







前面介绍了与进程相关的一些文件,但是通常来说,我们的文件并不是所有的文件都被进程打开的。系统中绝大部分的文件都是未打开的状态,而这些文件通常存在于磁盘或者固态的硬盘当中,由文件系统统一进行管理,方便OS找到对应文件。
目录
3.inode中int block[15] 这个成员是如何存储对应数据块编号?
1.磁盘的简单介绍
现在在个人电脑上已经不怎么使用磁盘了,而是使用固态硬盘。主要是因为磁盘其实不是很稳定,如果经常移动设备,可能对磁盘存储造成较大影响。但是企业应用磁盘还是比较广泛的,这些磁盘主要被应用于一些服务器上,企业不使用硬盘的原因主要还是因为价格,在同等价格下,磁盘的存储容量比硬盘要大。
磁盘正面

磁盘背面

当我们需要读取数据时,马达会带动盘片旋转,同时磁头会在盘片区来回摆动。需要注意的是,磁头和盘片并没有接触(盘片转速通常是很高的,如果磁头与之相接触,会导致盘片产生大量的热量,而热量过高是能够消磁的),而且磁头与盘片接触可能会刮花盘片,导致存储的数据有一定的影响(这也是为什么笔记本电脑淘汰磁盘的原因)。
存储的方式:在计算机中,数据本质上都是以二进制的方式进行存储的,而对应到磁盘中的实现方式就是一个一个小磁铁。而每个磁铁都有南北极,如果我们以南极朝上为0,则北极朝上就为1。磁头通过对南北极的修改,实现对01序列的修改。
2.磁盘的物理存储
磁盘的存放的01序列并不是无序存放的,而是在盘片的特定结构下按顺序存储。
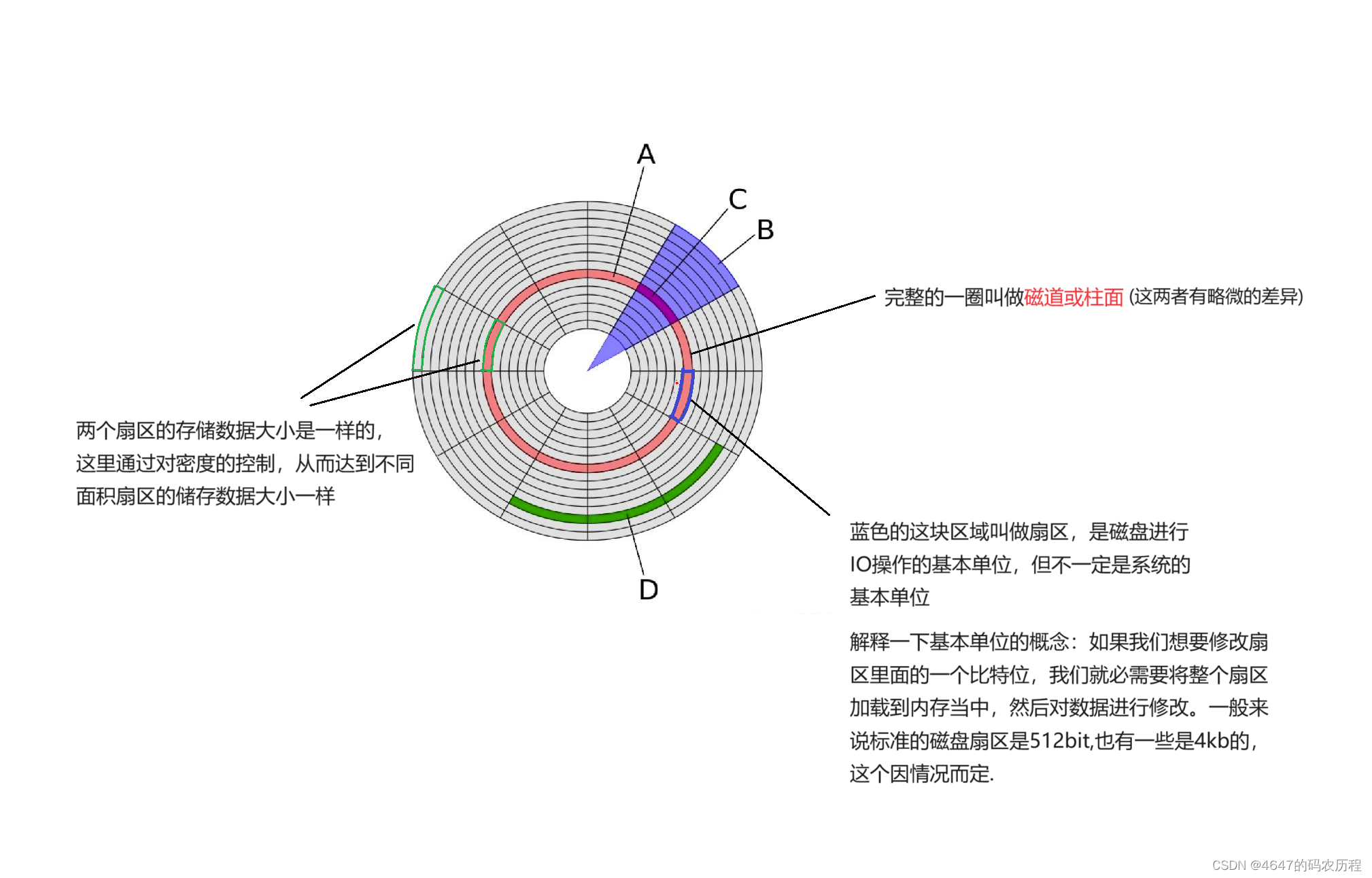
一个磁盘中可能会包含多个盘面和磁头,为了区分它们,每个盘面和磁头都会带有唯一的编号,而且磁道和扇区也有唯一的编号,当我们需要寻找特定扇区时,先要找到扇区所处的柱面(cylinder), 然后定位出在哪一个磁头(head)上,最后找到特定的扇区(sector)。这个寻址的方法又叫CHS定位法。
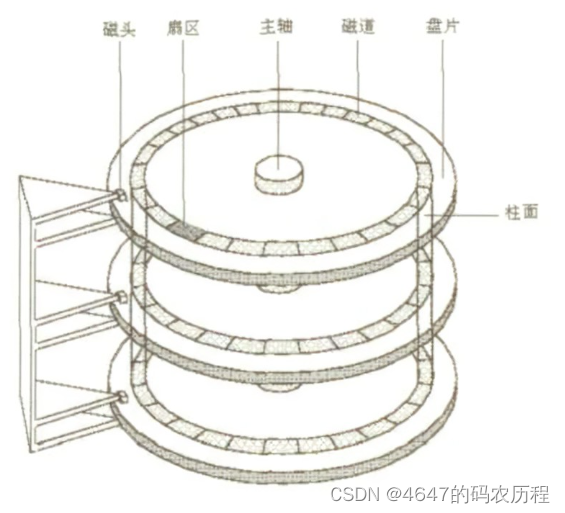
而文件就通过多个扇区就可以存储数据了。在寻找数据时,磁头会左右摆动来确定柱面,然后会选择磁头和扇区,这些过程都是机械运动并且磁盘还是外设,所以对于内存来说,这个过程是比较慢的。
3.磁盘的逻辑存储
在了解磁盘的逻辑存储之前,我们先看一下磁带。

