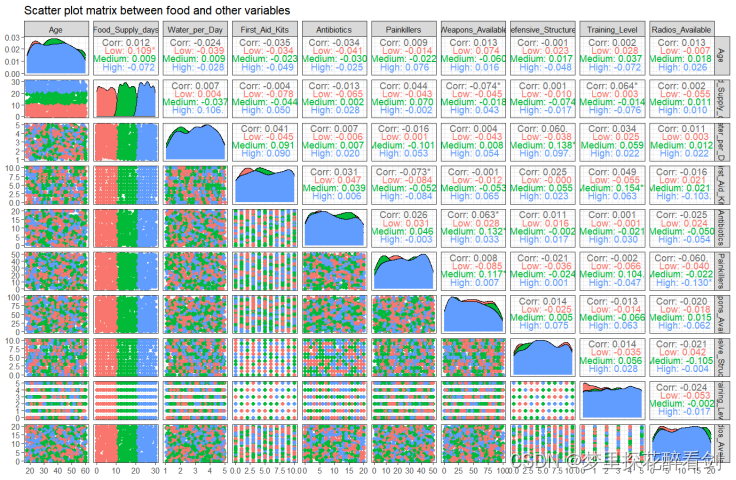
矩阵散点图是散点图的高维扩展,它将高维度的数据每两个变量组成一个散点图,再将它们按照一定的顺序组成矩阵散点图。通过这样的可视化方式,能够将高维度数据中所有的变量两两之间的关系展示出来。它从一定程度上克服了在平面上展示高维度数据的困难,在展示多维数据的两两关系时有着不可替代的作用。对于本文,通过散点图矩阵能很好的展现出该数据集高纬度下不同数据列间存在的相关关系,可视化结果如图所示:
图5 各变量间散点图矩阵
#第三份数据,散点图矩阵
library(GGally)
df <- read.csv('war_survival_data处理后.csv', header = TRUE)
df_selected <- df[ , 2:11]
df_selected$Food_Supply_days_Factor <- cut(df_selected$Food_Supply_days,
breaks = c(-Inf, 10, 20, Inf),
labels = c("Low", "Medium", "High"))
ggpairs(df_selected, columns=1:10, aes(color=Food_Supply_days_Factor)) +
ggtitle("Scatter plot matrix between food and other variables")+
theme_bw() 由图可见,在本数据集中的各变量之间相关关系较弱,可认为各变量相互独立,互不影响。
4.3.2 分组堆积柱状图
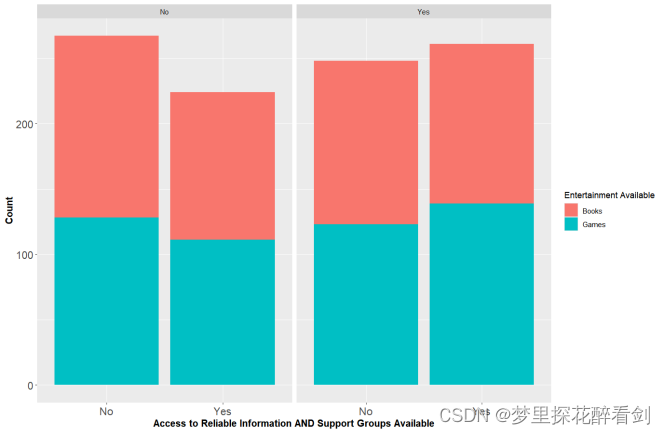
堆积柱形图显示单个项目与整体之间的关系,它比较各个类别的每个数值所占总数值的大小,其以二维垂直堆积矩形显示数值。在本文中,对Access to Reliable Information、Support Groups Available和Entertainment Available列进行不同分组的堆积柱状图绘制,以展示在不同取值情况下的Entertainment Available列取值情况,可视化结果如图所示:
图6 分组堆积柱状图
#第三份数据,创建堆叠条形图
df<- read.csv('war_survival_data处理后.csv', header = TRUE)
colnames(df) <- c("Name", "Age", "Food_Supply_days", "Water_per_Day",
"First_Aid_Kits", "Antibiotics", "Painkillers", "Weapons_Available",
"Defensive_Structures", "Training_Level", "Radios_Available",
"Access_to_Reliable_Information", "Support_Groups_Available",
"Entertainment_Available")
df$Access_to_Reliable_Information <- as.factor(df$Access_to_Reliable_Information)
df$Support_Groups_Available <- as.factor(df$Support_Groups_Available)
df$Entertainment_Available <- as.factor(df$Entertainment_Available)
# 创建堆叠条形图
ggplot(df, aes(x = Access_to_Reliable_Information, fill = Entertainment_Available)) +
geom_bar(position = "stack") +
