






此文章涉及E-R图、范式、关系代数,及前三者中的各种知识点,想进行数据库简单设计的同学可以参考该文章。有一定基础的同学可以从第一章开始看,基础薄弱的同学可以先看第四章补充零碎的知识。
💬 欢迎讨论:如对文章内容有疑问或见解,欢迎在评论区留言,我需要您的帮助!
👍 点赞、收藏与分享:如果这篇文章对您有所帮助,请不吝点赞、收藏或分享,谢谢您的支持!
🚀 传播技术之美:期待您将这篇文章推荐给更多对需要学习数据库系统概论、低代码开发感兴趣的朋友,让我们共同学习、成长!
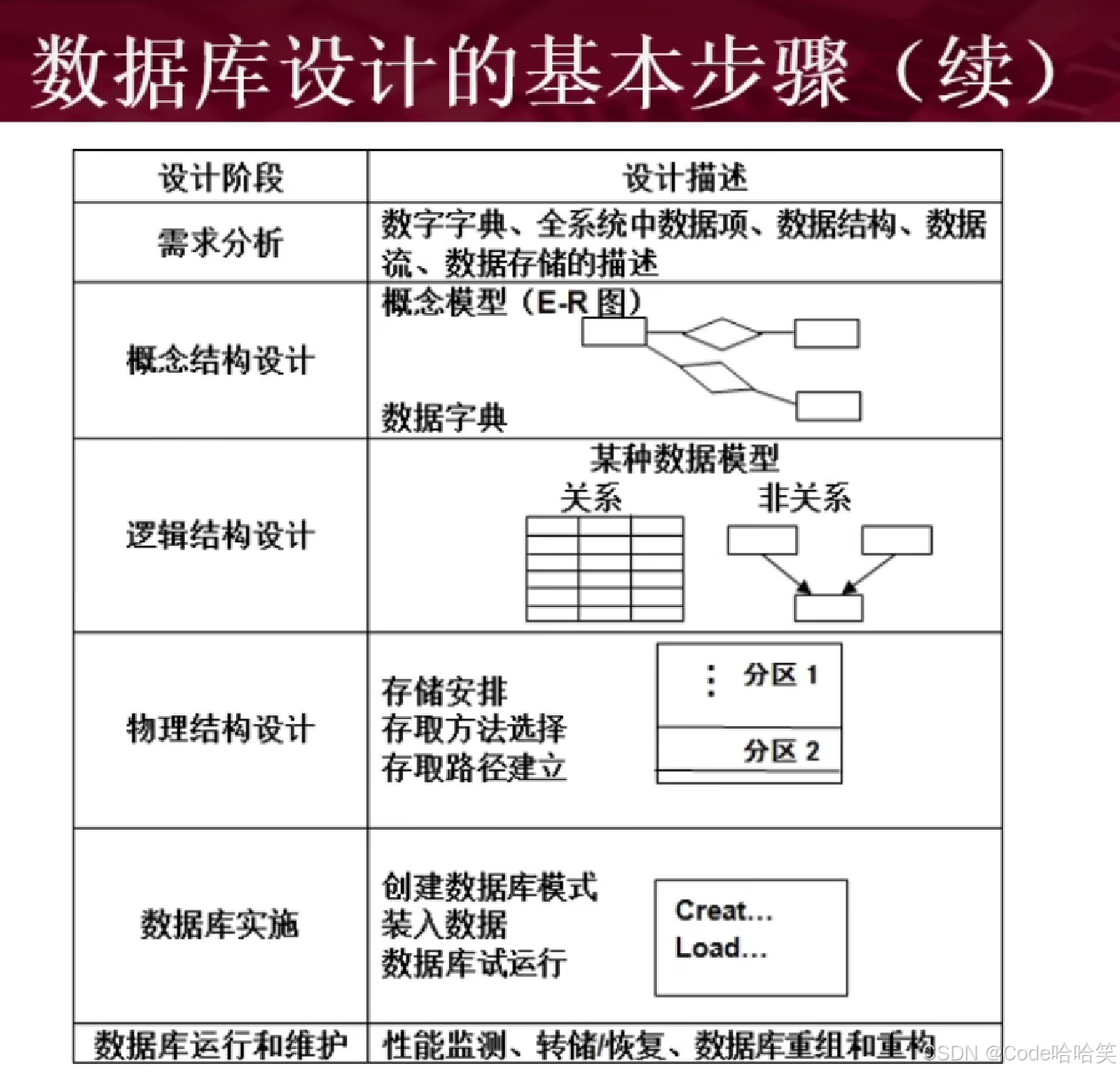
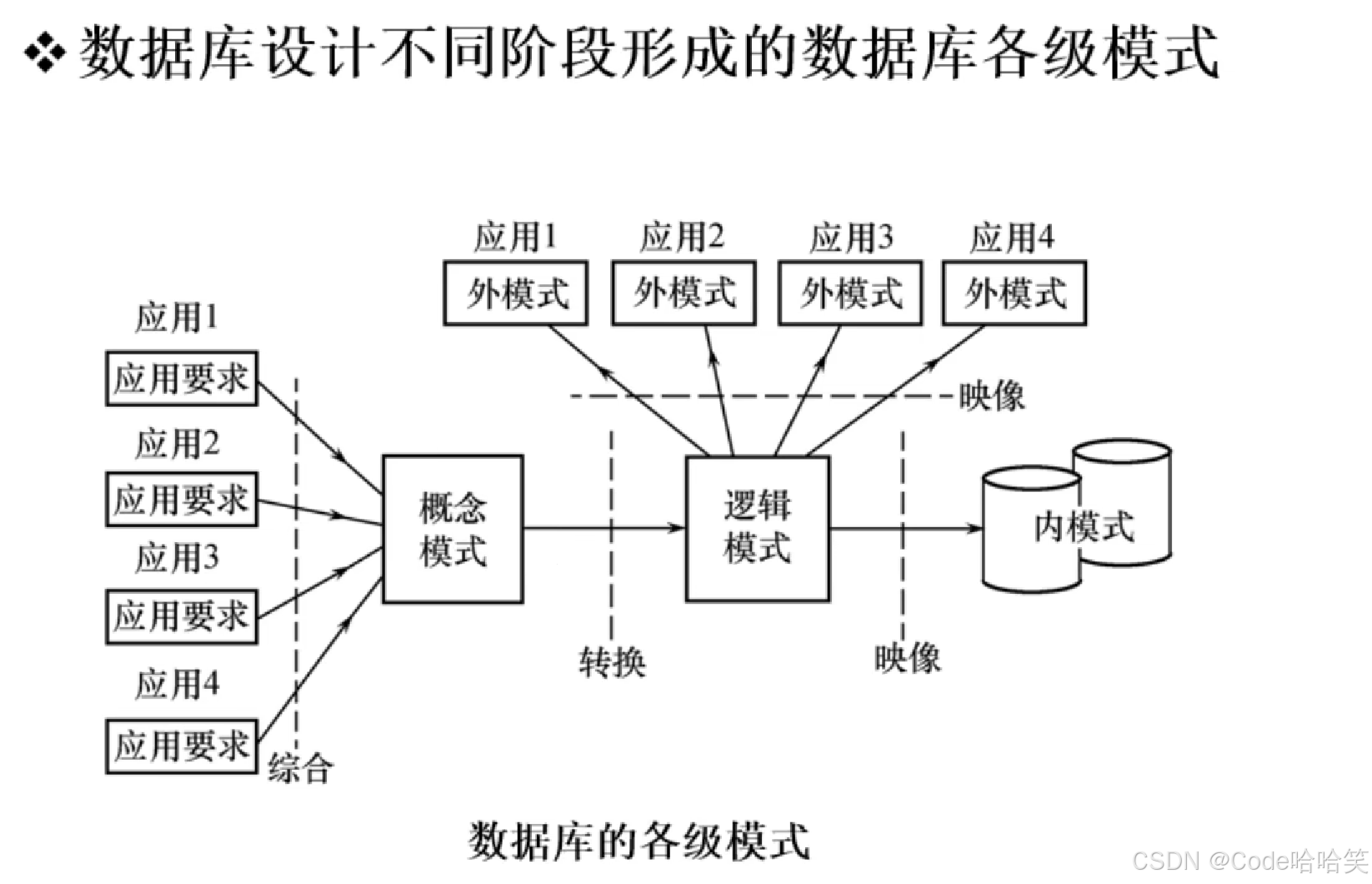
数据库的各级模式:
概念模式设计阶段:形成独立于机器特点,独立于各个数据库管理系统产品的概念模式(画E-R图)。
逻辑设计阶段:
- 首先将E-R图转换成具体的数据模型,如关系模型形成数据库的逻辑模式。
- 然后根据用户处理的要求、安全性的考虑,在基本表的基础上再建立必要的视图(View),形成数据的外模式(三范式)。
物理设计阶段:根据数据库管理系统特点和处理的需要,进行物理存储安排,建立索引,形成数据库内模式。
1. 概念结构设计
1.1 概念模型
将需求分析得到的用户需求抽象为信息结构(即概念模型)的过程就是概念结构设计。
概念模型的特点:
- 能真实、充分的反映现实世界,是现实世界的一个真实模型。
- 易于理解,从而可以用它和不熟悉计算机的用户交换意见。
- 易于更改,当应用环境与应用要求改变时吗,容易对概念模型修改和扩充。
- 易于向关系、网状、层次等各种数据模型转换
1.2 各实体之间的联系
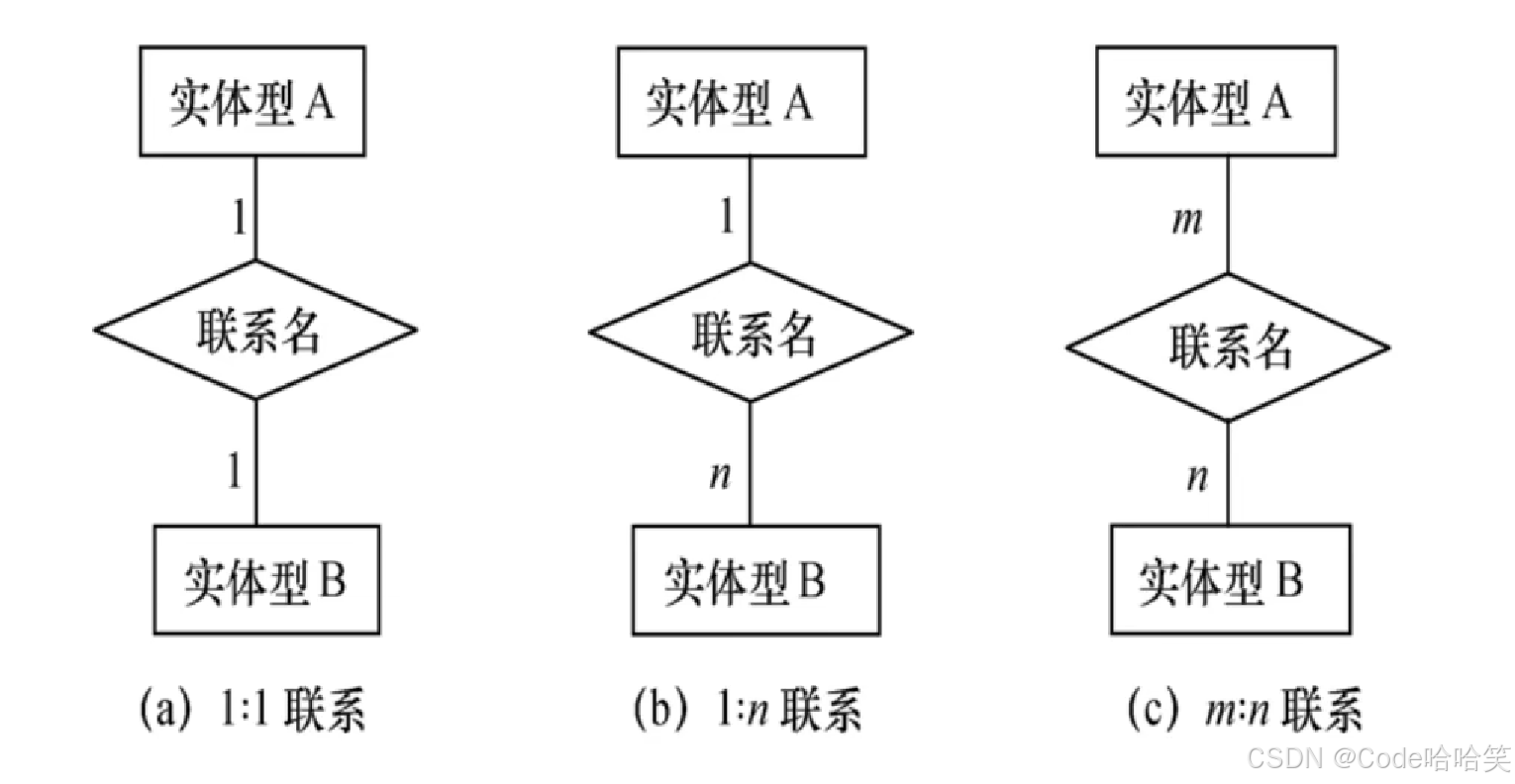
1.2.1 两实体之间的联系
- 一对一联系(1:1)

- 一对多联系(1:n)

- 多对多联系(m:n)

E-R模型:
1.2.2 两个以上实体 型之间的联系
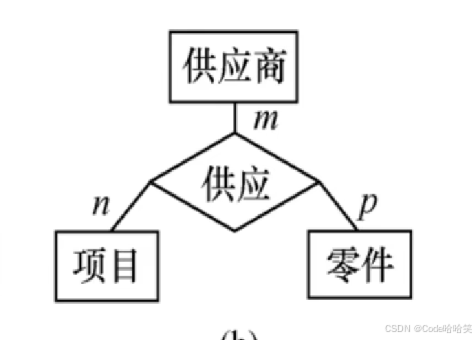
一般地,两个以上的实体型之间也存在着一对一、一对多、多对多的联系
比如:对于课程、教师与参考书3个实体型,如果一门课程可以有若干个教师讲授,使用若干本参考书,而每一个教师只讲授一门课程,每一本参考书只供一门课程使用,则课程与教师、参考书之间的联系是一对多的,如图

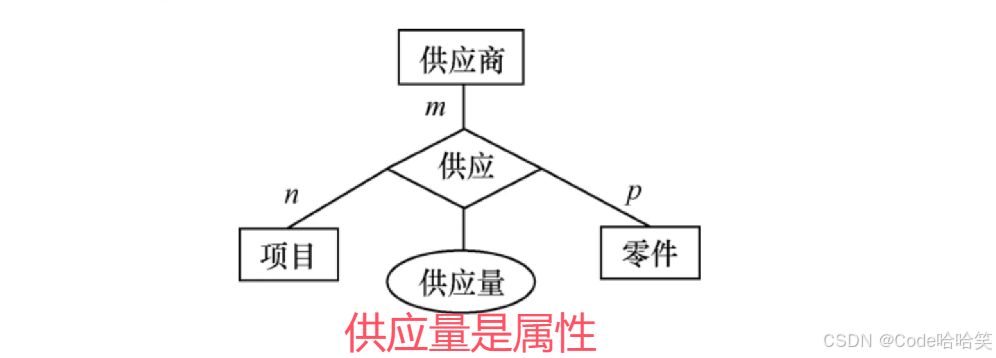
比如:对于供应商、项目、零件
1.2.3 单个实体内的一对多联系
比如:一个职工只能有一个直属领导,而一个领导能管理很多个职工,职工和领导都是职工。

