1.Spring
1.1什么是Spring框架?
Spring
是⼀种轻量级开发框架,旨在提⾼开发⼈员的开发效率以及系统的可维护性。
Spring 的 6 个特征:核⼼技术,测试,数据访问,Web⽀持,集成,语⾔
1.2列举⼀些重要的Spring模块?
Spring Core
:
基础
,
可以说
Spring
其他所有的功能都需要依赖于该类库。主要提供
IoC
依
赖注⼊功能。
Spring Aspects
: 该模块为与
AspectJ
的集成提供⽀持。
Spring AOP
:提供了⾯向切⾯的编程实现。
Spring JDBC
: Java
数据库连接。
Spring JMS
:
Java
消息服务。
Spring ORM
:
⽤于⽀持
Hibernate
等
ORM
⼯具。
Spring Web
:
为创建
Web
应⽤程序提供⽀持。
Spring Test
:
提供了对
JUnit
和
TestNG
测试的⽀持
1.3@RestController vs @Controller
Controller
返回⼀个⻚⾯
单独使⽤
@Controller
不加
@ResponseBody
的话⼀般使⽤在要返回⼀个视图的情况,这种情况
属于⽐传统的
Spring MVC
的应⽤,对应于前后端不分离的情况。
@RestController
返回
JSON
或
XML
形式数据
但
@RestController
只返回对象,对象数据直接以
JSON
或
XML
形式写⼊
HTTP
响应
(Response)
中,这种情况属于
RESTful Web
服务,这也是⽬前⽇常开发所接触的最常⽤的情况
(前后端分离)。
@Controller +@ResponseBody
返回
JSON
或
XML
形式数据
如果你需要在
Spring4
之前开发
RESTful Web
服务的话,你需要使⽤
@Controller
并结
合
@ResponseBody
注解,也就是说
@Controller
+
@ResponseBody
=
@RestController
(
Spring 4
之后新加的注解)。
@ResponseBody将对象转换成JSON 或者XML形式
@ResponseBody
注解的作⽤是将
Controller
的⽅法返回的对象通过适当的转换器转换为指
定的格式之后,写⼊到
HTTP
响应
(Response)
对象的
body
中,通常⽤来返回
JSON
或者
XML
数据,返回
JSON
数据的情况⽐较多。
1.4Spring IOC & AOP
IOC
IoC(
Inverse of Control:
控制反转)是⼀种
设计思想
,就是
将原本在程序中⼿动创建对象的控制
权,交由
Spring
框架来管理。
IoC
容器是
Spring
⽤来实现
IoC
的载体,
IoC
容器实际上就是个
Map
(
key
,
value
)
,Map
中存放的是各
种对象。
将对象之间的相互依赖关系交给 IoC
容器来管理,并由
IoC 容器完成对象的注⼊。
IoC
容器就像是⼀个⼯⼚⼀
样,当我们需要创建⼀个对象的时候,只需要配置好配置⽂件
/
注解即可,完全不⽤考虑对象是如
何被创建出来的。
AOP
AOP(Aspect-Oriented Programming:⾯向切⾯编程
)
能够将那些与业务⽆关,
却为业务模块所共
同调⽤的逻辑或责任(例如事务处理、⽇志管理、权限控制等)封装起来
,便于
减少系统的重复
代码
,
降低模块间的耦合度
,并
有利于未来的可拓展性和可维护性
。
Spring AOP就是基于动态代理的
,如果要代理的对象,实现了某个接⼝,那么
Spring AOP
会使⽤JDK Proxy(动态代理)
,去创建代理对象,⽽对于没有实现接⼝的对象,
这时候
Spring AOP
会使⽤
Cglib
⽣成⼀个被代理对象的⼦类来作为代理
1.5Spring AOP 和 AspectJ AOP 有什么区别?
Spring AOP 属于运⾏时增强,⽽
AspectJ
是编译时增强。
Spring AOP
基于代理
(Proxying)
,⽽ AspectJ
基于字节码操作
(Bytecode Manipulation)
。
Spring AOP 已经集成了
AspectJ
,
AspectJ
应该算的上是
Java
⽣态系统中最完整的
AOP
框
架了。
AspectJ
相⽐于
Spring AOP
功能更加强⼤,但是
Spring AOP
相对来说更简单,如果我们的切⾯⽐较少,那么两者性能差异不⼤。但是,当切⾯太多的话,最好选择 AspectJ
,它⽐Spring AOP
快很多。
1.6Spring 中的 bean 的作⽤域有哪些?
singleton :
唯⼀
bean
实例,
Spring
中的
bean
默认都是单例的。
prototype :
每次请求都会创建⼀个新的
bean
实例。
request :
每⼀次
HTTP
请求都会产⽣⼀个新的
bean
,该
bean
仅在当前
HTTP request
内有
效。
session :
每⼀次
HTTP
请求都会产⽣⼀个新的
bean
,该
bean
仅在当前
HTTP session
内有
效。
global-session
: 全局
session
作⽤域,仅仅在基于
portlet
的
web
应⽤中才有意义,
Spring5
已
经没有了。
Portlet
是能够⽣成语义代码
(
例如:
HTML)
⽚段的⼩型
Java Web
插件。它们基于
portlet
容器,可以像
servlet
⼀样处理
HTTP
请求。但是,与
servlet
不同,每个
portlet
都有不
同的会话
1.7Spring 中的单例 bean 的线程安全问题了解吗?
