







前言:(可以跳过)2024年C题题目参考,参考代码,参考文献
题目:

 我参考的代码是这个博主,如过觉得侵权,及时联系,立马删帖!!!
我参考的代码是这个博主,如过觉得侵权,及时联系,立马删帖!!!
参考文献
[1] 张雅静, 李梦晨, 洪传春. 基于多目标线性规划的河北种植业结构调整研究[J]. 中国集体经济, 2022(09): 32-33.
[2] 张玲, 叶先宝, 陈圣群. 线性规则下应急资源配置的随机优化模型与算法研究[J]. 系统科学与数学, 2017, 37(05): 1221-1230.
[3] 张慧, 李文丽. 2020-2021年河南省农作物种子产供需形势分析[J]. 种业导刊, 2021(01): 16-18.
[4] 李彩花. 多期动态规划下的家庭资产组合决策优化研究[D]. 大连理工大学, 2016.
[5] 许文, 迟国泰, 杨万武. 考虑违约损失控制的商业银行多期资产组合动态优化模型[J]. 管理学报, 2010, 7(04): 585-594.
[6] 迟国泰, 余方平, 王玉刚. 基于动态规划的多期期货套期保值优化模型研究[J]. 中国管理科学, 2010, 18(03): 17-24. DOI: 10.16381/j.cnki.issn1003-207x.2010.03.018.
[7] Smith, J., & Jones, A. (2019). Optimizing Crop Yield under Variable Climate Conditions[J]. Journal of Agricultural Science, 112(3), 225-240.
[8] 刘亚琼, 李法虎, 杨玉林. 北京市农作物种植结构调整与节水节肥方案优化研究[J]. 中国农业大学学报, 2011, 16(05): 39-44.
[9] 吴殿廷, 王传周. 农作物布局优化模型的初步探讨[J]. 北京师范大学学报(自然科学版), 1998(04): 554-558.
[10] Johnson, D., & Lee, K. (2020). The Impact of Market Price Fluctuations on Crop Selection Strategies[J]. Agricultural Economics Review, 45(4), 345-360.
[11] 罗强, 周东. (2021). 作物选择的多准则决策支持系统研究[J]. 计算农业期刊, 15(4), 377-389.
[12] Patel, Kumar, N. (2019). Optimizing Crop Mixes for Smallholder Farmers: A Linear Programming Model Approach[J]. Sustainable Agriculture, 37(6), 512-525.
[13] Anderson, G., & Taylor, H. (2016). Uncertainty and Risk in Agricultural Decision-Making: A Stochastic Approach[J].
2024全国大学生数学建模比赛C题第一问模型+代码参考

优化模型:



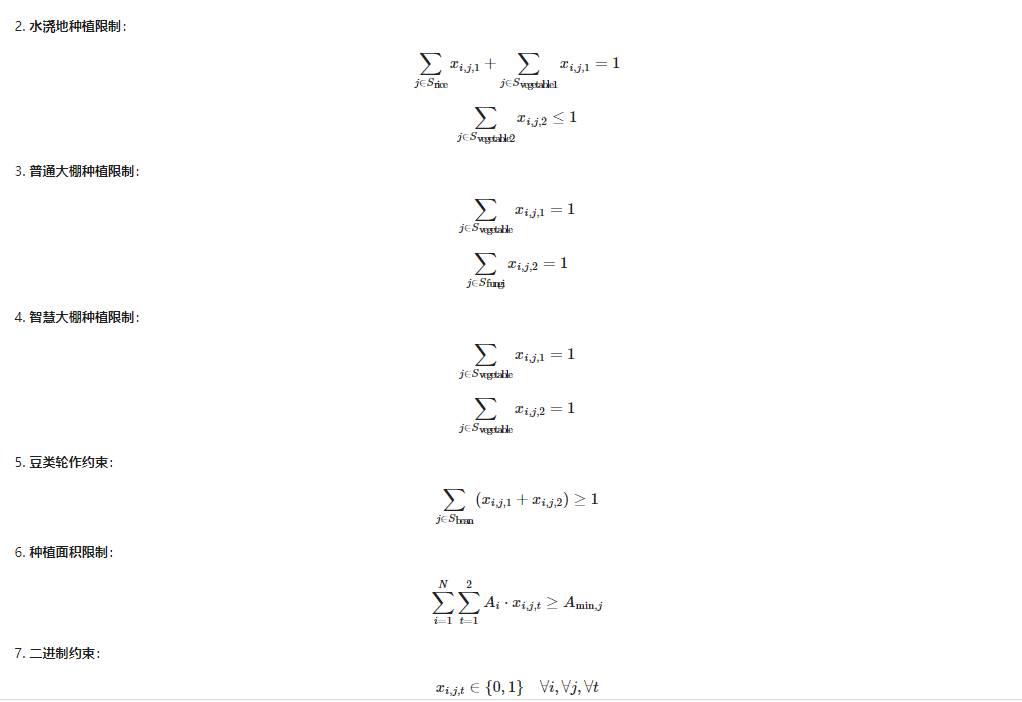
for index,i in enumerate(df['地块类型'].unique()):
df.loc[df.地块类型==i,'地块类型'] = index
df = df.sort_values(by=['地块类型','作物编号'])
for index,i in enumerate(df['作物类型'].unique()):
df.loc[df.作物类型==i,'作物类型'] = index
for index,i in enumerate(df1['地块类型'].unique()):
df1.loc[df1.地块类型==i,'地块类型'] = index
df['种植产量'] = df['亩产量/斤']*df['种植面积/亩']for index,i in enumerate(df['作物类型'].unique()):
df.loc[df.作物类型==i,'作物类型'] = index
pinghan_crops = []
titian_crops = []
shanpo_crops = []
shuijiao_crops = []
shuijiao_veg_s1 = []
shuijiao_veg_s2 = []
putong_veg = []
putong_jun = []
zhihui_veg_s1 = []
zhihui_veg_s2 = []
for index,i in enumerate(zip(df.作物类型,df.种植季次,df.地块类型,df.作物名称)):
if i[2] == 0:
pinghan_crops.append(index)
elif i[2] == 1:
titian_crops.append(index)
elif i[2] == 2:
shanpo_crops.append(index)
elif i[2] == 3 and i[1] =='单季':
shuijiao_crops.append(index)
elif i[2] == 3 and i[1] =='第一季':
shuijiao_veg_s1.append(index)