1.2.4 联系的度
联系的度:参与联系的实体型的数目:
- 2个实体型之间的联系度为2,也称为二元联系;
- 3个实体型之间的联系度为3,称为三元联系;
- N个实体型之间的联系度为N,也称为N元联系。
1.2.5 实体的属性
E-R图提供了表示实体型、属性和联系的方法:
- 实体型:用矩形表示,矩形框内写明实体名。
- 属性:用椭圆形表示,并用无向边将其与相应的实体型连接起来。
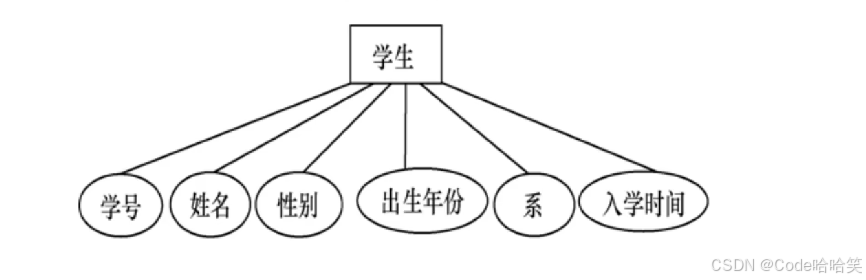
例如,学生实体具有学号、姓名、性别、出生年份、系、入学时间等属性,用E-R图表示如图所示:
1.2.6 联系的属性
联系:用菱形表示,菱形框内写明联系名,并用无向边分别与有关实体型连接起来,同时在无向边旁标上联系的类型(1:1,1∶n 或 m:n)
联系也可以具有属性
1.3 E-R 图 例题
实例:
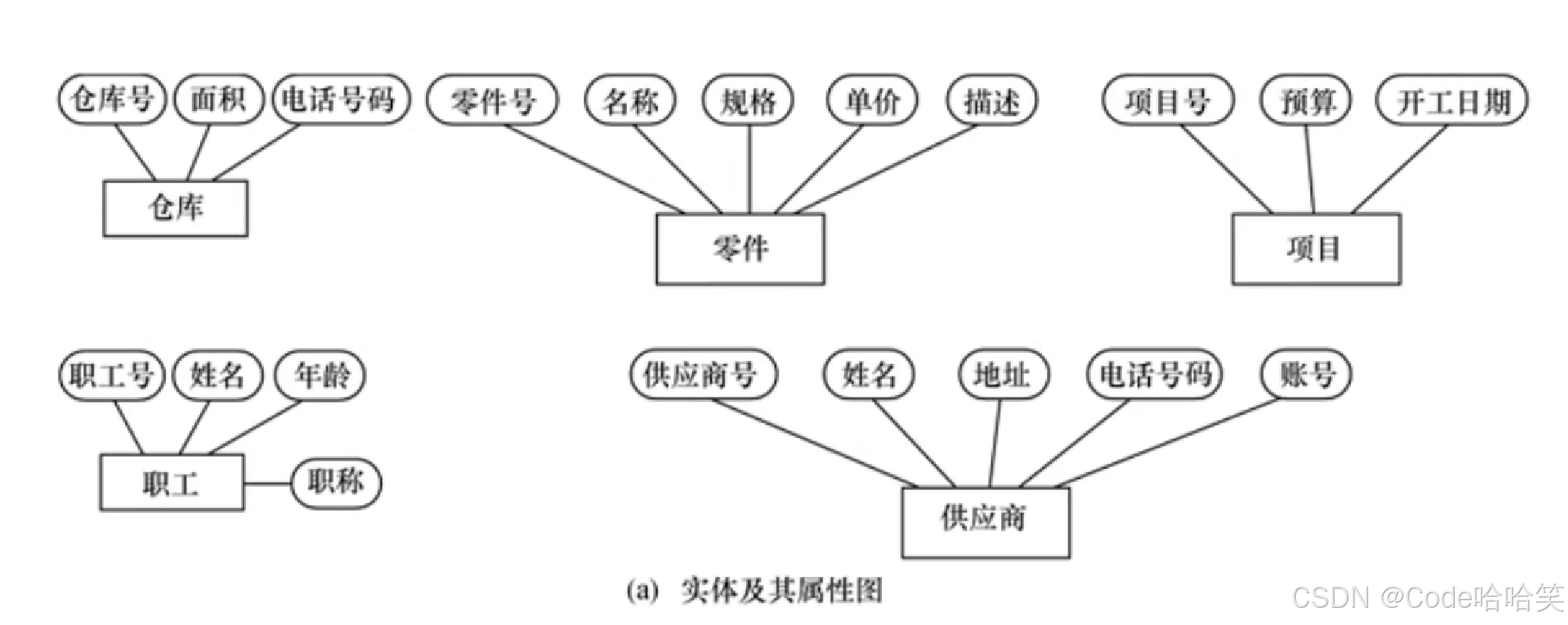
某个工厂物资管理的概念模型。物资管理涉及的实体有:
(1)仓库:属性有仓库号、面积、电话号码
(2)零件:属性有零件号、名称、规格、单价、描述
(3)供应商:属性有供应商号、姓名、地址、电话号码、账号
(4)项目:属性有项目号、预算、开工日期
(5)职工:属性有职工号、姓名、年龄、职称
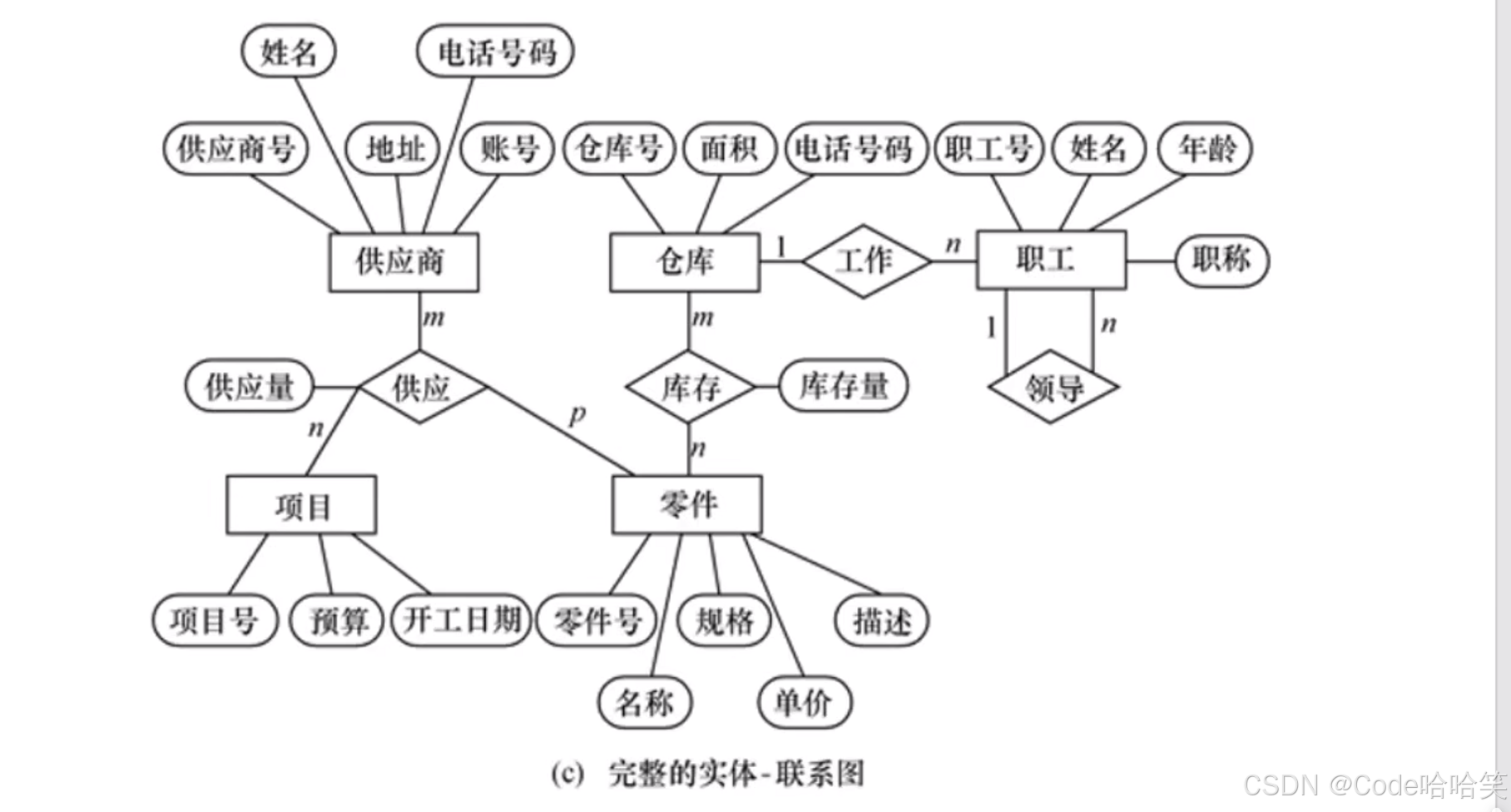
这些实体之间的联系如下:
(1)一个仓库可以存放多种零件,一种零件可以存放在多个仓库中,因此仓库和零件具有多对多的联系。用库存量来表示某种零件在某个仓库中的数量。
(2)一个仓库有多个职工当仓库保管员,一个职工只能在个仓库工作,因此仓库和职工之间是一对多的联系。
(3)职工之间具有领导与被领导关系。即仓库主任领导若干保管员,因此职工实体型中具有一对多的联系。
(4)供应商、项目和零件三者之间具有多对多的联系。即一个供应商可以供给若干项目多种零件,每个项目可以使用不同供应商供应的零件,每种零件可由不同供应商供给。
实体属性:
实体及其联系:

完整的E-R图:
2. 范式
2.1 什么是范式?
数据无处不在,但其中有的数据是错误的。
大体上说,即使是良好的数据库设计也不能防止错误数据的存在。
但有一些情况下,良好的数据库设计可以防止错误数据的存在。
比如下图的的表:

理论上来说,一个客户只有一个出生日期,但是该表出现两个,这是肯定错误的。
为什么表格中能出现这样的情况?
这是数据库设计的不合理。
具体而言,当数据库设计没有得到适当的规范化时,就会出现这种情况。
什么是范式?
答:
范式(Normal Forms,简称 NF)是关系数据库设计中的一系列规则,用于确保数据库结构的合理性,减少数据冗余,并避免数据操作时出现异常(如插入异常、删除异常和更新异常)。
为什么要规定范式?
答:
便于理解;减少数据冗余,当数据库不遵循范式时,数据可能会大量重复存储;避免数据操作异常,如不遵循范式,可能会出现插入数据困难的情况;提高数据的一致性和完整性,范式有助于确保数据在整个数据库中的一致性。
那我们如何确定冗余的数据可能会进入表中?
事实证明,我们可以使用一组标准来评估危险程度

我们可以将这些规范行式类比为安全评估
假如我们对桥的评估为:
安全等级1:适用于行人交通。
安全等级2:适用于轿车交通。
安全等级3:适用于卡车交通。
以此类比,第一范式(1NF)就是对数据库设计最基本的等级评估。
2.2 第一范式 1NF
下面的表格看着舒服吗?其实更像一个文本。第一范式规定,不允许使用行顺序传达信息。

同学们可以看一下下面的表格,信息很全,但是很乱,这就不符合第一范式,第一范式规定,不允许在同一列中混合不同的数据类型。

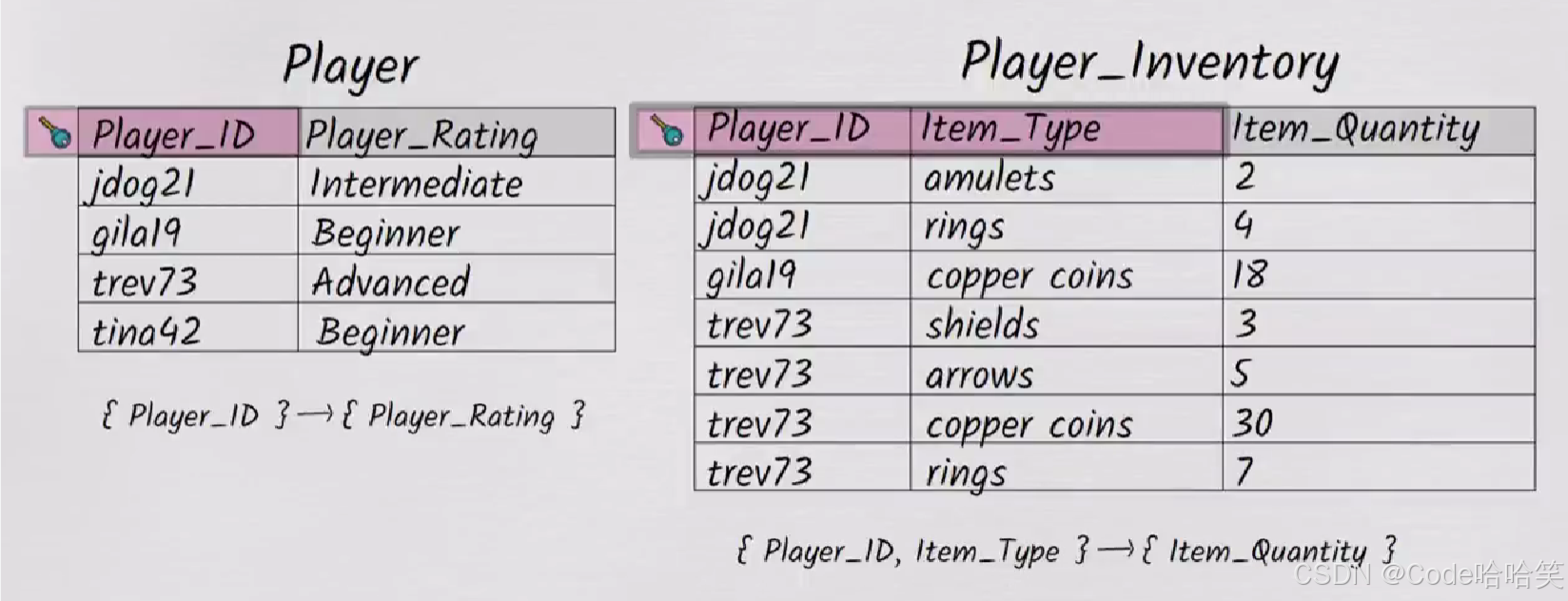
加入我们正在设计一个在线多人游戏的数据库,某个时间点,每个玩家都拥有很多种类的物品,比如剑、盾牌和铜币;大致如下

如果我们想知道哪些玩家拥有超过10铜币,上面设计的文本表格很不容易查询。可以把表格设计为以下方式:

每个表格都作为一个专属物件的厂库。但是玩家会有几百个种类的装备,创建一个超宽的表来查询还是非常笨拙。我们还可以这样设计:

