






在 Java 编程的世界里,IO 流如同数据传输的 “高速公路”,承担着程序与外部设备之间的数据交互重任。无论是读写文件、网络通信,还是处理其他外部资源,IO 流都是不可或缺的核心技术。同时,不同的 IO 网络模型也影响着数据交互的效率与性能。接下来,我们将深入剖析 Java IO 流的分类与应用,以及 BIO、NIO、AIO 网络模型的奥秘。
一、Java IO 流基础概念
1.1 什么是 IO 流
IO 流(Input/Output Stream)是 Java 中用于实现数据输入和输出操作的机制。输入流负责将外部数据读取到程序中,就像把外部世界的信息 “引入” 到程序的 “大脑”;输出流则负责将程序中的数据写入到外部设备,如同程序将处理好的信息 “发送” 到外部世界。例如,从文件中读取数据、向控制台输出信息、与网络服务器进行数据交换等,都离不开 IO 流的支持。
1.2 IO 流的分类维度
IO 流可以从多个维度进行分类:
- 流向维度:分为输入流和输出流。输入流是数据进入程序的通道,输出流是数据离开程序的通道。
- 操作单元维度:可分为字节流和字符流。字节流以字节(8 位二进制数据)为单位进行数据操作,适用于处理所有类型的数据,如图片、音频、视频等;字符流以字符(根据字符编码,一个字符可能由多个字节组成)为单位进行操作,专门用于处理文本数据,在处理中文等字符时更加方便高效。
- 角色维度:分为节点流和处理流。节点流直接与数据源或目标相连,如FileInputStream和FileOutputStream直接操作文件;处理流则 “包裹” 在节点流之上,对数据进行加工处理,如BufferedInputStream和BufferedOutputStream可以提高数据读写性能。
二、Java IO 流的具体类型及使用
2.1 字节流
2.1.1 字节输入流 FileInputStream
FileInputStream用于从文件中读取字节数据。通过指定文件路径创建对象后,可使用read()方法读取数据。read()方法每次读取一个字节,返回值为读取到的字节数据(以 int 类型表示,范围为 0 - 255),当读取到文件末尾时返回 -1。
try (FileInputStream fis = new FileInputStream("test.txt")) { int data; while ((data = fis.read()) != -1) { System.out.print((char) data); } } catch (Exception e) { e.printStackTrace(); }
2.1.2 字节输出流 FileOutputStream
FileOutputStream用于将字节数据写入文件。创建对象时,若文件不存在则创建新文件;若文件已存在,默认会覆盖原有内容。使用write()方法写入数据,可传入一个字节或字节数组。
try (FileOutputStream fos = new FileOutputStream("output.txt")) { String message = "Hello, World!"; byte[] data = message.getBytes(); fos.write(data); } catch (Exception e) { e.printStackTrace(); }
2.2 字符流
2.2.1 字符输入流 FileReader
FileReader是专门用于读取文本文件的字符输入流。它内部基于FileInputStream,自动处理了字节到字符的转换。使用read()方法读取字符,每次读取一个字符,返回值为读取到的字符(以 int 类型表示,实际为字符的 Unicode 编码值),文件末尾返回 -1。
try (FileReader reader = new FileReader("test.txt")) { int character; while ((character = reader.read()) != -1) { System.out.print((char) character); } } catch (Exception e) { e.printStackTrace(); }
2.2.2 字符输出流 FileWriter
FileWriter用于将字符数据写入文件,同样自动处理字符到字节的转换。write()方法可写入单个字符、字符数组或字符串。
try (FileWriter writer = new FileWriter("output.txt")) { writer.write("这是一段写入文件的字符数据"); } catch (Exception e) { e.printStackTrace(); }
2.3 缓冲流
2.3.1 缓冲字节流
- 字节缓冲输入流 BufferedInputStream:在FileInputStream基础上增加了缓冲机制,内部维护一个缓冲区。读取数据时,先将数据批量读取到缓冲区,后续读取操作直接从缓冲区获取,减少了对底层文件的频繁读取操作,提高了读取效率。
- 字节缓冲输出流 BufferedOutputStream:写入数据时,先将数据写入缓冲区,当缓冲区满或调用flush()方法时,才将数据一次性写入目标文件,降低了磁盘 I/O 操作次数。
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream("input.txt")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("output.txt"))) { int data; while ((data = bis.read()) != -1) { bos.write(data); } } catch (Exception e) { e.printStackTrace(); }
2.3.2 缓冲字符流