单例
bean
存在线程问题,主要是因为当多个线程操作同⼀个对象的时候,对这个对象的⾮静态成员变量的写操作会存在线程安全问题。
常⻅的有两种解决办法:
1.
在
Bean
对象中尽量避免定义可变的成员变量(不太现实)。
2.
在类中定义⼀个
ThreadLocal
成员变量,将需要的可变成员变量保存在
ThreadLocal
中(推
荐的⼀种⽅式)。
1.8@Component 和 @Bean 的区别是什么?
1.
作⽤对象不同
:
@Component
注解作⽤于类,⽽
@Bean
注解作⽤于⽅法。
2.
@Component
通常是通过类路径扫描来⾃动侦测以及⾃动装配到
Spring
容器中(我们可以使
⽤
@ComponentScan
注解定义要扫描的路径从中找出标识了需要装配的类⾃动装配到
Spring
的
bean
容器中)。
@Bean
注解通常是我们在标有该注解的⽅法中定义产⽣这个
bean,
@Bean
告诉了
Spring
这是某个类的示例,当我需要⽤它的时候还给我。
3.
@Bean
注解⽐
Component
注解的⾃定义性更强,⽽且很多地⽅我们只能通过
@Bean
注
解来注册
bean
。⽐如当我们引⽤第三⽅库中的类需要装配到
Spring
容器时,则只能通过
@Bean
来实现。
1.9将⼀个类声明为Spring的 bean 的注解有哪些?
我们⼀般使⽤
@Autowired
注解⾃动装配
bean
,要想把类标识成可⽤于
@Autowired
注解⾃动
装配的
bean
的类
,
采⽤以下注解可实现:
@Component
:通⽤的注解,可标注任意类为
Spring
组件。如果⼀个
Bean
不知道属于哪
个层,可以使⽤
@Component
注解标注。
@Repository
:
对应持久层即
Dao
层,主要⽤于数据库相关操作。
@Service
:
对应服务层,主要涉及⼀些复杂的逻辑,需要⽤到
Dao
层。
@Controller
:
对应
Spring MVC
控制层,主要⽤户接受⽤户请求并调⽤
Service
层返回数
据给前端⻚⾯。
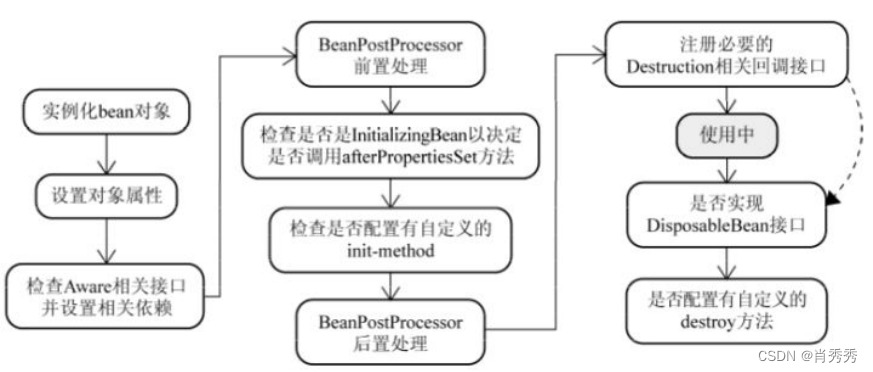
1.10Spring 中的 bean ⽣命周期?
Bean
容器找到配置⽂件中
Spring Bean
的定义。
Bean
容器利⽤
Java Reflection API
创建⼀个
Bean
的实例。如果涉及到⼀些属性值 利⽤ set()
⽅法设置⼀些属性值。
如果
Bean
实现了
BeanNameAware
接⼝,调⽤
setBeanName()
⽅法,传⼊
Bean
的名字。
如果
Bean
实现了
BeanClassLoaderAware
接⼝,调⽤
setBeanClassLoader()
⽅法,传⼊ ClassLoader 对象的实例。
与上⾯的类似,如果实现了其他
*.Aware
接⼝,就调⽤相应的⽅法。
如果有和加载这个
Bean
的
Spring
容器相关的
BeanPostProcessor
对象,执
⾏
postProcessBeforeInitialization()
⽅法
如果
Bean
实现了
InitializingBean
接⼝,执⾏
afterPropertiesSet()
⽅法。
如果
Bean
在配置⽂件中的定义包含
init-method
属性,执⾏指定的⽅法。
}
如果有和加载这个
Bean
的
Spring
容器相关的
BeanPostProcessor
对象,执⾏ postProcessAfterInitialization()
⽅法
当要销毁
Bean
的时候,如果
Bean
实现了
DisposableBean
接⼝,执⾏
destroy()
⽅法。
当要销毁
Bean
的时候,如果
Bean
在配置⽂件中的定义包含
destroy-method
属性,执⾏指
定的⽅法。
1.11说说⾃⼰对于 Spring MVC 了解?
MVC(Model View Controller)
是⼀种设计模式,Spring MVC
是⼀款很优秀的
MVC
框架。
Spring MVC
可以帮助我们进⾏更简洁的Web
层的开发,并且它天⽣与
Spring
框架集成。
Spring MVC
下我们⼀般把后端项⽬分为 Service
层(处理业务)、
Dao
层(数据库操作)、
Entity
层(实体类)、
Controller
层
(
控制层,返回数据给前台⻚⾯)
1.12SpringMVC ⼯作原理了解吗?
