







概述
产生原因
-
IP 地址:是互联网上计算机唯一的逻辑地址,通过 IP 地址实现不同计算机之间的相互通信,每台联网计算机都需要通过 IP 地址来互相联系和分别,但由于 IP 地址是由一串容易混淆的数字串构成,人们很难记忆所有计算机的 IP 地址,这样对于我们日常工作生活访问不同网站是很困难的。
-
基于这种背景,人们在 IP 地址的基础上又发展出了一种更易识别的符号化标识,这种标识由人们自行选择的字母和数字构成,相比 IP 地址更易被识别和记忆,逐渐代替 IP 地址成为互联网用户进行访问互联的主要入口。这种符号化标识就是域名
-
域名虽然更易被用户所接受和使用,但计算机只能识别纯数字构成的 IP 地址,不能直接读取域名。因此要想达到访问效果,就需要将域名翻译成 IP 地址。而 DNS 域名解析承担的就是这种翻译效果
作用:
-
DNS(Domain Name System)是互联网上的一项服务,用于将域名和IP地址进行相互映射,使人更方便的访问互联网
-
正向解析:域名->IP
-
反向解析:IP->域名
连接方式
-
DNS使用53端口监听网络
-
查看方法:
-
DNS默认以UDP这个较快速的数据传输协议来查询,但没有查询到完整的信息时,就会再次以TCP协议重新查询则启动DNS时,会同时启动TCP以及UDP的port53
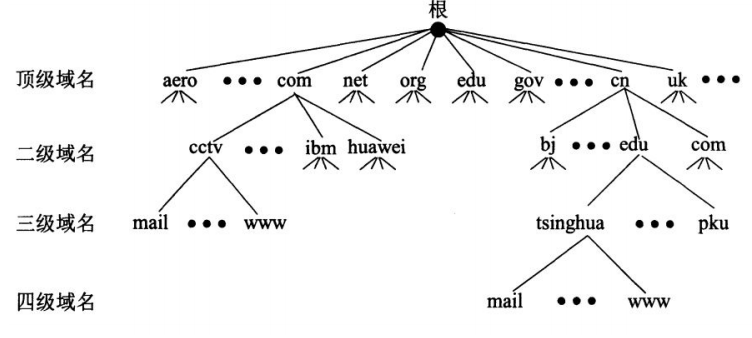
因特网的域名结构
拓扑:
-
由于因特网的用户数量较多,则因特网命名时采用层次树状结构的命名方法。
-
域名(domain name):任何一个连接在因特网上的主机或路由器,都有一个唯一的层次结构的名称
-
域(domain):是名字空间中一个可被管理的划分结构。
-
注意:域名只是逻辑概念,并不代表计算机所在的物理地点
分类
-
国家顶级域名:采用ISO3166的规定,如:cn代表中国,us代表美国,uk代表英国,等等。国家域名又常记为CCTLD(country code top-level domains,cc表示国家代码contry-code)
-
通用顶级域名:最常见的通用顶级域名有7个
-
com (公司企业)
-
net (网络服务机构)
-
org (非营利组织)
-
int (国际组织)
-
gov (美国的政府部门)
-
mil (美国的军事部门)
-
edu(教育机构)
-
-
基础结构域名(infrastructure domain):这种顶级域名只有一个,即arpa,用于反向域名解析,因此称为反向域名
域名服务器类型划分
-
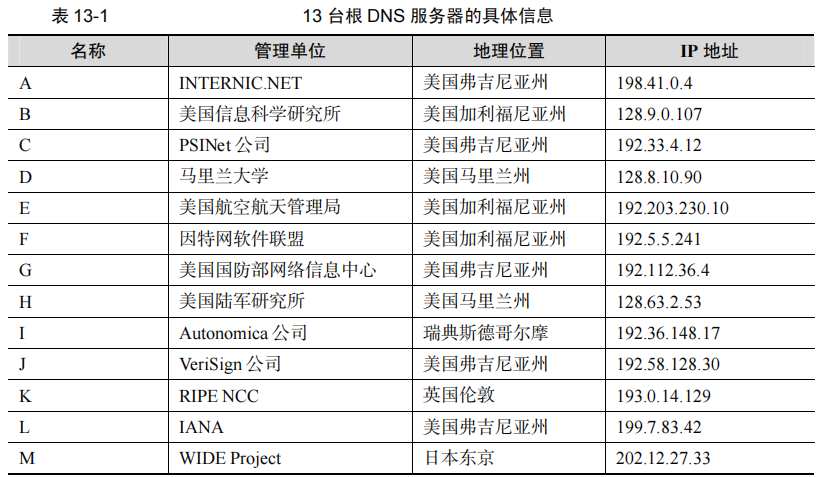
组织架构:根域名服务器:最高层次的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和IP地址。本地域名服务器要对因特网上任何一个域名进行解析,只要自己无法解析,就首先求助根域名服务器。则根域名服务器是最重要的域名服务器。假定所有的根域名服务器都瘫痪了,那么整个DNS系统就无法工作。所以根域名服务器并不直接把待查询的域名直接解析出IP地址,而是告诉本地域名服务器下一步应当找哪一个顶级域名服务器进行查询。