把前两列作为主键,该表格表示为:
玩家jdog的amulets的装备数量为2;
玩家trev73的shields的装备数量为3;
玩家trev73的arrows的装备数量为5。
总结
第一范式,也就是表的基本要求:
- 不允许使用行顺序传达信息。
- 不允许在同一列中混合不同的数据类型。
- 不允许没有主键的表。
- 不允许重复组。
2.3 第二范式 2NF
第一范式的表看起来是规范的,但是假设我们稍微增加一下表。
假设每个玩家都有一个等级:初学者、中级或高级
为了实现这一点,我们需要再增加一列Player_Rating
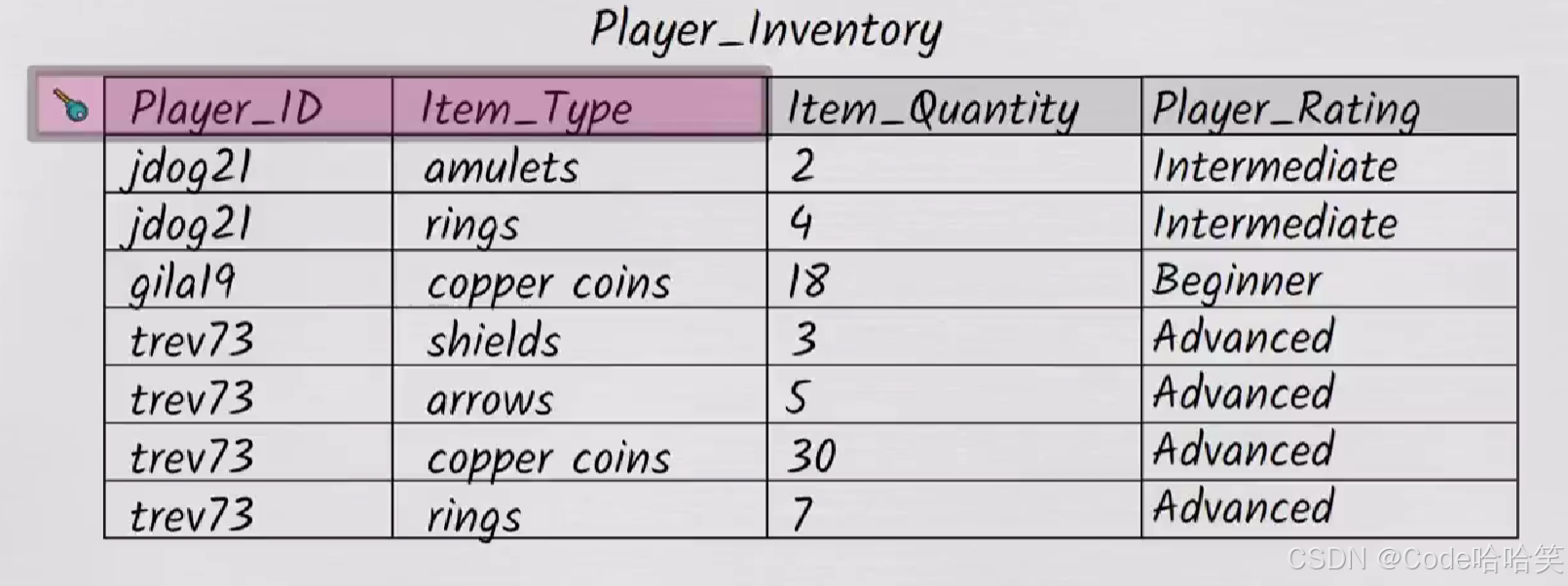
显而易见,相同的玩家有几行,该玩家的等级就会出现相应的次数。
这是一个不好的设计,为什么呢?
假设gila19失去了她说所有的铜币,这会使得她的库存为空,即改行就会消失。
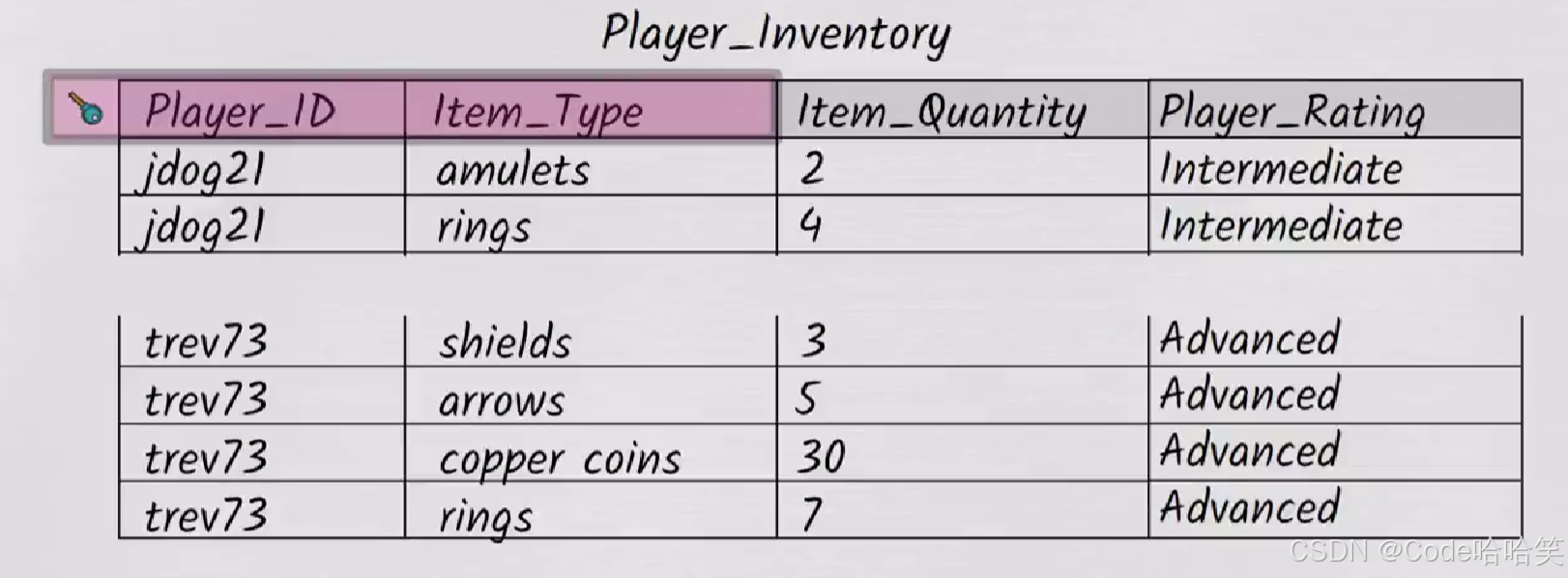
gila19就无法再被访问了,这个玩家还存在,但是数据库中没有他的信息了,这是矛盾的。
假如,玩家jdog升级了,就会变成Advance,但是他的多行存在可能会遗漏更改,这也是一个巨大的问题。
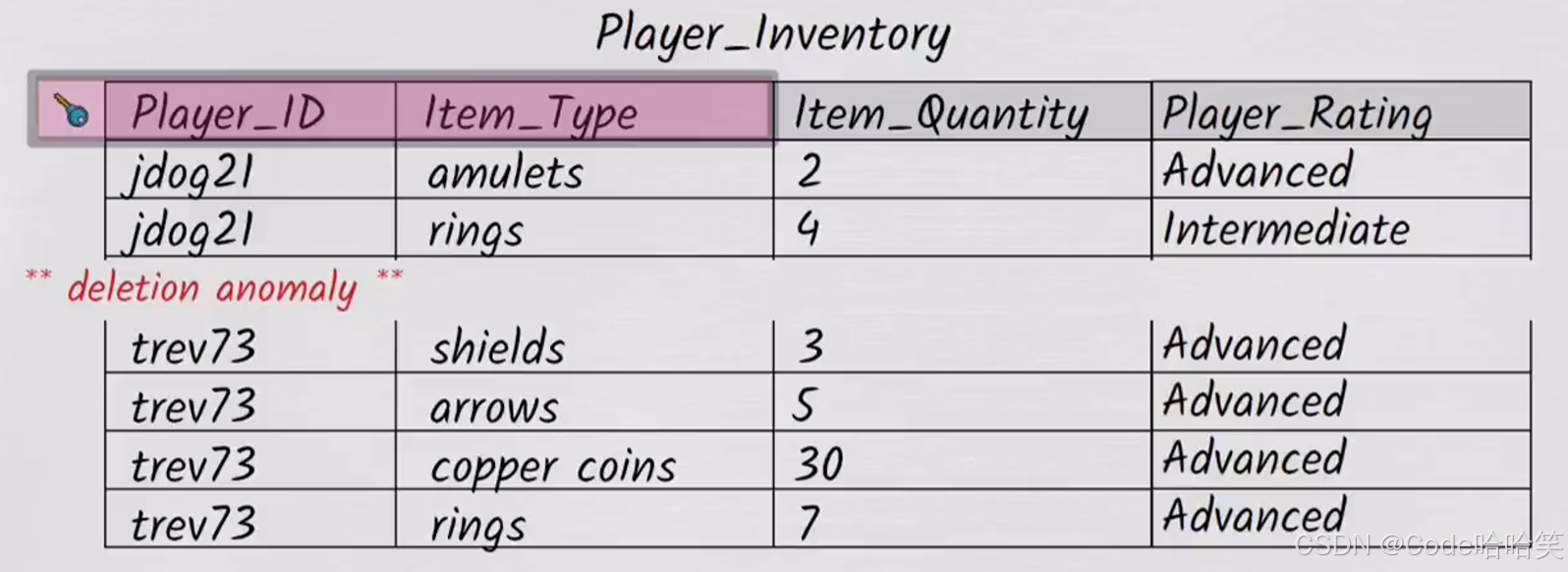
玩家jdog21在该表中会出现两个等级,这是不合理的。
所以我们要设计第二范式,第二范式涉及表的非主键列和主键的关系
重新看一下这个表:
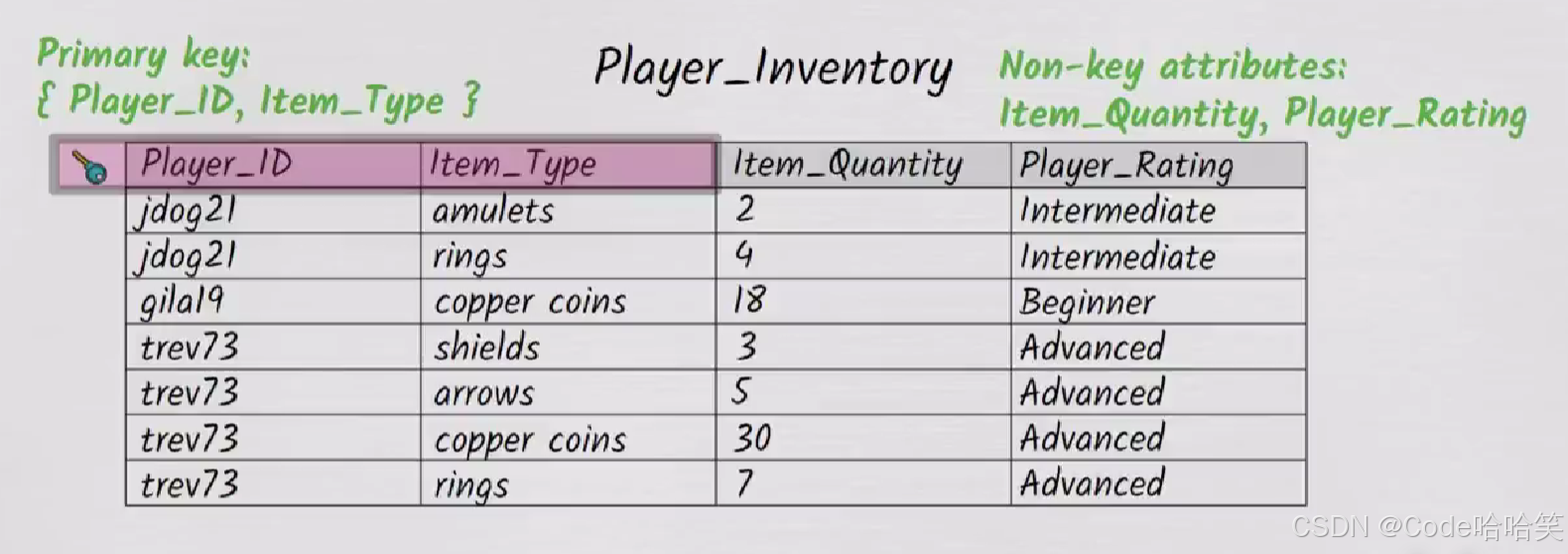
该表的主键是:(Player_ID,Item_typpe),列Item_Quantity完全依赖于主键(Player_ID,Item_typpe),而列Player_Rating依赖于主键:(Player_ID,Item_typpe)中的Player_ID
第二范式规定非键属性必须依赖于整个主键。
所以,Player_Rating不能放入上表中,需要
对Player_ID和Player_Rating重新创建一个表。
总结:
第二范式,非主键列和主键的关系:
- 非键属性必须依赖于整个主键
2.4 第三范式 3NF
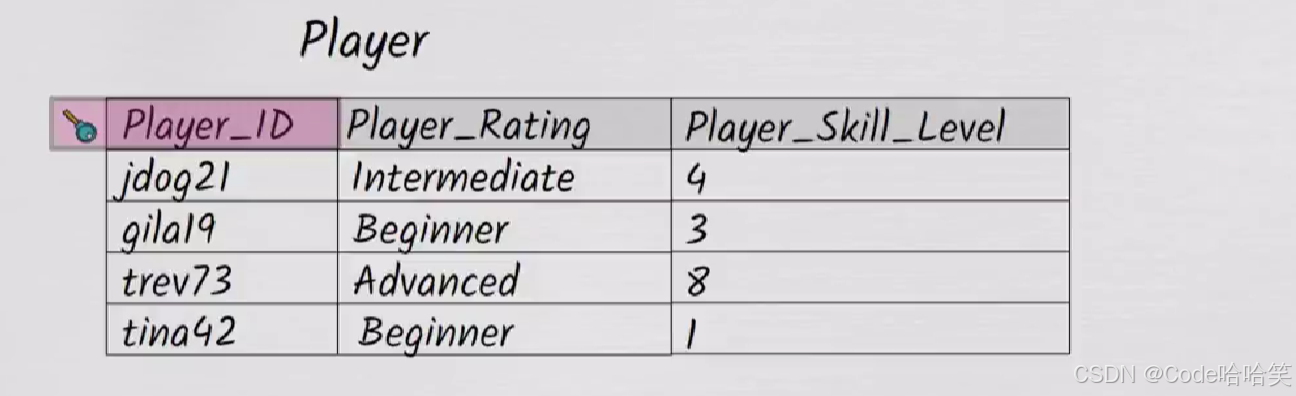
上述的表不易足够存储一个玩家的数据,我们还需要添加一个名为Player_Skill_Level的列。
假设技能级别有1-9的分制,分别表示一个玩家的熟练程度,1-3为初级,4-6为中级,7-9为高级