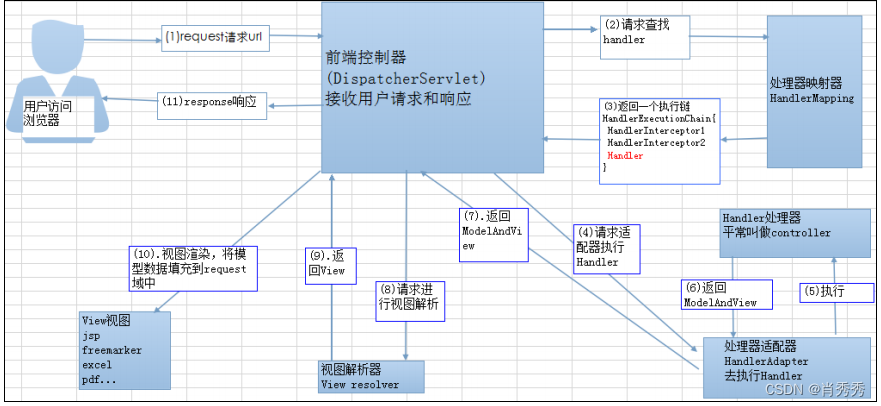
1.
客户端(浏览器)发送请求,直接请求到
前端控制器
。
2. 前端控制器根据请求信息调⽤ HandlerMapping
,解析请求对应的
Handler
。
3.
解析到对应的
Handler
(也就是我们平常说的
Controller
控制器)后,开始由HandlerAdapter 适配器处理。
4.
HandlerAdapter
会根据
Handler
来调⽤真正的处理器(controller)来处理请求,并处理相应的业务逻辑。
5.
处理器处理完业务后,会返回⼀个
ModelAndView
对象,
Model
是返回的数据对象, View
是个逻辑上的
View
。
6.
ViewResolver
会根据逻辑
View
查找实际的
View
。
7. 前端控制器把返回的 Model
传给
View
(视图渲染)。
8.
把
View
返回给请求者(浏览器)
1.13Spring 框架中⽤到了哪些设计模式?
⼯⼚设计模式
: Spring
使⽤⼯⼚模式通过
BeanFactory
、
ApplicationContext
创建
bean
对
象。
代理设计模式
: Spring AOP
功能的实现。
单例设计模式
: Spring
中的
Bean
默认都是单例的。
包装器设计模式
:
我们的项⽬需要连接多个数据库,⽽且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
观察者模式
:
Spring
事件驱动模型就是观察者模式很经典的⼀个应⽤。
适配器模式
:Spring AOP
的增强或通知
(Advice)
使⽤到了适配器模式、
spring MVC
中也是⽤
到了适配器模式适配
Controller
。
1.14Spring 管理事务的⽅式有⼏种?
1.
编程式事务,在代码中硬编码。
(
不推荐使⽤
)
2.
声明式事务,在配置⽂件中配置(推荐使⽤)
声明式事务⼜分为两种:
1.
基于
XML
的声明式事务
2.
基于注解的声明式事务
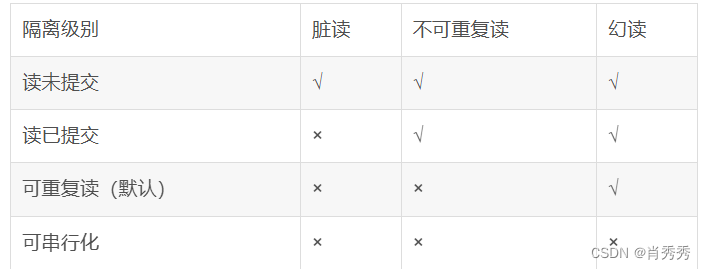
1.15Spring 事务中的隔离级别有哪⼏种?
1.16Spring 事务中哪⼏种事务传播⾏为?
事务传播行为,指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。
⽀持当前事务的情况:
REQUIRED(required)
: 如果当前存在事务,则加⼊该事务;如果当前没有事务,则创建⼀个新的事务。不管有几个事务存在,都合并成一个事务来处理,只要有一个事务抛出异常,所有事务都会回滚;
SUPPORTS(supports)
: 如果当前存在事务,则加⼊该事务;如果当前没有事务,则以⾮事务的⽅式继续运⾏。如果哥哥有一个苹果,我就吃哥哥的苹果,如果哥哥没有苹果,那我也没得吃;
MANDATORY(mandatory)
:
如果当前存在事务,则加⼊该事务;如果当前没有事务,则抛出异常。(mandatory
:强制性)
不⽀持当前事务的情况:
REQUIRES_NEW(requires-new)
:
创建⼀个新的事务,如果当前存在事务,则把当前事务挂起。
NOT_SUPPORTED(not-supported)
:
以⾮事务⽅式运⾏,如果当前存在事务,则把当前事务挂起。
NEVER(never)
:
以⾮事务⽅式运⾏,如果当前存在事务,则抛出异常。
其他情况:
NESTED(nested)
: 如果当前存在事务,则创建⼀个事务作为当前事务的嵌套事务来运⾏;如果当前没有事务,则该取值等价于REQUIRED.如果哥哥吃苹果吃出毛病了(代码抛异常了),那我和哥哥都会回到原点(回滚),如果我吃苹果吃出毛病了(代码抛异常了),那就只有我会回到原点(回滚);
1.17@Transactional(rollbackFor = Exception.class)注解了解吗?