elif i[2] == 3 and i[1] =='第二季':
shuijiao_veg_s2.append(index)
elif i[2] == 4 and i[1] == '第一季':
putong_veg.append(index)
elif i[2] == 4 and i[1] == '第二季':
putong_jun.append(index)
elif i[2] == 5 and i[1] == '第一季':
zhihui_veg_s1.append(index)
elif i[2] == 5 and i[1] == '第二季':
zhihui_veg_s2.append(index)
bean_crops = []
for index,i in enumerate(df['是否豆类']):
if i =='是':
bean_crops.append(index)
costs = df['种植成本/(元/亩)'].tolist()
# 54 块地,每块地都有特定的类型 (0: 平旱地, 1: 梯田, 2: 山坡, 3: 水浇地, 4: 普通大棚, 5: 智慧大棚)
num_plots = 54
num_crops = 125 # 125 种属于不同地块不同季节的作物
crop_codes = df['作物编号'].tolist()# 125种作物的作物编码,相当于是相对索引
# 定义成本、价格、产量、面积等数据 (仅示例)
sales_max = (df.groupby('作物编号').sum()['种植产量']*1.1).to_dict() #期望的需求量
sales_min1 = (df.groupby('作物编号').sum()['种植产量']*0.9).to_dict() #真实需求量
sales_min2 = (df.groupby('作物编号').sum()['种植产量']*0.9).to_dict() #真实需求量
sales_min3 = (df.groupby('作物编号').sum()['种植产量']*0.9).to_dict() #真实需求量
sales = (df.groupby('作物编号').sum()['种植产量']*1).to_dict() #去年的需求量
prices = (df['亩产量/斤']*df['平均销售单价']).tolist() #每一亩的销售价格
yields = df['亩产量/斤'].tolist() # 作物的亩产量产量列表
areas = df1['地块面积/亩'].tolist() # 地块面积
soil_type = df1['地块类型'].tolist() # 每个地块对应的地块类型
total_set = list(range(125))
time = 6def out_index(ls,total_ls):
return [item for item in total_ls if item not in ls]
def find_indices(lst, element):
return [index for index, value in enumerate(lst) if value == element]
#将相同产品的分散产量合在一起,计算是否超过销量,
def function(x,sales_min1,sales_min2,sales_min3):
for i in sales_min1.keys():
total = 0
index_ls = find_indices(soil_type, i)
total_product1 = sum([yields[j]*areas[i]*x[i][j][o] for i in range(num_plots) for j in index_ls for o in range(2)])
total_product2 = sum([yields[j]*areas[i]*x[i][j][o] for i in range(num_plots) for j in index_ls for o in range(2,4)])
total_product3 = sum([yields[j]*areas[i]*x[i][j][o] for i in range(num_plots) for j in index_ls for o in range(4,6)])
if total_product1 <= sales_min1[i]:
pass
else:
total += (total_product1-sales_min1[i])*prices[index_ls[0]]
if total_product2 <= sales_min2[i]:
pass
else:
total += (total_product2-sales_min2[i])*prices[index_ls[0]]
if total_product3 <= sales_min3[i]:
pass
else:
total += (total_product3-sales_min3[i])*prices[index_ls[0]]
return total假设每个作物的销售量会在上下10%的范围内浮动,我们的策略是根据去年销量的最大上涨范围作为目标销量,秉持宁可浪费,也不无法满足百姓食品需求的原则,制作生产计划,然后在目标函数中,使用最大下降范围作为真实的销量,将其放入到目标函数中,就可以得到剩余部分造成的损失,因此就存在两个模型,一个是“超过部分滞销,直接浪费“,另一个是“以百分之五十的价格低价出售”