表格如下:
当一个玩家不断地练习时,他的等级就会慢慢的升高,如果玩家gila19等级升为4时,她的Player_Rating应该升级为Intermadiate。但假设出现错误,未能更新Player_Rating,现在的数据就会不一致。
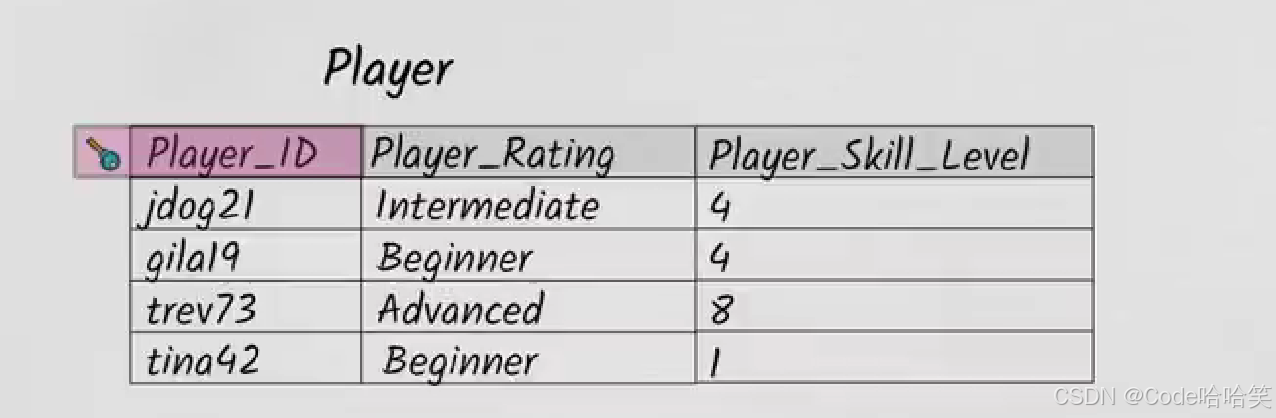
gila19的Player_Rating显示她是初级,而Player_Skill_Level显示她是中级,这是矛盾的。
从第二范式来看,Player_Rating和Player_Skill_Level都完全依赖于Player_ID,并没有什么不合适的,但是实际上很不合适。
他们的依赖关系如下:

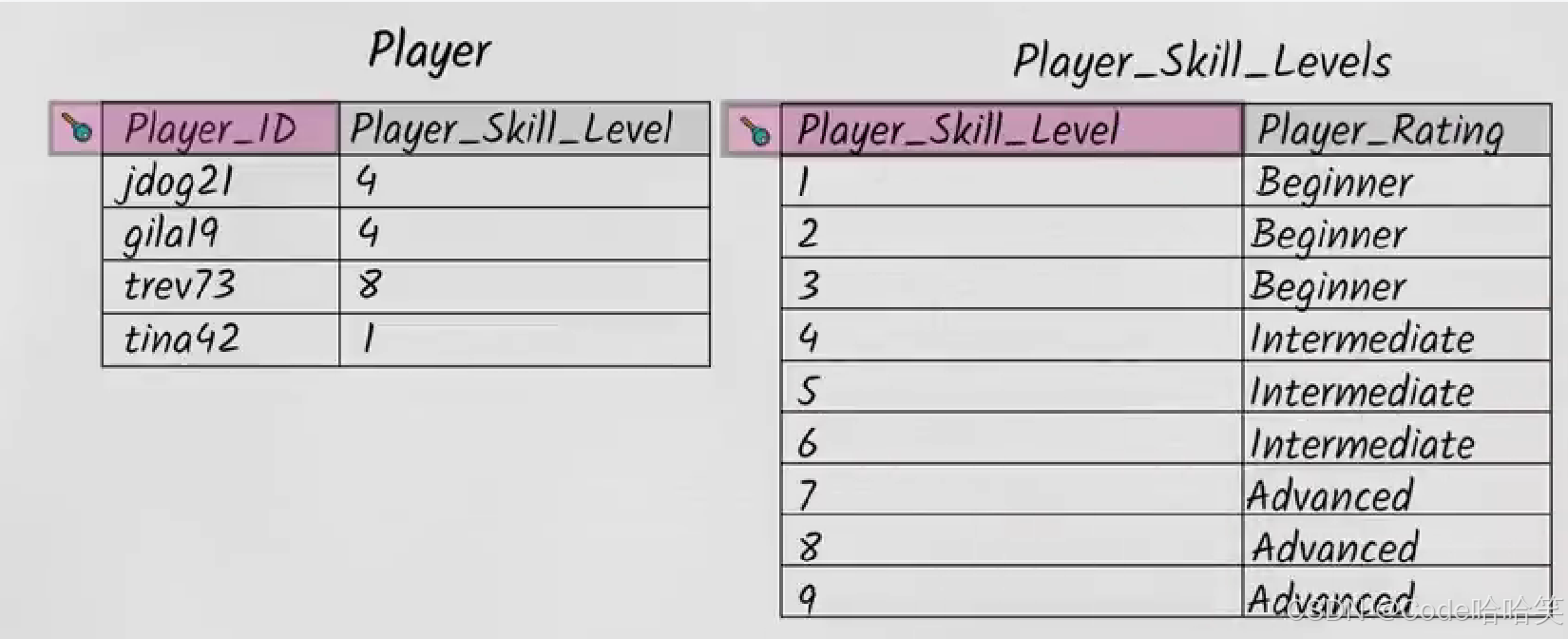
这样的关系被称为传递依赖。非键属性依赖于非键属性是不合理的。
这时需要改进该表格,把Player_Rating从上面的表格中移除,重新与Player_Skill_Level在另一个表格中建立关系。如下:
总结:
第三范式,非主键列和非主键列的关系
- 非主键列不能传递性的与主键依赖。
- 每个非主键属性都必须依赖于键(整个建或单单键)
总结:表中的每个非主键主键属性都应该依赖于键(整个建或单单键)
2.5 第四范式 4NF
第四范式:
- 表格中允许的多值依赖只能是对主键的多值依赖。
2.6 第五范式 5NF
第五范式:
- 第四范式的表格是不是在逻辑上其他表格连接一起的结果。
- 不能将该表的描述为连接其他表的逻辑结果
3. 关系代数
3.1 什么是关系代数
关系代数是一种抽象的查询语言,用于对关系(可以看作是数据库中的表)进行操作。它是关系数据库操作的数学基础,通过对关系进行一系列的运算来获取所需的数据。这些运算主要包括传统的集合运算和专门的关系运算。
换言之,关系代数类似与SQL语句,对关系(表)进行查询。
3.2 关系代数表达式
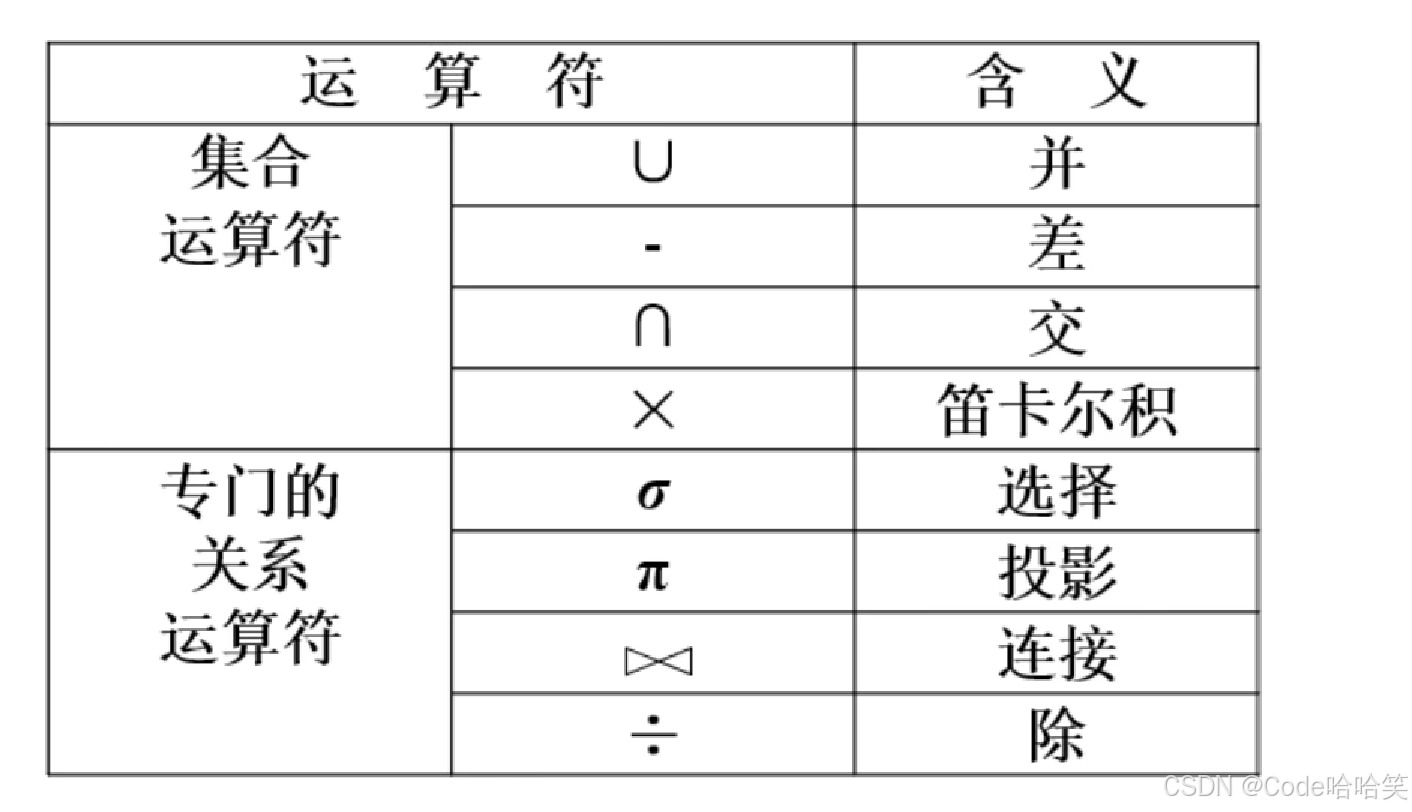
3.3 讲解-- 并、差、交
注:R和S具有相同的属性,形同的属性取同一域
并:并集操作是指将两个集合中的所有元素合并在一起,去除重复的元素后得到新的集合。在数据库中,并集操作可以用来合并两个或多个表中的所有记录。