@Transactional
注解作⽤于类上时,该类的所有
public
⽅法将都具有该类型的事务属性,同
时,我们也可以在⽅法级别使⽤该标注来覆盖类级别的定义。如果类或者⽅法加了这个注解,那
么这个类⾥⾯的⽅法抛出异常,就会回滚,数据库⾥⾯的数据也会回滚。
在
@Transactional
注解中如果不配置
rollbackFor
属性
,
那么事物只会在遇到
RuntimeException
的时候才会回滚,
加上
rollbackFor=Exception.class
,
可以让事物在遇到⾮运⾏时异常时也回滚。
1.18如何使⽤JPA在数据库中⾮持久化⼀个字段?
字段不被持久化,也就是不被数据库存储.
1.static String transient1; // not persistent because of static
2.final String transient2 = “Satish”; // not persistent because of final
3.transient String transient3; // not persistent because of transient(不被序列化)
4.@Transient
String transient4; // not persistent because of @Transient
2.MyBatis
2.1#{}和${}的区别是什么?
${} 是
Properties
⽂件中的变量占位符,它可以⽤于标签属性值和
sql
内部,属于静态⽂
本替换,⽐如
${driver}
会被静态替换为
com.mysql.jdbc.Driver
。
#{} 是
sql
的参数占位符,
Mybatis
会将
sql
中的
#{}
替换为
?
号,在
sql
执⾏前会使⽤
PreparedStatement
的参数设置⽅法,按序给
sql
的
?
号占位符设置参数值,⽐如
ps.setInt(0, parameterValue)
,
#{item.name}
的取值⽅式为使⽤反射从参数对象中获取
item
对象的
name
属性值,相当于
param.getItem().getName()
。
2.2Xml 映射⽂件中,除了常⻅的 select|insert|updae|delete 标签之外,还有哪些标签?
<resultMap>
、
<parameterMap>
、
<sql>
、
<include>
、
<selectKey>
,加上动态
sql
的
9
个标签,
trim|where|set|foreach|if|choose|when|otherwise|bind
等,其中
sql
⽚段标签,通过
<include>
标签引⼊
sql
⽚段,
<selectKey>
为不⽀持⾃增的主键⽣成策略标签。
2.3最佳实践中,通常⼀个 Xml 映射⽂件,都会写⼀个 Dao 接⼝与之对应,请问,这个 Dao 接⼝的⼯作原理是什么?Dao 接⼝⾥的⽅法,参数不同时,⽅法能重载吗?
Dao
接⼝,就是⼈们常说的
Mapper
接⼝,接⼝的全限名,就是映射⽂件中的
namespace的值,接⼝的⽅法名,就是映射⽂件中 MappedStatement
的
id
值,接⼝⽅法内的参数,就是传递给 sql
的参数。
Mapper
接⼝是没有实现类的,当调⽤接⼝⽅法时,接⼝全限名
+
⽅法名拼接字符
串作为
key
值,可唯⼀定位⼀个 MappedStatement.
在
Mybatis
中,每⼀个
<select>
、
<insert>
、
<update>
、
<delete>
标签,都会被解析为⼀
个
MappedStatement
对象
Dao
接⼝⾥的⽅法,是不能重载的,因为是全限名
+
⽅法名的保存和寻找策略。
Dao
接⼝的⼯作原理是
JDK
动态代理,
Mybatis
运⾏时会使⽤
JDK
动态代理为
Dao
接⼝⽣成代
理
proxy
对象,代理对象
proxy
会拦截接⼝⽅法,转⽽执⾏
MappedStatement
所代表的
sql
,然后将 sql
执⾏结果返回。
2.4Mybatis 是如何进⾏分⻚的?分⻚插件的原理是什么?
Mybatis
使⽤
RowBounds
对象进⾏分⻚,它是针对
ResultSet
结果集执⾏的内存分⻚,⽽
⾮物理分⻚,可以在
sql
内直接书写带有物理分⻚的参数来完成物理分⻚功能,也可以使⽤分⻚
插件来完成物理分⻚。
分⻚插件的基本原理是使⽤
Mybatis
提供的插件接⼝,实现⾃定义插件,在插件的拦截⽅法内拦
截待执⾏的 sql
,然后重写
sql
,根据
dialect
⽅⾔,添加对应的物理分⻚语句和物理分⻚参数。
2.5简述 Mybatis 的插件运⾏原理,以及如何编写⼀个插件
Mybatis 仅可以编写针对ParameterHandler 、
ResultSetHandler 、 StatementHandler 、
Executor
这
4
种接⼝的插件,Mybatis 使⽤
JDK
的动态代理,为需要拦截的接⼝⽣成代理对象以实现接⼝⽅法拦截功能,每当执⾏这 4
种接⼝对象的⽅法时,就会进⼊拦截⽅法,具体就是
InvocationHandler 的 invoke() ⽅
法,当然,只会拦截那些你指定需要拦截的⽅法。
实现 Mybatis
的
Interceptor
接⼝并复写
intercept()
⽅法,然后在给插件编写注解,指定要拦截哪⼀个接⼝的哪些⽅法即可,记住,别忘了在配置⽂件中配置你编写的插件。
2.6Mybatis 执⾏批量插⼊,能返回数据库主键列表吗?
在mysql数据库中支持批量插入,所以只要配置useGeneratedKeys(true)和keyProperty(主键字段)就可以批量插入并返回主键了。
2.7Mybatis 动态 sql 是做什么的?都有哪些动态 sql?能简述⼀下动态 sql 的执⾏原理不?
