






目录
前言:
1.下面我将阐述一些关于集合的理解和笔记分析,理论方面的解释较少,主要是一些实例说明,闲话少说,立刻开始。
集合框架总体结构
Collection概述
1.ArrayList
package day08;
import java.util.ArrayList;
import java.util.Iterator;
public class demo {
public static void main(String[] args) {
ArrayList List1 = new ArrayList();
//添加元素
List1.add(29);
List1.add("张三");
List1.add(true);
List1.add("张三");
List1.add("李四");
//集合长度
System.out.println(List1.size());
//返回此列表中指定位置的元素。
System.out.println(List1.get(1));
//按索引删除指定位置的元素
List1.remove(2);
//删除指定的元素内容
List1.remove("张三");
//用指定的元素替换此列表中指定位置的元素。
List1.set(2,"王五");
//for循环遍历
for (int i=0;i<List1.size();i++){
System.out.println(List1.get(i));
}
//迭代器的运用,遍历集合,快捷键itit
//查看所有代码段的快捷键ctrl+j
Iterator iter=List1.iterator();
while (iter.hasNext()) {
Object next = iter.next();
System.out.println(next);
}
}
}
2.LinkedList
1.LinkedList集合的特有功能:
| 方法名称 | 说明 |
|---|---|
|
public void addFirst(E e)
|
在该列表开头插入指定的元素
|
|
public void addLast(E e)
|
将指定的元素追加到此列表的末尾
|
|
public E getFirst()
|
返回此列表中的第一个元素
|
|
public E getLast()
|
返回此列表中的最后一个元素
|
|
public E removeFirst()
|
从此列表中删除并返回第一个元素
|
|
public E removeLast()
|
从此列表中删除并返回最后一个元素
|
2.ArrayList和LinkedList的区别:
|
ArrayList
|
LinkedList
|
|---|---|
|
底层封装数组实现,分配的是一块连续的内
存空间
|
底层封装链表实现,分配的是不连续的内存
空间
|
|
读取数据效率更高
|
读取数据效率相对较低
|
|
增,删等操作效率相对偏低
|
增,删等操作效率高
|
|
相对于
ArrayList,
多了对于首元素和尾元素的
操作
|
3.HashSet
重要特性和用法:
-
无序集合:
HashSet中的元素没有特定的顺序,每次调用iterator()方法时,返回的迭代器遍历的顺序也可能不同。 -
不允许重复元素:向
HashSet中添加元素时,如果元素已经存在,则添加操作不会成功,会抛出IllegalStateException异常。 -
线程不安全:
HashSet不是线程安全的,多个线程同时修改一份HashSet实例时需要外部同步。 -
大小可变:
HashSet的大小可以根据需要动态调整,当元素数量达到容量和负载因子(load factor)的乘积时,哈希表会自动扩容。 -
null值问题:
HashSet允许包含一个null值。
因为和 List 接口一样, Set 接口也是 Collection 的子接口,因此,常用方法和 Collection 接口一样,这里就不赘述了。
请看代码实例:
package day09;
import java.util.HashSet;
import java.util.Iterator;
public class SetDemo1 {
public static void main(String[] args) {
/*set集合的特点:
1.添加元素的顺序与输出的顺序不一定相同
2.set的不能使用普通的for循环进行遍历,因为set集合没有索引
3.添加的元素不能重复*/
HashSet hashSet = new HashSet();
hashSet.add("hello");
hashSet.add("world");
hashSet.add("java");
hashSet.add("world");
//增强型for
for (Object item:hashSet){
System.out.println(item);
}
//迭代器
Iterator iterator = hashSet.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next);
}
System.out.println(hashSet);
}
}
4.LinkedHashSet
特性与区别:
5.方法与HashSet大致都一样
5.TreeSet
特性:
-
自动排序:
TreeSet会自动保持其元素的排序状态,元素会按照它们的自然顺序进行排序,或者根据Comparator提供的顺序进行排序。 -
不包含重复元素:和所有
Set实现一样,TreeSet不允许有重复的元素。 -
有序性:
TreeSet中的元素是有序的,支持一系列有序的操作,如first(),last(),ceiling(),floor()等。 -
Null 值:
TreeSet不允许使用null值。如果尝试插入null值,将抛出NullPointerException。 -
线程不安全:
TreeSet的设计不是线程安全的。如果需要在多线程环境中使用,可以使用Collections.synchronizedSet(new TreeSet<>())来包装。
排序说明:
1.自然排序:
2.定制排序:
下面我将重点讲述定制排序,请看实例:
键盘录入5个学生信息(姓名,语文成绩,数学成绩,英语成绩),按照总分从低到高输出到控制台,使用TreeSet保存学生的信息