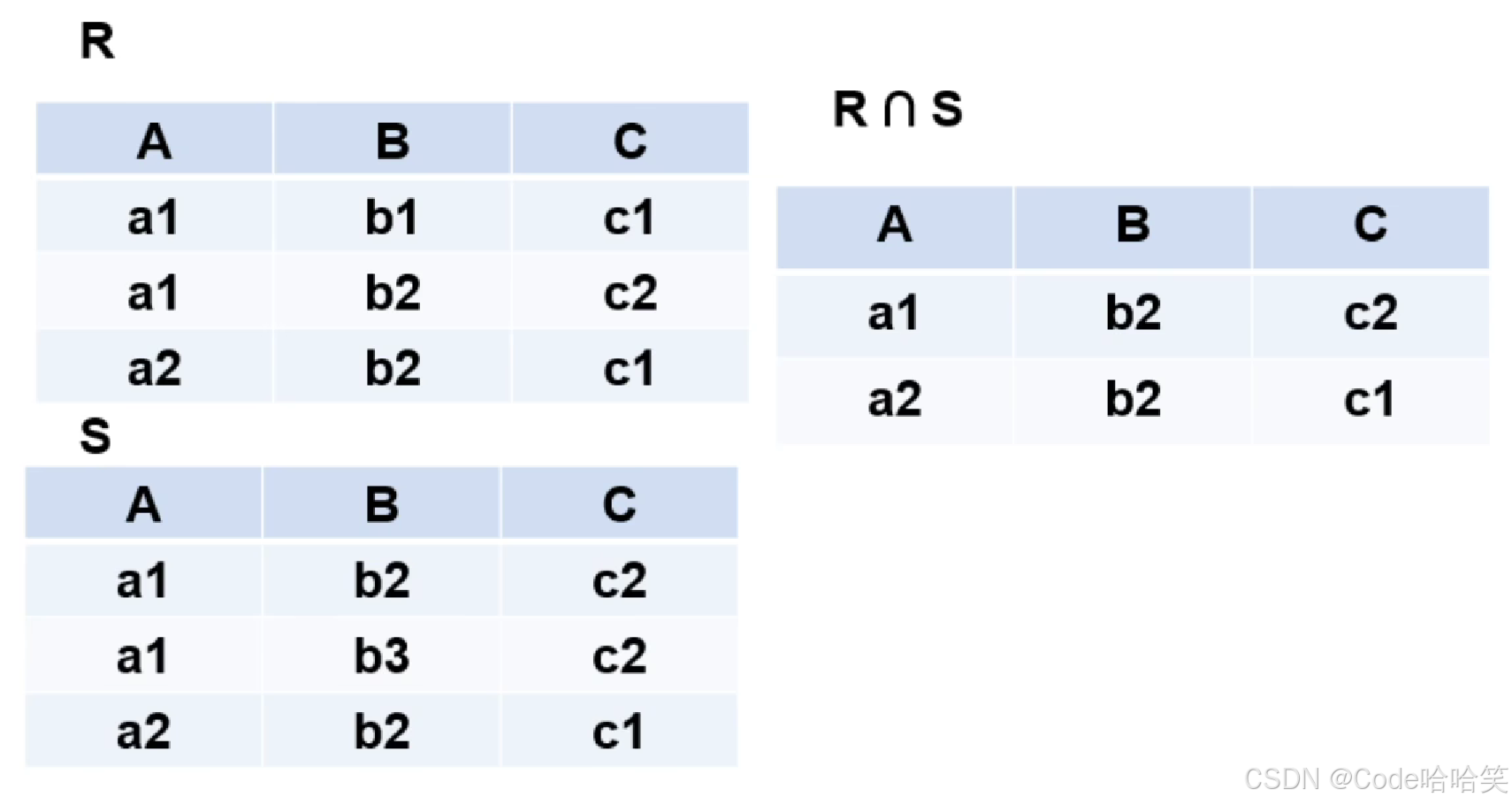
差:差集操作是指从一个集合中减去另一个集合中的元素,得到的结果是仅存在于第一个集合中的元素。在数据库中,差集操作可以用来找出在一个表中但不在另一个表中的记录。
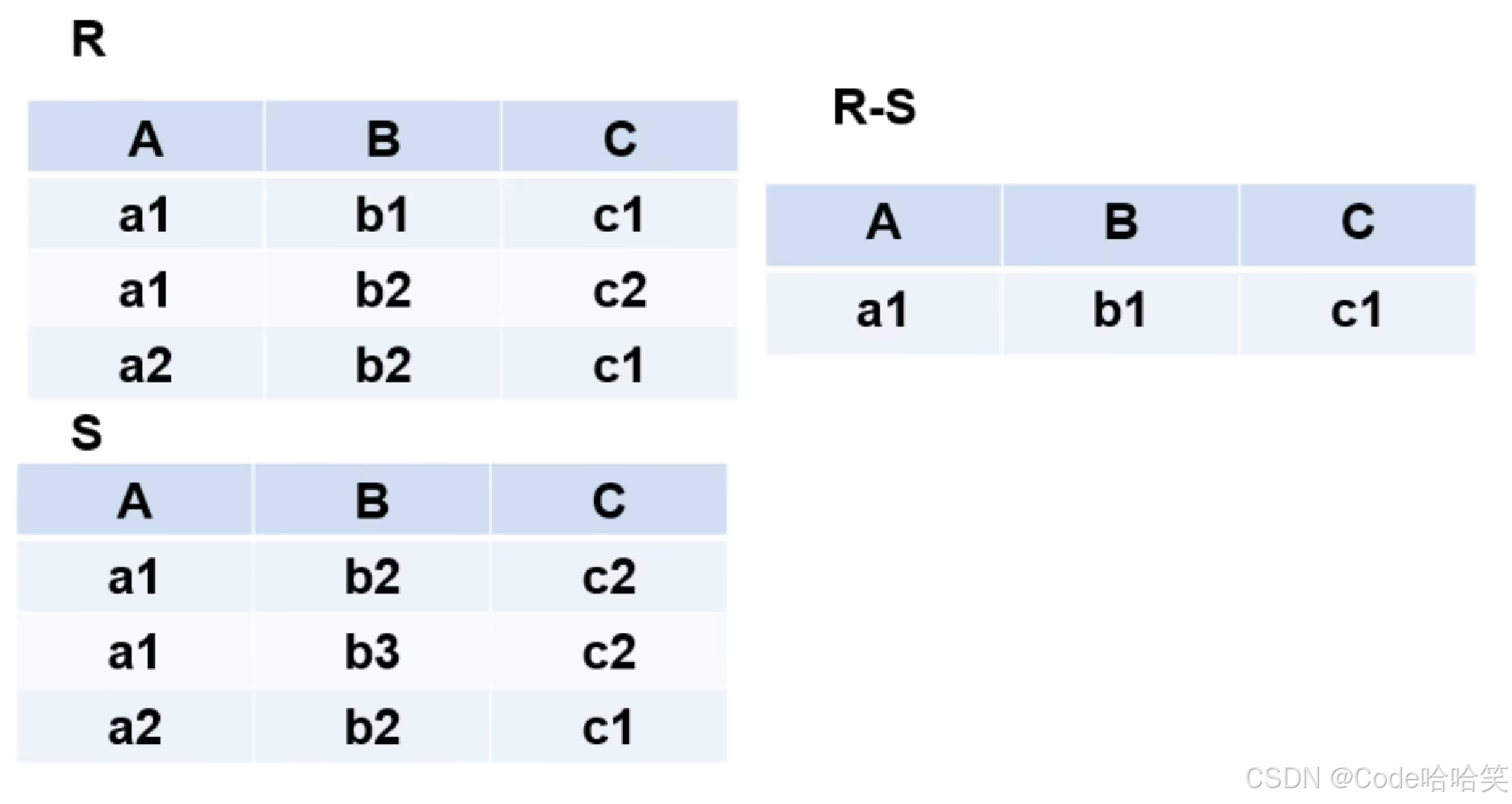
交:交集操作是指找出两个集合中共有的元素。在数据库中,这通常意味着找出同时满足两个或多个表中条件的记录。例如,如果有两个表A和B,交集操作可以找出同时存在于A和B中的记录。
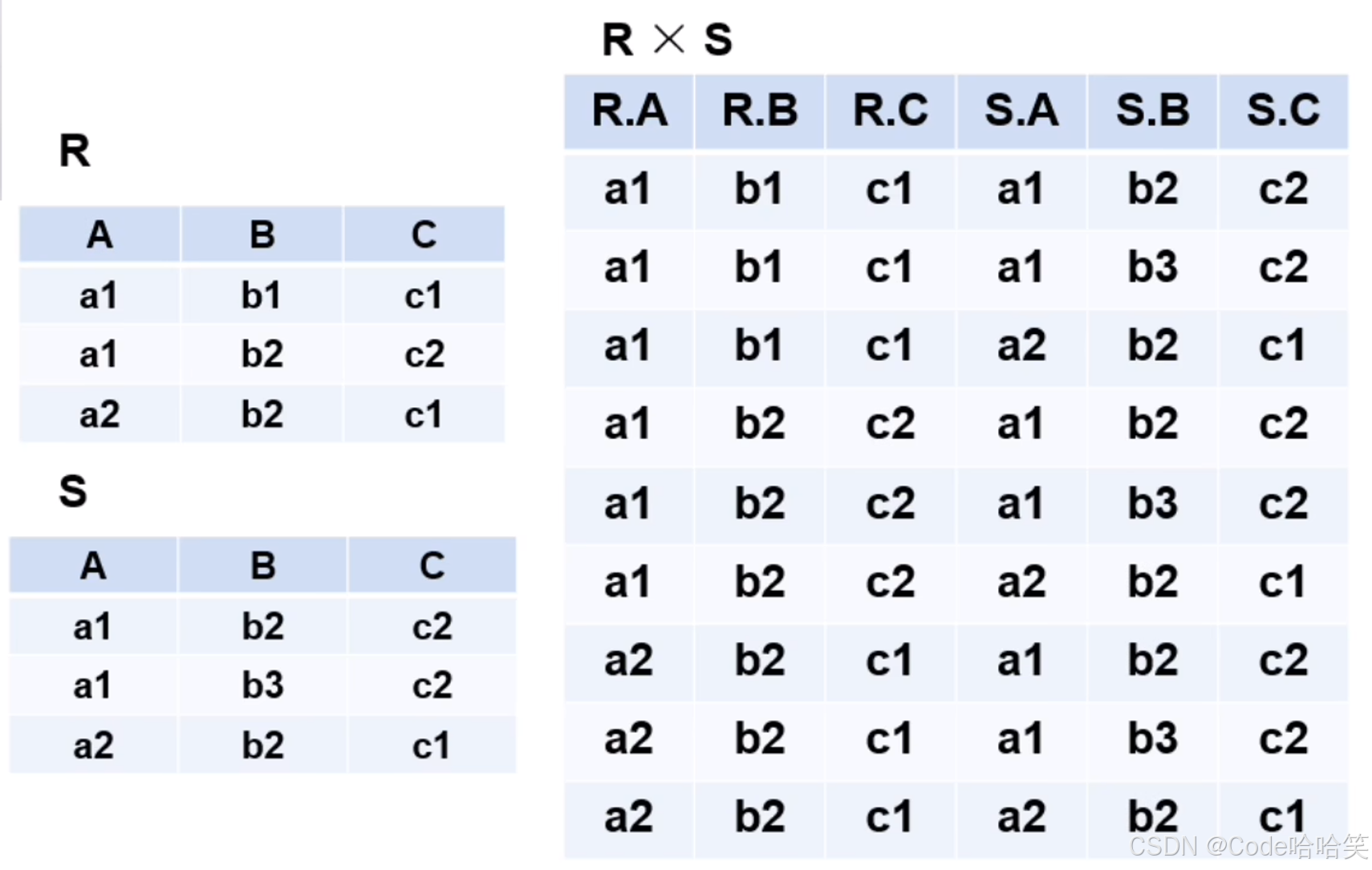
3.4 笛卡尔积
笛卡尔积是指两个集合之间的一种运算,其结果是一个新集合,该集合中的每个元素都是由来自第一个集合的一个元素和第二个集合的一个元素组成的有序对。如果第一个集合有m个元素,第二个集合有n个元素,那么它们的笛卡尔积将包含m×n个这样的有序对。
3.5 讲解 选择、投影、连接、除 使用的表
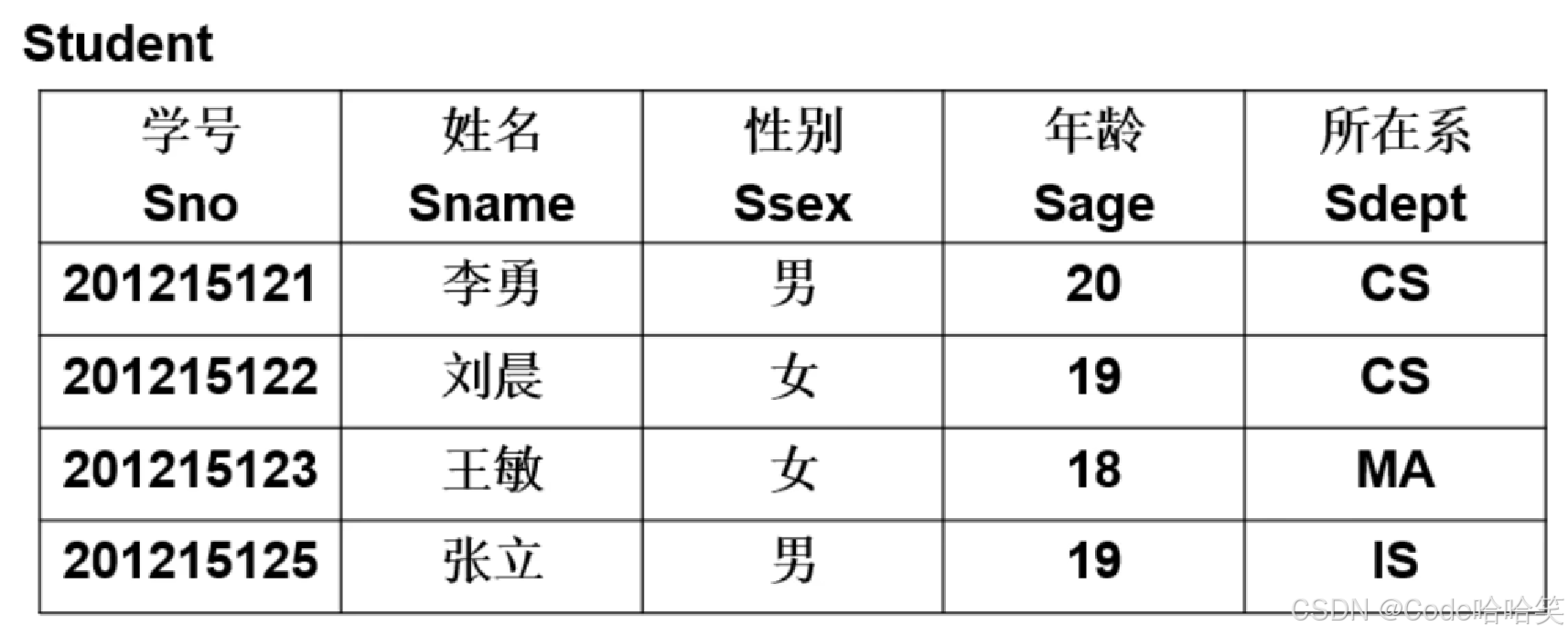
Student表。主码为:学号。
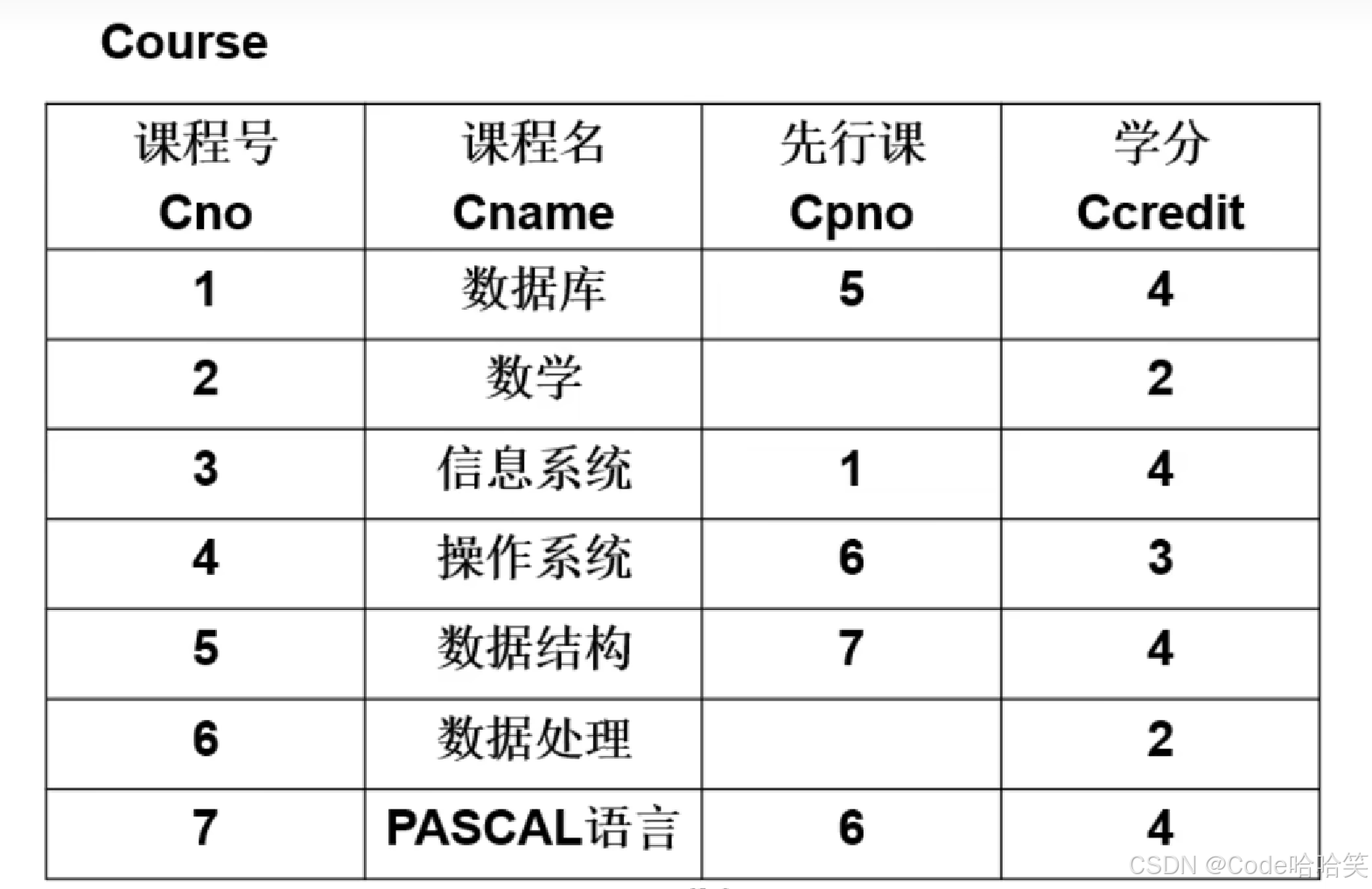
Course表。主码为:课程号。
SC表。主码为:(学号,课程号)。