- 字符缓冲输入流 BufferedReader:除了具备缓冲功能外,还提供了readLine()方法,用于按行读取文本数据,非常方便处理文本文件。
- 字符缓冲输出流 BufferedWriter:提供newline()方法,用于写入系统相关的换行符,以及write()方法用于写入字符数据。
try (BufferedReader br = new BufferedReader(new FileReader("input.txt")); BufferedWriter bw = new BufferedWriter(new FileWriter("output.txt"))) { String line; while ((line = br.readLine()) != null) { bw.write(line); bw.newLine(); } } catch (Exception e) { e.printStackTrace(); }
2.4 转换流
转换流用于在字节流和字符流之间进行转换。当我们希望使用字符流的方法处理字节流数据时,就需要用到转换流。
- 字符转换输入流 InputStreamReader:将字节输入流转换为字符输入流,可指定字符编码,实现字节到字符的正确转换。
- 字节转换输出流 OutputStreamWriter:将字符输出流转换为字节输出流,同样可指定字符编码。
try (InputStreamReader isr = new InputStreamReader(new FileInputStream("input.txt"), "UTF-8"); OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("output.txt"), "UTF-8")) { int data; while ((data = isr.read()) != -1) { osw.write(data); } } catch (Exception e) { e.printStackTrace(); }
2.5 序列化流
序列化流用于将对象转换为字节序列(序列化),以便存储到文件或通过网络传输;反序列化流则用于将字节序列还原为对象。
- 序列化流 ObjectOutputStream:使用writeObject()方法将对象写入输出流。要序列化的对象必须实现Serializable接口。
- 反序列化流 ObjectInputStream:使用readObject()方法从输入流中读取并还原对象。
import java.io.*; class Person implements Serializable { private String name; private int age; public Person(String name, int age) { this.name = name; this.age = age; } // 省略getter和setter方法 } public class SerializationExample { public static void main(String[] args) { // 序列化对象 try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.ser"))) { Person person = new Person("Alice", 25); oos.writeObject(person); } catch (Exception e) { e.printStackTrace(); } // 反序列化对象 try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream("person.ser"))) { Person deserializedPerson = (Person) ois.readObject(); System.out.println("Deserialized Person: " + deserializedPerson.getName() + ", " + deserializedPerson.getAge()); } catch (Exception e) { e.printStackTrace(); } } }
2.6 打印流
打印流用于方便地输出各种数据类型,提供了丰富的格式化输出方法。
- 字节打印流 PrintStream:print()和println()方法可输出各种数据类型,printf()方法用于格式化输出,类似于 C 语言中的printf函数。PrintStream默认输出到控制台,也可指定输出目标,如文件。
- 字符打印流 PrintWriter:功能与PrintStream类似,但用于处理字符数据。
try (PrintStream ps = new PrintStream("output.txt")) { ps.println("这是一个字节打印流输出的示例"); ps.printf("格式化输出:%d, %s", 10, "字符串"); } catch (Exception e) { e.printStackTrace(); } try (PrintWriter pw = new PrintWriter("output.txt")) { pw.println("这是一个字符打印流输出的示例"); pw.printf("格式化输出:%d, %s", 20, "另一个字符串"); pw.flush(); } catch (Exception e) { e.printStackTrace(); }
2.7 压缩流
压缩流用于实现文件的压缩和解压缩操作。
- 压缩流 ZipInputStream:用于读取压缩文件(.zip 格式),通过getNextEntry()方法获取压缩包中的下一个文件或目录,isDirectory()方法判断当前条目是否为目录。
- 解压缩流 ZipOutputStream:用于创建压缩文件,使用putNextEntry()方法开始写入一个新的文件或目录条目,write()方法写入数据。