磁带在运行时,磁带会逐渐被抽出,而磁带的侧面涂有磁性材料,能够存储数据。我们可以发现,磁带卷成圆盘状时,与我们的磁盘存储结构是类似的。那我们就可像磁带一样,将磁盘的结构像磁带一样,全部拉伸为一条绳。由此,我们就可以把磁盘变成一个巨大的线性空间,将不同的盘面的线性空间并在一起,就是整体存储数据的一个线性空间。

通过计算,我们可以得出,在800GB的储存空间中,大概有1677721600个扇区(每个扇区512字节)。为了管理这些扇区我们可以设置一个大小为1677721600的数组,代表每个扇区。
上面我们把磁盘抽象成了一个线性空间,但是在寻找扇区时,我们还是得通过CHS定位来找到扇区在磁盘位置。不过我们可以借助数组的下标来进行寻找
假设我们要寻找的扇区下标为count
则我们所要寻找的扇区所处的盘面 A = count / 每个盘面的扇区数量
在这个盘面中的第几个位置 tmp = count % 每个盘面的扇区数量
扇面所处的磁道 B = tmp / 一个磁道上扇区的个数
扇区的精确位置 D = tmp % 一个磁道上扇区的个数
上述的由线性地址转换成CHS的具体地址过程,是由磁盘本身来完成。
在OS文件系统中,OS认为磁盘的基本IO单位太小了,所以OS文件系统默认的IO基本单位是4kb。当然,这个数值可以通过编码进行修改。所以我们可以再对上述的线性地址进行修改,把连续的8个扇区看成一个大小为4kb的数据块,再创建一个数组。如果需要寻找扇区,也可以通过上述的方式来寻找,只不过中间还要再加一步。对于这个数组,我们用唯一的下标表示特定的数据块,而在文件系统中,我们称这些数组下标为LBA地址(逻辑块地址) 。
1.存储区域的划分
可是对于一个800GB的磁盘来说,仅用数组的方式肯定是没法管理这么大的区域的,所以文件系统就对磁盘进行分区(C盘D盘的由来便是这个),只要我们将一个区块的存储区域管理好了,另外几个区域的管理就可以照搬。

我们将800GB分成几个区,我们只要将100GB的存储空间管理好了,其余的区域自然不在话下。但是,100GB的储存空间还是太大了,所以我们需要再对100GB的空间进行分组。只要把其中一个组管理好了,我们就可以类似地把其余组管理好。

这样,我们就把一个管理800GB储存空间的问题转换成管理10GB储存空间的问题。下面介绍一下这些线性空间在计算机中的具体表现形式。
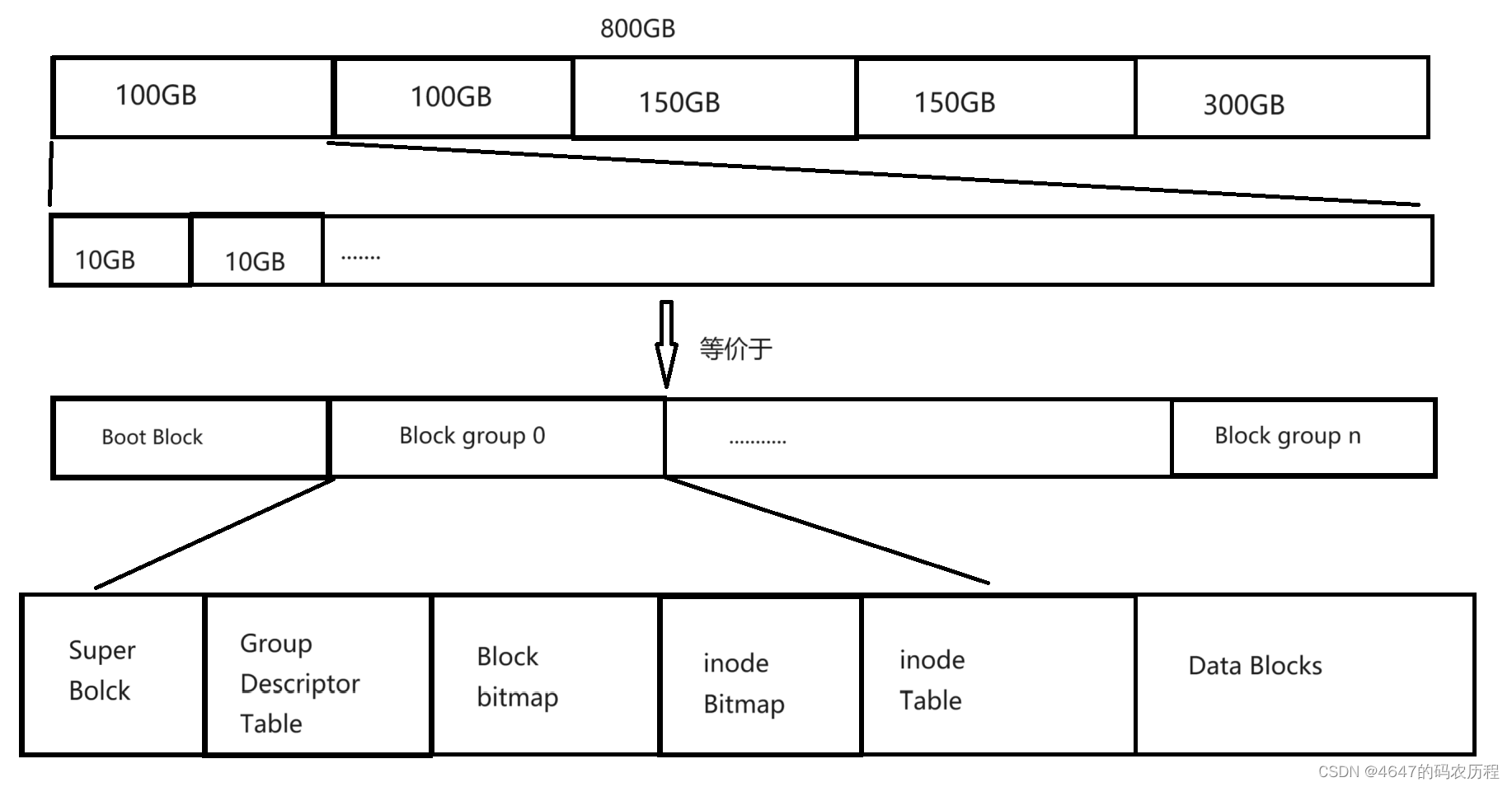
在正式介绍上述的存储区域之前,我们先了解一下linux中磁盘文件的特性
前面我们了解到,文件 = 内容 + 属性,内容和属性分别存储。其中内容的大小我们是不确定,可大可小,但是文件属性的大小是固定的。文件的属性类别是一样的,只不过不同文件的属性类别内容是不同的,我们可以通过一个结构体来描述这些属性类别。这个结构体称为inode,里面包括了文件类型,文件大小权限,类型等等,需要注意的是文件名并不属于文件名。这个inode结构体大小为128字节,而一个数据块能存储32inode结构体。为了区分每一个文件,我们需要给每一个inode结构以特定的inode编号,用于标识这个文件(标识文件不是文件名)。linux系统中可以使用" ll -i ",这条命令来查看每个文件的inode编号(例如下图的最左侧就是文件对应的inode)。