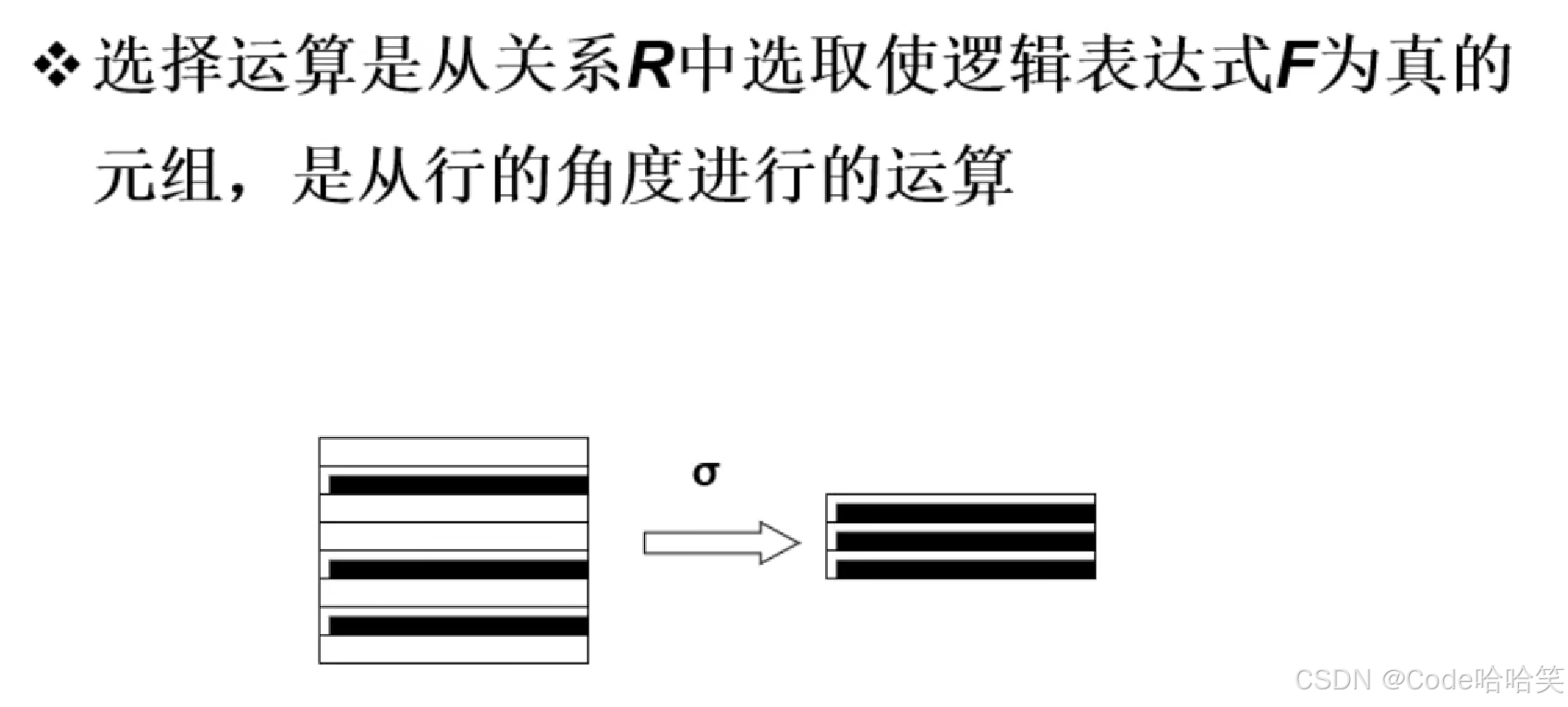
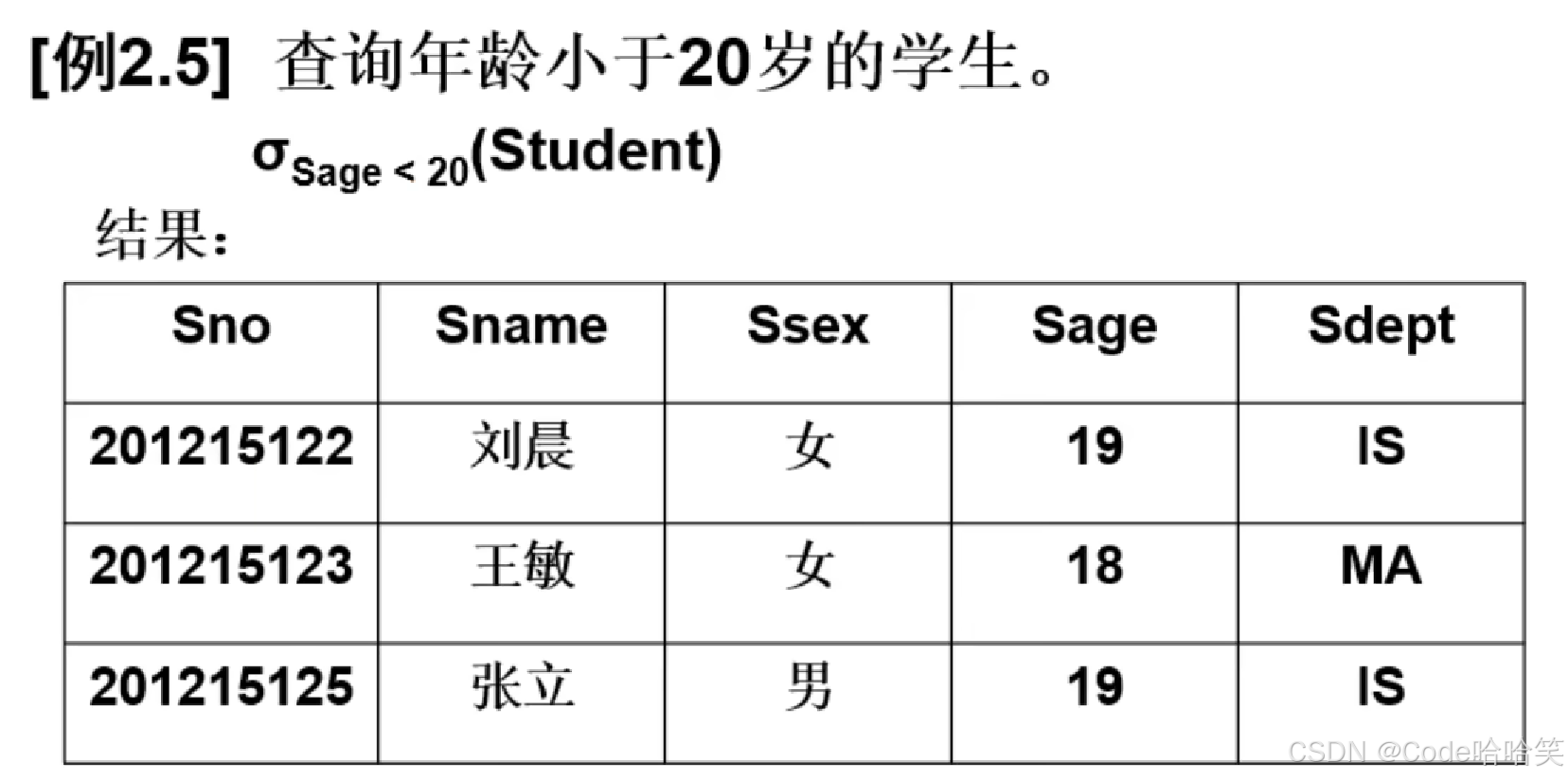
3.6 选择


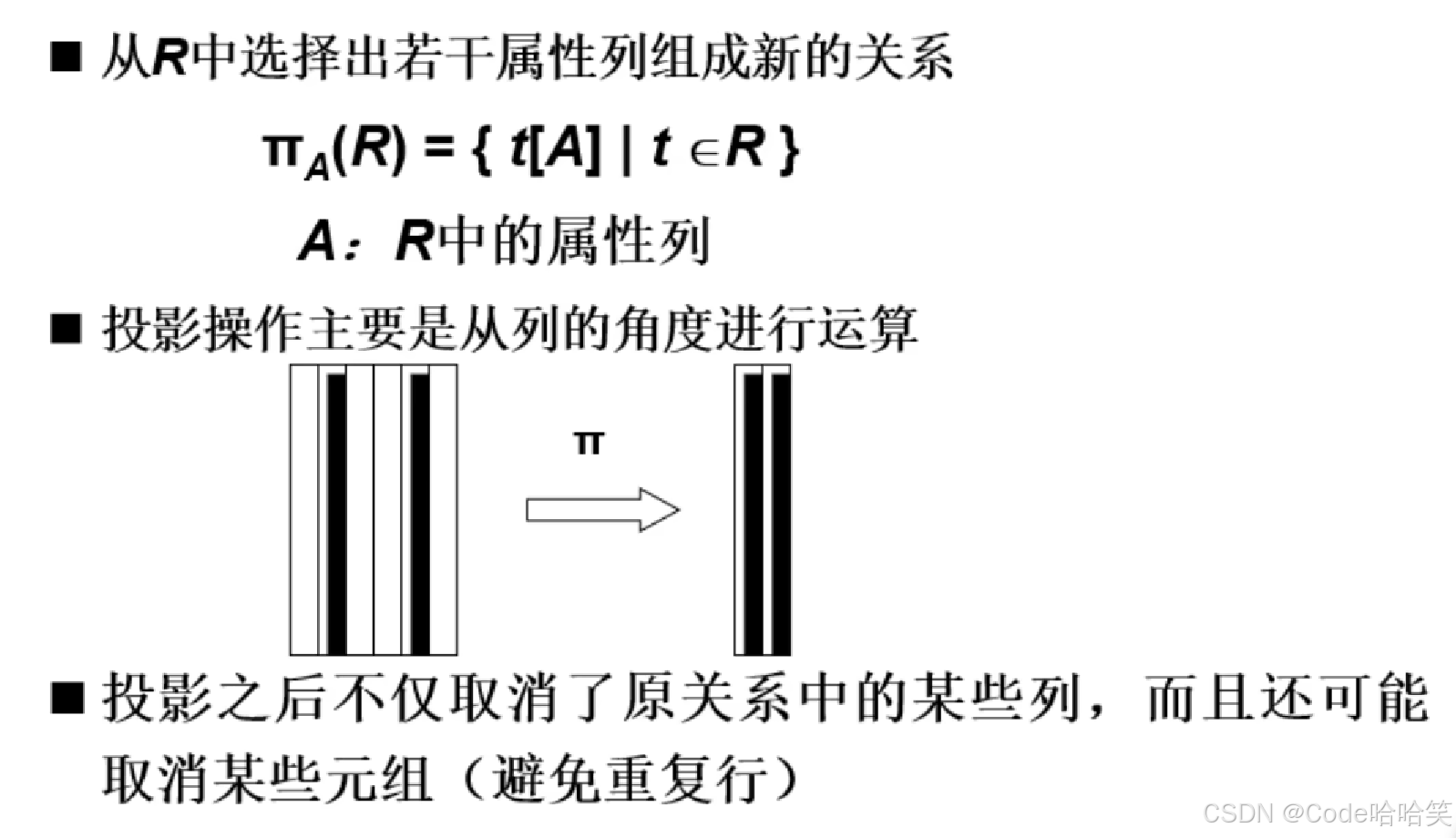
3.7 投影


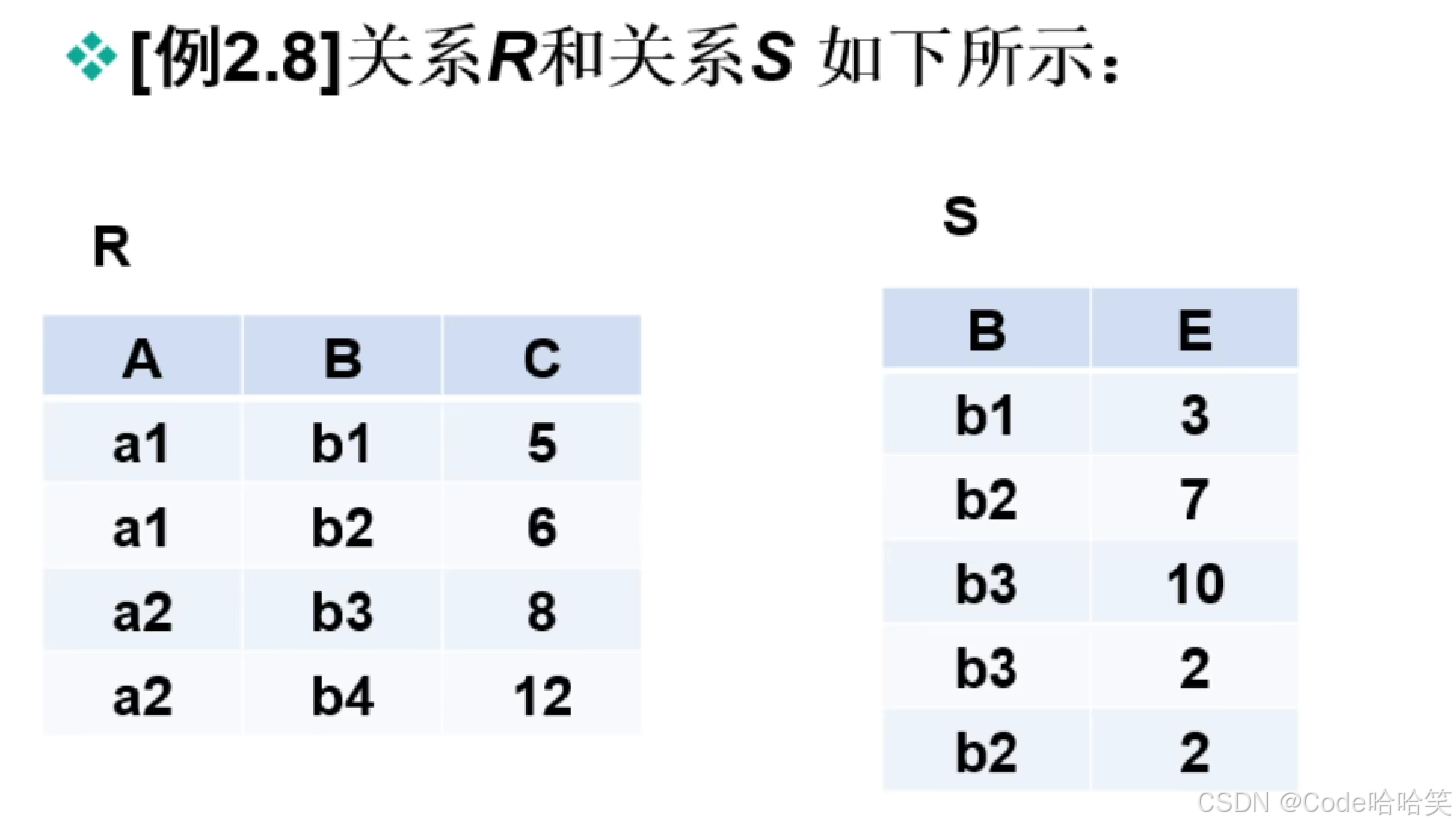
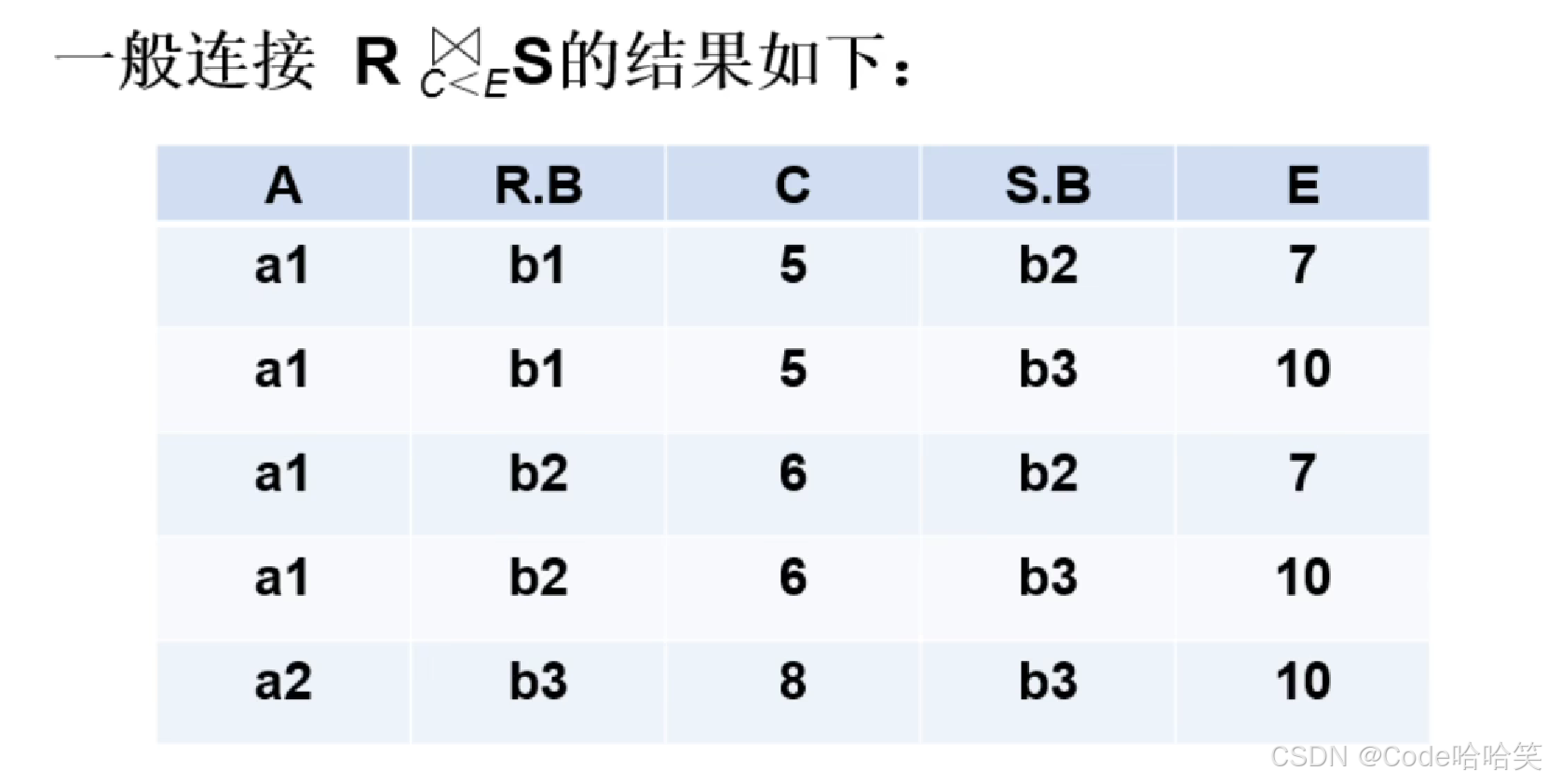
3.8 连接