首先我们先创建一个学生类:
package day09;
public class Student implements Comparable<Student>{
private String name;
private int math;
private int china;
private int english;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getMath() {
return math;
}
public void setMath(int math) {
this.math = math;
}
public int getChina() {
return china;
}
public void setChina(int china) {
this.china = china;
}
public int getEnglish() {
return english;
}
public void setEnglish(int english) {
this.english = english;
}
public Student(String name, int math, int china, int english) {
this.name = name;
this.math = math;
this.china = china;
this.english = english;
}
public Student() {
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", math=" + math +
", china=" + china +
", english=" + english +
'}';
}
public int Score(){
return this.china+this.english+this.math;
}
@Override
public int compareTo(Student o) {
//根据成绩升序排序
int rs = this.Score() - o.Score();
//根据成绩降序排列
//int rs1=o.Score()-this.Score();
if(rs == 0 ){
if(o == this){
return 0;
}else{
return -1;
}
}
return rs;
}
}
然后创建一个测试类:
package day09;
import java.util.ArrayList;
import java.util.TreeSet;
public class tes01 {
public static void main(String[] args) {
TreeSet<Student> students = new TreeSet<>();
students.add(new Student("zs",24,45,89));
students.add(new Student("ww",12,39,78));
students.add(new Student("ls",34,61,56));
for (Student as:students){
System.out.println(as);
}
}
}
最后它将会输出
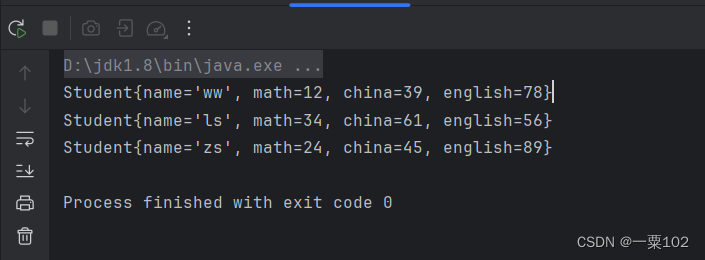
6.Map集合的特征
7.HashMap
简述:基于哈希表实现,键值对无序,允许空键和空值。
下面讲解一些主要方法,请看实例:
package day10;
import java.util.Collection;
import java.util.HashMap;
import java.util.Set;
public class MapDemo {
public static void main(String[] args) {
HashMap map = new HashMap();
//添加键值对
map.put("CN","中国");
map.put("CN","中国香港");
map.put("USA","美国");
map.put("null","空值");
map.put("Null",null);
//获取对应键的值
System.out.println(map.get("CN"));
System.out.println(map.get("USA"));
System.out.println(map.get("null"));
//获取map集合的长度
System.out.println(map.size());
//判断集合是否包含指定key
System.out.println(map.containsKey("CN"));
//判断集合是否包含指定value
System.out.println(map.containsValue(null));
// 获取所有的键
Set<String> keys = map.keySet();
for (String key : keys) {
System.out.println("键:" + key + ",值:" + map.get(key));
}
// 获取所有的值
Collection<String> values = map.values();
for (String value : values) {
System.out.println("值:" + value);
}
//遍历
map.forEach((key,value)->{
System.out.println("Key:"+key+",Value:"+value);
});
}
}
8.HashTable与HashMap的区别
9.TreeMap
TreeMap 是 Java 集合框架(Java Collections Framework)中的一种基于红黑树(Red-Black Tree)的有序映射表。它存储键值对,并确保键的顺序性。以下是 TreeMap 的几个重要特点:
-
键的排序性:
TreeMap会根据键的自然顺序或者用户指定的比较器来保持键的顺序。如果没有任何排序,它默认会按照键的字符串顺序进行排序。 -
红黑树实现:
TreeMap使用红黑树来存储键值对,这样可以在对数时间复杂度内完成查找、插入和删除操作。 -
无序集合:与
LinkedHashMap不同,TreeMap不会保持插入顺序,而是保持基于键的排序顺序。 -
不保证映射的迭代顺序:自 Java 8 开始,
TreeMap不保证迭代顺序,因为迭代顺序可能会在结构修改后发生改变。 -
null值:TreeMap不允许键或值是null。如果尝试插入null键,会抛出NullPointerException。 -
无界性:
TreeMap没有预定义的最大容量,但是由于它基于内存,所以会受到系统资源的限制。 -
性能:在理想情况下,
TreeMap的get、put和remove操作的时间复杂度为 O(log n),其中 n 是树中节点的数量。 -
功能方法:
TreeMap提供了多种方法,如ceilingKey、floorKey、lowerKey、higherKey等,用于在树中查找特定的键。
下面讲解一些主要方法,请看实例:
package day10;
import java.util.*;
public class TreeMap_Demo {
public static void main(String[] args) {
TreeMap<String, Integer> map = new TreeMap<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
//当两个字符串长度一致
if (o1.length()==o2.length()){
//按顺序依次比较每一个字符
for (int i = 0; i <o1.length() ; i++) {
if (o1.charAt(i)==o2.charAt(i)){
continue;
}
return o1.charAt(i)-o2.charAt(i);
}
}
return o1.length()-o2.length();
}
});
//添加元素,为了更好的体现各种方法,你可以改变所添加的元素
map.put("a",32);
map.put("bc",13);
map.put("def",10);
map.put("cccc",29);
map.put("eeeee",24);
//返回此地图中包含的映射的Set视图。
Set<Map.Entry<String,Integer>> es=map.entrySet();
for (Map.Entry en:es){
System.out.println("key:"+en.getKey()+",value:"+en.getValue());
}
System.out.println("------------");
//返回与大于或等于给定键的最小键相关联的键值映射,如果没有此键,则 null
Map.Entry entry=map.ceilingEntry("d");
System.out.println(entry.getKey()+"---"+entry.getValue());
//严格大于
entry=map.higherEntry("d");
System.out.println(entry.getKey()+"---"+entry.getValue());
//返回大于或等于给定键的 null键,如果没有此键,则返回 null 。
System.out.println(map.ceilingKey("d"));
//返回与小于或等于给定键的最大键相关联的键值映射,如果没有此键,则 null
entry=map.floorEntry("d");
System.out.println(entry.getKey()+"---"+entry.getValue());
//严格小于
entry=map.lowerEntry("d");
System.out.println(entry.getKey()+"---"+entry.getValue());
//返回小或等于给定键的 null键,如果没有此键,则返回 null 。
System.out.println(map.floorKey("d"));
//获取第一个实体对
entry=map.firstEntry();
System.out.println(entry.getKey()+"---"+entry.getValue());
//获取第一个key
String key=map.firstKey();
System.out.println(key);
//获取最后一个实体对象
entry=map.lastEntry();
System.out.println(entry.getKey()+"---"+entry.getValue());
//截取Map集合当中的一部分
SortedMap sm=map.subMap("b","d");
Set<Map.Entry> entrys=sm.entrySet();
for (Map.Entry en:entrys){
System.out.println("key:"+en.getKey()+",value:"+en.getValue());
}
}
}
10.ConcurrentHashMap(拓展)
主要特点:
-
线程安全:
ConcurrentHashMap是线程安全的,这意味着它可以在多个线程之间安全地共享,而无需额外的同步或包装。 -
高并发性能:它通过分段技术(Segment)或原子操作(如 CAS)来实现高并发性能。这允许在绝大多数情况下进行无锁操作,只有在数据结构需要扩容或者极少数的竞争情况下才会使用锁。
-
可扩展性:
ConcurrentHashMap能够在不影响并发性能的情况下进行动态扩容。
稍微看一下实列吧
package day10;
import java.util.Random;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMaps_Demo {
public static void main(String[] args) {
ConcurrentHashMap<Integer, Integer> con = new ConcurrentHashMap<>();
/* Random random = new Random();
for (int i=0;i<=10;i++){