下面介绍具体这些分区的存储内容以及含义
<1>inode Table
inode Table是inode结构体存储表,里面存放了很多的inode结构体。这是一块连续的空间,不过大小是不确定的。
<2>inode Bitmap
由于inode Table里面存放了许多的inode结构体,但是我们怎么知道,哪一个inode被使用,哪一个没有使用呢?所以我们就可以使用位图的方式来标记哪些inode结构体没有被使用。比特位的位置,就表示第几个inode,比特位的内容表示inode是否被使用
<3>Data Block
这块区域就是用于存放文件内容的,里面被划分成了一个一个大小为4kb的数据块。
<4> Block Bitmap
这块区域用于标识哪一块Data Block区域中,哪一个数据块被使用了。原理和inode Bitmap是一样的。
<5>Group Descriptor Table
用于描述一个组储存空间使用情况,管理整个组,比如用了多少数据块,用来多少inode,整组的数据存储空间范围是多少,每个组的各个区域的开始区域......
<6> Super Block
存放文件系统本身的系统结构信息,管理整个分区,包括共有几个分区,每一个分区的使用情况,数据块共有多少等等。这块区域非常重要,一旦缺失,整个文件系统就挂掉了。但是也不是每一个分组内都包含,而是挑选一些分组插入。不在所有组里面存在是因为提高效率(一个数据更新,要刷新所有的Super Block),而在多个组中插入是为了防止一个Super Block崩溃导致整个分区挂掉。如果一个Super Block损坏,我们可以直接将其他组中Super Block覆盖写入,这也是我们平时开机时出现系统修复的原理。
<7>Boot Block
该区域与计算机开机相关,这里不详细介绍
2.文件的创建与删除
通过上面的知识,我们可以得知一个新文件的创建过程:先遍历inode Bitmap,其中通过一个计数器,记录遍历的inode个数,找到某一个比特位内容为0(比特位上的内容为1,就表示这个inode已经被使用了)就停下。此时将该比特位改为1,同时根据计数器的值来找道对应的具体的inode结构所在的位置。然后将文件的各种属性填充完毕后,拷贝到inode Table上,同时我们要在Block Bitmap上找到空余的数据块,用于存放文件内容,查找的步骤和前面差不多。在inode结构体中存在一个int block[15],用于存储一个文件的内容所占的数据块编号(稍后介绍)。
如果我们要删除一个文件,就把上文的步骤反过来。这里我们并不需要将inode Table 和 Data Block 中的内容删除,只需要将对应的inode Bitmap 和 Block Bitmap中的比特位清零即可。下次使用这些存储空间时,把原来的数据覆盖即可(这也时为什么应用的卸载比安装要快得多)。
inode编号在一个分区内是唯一的,在不同的组中,起始inode编号是不一样的,这个和上面的用数组分割存储空间的原理是一样的。如果我们要寻找一个文件的inode编号,只要将要寻找的inode编号与每个组的起始inode编号相比较即可。至于文件inode编号对应的inode Bitmap位置就是inode编号 - 起始inode 编号。
3.inode中int block[15] 这个成员是如何存储对应数据块编号?
如果只是单纯按顺寻存储每个存放文件内容的数据块编号,那样只能存储非常有限的编号,这和我们平常所看的超大文件的现象是相悖的。