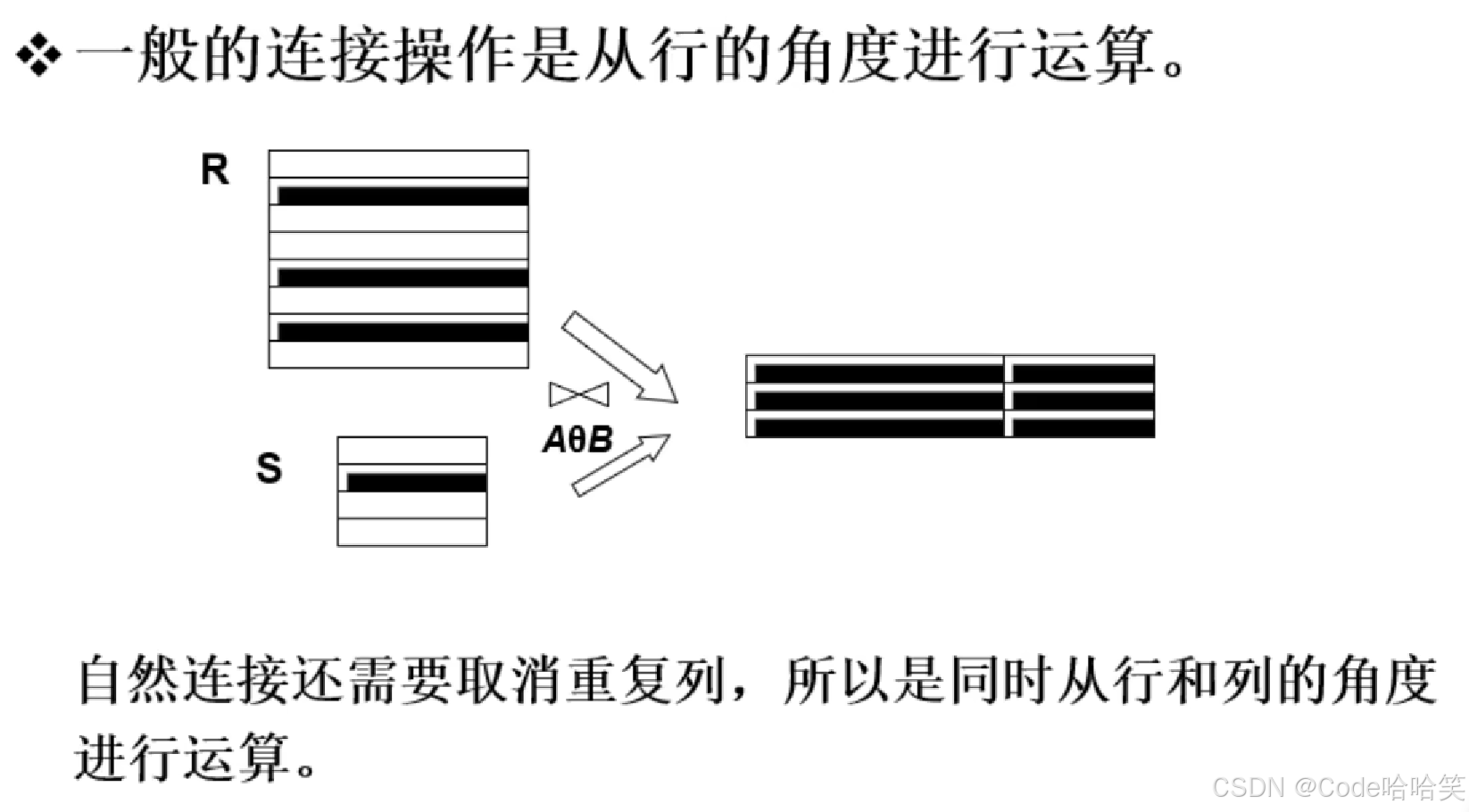
连接一般有两步:
(1)先做笛卡尔积
(2)再根据连接条件进行筛选
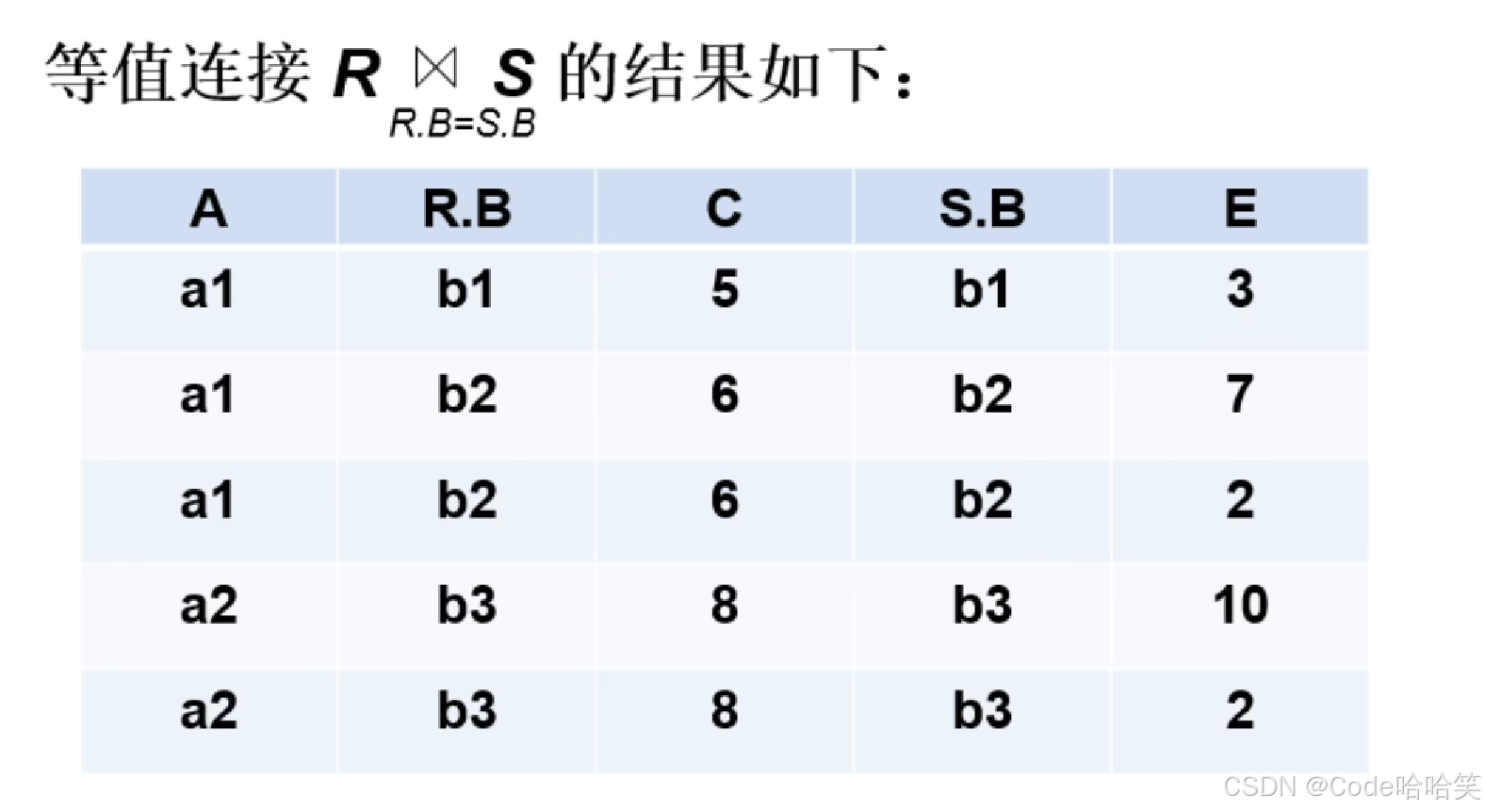
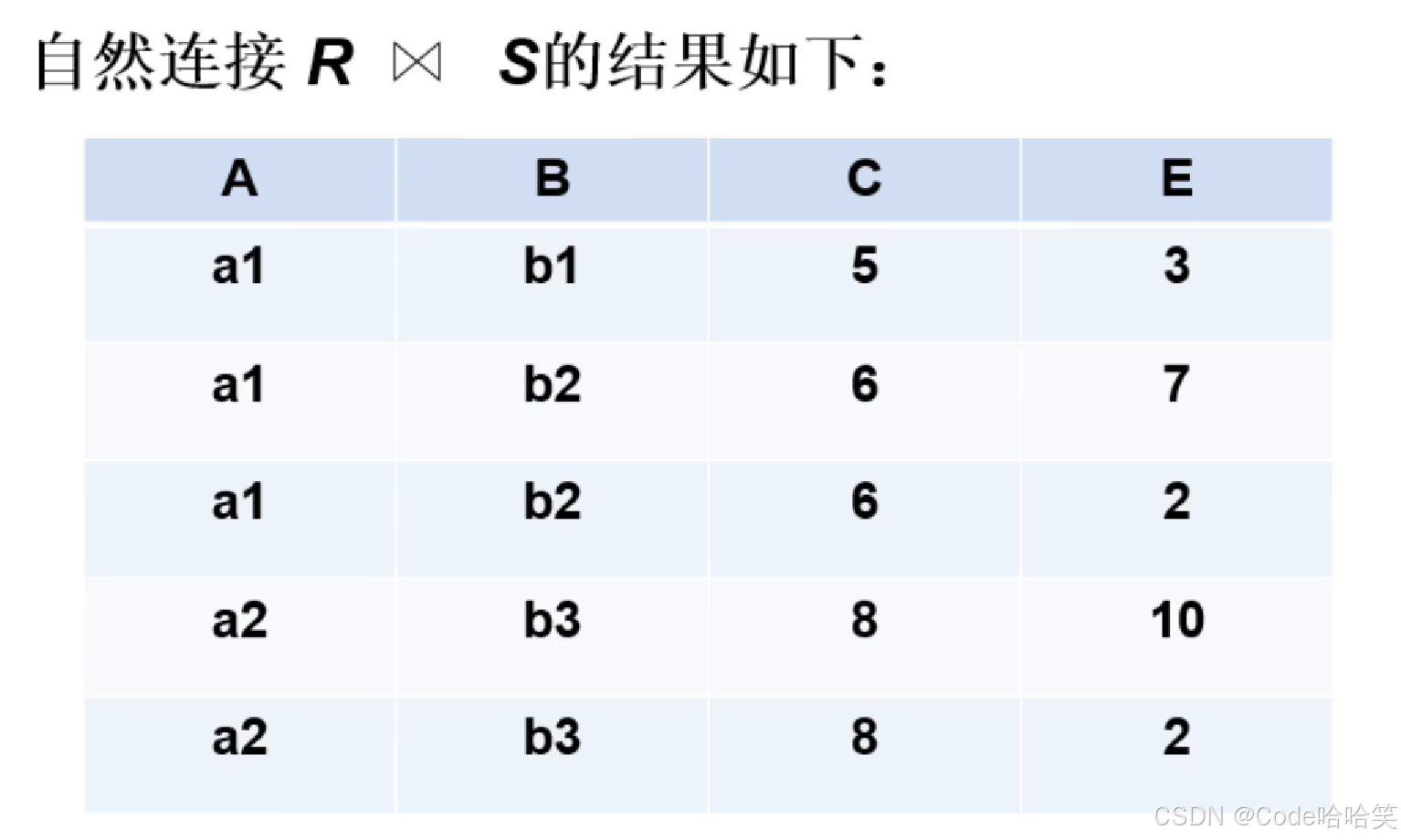
3.9 外连接、左连接、右连接
外连接(也称为全外连接)是返回两个关系中所有元组的连接,无论它们是否匹配。如果某个关系中没有匹配的元组,则在结果中补充NULL值。

左连接是返回左关系中所有元组的连接,以及右关系中与左关系元组匹配的元组。如果左关系中的元组在右关系中没有匹配的元组,则结果中相应的位置将填充为NULL值。

右连接是返回右关系中所有元组的连接,以及左关系中与右关系元组匹配的元组。如果右关系中的元组在左关系中没有匹配的元组,则结果中相应的位置将填充为NULL值。

3.10 除运算


4. 知识点
4.1 笛卡尔积
4.1.1 域
域:域是一组具有相同数据类型的值的集合。在数据库中,域用于定义表中列(属性)的数据类型和取值范围。
举例:
假设我们有一个学生信息表,其中有一个 “性别” 列。这个列的域可以定义为 {“男”,“女”},这意味着该列只能取 “男” 或者 “女” 这两个值。
再比如 “年龄” 列,它的域可能是大于等于 0 且小于等于 100 的整数集合,这就限制了 “年龄” 列的数据必须是这个范围内的整数。
4.1.2 关系
关系:关系是一个二维表,它是元组(行)的集合。表中的每一行代表一个元组,每一列代表一个属性。关系有一些特性,比如列是同质的(每一列的数据类型相同),列的顺序可以交换,行的顺序也可以交换,关系中的任意两个元组不能完全相同。
如下表所示:
| 学号 | 姓名 | 性别 | 年龄 |
|---|---|---|---|
| 001 | 张三 | 男 | 20 |
| 002 | 李四 | 女 | 19 |
这个学生信息表就是一个关系,它包含了 4 个属性(学号、姓名、性别、年龄),有两个元组(分别代表张三和李四的信息)。每个属性都有自己的数据类型,比如学号可能是字符串类型,年龄是整数类型等。而且这个表满足关系的特性,列的数据类型相同,行和列的顺序改变不影响关系的本质,并且不会出现两个完全相同的行来重复表示同一个学生的信息。
4.1.3 笛卡尔积
笛卡尔积:设关系 R 和关系 S 的元数分别为 r 和 s,R 和 S 的笛卡尔积是一个 (r + s) 元的关系,记为 R×S。它是所有可能的有序对的集合,其中有序对的第一个元素来自关系 R,第二个元素来自关系 S。如果关系 R 有 m 个元组,关系 S 有 n 个元组,那么 R×S 就有 m×n 个元组。
举例:
假设有两个集合(可以看作是简单的关系),集合 A = {1, 2},集合 B = {a, b}。它们的笛卡尔积 A×B ={(1,a),(1,b),(2,a),(2,b)}。
用表格来表示关系 R 和关系 S 以及它们的笛卡尔积更直观。设关系 R 有两列(属性)A 和 B,有两个元组 {(1,3),(2,4)};关系 S 有两列(属性)C 和 D,有两个元组 {(a,x),(b,y)}。
关系 R:
| A | B |
|---|---|
| 1 | 3 |
| 2 | 4 |
关系 S:
| C | D |
|---|---|
| a | x |
| b | y |