Mybatis
动态
sql
可以让我们在
Xml
映射⽂件内,以标签的形式编写动态
sql
,完成逻辑判断
和动态拼接
sql
的功能,
Mybatis
提供了
9
种动态
sql
标签trim|where|set|foreach|if|choose|when|otherwise|bind 。
其执⾏原理为,使⽤
OGNL 从 sql 参数对象中计算表达式的值,根据表达式的值动态拼接 sql,
以此来完成动态 sql 的功能。
2.8Mybatis 是如何将 sql 执⾏结果封装为⽬标对象并返回的?都有哪些映射形式?
第⼀种是使⽤ <resultMap>
标签,逐⼀定义列名和对象属性名之间的映射关系。
第⼆种是使⽤ sql
列的别名功能,将列别名书写为对象属性名,⽐如
T_NAME AS NAME
,对象属性名⼀般是 name
,⼩写,但是列名不区分⼤⼩写,
Mybatis
会忽略列名⼤⼩写,智能找到与之对应对象属性名,你甚⾄可以写成 T_NAME AS NaMe
,
Mybatis
⼀样可以正常⼯作。
有了列名与属性名的映射关系后,Mybatis
通过反射创建对象,同时使⽤反射给对象的属性逐⼀赋值并返回,那些找不到映射关系的属性,是⽆法完成赋值的。
2.9Mybatis 能执⾏⼀对⼀、⼀对多的关联查询吗?都有哪些实现⽅式,以及它们之间的区别。
能,Mybatis
不仅可以执⾏⼀对⼀、⼀对多的关联查询,还可以执⾏多对⼀,多对多的关联查询,多对⼀查询,其实就是⼀对⼀查询,只需要把 selectOne()
修改为
selectList()
即可;多对多查询,其实就是⼀对多查询,只需要把 selectOne()
修改为
selectList()
即可。
关联对象查询,有两种实现⽅式,⼀种是单独发送⼀个 sql
去查询关联对象,赋给主对象,然后返回主对象。另⼀种是使⽤嵌套查询,嵌套查询的含义为使⽤ join
查询,⼀部分列是
A
对象的属性值,另外⼀部分列是关联对象 B
的属性值,好处是只发⼀个
sql
查询,就可以把主对象和其关
联对象查出来。
那么问题来了,join
查询出来
100
条记录,如何确定主对象是
5
个,⽽不是
100
个?其去重复的原理是 <resultMap>
标签内的
<id>
⼦标签,指定了唯⼀确定⼀条记录的
id
列,
Mybatis
根据列值来完成 100
条记录的去重复功能,
<id>
可以有多个,代表了联合主键的语意。同样主对象的关联对象,也是根据这个原理去重复的,尽管⼀般情况下,只有主对象会有重复记
录,关联对象⼀般不会重复
2.10Mybatis 是否⽀持延迟加载?如果⽀持,它的实现原理是什么?
Mybatis 仅⽀持
association
关联对象和
collection
关联集合对象的延迟加载,
association
指的就是⼀对⼀,collection
指的就是⼀对多查询。在
Mybatis
配置⽂件中,可以配置是否启⽤延
迟加载
lazyLoadingEnabled=true|false
它的原理是,使⽤
CGLIB
创建⽬标对象的代理对象,当调⽤⽬标⽅法时,进⼊拦截器⽅法,⽐如调⽤ a.getB().getName()
,拦截器
invoke()
⽅法发现
a.getB()
是
null
值,那么就会单独发送事先保存好的查询关联 B
对象的 sql
,把
B
查询上来,然后调⽤
a.setB(b)
,于是
a
的对象
b
属性就有值了,接着完成 a.getB().getName()
⽅法的调⽤。这就是延迟加载的基本原理。
2.11Mybatis 的 Xml 映射⽂件中,不同的 Xml 映射⽂件,id 是否可以重复?
不同的
Xml
映射⽂件,如果配置了
namespace
,那么
id
可以重复;如果没有配置namespace,那么
id
不能重复;毕竟
namespace
不是必须的,只是最佳实践⽽已。原因就是 namespace+id
是作为
Map<String, MappedStatement>
的
key
使⽤的,如果没有namespace,就剩下
id
,那么,
id
重复会导致数据互相覆盖。有了
namespace
,⾃然
id
就可以重复,namespace
不同,
namespace+id
⾃然也就不同。
2.12Mybatis 中如何执⾏批处理?
使⽤
BatchExecutor
完成批处理
2.13Mybatis 都有哪些 Executor 执⾏器?它们之间的区别是什么?
Mybatis
有三种基本的
Executor
执⾏器, SimpleExecutor
、
ReuseExecutor
、
BatchExecutor
。
SimpleExecutor
:
每执⾏⼀次
update
或
select
,就开启⼀个
Statement
对象,⽤完⽴刻关闭
Statement
对象。
ReuseExecutor
:
执⾏
update
或
select
,以
sql
作为
key
查找
Statement
对象,存在就使⽤, 不存在就创建,⽤完后,不关闭 Statement
对象,⽽是放置于
Map<String, Statement>
内,供下
⼀次使⽤。简⾔之,就是重复使⽤
Statement
对象。
BatchExecutor
:
执⾏
update
(没有
select
,
JDBC
批处理不⽀持
select
),将所有
sql
都添加
到批处理中(
addBatch()
),等待统⼀执⾏(
executeBatch()
),它缓存了多个
Statement
对象,每个 Statement
对象都是
addBatch()
完毕后,等待逐⼀执⾏
executeBatch()
批处理。与JDBC 批处理相同。
作⽤范围:
Executor
的这些特点,都严格限制在
SqlSession
⽣命周期范围内。
2.14Mybatis 中如何指定使⽤哪⼀种 Executor 执⾏器?