对于未来n年,我们只需要优化最近三年的内容,只要保证每三年,每个土地都种植豆类,那么即可保证土地是营养的,并且最终的目标模型以利润最大化目标进行度量,所以未来n年,我们只需要重复的依次填写优化结果即可
情况一:超过部分滞销,造成浪费;
import pulp
# 定义问题
model = pulp.LpProblem("Land_Type_Optimization", pulp.LpMaximize)
# 定义变量 x[i][j][t],表示在第i块地是否种植第j种作物,t 表示第 t 季节
x = pulp.LpVariable.dicts("x", (range(num_plots), range(num_crops), range(6)), cat="Binary")
# 额外定义一个二进制变量 y[i][o],表示第o季第i个田是否种水稻(0 为不种,1 为种)
y = pulp.LpVariable.dicts("y", (range(num_plots), range(6)), cat="Binary")
# 目标函数:利润最大化
model += pulp.lpSum([(prices[j] * yields[j] - costs[j]) * x[i][j][t] * areas[i]
for i in range(num_plots) for j in range(num_crops) for t in range(6)]) - function(x,sales_min1,sales_min2,sales_min3)
#情况一
# 地块类型约束
for i in range(num_plots):
if soil_type[i] == 0:
for o in [0,2,4]:
model += pulp.lpSum([x[i][j][o] for j in pinghan_crops]) >= 1 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in pinghan_crops]) <= 5 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in out_index(pinghan_crops,total_set)]) == 0 # 每块地只能种自己的作物
model += pulp.lpSum([x[i][j][o+1] for j in range(num_crops)]) == 0 # 只能种一季,第二季不种
model += pulp.lpSum([x[i][j][0]+x[i][j][2]+x[i][j][4] for j in bean_crops]) == 1 # 三年内必须有一次豆类
elif soil_type[i] == 1:
for o in [0,2,4]:
model += pulp.lpSum([x[i][j][o] for j in titian_crops]) >= 1 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in titian_crops]) <= 5 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in out_index(titian_crops,total_set)]) == 0 # 每块地只能种自己的作物
model += pulp.lpSum([x[i][j][o+1] for j in range(num_crops)]) == 0 # 只能种一季,第二季不种
model += pulp.lpSum([x[i][j][0]+x[i][j][2]+x[i][j][4] for j in bean_crops]) == 1 # 三年内必须有一次豆类
elif soil_type[i] == 2:
for o in [0,2,4]:
model += pulp.lpSum([x[i][j][o] for j in shanpo_crops]) >= 1 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in shanpo_crops]) <= 5 # 每块地最多种5种作物
model += pulp.lpSum([x[i][j][o] for j in out_index(shanpo_crops,total_set)]) == 0 # 每块地只能种自己的作物
model += pulp.lpSum([x[i][j][o+1] for j in range(num_crops)]) == 0 # 只能种一季,第二季不种
model += pulp.lpSum([x[i][j][0]+x[i][j][2]+x[i][j][4] for j in bean_crops]) == 1 # 三年内必须有一次豆类
elif soil_type[i] == 3: # 水浇地
for o in range(6):
model += x[i][45][o] == y[i][o] # 是否种植水稻
for o in [0,2,4]:
model += y[i][o+1] == 0 # 第二季不能种水稻
# 如果不种水稻,则可以在两季都种蔬菜(蔬菜可以混合种植)
model += pulp.lpSum([x[i][j][o] for j in shuijiao_veg_s1]) >= 0 #第一季最多种四种