-
在与现有IPv4根服务器体系架构充分兼容基础上,由我国下一代互联网国家工程中心领衔发起的“雪人计划”于2016年在美国、日本、印度、俄罗斯、德国、法国等全球16个国家完成25台IPv6(互联网协议第六版)根服务器架设,事实上形成了13台原有根加25台IPv6根的新格局,为建立多边、民主、透明的国际互联网治理体系打下坚实基础。中国部署了其中的4台,由1台主根服务器和3台辅根服务器组成,打破了中国过去没有根服务器的困境。
-
顶级域名服务器:负责管理在该顶级域名服务器注册的二级域名
-
权威域名服务器:负责一个“区”的域名服务器
-
本地域名服务器:本地域名服务器不属于域名服务器的层次结构,当主机发出DNS查询时,这个查询报文就发送给本地域名服务器
-
为了提高域名服务器的可靠性,DNS域名服务器都把数据复制到几个域名服务器来保存,如:
-
主服务器:在特定区域内具有唯一性,负责维护该区域内的域名与 IP 地址之间的对应关系(真正干活的)
-
从服务器:从主服务器中获得域名与 IP 地址的对应关系并进行维护,以防主服务器宕机等情况(打下手的)
-
缓存服务器:通过向其他域名解析服务器查询获得域名与 IP 地址的对应关系,并将经常查询的域名信息保存到服务器本地,以此来提高重复查询时的效率,一般部署在企业内网的网关位置,用于加速用户的域名查询请求
-
DNS域名解析过程
分类:
-
递归解析:DNS 服务器在收到用户发起的请求时,必须向用户返回一个准确的查询结果。如果 DNS 服务器本地没有存储与之对应的信息,则该服务器需要询问其他服务器,并将返回的查询结果提交给用户
-
迭代解析(反复):DNS 服务器在收到用户发起的请求时,并不直接回复查询结果,而是告诉另一台 DNS 服务器的地址,用户再向这台 DNS 服务器提交请求,依次反复,直到返回查询结果
解析图:
过程分析
-
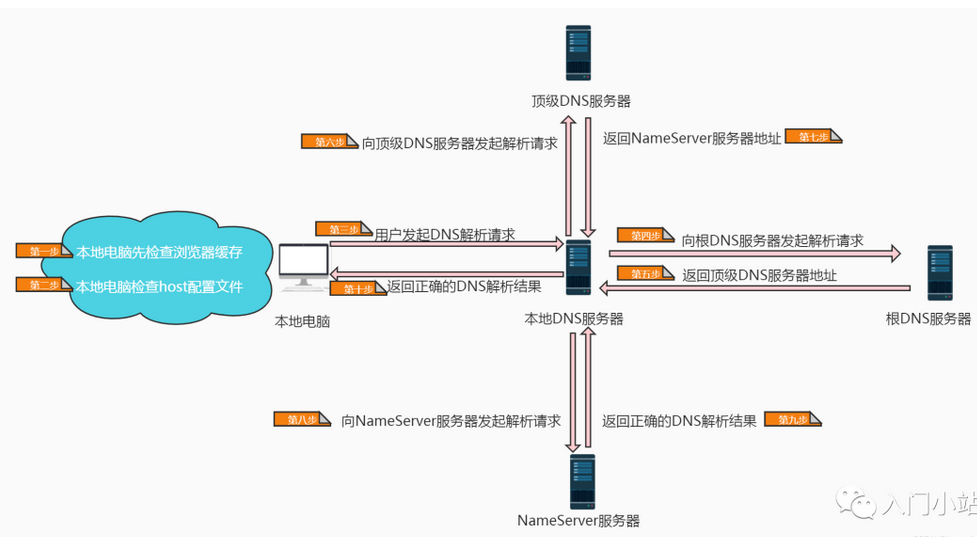
第一步:在浏览器中输入www . google .com 域名,本地电脑会检查浏览器缓存中有没有这个域名对应的解析过的 IP 地址,如果缓存中有,这个解析过程就结束。浏览器缓存域名也是有限制的,不仅浏览器缓存大小有限制,而且缓存的时间也有限制,通常情况下为几分钟到几小时不等,域名被缓存的时间限制可以通过 TTL 属性来设置。这个缓存时间太长和太短都不太好,如果时间太长,一旦域名被解析到的 IP 有变化,会导致被客户端缓存的域名无法解析到变化后的 IP 地址,以致该域名不能正常解析,这段时间内有一部分用户无法访问网站。如果设置时间太短,会导致用户每次访问网站都要重新解析一次域名
-
第二步:如果浏览器缓存中没有数据,浏览器会查找操作系统缓存中是否有这个域名对应的 DNS 解析结果。其实操作系统也有一个[域名解析]的过程,在 Linux 中可以通过 / etc/hosts 文件来设置,而在 windows 中可以通过配置 C:\Windows\System32\drivers\etc\hosts 文件来设置,用户可以将任何域名解析到任何能够访问的 IP 地址。例如,我们在测试时可以将一个域名解析到一台测试服务器上,这样不用修改任何代码就能测试到单独服务器上的代码的业务逻辑是否正确。正是因为有这种本地 DNS 解析的规程,所以有黑客就可能通过修改用户的域名来把特定的域名解析到他指定的 IP 地址上,导致这些域名被劫持