在
Mybatis
配置⽂件中,可以指定默认的
ExecutorType
执⾏器类型,也可以⼿动给
DefaultSqlSessionFactory
的创建
SqlSession
的⽅法传递
ExecutorType
类型参数。
2.15Mybatis 是否可以映射 Enum 枚举类?
Mybatis
可以映射枚举类,不单可以映射枚举类,
Mybatis
可以映射任何对象到表的⼀列上。映射⽅式为⾃定义⼀个 TypeHandler
,实现
TypeHandler
的
setParameter() 和
getResult() 接⼝⽅法。 TypeHandler
有两个作⽤,⼀是完成从
javaType
⾄
jdbcType
的转换,⼆是完成jdbcType ⾄
javaType
的转换,体现为
setParameter()
和
getResult()
两个⽅法,分别代表设置sql 问号占位符参数和获取列查询结果。
2.16Mybatis 映射⽂件中,如果 A 标签通过 include 引⽤了 B 标签的内容,请问,B 标签能否定义在 A 标签的后⾯,还是说必须定义在 A 标签的前⾯?
虽然
Mybatis
解析
Xml
映射⽂件是按照顺序解析的,但是,被引⽤的
B
标签依然可以定义
在任何地⽅,
Mybatis
都可以正确识别。
原理是,
Mybatis
解析
A
标签,发现
A
标签引⽤了
B
标签,但是
B
标签尚未解析到,尚不存在,此时,Mybatis
会将
A
标签标记为未解析状态,然后继续解析余下的标签,包含
B
标签,待所有标签解析完毕,Mybatis
会重新解析那些被标记为未解析的标签,此时再解析
A
标签时,
B标签已经存在,A
标签也就可以正常解析完成了。
2.17简述 Mybatis 的 Xml 映射⽂件和 Mybatis 内部数据结构之间的映射关系?
Mybatis
将所有
Xml
配置信息都封装到
All-In-One
重量级对象
Configuration
内部。在
Xml映射⽂件中, <parameterMap>
标签会被解析为
ParameterMap
对象,其每个⼦元素会被解析为
ParameterMapping
对象。
<resultMap>
标签会被解析为
ResultMap
对象,其每个⼦元素会被解析为
ResultMapping
对象。每⼀个
<select> <insert><update> <delete>
标签均会被解析为MappedStatement 对象,标签内的
sql
会被解析为
BoundSql
对象。
2.18为什么说 Mybatis 是半⾃动 ORM 映射⼯具?它与全⾃动的区别在哪⾥?
Hibernate
属于全⾃动
ORM
映射⼯具,使⽤
Hibernate
查询关联对象或者关联集合对象时,可以根据对象关系模型直接获取,所以它是全⾃动的。⽽ Mybatis
在查询关联对象或关联集合对象时,需要⼿动编写 sql
来完成,所以,称之为半⾃动
ORM
映射⼯具。
ORM框架是一种编程技术,它的目标是通过使用面向对象的语法来处理数据库操作,而不是使用传统的SQL查询
3.Kafka
3.1Kafka 是什么?主要应⽤场景有哪些?
Kafka
是⼀个分布式流式处理平台。
流平台具有三个关键功能:
1.
消息队列
:发布和订阅消息流,这个功能类似于消息队列,这也是
Kafka
也被归类为消息队
列的原因。
2.
容错的持久⽅式存储记录消息流
:
Kafka
会把消息持久化到磁盘,有效避免了消息丢失的⻛
险
·
。
3.
流式处理平台:
在消息发布的时候进⾏处理,
Kafka
提供了⼀个完整的流式处理类库。
Kafka
主要有两⼤应⽤场景:
1.
消息队列
:建⽴实时流数据管道,以可靠地在系统或应⽤程序之间获取数据。
2.
数据处理:
构建实时的流数据处理程序来转换或处理数据流。
3.2和其他消息队列相⽐,Kafka的优势在哪⾥?
1.
极致的性能
:基于
Scala
和
Java
语⾔开发,设计中⼤量使⽤了批量处理和异步的思想,最
⾼可以每秒处理千万级别的消息。
2.
⽣态系统兼容性⽆可匹敌
:
Kafka
与周边⽣态系统的兼容性是最好的没有之⼀,尤其在⼤数
据和流计算领域。
3.3队列模型了解吗?Kafka 的消息模型知道吗?
