







目录
一.字典
字典是一种存储键值对的结构
键(key)值(value)对 : 依据key可以快速找到value ,是一种映射关系,就好比在学校里依据学号找人,一个学号对应一个人这样的关系。学号在这里就可以认为是key , 人在这里就可以认为是value 。
在同一个字典中,键应该是唯一的,值则没有这个限制。
键是不可变对象,如整数,实数,复数,字符串,元组等类型,但不能使用列表,集合,字典或其他可变的类型作为字典的键,包含列表等可变序列也不能作为字典的键。
值是可变的,可以由任何数据类型组成。
创建
用 { } 进行创建:键值对之间使用 ,分隔开,键和值之间使用:分隔开
用 dict( )函数 进行创建:在()中的格式,键值对,key = value
#格式一
dict1 = {'id': 10,'name':'zhangsan','score':'66'}
#格式二
dict1 = {
'id': 10,
'name':'zhangsan',
'score':'66',
}
#格式三
dict2 = dict(id='10',name='zhangsan',score='66')创建字典是,如果一个键被赋予两次值,
访问
方法一:通过key访问
语法格式: 变量名[ key ]
information = {'id': 10, 'name': 'zhangsan', 'score': '66'}
print(information['name'])运行结果:

方法二:通过 get 方法获得
get( )第一个参数用于指定键,必须存在
第二个参数用于指定的键不存在时要返回的值
dict1 = {'id': 10, 'name': 'zhangsan', 'score': '66'}
print(dict1.get('name'))
print(dict1.get('na'))
print(dict1.get('na', '该值不存在'))运行结果:

遍历
用for循环进行遍历
# 获取键值对
name = {'张三': 66,
'李四': 55,
'小明': 99,
'小红': 87}
for item in name.items() :
print(item)
#单独获取key,value
for key,value in name.items():
print(f'{key}的成绩是{value}')运行结果:


增
如果字典里没有我们想要查找的键,会自动添加该键值对
name = {
'张三': 66,
'李四': 55,
'小明': 99,
'小红': 87
}
name['hh'] = 77
print(name)运行结果:
![]()
我们可以看到,本来不存在 'hh' ,经过操作其在字典里,完成了字典的增
改
如果字典中存在我们想要查找的键,会自动对已经存在的值进行修改
name = {
'张三': 66,
'李四': 55,
'小明': 99,
'小红': 87
}
name['李四'] = 77
print(name)运行结果:

我们可以看到,原来李四的成绩是55,经过我们的操作,变成了77
字典的增和改,我们可以类似为变量的创建和修改。原来不存在变量,命名并创建一个新变量之后,该变量存在了。同理,原来存在一个变量,我们重新赋值后,其值改变了。
删
用 del 进行字典元素的删除
name = {'张三': 66, '李四': 55, '小明': 99, '小红': 87}
del name['张三']
print(name)运行结果:
![]()
合并
1.update( )
语法格式: 变量名.update(另一个要加的变量名)
dict01 = {'张三': 66, '李四': 55}
dict02 = {'小明': 99, '小红': 87}
dict01.update(dict02)
print(dict01)
print(dict02)运行结果:

对dict01进行修改,对dict02不进行修改
2.{**d1 , **d2}
语法格式:d = {**d1, **d2}
dicthh = {'张三': 0, '李四': 55}
dict01 = {'张三': 66, '李四': 55}
dict02 = {'小明': 99, '小红': 87}
dict03 = {**dict01, **dict02}
dict04 = {**dict02, **dict01}
dict05 = {**dict01, **dict02, **dicthh}
dict06 = {**dicthh, **dict02, **dict01}
dict07 = {**dict01, **dict02, **dict03}
print(dict01)
print(dict02)
print(dict03)
print(dict04)
print(dict05)
print(dict06)
print(dict07)运行结果:

在这里,我们可以看到,利用{**d1 , **d2}是将结果赋值给了一个新变量,它可以合并多个字典,当合并的字典和前面相同时,则不进行合并,存在相同的key但value 不相同时,则对value 进行修改,当没有重复时,则进行合并。这也完全符合了字典的定义, 键应该是唯一的
3."|" "|="
语法格式:d = d1 | d2
dicthh = {'张': 66, '李四': 55}
dict01 = {'张三': 66, '李四': 55}
dict02 = {'小明': 99, '小红': 87}
dict03 = dict01 | dict02
dict04 = dict01 | dict02 | dicthh
print(dict01)
print(dict02)
print(dict03)
print(dict04)运行结果:

这个 | 的解释同上面{**d1 , **d2} 这个
语法格式:d2 |= d2
dict01 = {'张三': 66, '李四': 55}
dict02 = {'小明': 99, '小红': 87}
dict01 |= dict02
print(dict01)
print(dict02)|= 是原地更新,谁在前,对谁进行更新,类似于update( )
字典推导式
语法格式1:{key : value for value in iterable(可迭代对象)}
语法格式2:{key : value for value in iterable(可迭代对象) if 条件 }
d1 = {x:x*2 for x in range(1,9)}
print(d1)
d2 = {x:x*2 for x in range(1,9) if x % 2 == 0}
print(d2)语法格式2 中后面的采用if语句进行一个对于在前面的可迭代对象内的一个筛选
二. 集合
创建
语法格式1:用{ }进行创建
语法格式2:用set()进行创建
set1 = {1, 2, 3}
num = range(4,10)
set2 = set(num)
print(set1)
print(num)
print(set2) 运行结果: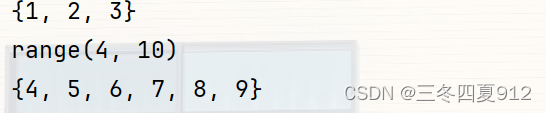
注意一点:{ } 当里面什么也没有时,是空字典
test = {}
print(type(test))运行结果:
![]()
增加
两种方法:
语法格式1:set1.add()
语法格式2:set1.update( iterable)
第一种方法用来添加一个元素,第二种方法用来添加一个可迭代对象或者序列(添加一个数直接输入到iterable那里是不对的,无法正常运行)。
num = range(1,8)
set1 = set(num)
print(set1)
#方法1:add()
set1.add(8)
print(set1)
#方法2:update()
Num = range(11,12)
set1.update(Num)
print(set1)运行结果:

删除
语法格式1:set1.clear()
清空所有元素
语法格式2:del set1
删除这个代码块,直接无法再找到,会报错
#clear()
num = range(1,8)
set1 = set(num)
print(set1)
set1.clear()
print(set1)
#del
num = range(1,8)
set1 = set(num)
print(set1)
del set1
print(set1)运行结果:

集合的运算
| A&B | 交集,返回一个同时在A和B中的元素的新集合 |
|---|---|
| A|B | 并集,返回一个包含A和B中所有元素的新集合 |
| A-B | 差集,返回一个包含在A不在B中元素的新集合 |
| A^B | 对称差集,返回一个不含同时在A和B中的元素的新集合 |
A = {1, 2, 3, 4, 5, 6}
B = {4, 5, 6, 7, 8, 9}
print(A & B)
print(A | B)
print(A - B)
print(A ^ B)运行结果:
集合推导式
语法格式1:{表达式 for 变量 in iterable(可迭代对象)}
语法格式2:{表达式 for 变量 in iterable(可迭代对象) if 条件 }
set1 = {x**2 for x in range(1,7)}
print(set1)
set2 = {x**2 for x in range(1,7) if x >=6}
print(set2)运行结果:

和前面的字典推导式很类似
三.字符串
字符串的定义格式
单行字符串
语法格式:s = ' '
单引号或者双引号引起来的
s1 = 'hhhhhhhhhhhh'
print(type(s1))
s2 = "hello"
print(type(s2))运行结果:

多行字符串
由三引号(三个单引号或三个双引号)引起的,通常里面什么格式,打印出来就什么格式
s3 = '''
*
***
*****
*
'''
print(s3)运行结果:

转义字符
利用反斜杠\ 加一个字符的形式进行转义
| \n | 换行符 |
|---|---|
| \t | 水平制表符 |
| \" | 双引号,单引号同理 |
| \\ | \ |
| \f | 换页符 |
print("红楼梦 西游记 水浒传 三国演义")
#\n
print("红楼梦\n西游记\n水浒传\n三国演义")
#\t 相当于一个tab键
print("红楼梦\t西游记\t水浒传\t三国演义")
#\'
print("红楼梦\'西游记\'水浒传\'三国演义")
#\\
print("红楼梦\\西游记\\水浒传\\三国演义")
#\f
print("红楼梦\f西游记\f水浒传\f三国演义")运行结果:
使用r 或者R避免出现转义字符的错误
在文件中会涉及到
格式化
方法1:占位符%格式化
方法2:format
方法3:f - string 方法
方法1:占位符%格式化
在要打印的字符串中,用占位符%和一个数据类型代号来地体变量,字符串中有多少占位符,就要有多少变量与占位符一一对应
name = "Tim"
age = 20
print("大家好,我是%s"%name)
print("大家好,我是%s,我的年龄是%d"%(name,age))运行结果:

方法2:format
name = "Tim"
age = 20
print("大家好,我是{},我的年龄是{}".format(name,age))
print("大家好,我是{0},我的年龄是{1}".format(name,age))
print("大家好,我是{1},我的年龄是{0}".format(name,age))这里的0,1 是后面format里面的顺序,从零开始,可以依据需要传入0,1......
运行结果:
输出浮点数,想指定小数点后面的位置,格式{ :.nf } ,n表示几位小数
n = 98.654321
print("概率为{:.2f}%".format(n))方法3:f - string 方法
语法格式:print(f "... {}...")
name = "Tim"
age = 20
print(f"大家好,我是{name},我的年龄是{age}")输出浮点数
good_percent = 98.654321
print(f"好评率是{good_percent}%")
print(f"好评率是{good_percent:.2f}%")














 2273
2273











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