笛卡尔积 R×S:
| A | B | C | D |
|---|---|---|---|
| 1 | 3 | a | x |
| 1 | 3 | b | y |
| 2 | 4 | a | x |
| 2 | 4 | b | y |
4.2 码
4.2.1 码的概念
码:在关系数据库中,码是能够唯一标识一个元组(一行数据)的属性或属性组。它就像是每个数据行的 “身份证”,通过码可以准确地找到和区分不同的记录。
举例:
考虑一个学生信息表,包含学号、姓名、性别、年龄这几个属性。如果学号是唯一的,那么学号这个属性就可以作为码,因为通过学号能够唯一地确定一名学生的所有信息。
4.2.2 候选码
候选码:候选码是能够唯一标识关系中每一个元组的最小属性集。一个关系可能有多个候选码,这些候选码都具有能够唯一标识元组的能力,并且不能再减少其中的属性而仍然保持唯一性。
举例:
假设在一个员工信息表中有员工编号、身份证号、姓名、部门编号这几个属性。员工编号和身份证号都可以唯一地标识一个员工。因为任何一个员工都有唯一的员工编号和唯一的身份证号。这里员工编号和身份证号就是候选码。姓名可能会有重复,不能单独作为候选码;部门编号也不能单独标识一个员工,因为一个部门有多个员工。
再比如一个课程表,包含课程号、课程名称、授课教师姓名这几个属性。如果规定课程号是唯一的,并且课程名称和授课教师姓名组合起来也是唯一的(即不会出现两门课程有相同的课程名称和相同的授课教师),那么课程号和(课程名称,授课教师姓名)这两组属性都是候选码。
4.2.3 主码
主码(Primary Key):主码是从候选码中选取的一个用于唯一标识关系中的元组的码。在一个关系中,主码是最重要的标识符,它可以帮助数据库管理系统快速准确地定位和操作数据。一个关系只能有一个主码。
举例:
在上述员工信息表中,如果我们选择员工编号作为主码,那么员工编号就会被数据库系统用于建立索引、关联其他表等操作。当我们需要查询某一个员工的信息时,数据库系统可以根据员工编号快速找到对应的记录。
对于课程表,如果我们选择课程号作为主码,那么在涉及到课程的选课记录关联(比如学生选课表中会引用课程号来表示学生选了哪门课程)等操作时,就通过课程号来建立关系,保证数据的一致性和准确性。
4.2.4 外码
外码:用于建立两个关系(表)之间联系的一种机制。在关系数据库中,如果一个关系(表)中的一个属性(或属性组)是另一个关系(表)的主码(或候选码),那么这个属性(或属性组)在本关系中就被称为外码。
外码的作用
它主要用于维护数据库中表与表之间的参照完整性。参照完整性确保了相关表之间的数据一致性。例如,在学生选课系统中,通过外码可以保证选课表中的学生信息和课程信息与学生表和课程表中的信息相对应,防止出现不存在的学生选课或者不存在的课程被选的情况。
举例:
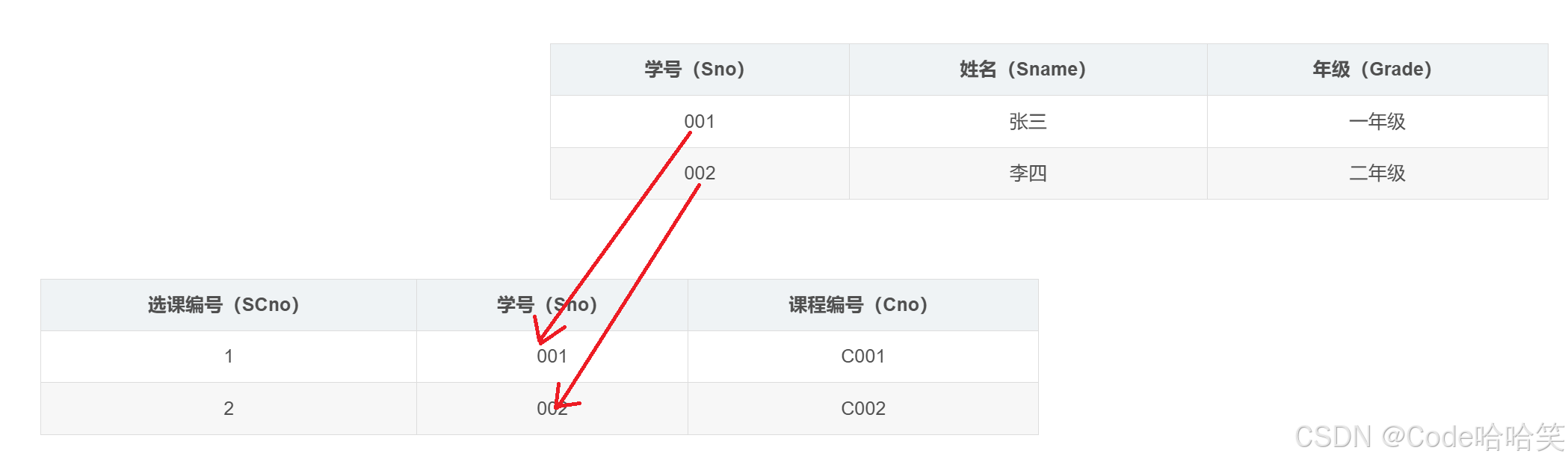
假设我们有一个简单的学校数据库,包含 “学生表” 和 “选课表”。
学生表(Student):
| 学号(Sno) | 姓名(Sname) | 年级(Grade) |
|---|---|---|
| 001 | 张三 | 一年级 |
| 002 | 李四 | 二年级 |
选课表(SC):
学号(Sno)这个外码用于关联学生表中的 学号(Sno),表示每个选课记录所属的学生。
| 选课编号(SCno) | 学号(Sno) | 课程编号(Cno) |
|---|---|---|
| 1 | 001 | C001 |
| 2 | 002 | C002 |
我们可以用两个矩形分别表示 “学生表” 和 “选课表”,然后用箭头来表示外码的关联关系。从学生表的 “学号(Sno)” 指向选课表的 “学号(Sno)”,箭头表示选课表中的学号是参照学生表中的学号的,即选课表中的学号必须是学生表中已存在的学号。
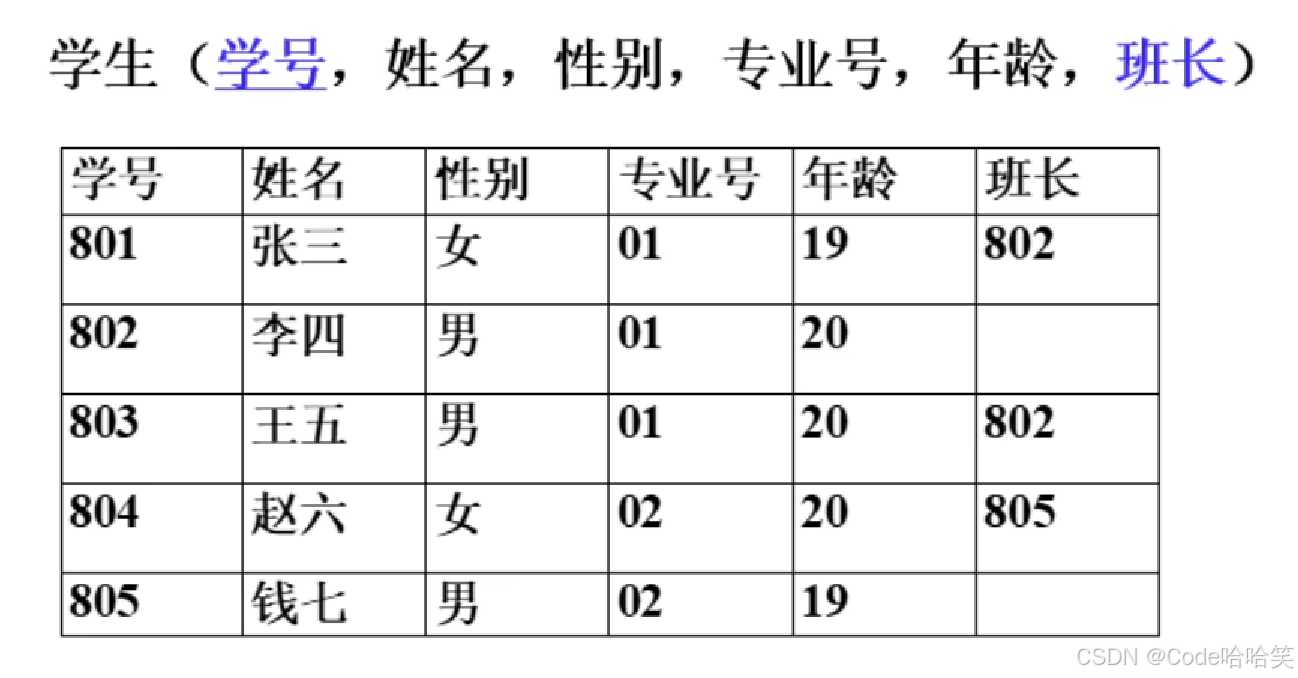
4.2.5 特殊的外码
主码和外码也有可能在一个表中。
学号是主码,班长是外码(引用了本关系的学号)
4.2.6 主属性和非主属性
主属性:包含在任何一个候选码中的属性称为主属性。
非主属性:关系模式中除了主属性之外的属性就是非主属性。
举例说明:
假设有一个关系模式R(学号,姓名,性别,班级,班主任)
假设在这个学校里,学号是唯一的,学号可以唯一确定一个学生的所有信息(姓名、性别、班级、班主任),那么学号就是一个候选码。
同时,假设姓名和班级组合起来也能唯一确定一个学生(因为学校里不存在姓名相同且班级相同的两个学生),那么(姓名,班级)也是一个候选码。
在这个例子中,学号、姓名和班级都是主属性,因为它们分别包含在候选码(学号)和候选码(姓名,班级)中。而性别和班主任不是主属性,因为它们没有参与构成候选码。
4.2.7 例子
例一:
| 学号 (主码) | 姓名 | 性别 | 年龄 |
|---|---|---|---|
| 1001 | 张三 | 男 | 20 |
| 1002 | 李四 | 女 | 19 |
在这个学生信息表中,学号是主码,它可以唯一标识每一个学生。同时,假设学校规定姓名和年龄组合起来也不会出现重复(在这个简单示例中),那么(姓名,年龄)就是候选码,因为它也能唯一地标识每一个学生,但我们选择了学号作为主码来进行主要的标识操作。
例二:
课程表(Course):
| 课程编号(Cno) | 课程名称(Cname) |
|---|---|
| C001 | 数学 |
| C002 | 英语 |
教师表(Teacher):
| 教师编号(Tno) | 教师姓名(Tname) |
|---|---|
| T001 | 王老师 |
| T002 | 李老师 |
授课表(TC):
“课程编号(Cno)” 用于关联课程表中的课程编号,“教师编号(Tno)” 用于关联教师表中的教师编号,表示每一个授课记录对应的课程和教师。
| 授课编号(TCno) | 课程编号(Cno) | 教师编号(Tno) |
|---|---|---|
| 1 | C001 | T001 |
| 2 | C002 | T002 |
些箭头清晰地展示了外码在不同表之间建立的关联关系,用于维护数据的参照完整性。

4.3 关系模式
4.3.1 什么是关系模式?
上面已经讲解,关系就是表,换言之就是表模式。
关系模式是对关系(二维表)的描述,它包括关系名、组成该关系的属性名集合、属性向域的映像集合、属性间的数据依赖关系集合等内容。
4.3.2 关系模式的组成

一般用关系名 (属性 1,属性 2,…,属性 n) 来表示一个关系模式( R(U) )。例如,学生 (学号,姓名,年龄,性别) 就是一个关系模式,其中 “学生” 是关系名,学号、姓名、年龄和性别是属性。
4.3.3 关系模式的规范化
为了使关系模式设计得更加合理,通常会对关系模式进行规范化。规范化过程主要依据函数依赖等数据依赖关系,将关系模式分解成更规范的形式。
例如,第一范式(1NF)要求关系中的每个属性都是不可再分的原子值。如果有一个关系模式 “员工信息 (员工编号,姓名,工资 (基本工资,奖金))”,这里工资是一个可分的属性,不符合 1NF。可以将其分解为 “员工信息 (员工编号,姓名,基本工资,奖金)”,使其满足 1NF。
进一步还有第二范式(2NF)、第三范式(3NF)等规范化形式,它们都是通过分析和处理属性间的数据依赖关系来实现的,目的是使数据库结构更加优化,提高数据的存储和操作效率。
4.4 函数依赖
4.4.1 什么是函数依赖?
在关系数据库中,函数依赖是指一个关系模式(可以简单理解为一张表)中属性之间的一种约束关系。如果给定一个属性(或属性组)的值,就能够唯一确定另一个属性(或属性组)的值,那么就称后者函数依赖于前者。
4.4.2 完全函数依赖
这是一个学生成绩表格,Sno是学号,Cno是课程号,Grade表示成绩。
| Sno | Cno | Grade |
|---|---|---|
| 001 | C01 | 85 |
| 001 | C02 | 90 |
| 002 | C01 | 78 |
从该表中可以看出(Sno,Cno)一起能决定成绩Grade。称为Grade完全依赖于Sno和Cno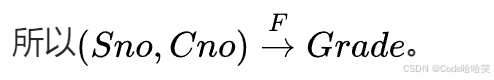
4.4.3 函数部分依赖
| Sno | Sname | Sdept | Sage |
|---|---|---|---|
| 001 | 张三 | 计算机系 | 20 |
| 002 | 李四 | 数学系 | 21 |
学号Sno可以决定学生所在的系Sdept,所以(Sno,Sname)一起也能决定学生所在的系Sdept,即称为Sdept对(Sno,Sname)部分依赖。
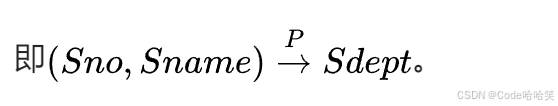
4.4.4 传递函数依赖
系表:
| Deptno | Dname |
|---|---|
| 001 | 计算机系 |
| 002 | 数学系 |
老师表:
| Tno | Tname | Deptno | Director |
|---|---|---|---|
| 0001 | 张老师 | 001 | 李主任 |
| 0002 | 王老师 | 001 | 李主任 |
| 0003 | 赵老师 | 002 | 钱主任 |
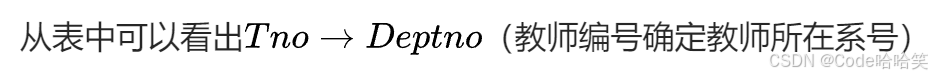
系号确定系主任
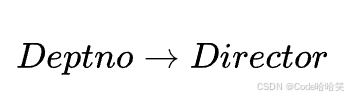
所以,Tno对Director是传递函数依赖,
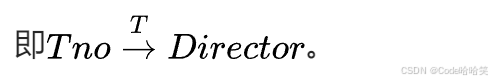
4.5 记号 t[A] 等




象集举例(下图是一个R表):



















 3436
3436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