队列模型:早期的消息模型
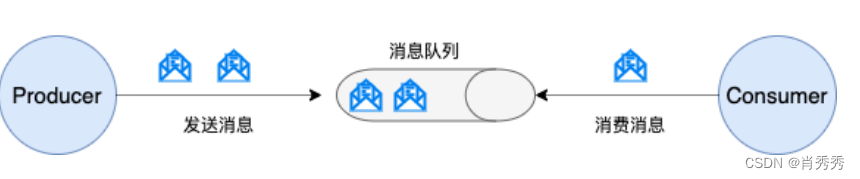
使⽤队列(
Queue
)作为消息通信载体,满⾜⽣产者与消费者模式,⼀条消息只能被⼀个消费者
使⽤,未被消费的消息在队列中保留直到被消费或超时。
不好解决的问题:
假如我们存在这样⼀种情况:我们需要将⽣产者产⽣的消息分发给多个消费者,并且每个消费者
都能接收到完成的消息内容。
发布
-
订阅模型
:Kafka
消息模型
在发布
-
订阅模型中,如果只有⼀个订阅者,那它和队列模型就基本是⼀样的了。所以说,发布
-
订阅模型在功能层⾯上是可以兼容队列模型的。
Kafka
采⽤的就是发布
-
订阅模型。
RocketMQ
的消息模型和
Kafka
基本是完全⼀样的。唯⼀的区别是
Kafka
中没有队列这个
概念,与之对应的是
Partition
(分区)。
3.4什么是Producer、Consumer、Broker、Topic、Partition?
Kafka
将⽣产者发布的消息发送到
Topic
(主题)
中,需要这些消息的消费者可以订阅这些
Topic
(主题)。
1.
Producer
(⽣产者)
:
产⽣消息的⼀⽅。
2.
Consumer
(消费者)
:
消费消息的⼀⽅。
3.
Broker
(代理)
:
可以看作是⼀个独⽴的
Kafka
实例。多个
Kafka Broker
组成⼀个
KafkaCluster。
4.Topic
(主题)
: Producer
将消息发送到特定的主题,
Consumer
通过订阅特定的
Topic(
主
题
)
来消费消息。
5.Partition
(分区)
: Partition
属于
Topic 的⼀部分,真正保存消息的地⽅。⼀个 Topic
可以有多个
Partition
,并且同⼀ Topic
下的
Partition
可以分布在不同的
Broker
上,这也就表明⼀个
Topic
可以横跨多个 Broker 。Kafka
中的
Partition
(分区) 实际上可以对应成为消息队列中的队列
3.5Kafka 的多副本机制了解吗?带来了什么好处?
分区(Partition
)中的多个副本之间会有⼀个叫做
leader
的家伙,其他副本称为
follower
。我们发送的消息会被发送到 leader
副本,然后
follower
副本才能从
leader
副本中拉取消息进⾏同步。
⽣产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷⻉,它
们的存在只是为了保证消息存储的安全性。当 leader 副本发⽣故障时会从 follower 中选举
出⼀个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞
选
Kafka
的多分区(
Partition
)以及多副本(
Replica
)机制有什么好处呢?
1. Kafka
通过给特定
Topic
指定多个
Partition,
⽽各个
Partition
可以分布在不同的
Broker
上
,
这样便能提供⽐较好的并发能⼒(负载均衡)。
2. Partition
可以指定对应的
Replica
数
,
这也极⼤地提⾼了消息存储的安全性
,
提⾼了容灾能
⼒,不过也相应的增加了所需要的存储空间。
3.6Zookeeper 在 Kafka 中的作⽤知道吗?
ZooKeeper
主要为
Kafka
提供元数据的管理的功能。
1.
Broker
注册
:在
Zookeeper
上会有⼀个专⻔
⽤来进⾏
Broker
服务器列表记录
的节点。每
个
Broker
在启动时,都会到
Zookeeper
上进⾏注册,即到
/brokers/ids
下创建属于⾃⼰的节点。每个 Broker
就会将⾃⼰的
IP
地址和端⼝等信息记录到该节点中去
2.
Topic
注册
: 在
Kafka
中,同⼀个
Topic
的消息会被分成多个分区
并将其分布在多个Broker 上,
这些分区信息及与
Broker
的对应关系
也都是由
Zookeeper
在维护。
3.
负载均衡
:上⾯也说过了
Kafka
通过给特定
Topic
指定多个
Partition,
⽽各个
Partition
可以
分布在不同的
Broker
上
,
这样便能提供⽐较好的并发能⼒。 对于同⼀个
Topic
的不同Partition,
Kafka
会尽⼒将这些
Partition
分布到不同的
Broker
服务器上。当⽣产者产⽣消息后也会尽量投递到不同 Broker
的
Partition
⾥⾯。当
Consumer
消费的时候,
Zookeeper
可以根据当前的 Partition
数量以及
Consumer
数量来实现动态负载均衡
3.7Kafka 如何保证消息的消费顺序?
每次添加消息到 Partition(
分区
)
的时候都会采⽤尾加法。
Kafka
只能为我们保证Partition(分区
)
中的消息有序,⽽不能保证
Topic(
主题
)
中的
Partition(
分区
) 的有序。
消息在被追加到
Partition(
分区
)
的时候都会分配⼀个特定的偏移量(
offset
)。
Kafka
通过偏
移量(
offset
)来保证消息在分区内的顺序性。
Kafka 中发送
1
条消息的时候,可以指定
topic, partition, key,data
(数据)
4
个参数。如果你发送消息的时候指定了 Partition
的话,所有消息都会被发送到指定的
Partition
。并且,同⼀个
key
的消息可以保证只发送到同⼀个
partition
,这个我们可以采⽤表
/
对象的
id
来作为
key
。
对于如何保证
Kafka
中消息消费的顺序,有了下⾯两种⽅法:
1. 1
个
Topic
只对应⼀个
Partition
。
2.
