






1.集合概念
Java集合是一个存储对象的容器,用于存储和操作多个对象。集合框架定义了一种通用的集合接口,以及一组实现这些接口的类。
1.1为什么要使用集合
在最开始我们使用变量存储数据,为了存储多个数据我们引入了数组的概念。但是数组的由于长度固定造成了我们在添加数据但是未知大小时存储很困难。为了解决这个问题,我们引如集合概念,集合是一类更高级的数据结构封装,灵活使用集合可以有效的规避数组的一些问题,提高开发效率。
1.2泛型
泛型就是把类型明确的工作推迟到创建对象或调用方法的时候才去明确的特殊的类型。
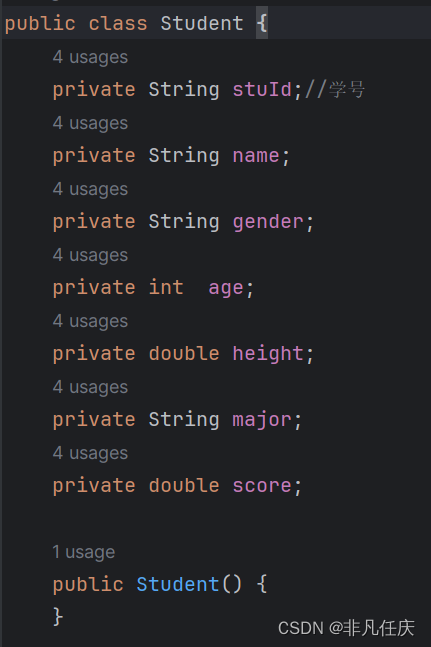

简单来说,像上面这个例子,我们创建了一个student类,在创建ArrayList数组的时候其中方括号内填写的这个类的名称,就表示后面往这个list中加入的只能是student类所创建出的对象。
![]()
这个ArrayList类中用到的类,用E替代(泛型), 当创建对象时才明确它的类型。
![]()
在创建这个list对象的时候才确定他的类型为Integer。
1.2.1为什么要使用泛型
使代码更加简洁
// 不使用泛型
public void printInt(int num){
System.out.println(num);
}
public void printString(String str){
System.out.println(str);
}
// 使用泛型
public <T> void print(T item){
System.out.println(item);
}使程序更加健壮
// 使用泛型避免类型转换错误
List<String> list = new ArrayList<>();
list.add("hello");
String str = list.get(0); // 不需要进行类型转换
// 非泛型代码,需要进行类型转换
List list = new ArrayList();
list.add("hello");
String str = (String) list.get(0); // 需要进行类型转换提高可读性和稳定性
// 使用泛型,增加了代码的表现力
Map<String, Integer> map = new HashMap<>();
// 没有使用泛型,代码表达不清晰
Map map = new HashMap();1.2.2泛型的擦除
泛型的擦除是指编译器在编译时会将泛型类型擦除,将所有的泛型类型替换为其原始类型或限定类型。这是因为Java虚拟机中并没有泛型的概念,泛型信息仅存在于编译期,在运行时是不会保留泛型类型信息的。
//一个泛型类
public class MyList<T> {
private T data;
public MyList(T data) {
this.data = data;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}
//使用该泛型类
public class Main {
public static void main(String[] args) {
MyList<String> stringList = new MyList<>("Hello");
String data = stringList.getData();
}
}
//在编译时编译器会擦除泛型信息,将代码转换为如下形式
public class MyList {
private Object data;
public MyList(Object data) {
this.data = data;
}
public Object getData() {
return data;
}
public void setData(Object data) {
this.data = data;
}
}
1.2Collection接口