4.文件系统
上述的区域划分并不是一开始就有的,而是在分区进行格式化后才写入的。
上述格式化的过程,其实就是向指定的分区中写入全新的文件系统(前面介绍区域划分的管理方式较Ext* (2) 文件系统)。现在一般我们用的Ext* (3) 或 Ext*(4),每一个分区都可以格式化不同的文件系统,而我们可以将每个分区的Super Block模块加载到内存中,并用链表链接起来,这样OS就能实现对文件系统的管理。
1.文件名
我们在系统中使用inode标识文件,但是作为用户,我们是根据文件名进行标识文件的。那么文件名在哪里呢?在解决这个问题前,我们需要对目录文件进行重新的了解。文件 = 属性 + 内容,目录文件的属性类别和普通文件是一样的,只不过内容上有些许差别。而目录文件内容存储的内容是
文件名 :inode编号的映射关系,有多少个文件,就有多少个映射关系。这也是之前我们没有目录的w权限,就不能创建文件,没有r权限,就不能读目录文件。
2.文件的增删查改问题
对于一个文件来说,进行增删查改,都和改文件的目录有关。所以我们要增删查改文件时,就要找到目录文件中的映射关系进行修改。在这之前,我们又必需先找到目录文件,目录文件包含于上级的目录文件中,依次类推,直到找到根目录的inode。找到根目录的inode后,再依次解析路径。
3.文件系统的挂载
前面我们了解到inode编号只在一个分区内有效,但是一个磁盘可能有许多分区,那么OS是如何知道文件在哪一个分区中?其实在一个被写入文件系统的分区,要被Linux使用,必需先把这个具有文件系统的分区进行“挂载”(挂载就是使文件系统和目录产生一定联系)。一个文件系统所对应的分区,挂载在对应的目录中。而我们访问分区中的文件,都是通过所挂载的路径访问的。回到最初的问题上,我们想要访问一个文件,可以将文件路径的前缀和文件系统挂载的路径进行比对,如果一致,就表示该分区中,就包含了我们需要寻找的文件。而我们执行一些操作时,基本都是通过进程来实现的,通过进程,我们就可以间接或直接获得文件所处的路径。
我们可以通过df -h 命令,来看一下具体系统的具体挂载情况

最左侧就是所挂载的分区路径。
小节:文件查找过程
-
解析路径:首先,文件系统需要解析你提供的文件路径。这个路径可以是绝对路径(从根目录
/开始),也可以是相对路径(从当前工作目录开始)。 -
查找当前目录的inode:如果路径是相对路径,文件系统会查找当前工作目录的inode。如果路径是绝对路径,通常从根目录(
/)开始。 -
读取目录内容:文件系统会读取当前目录inode指向的数据块,这些数据块包含了该目录下的所有文件和子目录的列表。
-
匹配下一级目录或文件:根据路径中的下一部分,文件系统在当前目录的列表中查找匹配的条目。如果这部分是目录,则继续查找该目录的inode;如果这部分是文件名,则查找该文件名对应的inode。
-
递归或返回结果:如果找到了匹配的目录,则重复步骤3和步骤4,直到找到最终的文件或确定文件不存在。如果找到了匹配的文件,则查找过程结束,返回该文件的inode信息。
-
获取文件数据:一旦找到文件的inode,应用程序可以通过inode中的指针访问文件的数据块,从而读取或写入文件内容。
以上就是所有的内容,文中如有不对之处,还望各位大佬指出,谢谢!!!















 3520
3520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