facet_wrap(~Support_Groups_Available) +
labs(x = "Access to Reliable Information AND Support Groups Available",
y = "Count",
fill = "Entertainment Available") +
theme_minimal()由图可见,在不同的Access to Reliable Information、Support Groups Available列取值情况下,Entertainment Available列取值基本保持均等,且Access to Reliable Information、Support Groups Available列的不同取值情况也基本保持对等。
五、World Economic Classifications v2数据集
5.1 数据集分析
数据中的每一列代表了一个不同的经济指标或国家属性,数据内容是一系列国家在不同经济指标上的排名和分类,对数据中各列含义进行分析,结果如表所示:
表5 World Economic Classifications v2数据集各列信息表
| 列名 | 含义分析 |
| country_name | 国家名称。 |
| un_class_2014 | 2014年联合国对国家的发展分类(Developed=已发展国家,Developing=发展中国家,Transition=过渡国家)。 |
| imf_class_2023 | 2023年国际货币基金组织(IMF)对国家的经济分类(Advanced=先进经济体,Emerging=新兴经济体,Transition=过渡经济体)。 |
| g7 | 国家是否是G7成员国(是的话为"Yes",否则为"No")。 |
| eu_member | 国家是否是欧盟(EU)成员国(是的话为"Yes",否则为"No")。 |
| fuel_exp_country | 国家是否是燃料出口国(是的话为"Yes",否则为"No")。 |
| wealth_rank | 根据GDP PPP(购买力平价国内生产总值)计算的国家财富排名。 |
| gdp_ppp_2022 | 2022年的国家GDP PPP总值,单位为美元。 |
| gdp_pc_2022 | 2022年的国家人均GDP PPP,单位为美元。 |
5.2 数据预处理
在数据预处理之前,本文首先针对要进行的可视化任务进行分析,对于本份数据集,本文将从分类数据与地理数据两个角度进行分析,分别根据un_class_2014列绘制按国家发展分类的不同国家发展占比华夫饼图,并根据gdp_pc_2022列绘制各个国家在世界地图上的着色地图。
5.2.1 缺失值检测
首先对于数据各列进行缺失值检测,发现在除country_name列外各列基本都存在N/A缺失数据的存在,本文分析该缺失数据源自不同统计机构对国家的统计范围不同所导致,对此将其转化为空白值,使其在统计时不将相应的数据纳入计算。
5.2.2 重复值检测
对数据中的country_name列进行重复值检测,发现其并无重复值。
5.2.3 数据类型转换
对于经济指标数据中存在的千分位符与美元符号,对其进行删除,将其转化为浮点型数据。
5.2.4 地图信息合并
由于需要绘制着色地图,对数据中各国家与绘制所需世界地图对应数据进行合并,并将country_name列中部分存在的错误国家名称与非世界地图国家名称格式进行改正。
5.3 数据可视化
5.3.1 华夫饼图
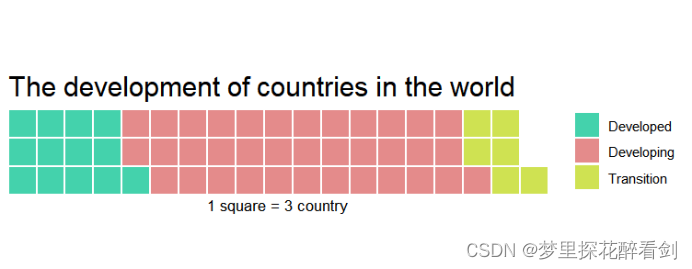
块状华夫饼图是展示总数据的组类别情况的一种有效图表,块状华夫饼图的小方格用不同颜色表示不同类别,适合用来快速检视数据集中不同类别的分布和比例,并与其他数据集的分布和比例进行比较,让人更容易找出当中模式。对于本文数据集,使用华夫饼图能够快速的看出不同国家类型的分布与比例,可视化结果如图所示:
图7 按发展情况分类各国家华夫饼图