集合框架中的Collection接口是所有集合类的根接口,他继承于Iterable。

Collection是一个接口,不可以直接创建一个对象,要借助其子类去创建一个对象。他的主要方法有下面几个。
- add(E e):将指定的元素添加到集合中。
- remove(Object o):从集合中移除指定的元素。
- contains(Object o):判断集合中是否包含指定的元素。
- size():返回集合中元素的个数。
- isEmpty():判断集合是否为空。
- clear():清空集合中的所有元素。
- iterator():返回一个迭代器,用于遍历集合中的元素。
这里主要说一下iterator。
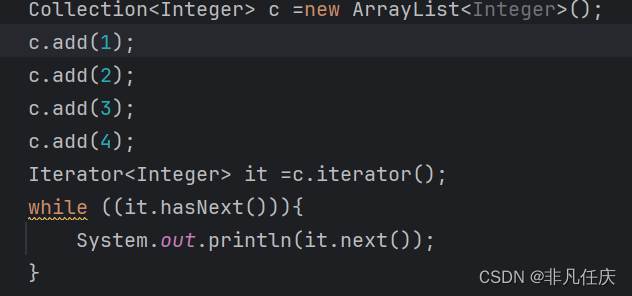
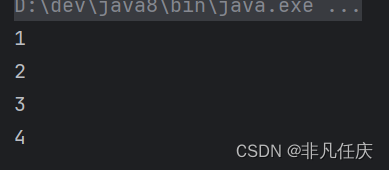
Iterator<Integer> it =c.iterator();构造一个迭代器,it.hasNext()判断当前元素后面还有元素吗,运行结果如下。
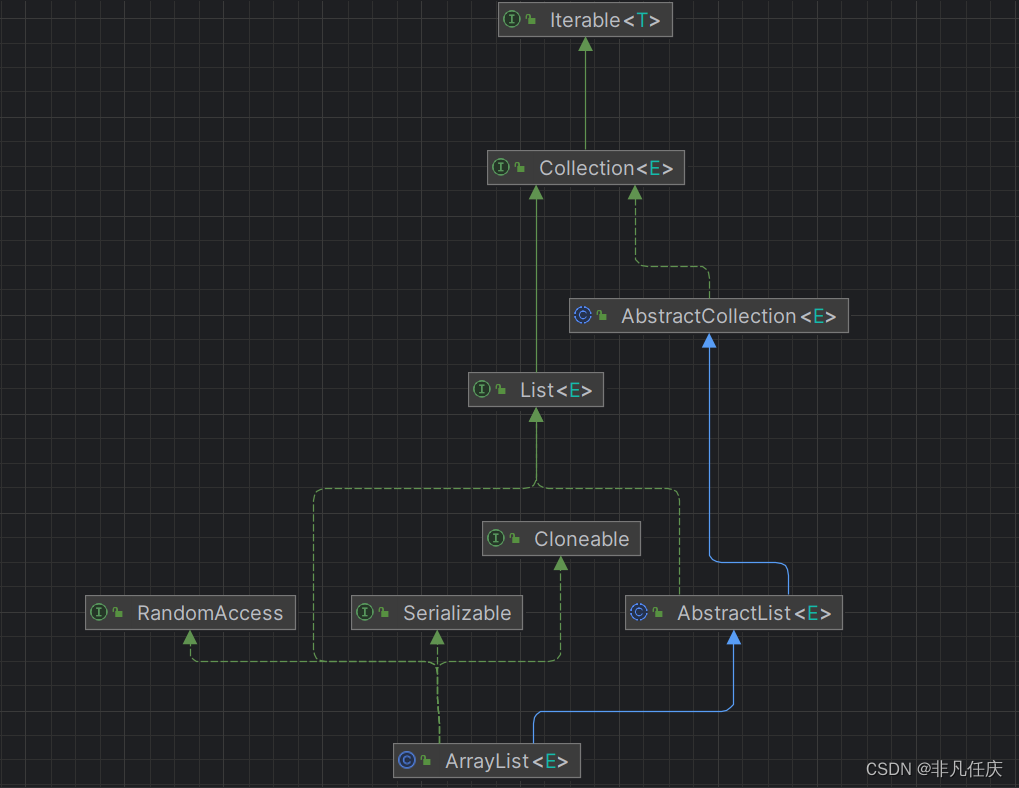
1.3List接口
List接口继承于Collection,他也需要自己的子类去实现,其常用的的子类有arrayList和Linked List。
1.3.1ArrayList
1.3.1.1ArrayList与普通数组的区别
与普通数组相比,ArrayList可以在创建对象的时候不用确定个数,可以一直往里面添加数据,Array List可以自动扩容,Array List在创建时会默认初始化长度为10,但是Array List数组也并不是每一次添加数据就扩容一次,一般会按照1.5倍去扩容,当初始为10时,并且也元素已经添加满了,就会自动扩容1.5倍,变成15。
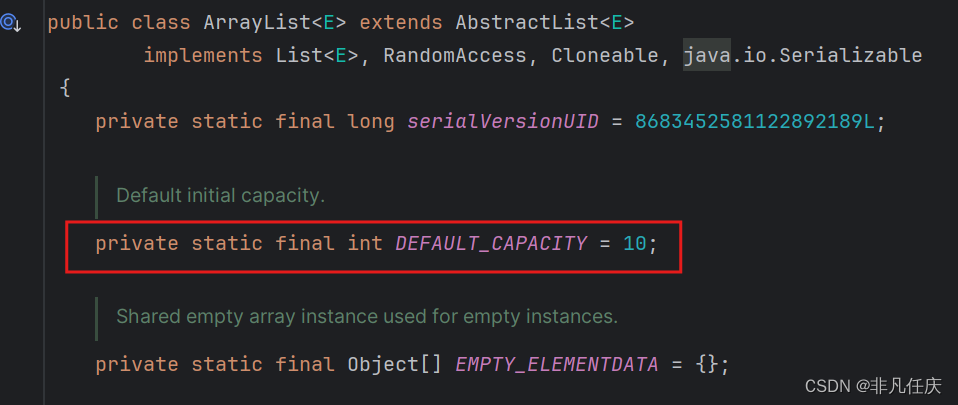
1.3.1.2AyyayList常用api
- add(E element): 向ArrayList中添加一个元素。
- get(int index): 获取指定索引位置的元素。
- remove(int index): 移除指定索引位置的元素。
- size(): 返回ArrayList中元素的个数。
- clear(): 清空ArrayList中的所有元素。
- indexOf(Object o): 返回指定元素在ArrayList中第一次出现的索引位置,如果不存在则返回-1。
- contains(Object o): 判断ArrayList中是否包含指定元素。
- isEmpty(): 判断ArrayList是否为空。
- set(int index, E element): 替换指定索引位置的元素。
- toArray(): 将ArrayList转换为数组。
1.3.2LinkedList
逻辑上连续,空间上不联系,如下图车厢和前后两个车厢相连(双向链表)。

LinkedList与ArrayList的功能差不多,但是ArrayList支持随机访问,通过索引可以快速定位元素;而LinkedList不支持随机访问,需要从头开始逐个遍历或者从尾部开始逐个遍历。在ArrayList中,如果在中间位置插入或删除元素,需要将该位置后面的元素向后或向前移动;而在LinkedList中,插入和删除操作效率较高,只需要修改相邻节点的指针即可。在空间复杂度上,ArrayList在存储大量数据时,可能会浪费一定的内存空间;而LinkedList的内存利用率相对较高,因为它只需要额外的空间存储节点之间的指针。对于迭代操作,LinkedList比ArrayList更快,因为它具有更高的指针移动效率。ArrayList不是线程安全的,而LinkedList可以在并发环境中更容易地进行修改。















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