-
第三步:前两步是在本地电脑上完成的,若无法解析时,就要用到我们网络配置中的 "DNS 服务器地址" 了。操作系统会把这个域名发送给这个本地 DNS 服务器。每个完整的内网通常都会配置本地 DNS 服务器,例如用户是在学校或工作单位接入互联网,那么用户的本地 DNS 服务器肯定在学校或工作单位里面。它们一般都会缓存域名解析结果,当然缓存时间是受到域名的失效时间控制的。大约 80% 的域名解析到这里就结束了,后续的 DNS 迭代和递归也是由本地 DNS 服务器负责
-
第四步:如果本地 DNS 服务器仍然没有命中,就直接到根 DNS 服务器请求解析
-
第五步:根 DNS 服务器返回给本地 DNS 域名服务器一个顶级 DNS 服务器地址,它是国际顶级域名服务器,如. com、.cn、.org 等,全球只有 13 台左右
-
第六步:本地 DNS 服务器再向上一步获得的顶级 DNS 服务器发送解析请求
-
第七步:接受请求的顶级 DNS 服务器查找并返回此域名对应的 Name Server 域名服务器的地址,这个 Name Server 服务器就是我要访问的网站域名提供商的服务器,其实该域名的解析任务就是由域名提供商的服务器来完成。 比如我要访问 www.baidu.com,而这个域名是从 A 公司注册获得的,那么 A 公司上的服务器就会有 www.baidu.com 的相关信息
-
第八步:返回该域名对应的 IP 和 TTL 值,本地 DNS 服务器会缓存这个域名和 IP 的对应关系,缓存时间由 TTL 值控制
-
第九步:Name Server 服务器收到查询请求后再其数据库中进行查询,找到映射关系后将其IP地址返回给本地DNS服务器
-
第十步:本地DNS服务器把解析的结果返回给本地电脑,本地电脑根据 TTL 值缓存在本地系统缓存中,域名解析过程结束在实际的 DNS 解析过程中,可能还不止这 10 步,如 Name Server 可能有很多级,或者有一个 GTM 来负载均衡控制,这都有可能会影响域名解析过程
-
注意:
-
从客户端到本地DNS服务器是属于递归查询,而DNS服务器之间使用的交互查询就是迭代查询
-
114.114.114.114是国内移动、电信和联通通用的DNS,手机和电脑端都可以使用,干净无广告,解析成功率相对来说更高,国内用户使用的比较多,而且速度相对快、稳定,是国内用户上网常用的DNS。
-
223.5.5.5和223.6.6.6是阿里提供的免费域名解析服务器地址
-
8.8.8.8是GOOGLE公司提供的DNS,该地址是全球通用的,相对来说,更适合国外以及访问国外网站的用户使用
-


















 1242
1242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