(推荐)发送消息的时候指定
key/Partition
3.8Kafka 如何保证消息不丢失
⽣产者丢失消息的情况
⽣产者
(Producer)
调⽤
send
⽅法发送消息之后,消息可能因为⽹络问题并没有发送过去。
1.Kafka
⽣产者
(Producer)
使⽤
send
⽅法发送消息实际上是异步的操作,我们可以通过 get()
⽅法获取调⽤结果,但是这样也让它变为了同步操作
2.为其添加回调函数的形式。如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
另外这⾥推荐为
Producer
的
retries
(重试次数)设置⼀个⽐较合理的值,⼀般是
3
,但是为
了保证消息不丢失的话⼀般会设置⽐较⼤⼀点。设置完成之后,当出现⽹络问题之后能够⾃动重
试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太⼩的话重试的效果就不
明显了,⽹络波动⼀次你
3
次⼀下⼦就重试完了
消费者丢失消息的情况
我们知道消息在被追加到
Partition(
分区
)
的时候都会分配⼀个特定的偏移量(
offset
)。偏移量 (offset)
表示
Consumer
当前消费到的
Partition(
分区
)
的所在的位置。
Kafka
通过偏移量 (offset
)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会⾃动提交
offset
。⾃动提交的话会有⼀个问题,当消费者刚拿到这个消息准备进⾏真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset
却被⾃动提交了。
解决办法也⽐较粗暴,我们⼿动关闭闭⾃动提交
offset
,每次在真正消费完消息之后之后再⾃⼰
⼿动提交
offset
。
但是,这样会带来消息被重新消费的问题。⽐如你刚刚消费完消息之后,还没提交 offset
,结果⾃⼰挂掉了,那么这个消息理论上就会被消费两次
Kafka
弄丢了消息
假如
leader
副本所在的
broker
突然挂掉,那么就要从
follower
副本重新选出
⼀个
leader
,但是
leader
的数据还有⼀些没有被
follower
副本的同步的话,就会造成消息丢
失。四步骤:
1.设置
acks = all
解决办法就是我们设置
acks = all
。
acks
是
Kafka
⽣产者
(Producer)
很重要的⼀个参数。acks 的默认值即为
1
,代表我们的消息被
leader
副本接收之后就算被成功发送。当我们配置
acks
= all
代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。
2.设置
replication.factor >= 3
为了保证
leader
副本能有
follower
副本能同步消息,我们⼀般会为
topic
设置
replication.factor
>= 3
。这样就可以保证每个分区
(partition) ⾄少有 3
个副本。虽然造成了数据冗余,但是带来了
数据的安全性。
3.设置
min.insync.replicas > 1
⼀般情况下我们还需要设置
min.insync.replicas> 1
,这样配置代表消息⾄少要被写⼊到
2 个副
本才算是被成功发送。
min.insync.replicas
的默认值为
1
,在实际⽣产中应尽量避免默认值1。
但是,为了保证整个
Kafka
服务的⾼可⽤性,你需要确保
replication.factor >
min.insync.replicas
。
为什么呢?设想⼀下加⼊两者相等的话,只要是有⼀个副本挂掉,整个分区就⽆法正常⼯作了。这明显违反⾼可⽤性!⼀般推荐设置成 replication.factor =
min.insync.replicas + 1
。
4.设置
unclean.leader.election.enable = false
多个
follower
副本之间的消息同步情况不⼀样,当我们配置了
unclean.leader.election.enable = false
的话,当
leader
副本发⽣故障时就不会从
follower
副本中和 leader
同步程度达不到要求的副本中选择出
leader
,这样降低了消息丢失的可能性。
3.9Kafka 如何保证消息不重复消费
生产端:
生产端发送消息后,假如遇到网络问题,无法获得响应,生产端就无法判断该消息是否成功提交到了 Kafka,而我们一般会配置重试次数,但这样会引发生产端重新发送同一条消息,从而造成消息重复的发送。
从 0.11.0 的版本开始,Kafka 给每个 producer 一个唯一 ID,并且在每条消息中生成一个 sequence num,sequence num是递增且唯一的这样就能对消息去重,达到 一个生产端不重复发送一条消息。但是这个方法是有局限性的,只在一个 生产端 内生产的消息有效,如果一个消息分别在两个 producer 发送就不行了,还是会造成消息的重复发送。但是这种可能性比较小,因为消息的重试一般会在一个生产端内进行。当然,对应一个消息分别在两个 producer 发送的请求我们也有方案,只是多做一些补偿的工作,我们可以为每一个消息分配一个全局id,并把全局id存放在远程缓存或关系型数据库里。这样在发送前判断一下是否已经发送过。
服务端:
服务端不会重复的存储消息,如果有重复消息也应该是生产端重复发送造成的,所以无需特别的配置。
消费端:
第一步,enable.auto.commit=false:
同样要避免自动提交偏移量,大家可以想象一种情况,消费端拉取消息和处理消息都完成了,但是自动提交偏移量还没提交这时消费端挂了,这时候kakfa消费组开始重平衡并把分区分给了另一个消费者,由于偏移量没提交新的消费者会重复拉取消息,最终造成重复消费消息。
第二步,单纯配成手动提交同样不能避免重复消费,需要消费端用正确姿势消费。
消费者拉取消息后,先提交 offset 后再处理消息。在提交 offset 之后,业务逻辑处理消息之前出现宕机,待消费者重新上线时,就无法读到刚刚已经提交而未处理的这部分消息,这就对应了不重复消费消息但是会有丢失消息的情况。
4.Netty
























 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