model += pulp.lpSum([x[i][j][o] for j in shuijiao_veg_s1]) <= 4 #第一季最多种四种
model += pulp.lpSum([x[i][j][o+1] for j in shuijiao_veg_s2]) >= 0 #第二季最多种三种(只有三种蔬菜可以种)
model += pulp.lpSum([x[i][j][o+1] for j in shuijiao_veg_s2]) <= 1 #第二季最多种三种
# 水稻与蔬菜的选择是互斥的,要么种水稻,要么种蔬菜
model += pulp.lpSum([x[i][j][o] for j in shuijiao_veg_s1]) <= (1 - y[i][o])*1000 #乘以一个很大的数字
model += pulp.lpSum([x[i][j][o] for j in shuijiao_veg_s2]) <= (1 - y[i][o])*1000 #乘以一个很大的数字
#水浇田只能种水浇田能种的蔬菜
model += pulp.lpSum([x[i][j][o] for j in out_index(shuijiao_veg_s1+shuijiao_crops,total_set)]) == 0 # 其余的不能种
model += pulp.lpSum([x[i][j][o+1] for j in out_index(shuijiao_veg_s2,total_set)]) == 0 # 其余的不能种
model += pulp.lpSum([x[i][j][o] for j in bean_crops for o in range(6)]) == 1 # 三年内必须有一次豆类
elif soil_type[i] == 4: # 普通大棚
for o in [0,2,4]:
model += pulp.lpSum([x[i][j][o] for j in putong_veg]) <= 4 # 一季蔬菜最多4种
model += pulp.lpSum([x[i][j][o] for j in putong_veg]) >= 1 # 一季蔬菜最多4种
model += pulp.lpSum([x[i][j][o+1] for j in putong_jun]) <= 2 # 一季食用菌最多2种
model += pulp.lpSum([x[i][j][o+1] for j in putong_jun]) >= 1 # 一季食用菌最多2种
model += pulp.lpSum([x[i][j][o] for j in out_index(putong_veg,total_set)]) == 0 # 其余不能种
model += pulp.lpSum([x[i][j][o+1] for j in out_index(putong_jun,total_set)]) == 0 # 其余不能种
model += pulp.lpSum([x[i][j][0]+x[i][j][2]+x[i][j][4] for j in bean_crops]) == 1 # 三年内必须有一次豆类
elif soil_type[i] == 5: # 智慧大棚
for o in [0,2,4]:
model += pulp.lpSum([x[i][j][o] for j in zhihui_veg_s1]) <= 4 # 一季蔬菜最多4种
model += pulp.lpSum([x[i][j][o] for j in zhihui_veg_s1]) >= 1 # 一季蔬菜最多4种
model += pulp.lpSum([x[i][j][o+1] for j in zhihui_veg_s2]) <= 4 # 二季蔬菜最多4种
model += pulp.lpSum([x[i][j][o+1] for j in zhihui_veg_s2]) >= 1 # 二季蔬菜最多4种
model += pulp.lpSum([x[i][j][o] for j in out_index(zhihui_veg_s1,total_set)]) == 0 # 其余不能种
model += pulp.lpSum([x[i][j][o+1] for j in out_index(zhihui_veg_s2,total_set)]) == 0 # 其余不能种
model += pulp.lpSum([x[i][j][o] for j in bean_crops for o in range(time)]) == 1 # 三年内必须有一次豆类
#不能连续种植
for i in range(num_plots):
for j in range(num_crops):
model += pulp.lpSum([x[i][j][0] + x[i][j][2]]) <= 1
model += pulp.lpSum([x[i][j][2] + x[i][j][4]]) <= 1
model += pulp.lpSum([x[i][j][1] + x[i][j][3]]) <= 1
model += pulp.lpSum([x[i][j][3] + x[i][j][5]]) <= 1
model += pulp.lpSum([x[i][j][0] + x[i][j][1]]) <= 1
