







main函数里什么都没有,想起来之前一个题elf会先运行init函数
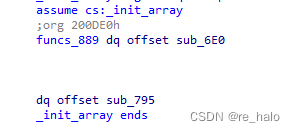




给的数据以小端序存储,不过shift+e时候不需要考虑

会是上一字节溢出的给了下一位
python好像不好处理溢出的问题,再看看
# data='zer0pts{********CENSORED********}'
# data2=[0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x42, 0x09,
# 0x4A, 0x49, 0x35, 0x43, 0x0A, 0x41, 0xF0, 0x19, 0xE6, 0x0B,
# 0xF5, 0xF2, 0x0E, 0x0B, 0x2B, 0x28, 0x35, 0x4A, 0x06, 0x3A,
# 0x0A, 0x4F, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00]
# for i in range(len(data)):
# tem=(ord(data[i])+data2[i])&0xff
# print(chr((tem)),end='')
data='zer0pts{********CENSORED********}'
data2=[0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x42, 0x09,
0x4A, 0x49, 0x35, 0x43, 0x0A, 0x41, 0xF0, 0x19, 0xE6, 0x0B,
0xF5, 0xF2, 0x0E, 0x0B, 0x2B, 0x28, 0x35, 0x4A, 0x06, 0x3A,
0x0A, 0x4F, 0x00]
f=0
for i in range(len(data)):
if f!=0:
tem = ord(data[i]) + data2[i]+f
f=0
else:
tem=ord(data[i])+data2[i]
if tem>0xff:
f=1
tem&=0xff
print(chr((tem)),end='')回头来看,还是对于那个 字符串转 qword 有点迷糊
嗯,像这些字符转化,确实用 C 好写一些
#include <iostream>
using namespace std;
int main() {
char enc[] = "zer0pts{********CENSORED********}";
uint64_t qword[] = {0, 0x410A4335494A0942, 0x0B0EF2F50BE619F0, 0x4F0A3A064A35282B, 0};
for (int i = 0; i < 5; i++) {
//(uint64_t)(enc[8 * i]) += qword[i]; left can't change
*(uint64_t*)&(enc[8 * i]) += qword[i];
//不直接写 p[8*j]是因为要将字符串转成 __int64 , so use pointer
}
cout << enc;
return 0;
}
// &(enc[8 * i]) 获取 enc 字符串中从第 8 * i 字节开始的地址。
//(uint64_t*)&(enc[8 * i]) 将这个地址强制转换为指向 uint64_t 类型的指针。
// * (uint64_t*)&(enc[8 * i]) 解引用这个指针,获取从 enc 的 8 * i 字节开始的8字节数据。是直接操作内存的,通过指针处理
target = "zer0pts{********CENSORED********}"
target = map(ord, target)
nums = []
for i in range(0, len(target), 8):
tmp = target[i:i+8]
num = 0
try:
for j in range(8):
num += tmp[j] << j * 8
except:
pass
nums.append(num)
res = []
qword_201060 = [0, 0x410A4335494A0942, 0xB0EF2F50BE619F0, 0x4F0A3A064A35282B, 0]
for i in range(5):
res.append(qword_201060[i] + nums[i])
flag = ''
for i in range(5):
tmp = "%016X" % res[i]
for j in range(14, -1, -2):
flag += chr(int(tmp[j:j+2], 16))
print flag.strip('\x00')而python 分块后要通过位操作,逆序提取字节(使其与内存布局一样)
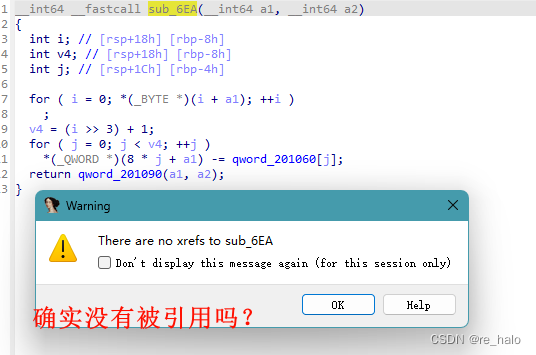
# for ( i = 0; *(_BYTE *)(i + flag); ++i )
# ;
# v4 = (i >> 3) + 1; #####calender team number
# for ( j = 0; j < v4; ++j ) ## deal every a team
# ^^ *(_QWORD *)(8 * j + flag) -= qword_201060[j];
# return qword_201090(flag, enc);
# }
enc='zer0pts{********CENSORED********}'
encdate=list(map(ord,enc))
print(encdate)
print(len(encdate))
nums=[]
for i in range(0,len(encdate),8):
tmp=encdate[i:i+8] # 8 char -- a team
#print(tmp)
num=0
# every team change into a int
try:
for j in range(8):
num+=tmp[j]<<j*8 # left move j*8 site
#为了将字符 tmp[j] 放到 64 位整数中的正确位置
#将 8 个字符的 ASCII 值按照其在 64 位整数中的位置排列起来,形成一个唯一的 64 位整数表示这 8 个字符的组合
except:
pass
nums.append(num)
res=[]
qword=[0, 0x410A4335494A0942, 0x0B0EF2F50BE619F0, 0x4F0A3A064A35282B, 0]
for i in range(5):
res.append(qword[i]+nums[i])
flag=''
for i in range(5):
# 64 位整数转换为 16 进制字符串
tmp="%016X" % res[i]
print(tmp)
# 7B7374703072657A
for j in range(14,-1,-2):
flag+=chr(int(tmp[j:j+2],16))
print(flag)
#移除 flag 字符串开头和结尾的空字节(\x00)(espacially deal with num including zero)
print(flag.strip('\x00'))















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