#第四份数据,华夫饼图
library(waffle)
expenses <- c('Developed' = 39, 'Developing' = 110, 'Transition' = 18)
waffle(expenses/3, rows=3, size=0.6,
colors=c("#44D2AC", "#E48B8B", "#CFE252"),
title="The development of countries in the world",
xlab="1 square = 3 country")由图可见,世界中的过渡型国家占比最少,而发展中国家占比最多。
5.3.2 着色地图
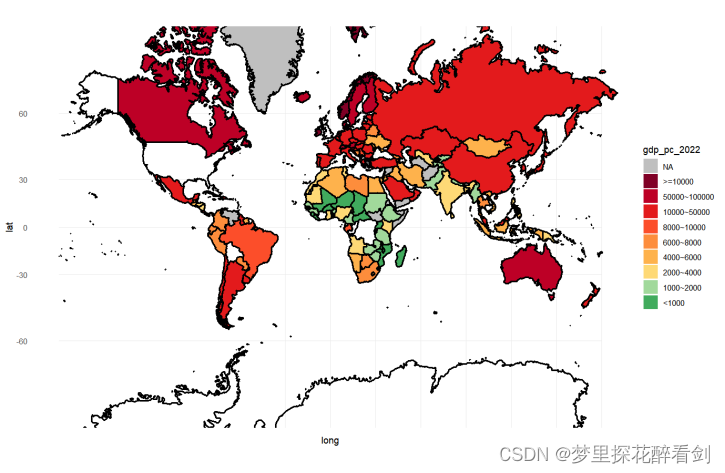
着色地图使用明暗度、颜色或图案来显示不同地理位置或区域之间的值在比例上有何不同。可使用从浅(不太频繁/较低)到深(较频繁/较多)的明暗度快速显示相对差异。对于本文数据,由于具备着大部分国家的相应经济指标,可以使用着色地图显示各国家人均GDP的差异,可视化结果如图所示:
图8 各国人均GDP着色地图
#第四份数据,地理图
#世界地图的绘制
library(maps)
library(ggplot2)
library(RColorBrewer)
colormap<-c(rev(brewer.pal(9,"Greens")[c(4,6)]),brewer.pal(9,"YlOrRd")[c(3,4,5,6,7,8,9)])
mydata<-read.csv("World Economic Classifications v2处理后数据.csv",stringsAsFactors = FALSE)
mydata$Scale<-as.numeric(unlist(mydata$gdp_pc_2022))
mydata$Rice<-mydata$gdp_pc_2022
mydata$fan<-cut(mydata$Rice,
breaks=c(min(mydata$gdp_pc_2022 ,na.rm=TRUE)-1,
1000,2000,4000,6000,8000,10000,50000,100000,
max(mydata$gdp_pc_2022 ,na.rm=TRUE)+1),
labels=c("<1000","1000~2000","2000~4000","4000~6000","6000~8000","8000~10000",
"10000~50000","50000~100000",">=10000"),order=TRUE)
world_map<-map_data("world")
ggplot()+
geom_map(data=mydata,aes(map_id=country_name,fill=fan),map=world_map)+
geom_path(data=world_map,aes(x=long,y=lat,group=group),colour="black",size=1)+
coord_map("mercator",xlim=c(-180,180),ylim=c(-90,90))+#墨卡托投影
scale_y_continuous(breaks=(-2:2)*30)+
scale_x_continuous(breaks=(-1:6)*30)+
scale_fill_manual(name="gdp_pc_2022",values=colormap,na.value="grey75")+
guides(fill=guide_legend(reverse = TRUE))+
theme_minimal()由图可见,在亚洲地区与欧洲地区的各国家具有相对较高的人均GDP,而在非洲的各国家则人均GDP较低。

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