model += pulp.lpSum([x[i][j][2] + x[i][j][3]]) <= 1
model += pulp.lpSum([x[i][j][4] + x[i][j][5]]) <= 1
#每一年不要,同一类型的田尽量不要重复的种植相同的植物
for j in range(num_crops):
#由于红萝卜白萝卜大白菜所需产量实在是过于小,第二季度只需要两个水浇田就可以满足一个作物的需求
for o in range(6):
if j in shuijiao_veg_s2:
model += pulp.lpSum([x[i][j][o] for i in range(num_plots)]) <= 1
# 求解
model.solve()
# 输出结果
for i in range(num_plots):
for j in range(num_crops):
for t in range(6):
if pulp.value(x[i][j][t]) == 1:
print(f"Plot {i} should plant crop {j} in season {t}")结果图表保存
#制作结果图表
a = df2[['作物名称','作物类型']].drop_duplicates()
dic = {}
for i,o in zip(df2.作物名称,df2.作物类型):
dic[i] = o
reward = pd.DataFrame(index=df['作物名称'].unique())
reward['作物类型'] = [dic[i] for i in reward.index]
for wh in range(3):
for t in range(6):
result = []
product = []
for i in range(num_plots):
tem = []
product_tem = []
n = 0
for j in range(num_crops):
if pulp.value(x[i][j][t]) == 1:
n += 1
tem.append(df1['地块面积/亩'].values[i])
product_tem.append(df1['地块面积/亩'].values[i]*df['亩产量/斤'].values[j])
else:
tem.append(0)
product_tem.append(0)
if max(product_tem) >0:
product_tem = [round(k/n,2) for k in product_tem]
if max(tem)>0:
tem = [round(k/n,2) for k in tem]
result.append(tem)
product.append(product_tem)
result = pd.DataFrame(result,index=df1['地块名称'].values,columns=df['作物编号'].values).T
result = result.groupby(result.index).sum().T
result.columns = df['作物名称'].unique()
if 2023+t//2+1+wh*3 > 2030:
continue
result.to_excel(f'{2023+t//2+1+wh*3}年第{t%2+1}季(情况2).xlsx')
product = pd.DataFrame(product,index=df1['地块名称'].values,columns=df['作物编号'].values).T
product = product.groupby(product.index).sum().T
product.columns = df['作物名称'].unique()
reward[f'{2023+t//2+1+wh*3}年{t%2+1}季产量(斤)'] = product.sum()
reward
收益分析
# sale = sales.values() #销量
df['平均成本'] = df['亩产量/斤']/df['种植成本/(元/亩)'] #平均成本
cost = df.sort_values(by='作物编号').drop_duplicates(subset='作物名称')['平均成本'].values
price = df['平均销售单价'].values
result = pd.DataFrame()
result.index=reward.index
for c in reward.columns[1:]:
ls = []
for i,o,n,m in zip(reward[c].values,sale,cost,price):
if i > o:
ls.append(o*(m-n)+(i-o)*(m-n)*0.5)
else:
ls.append(i*(m-n))
result[c+'盈利'] = ls
result['作物类型'] = reward['作物类型']
result.groupby('作物类型').sum().to_excel('情况二不同年份总的盈利情况.xlsx')
result.groupby('作物类型').sum()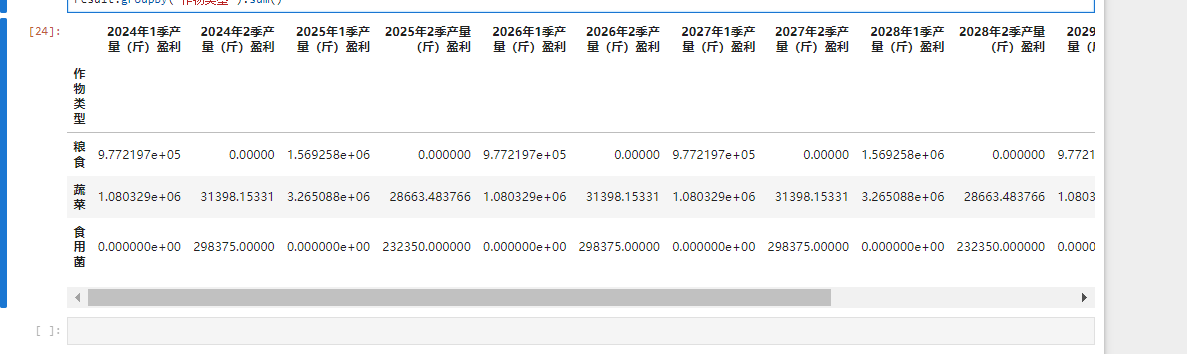


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