int a= random.nextInt(100);
con.put(i,a);
}*/
con.put(1,2);
con.put(2,3);
con.put(3,4);
con.put(4,5);
con.put(5,6);
//多线程
long before=System.currentTimeMillis();
con.forEach(5,(key,value)->{
System.out.println("key:"+key+",value:"+value);
});
long after=System.currentTimeMillis();
System.out.println("总消耗时间:"+(after-before));
//查找
String str=con.search(5,(key,value)->{
if(key==5){
return "存在";
}
return null;
});
System.out.println(str);
//统计1
Integer var = con.reduce(5,(key,value)->{
return key;},(o1,o2)->{
return o1+o2;
});
System.out.println(var);
//统计2
Integer val = con.reduceEntries(5,entry->{
return entry.getKey();},
(o1,o2)->{
return o1+o2;
});
System.out.println(val);
}
}
11.泛型
Java 集合框架(Java Collections Framework)中的泛型是一种类型安全机制,它允许程序员在集合中存储任何类型的对象,同时仍然保持类型检查。泛型在 Java 5 中引入,极大地增强了 Java 编程语言的类型安全性和表达力。
泛型主要通过以下几个关键字来实现:
-
泛型类型参数:在集合接口和类中,尖括号(<>)中的类型参数表示集合可以存储的类型。例如,
List<Integer>表示一个存储Integer对象的列表。 -
泛型方法:泛型方法允许在不知道具体类型的情况下执行操作。它通过在方法签名中使用类型参数来实现。例如,
Collections.sort(list)中的list可以是任何类型的List。 -
限定泛型:使用
extends和super关键字可以限定泛型的类型参数。例如,List<Integer>表示存储Integer对象的列表,而List<? extends Number>表示存储任何Number子类型的列表。 -
通配符泛型:通配符
?可以用作泛型的占位符,提供更多的灵活性。例如,List<?>表示一个可以存储任何类型对象的列表。
12.Collections 集合的工具类
package day11;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
public class Collection {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(3);
//添加
Collections.addAll(list,4,5,6,7);
for (Integer as:list){
System.out.println(as);
}
//查询
int index=Collections.binarySearch(list,6);
System.out.println("位置:"+index);
//复制
ArrayList<Integer> list1 = new ArrayList<>();
Collections.addAll(list1,0,0,0,0,0);
Collections.copy(list1,list);
for (Integer at:list1){
System.out.println(at);
}
//最大值
int a=Collections.max(list);
System.out.println(a);
//最小值
int b=Collections.min(list);
System.out.println(b);
System.out.println("-------------");
//填充
Collections.fill(list1,20);
for (Integer at:list1){
System.out.println(at);
}
//反转
Collections.reverse(list);
for (Integer as:list){
System.out.println(as);
}
//替换
Collections.replaceAll(list,6,29);
for (Integer as:list){
System.out.println(as);
}
//打乱顺序
System.out.println("--------");
Collections.shuffle(list);
for (Integer as:list){
System.out.println(as);
}
System.out.println("-------");
//排序(降序,升序)
Collections.sort(list, new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1-o2;
}
});
for (Integer as:list){
System.out.println(as);
}
System.out.println("--------");
//换位
Collections.swap(list,1,3);
for (Integer as:list){
System.out.println(as);
}
//转换为线程安全的列表
List<Integer> list2=Collections.synchronizedList(list);
}
}
13.总结
以上就是我个人对集合的一些理解和总结,如有描述不到之处,请批评指正。















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