import java.io.*; import java.util.zip.*; public class ZipExample { public static void main(String[] args) { // 压缩文件 try (ZipOutputStream zos = new ZipOutputStream(new FileOutputStream("example.zip"))) { File fileToCompress = new File("test.txt"); zos.putNextEntry(new ZipEntry(fileToCompress.getName())); try (FileInputStream fis = new FileInputStream(fileToCompress)) { byte[] buffer = new byte[1024]; int length; while ((length = fis.read(buffer)) > 0) { zos.write(buffer, 0, length); } } zos.closeEntry(); } catch (Exception e) { e.printStackTrace(); } // 解压文件 try (ZipInputStream zis = new ZipInputStream(new FileInputStream("example.zip"))) { ZipEntry entry; while ((entry = zis.getNextEntry()) != null) { File outputFile = new File(entry.getName()); if (entry.isDirectory()) { outputFile.mkdirs(); } else { try (FileOutputStream fos = new FileOutputStream(outputFile)) { byte[] buffer = new byte[1024]; int length; while ((length = zis.read(buffer)) > 0) { fos.write(buffer, 0, length); } } } zis.closeEntry(); } } catch (Exception e) { e.printStackTrace(); } } }
三、Java IO 网络模型
3.1 BIO 同步阻塞模型
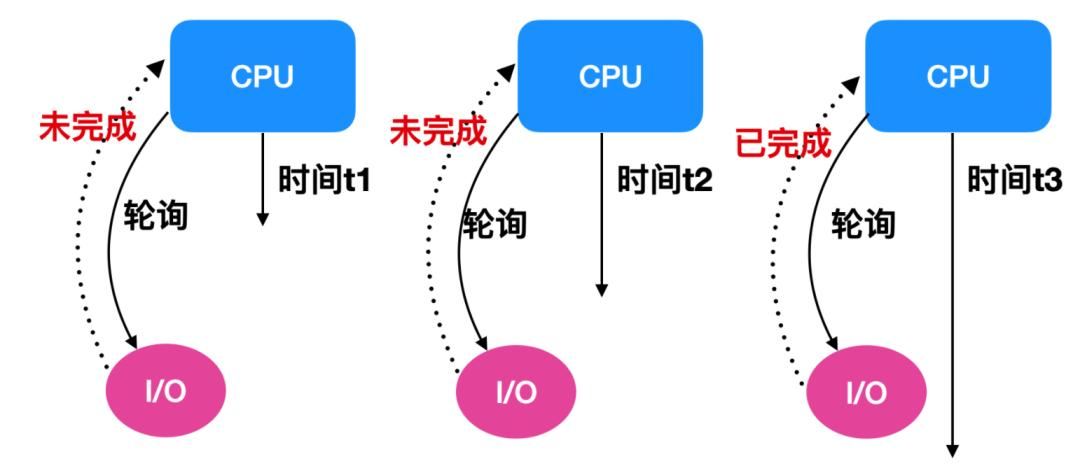
BIO(Blocking I/O)是同步阻塞模型。在 BIO 中,一个线程只能处理一个 Socket 连接。当线程处理 Socket 时,必须等待对方发送数据或完成操作后才能继续执行后续逻辑。例如,有一家小餐馆,只有一个服务员(线程),每来一位顾客(Socket 连接),服务员就得全程服务这位顾客,从点菜到上菜,期间不能去招呼其他顾客。这种方式在高并发场景下会导致线程数量消耗多、内存资源消耗高、CPU 上下文切换频繁,只适用于连接请求较少的情况。
3.2 NIO 同步非阻塞模型
NIO(Non-Blocking I/O)是同步非阻塞模型。一个线程可以监听处理多个 Socket 连接。它将所有客户端SocketChannel通道注册到轮询器(如Selector)的 kernel 内核上,有一个线程去轮询所有channel,当某一个channel状态发生变化时(如可读或可写),就去执行连接或接收请求逻辑。当线程发起一个 I/O 操作时,如果数据尚未准备好,NIO 会立即返回。
为了减少内核空间与用户空间之间的频繁切换,NIO 使用了多路复用技术。多路复用就是内核一次查询所有用户空间传入的fd文件描述符,只进行两次内核与用户态之间的切换,这就好比一个烤串师傅(线程),不用一直守着一个烤串(Socket 连接),而是可以同时关注多个烤串(fd 文件描述符),等某个烤串差不多好了(fd 状态变化)再去处理。
轮询器有select、poll和epoll等。select对用户态传入的fd文件数量有限制,poll没有这个限制。而epoll性能最优,它在内核态实现了红黑树和双向链表,红黑树存可连接的fd文件,双向链表存fd状态修改的fd文件,双向链表的数据是由中断技术(类似于信号驱动)来自动存取的,即自动检测fd文件状态修改并放入双向链表中。
3.3 AIO 异步非阻塞模型
AIO(Asynchronous I/O)是异步非阻塞模型。内核监听到请求事件后,会自动去处理请求,不需要切换到用户态去执行。异步处理完后,会进行通知相应线程进行后续操作。就像点外卖,顾客(线程)下单后不用一直等着,商家(内核)做好外卖后会主动通知顾客来取餐(后续操作),大大提高了效率和用户体验。但是现在并没有普及AIO,主要使用的还是BIO。
3.4 三种网络模型的对比与选择
| 模型 | 编程复杂度 | 并发性能 | 适用场景 |
| BIO | 简单 | 低 | 连接请求少、对性能要求不高 |
| NIO | 较复杂 | 高 | 高并发、阻塞时间较短的场景 |
| AIO | 复杂 | 最高 | 高并发、对响应时间要求苛刻 |
在实际项目中,应根据具体的业务需求、并发量、性能要求等因素综合考虑,选择合适的 IO 网络模型。
四、博主总结
- IO流(分类?IO网络模型?)
- 字节流
- 字节输入流:FileInputStream
- 字节输出流:FileOutputStream
- write()、read()
- 字符流
- 字符输入流FileReader
- 字符输出流:FileWriter
- write()、read()
- 缓冲字节流
- 字节缓冲输入流:BufferedInputStream
- 字节缓冲输出流:BufferedOutputStream
- write()、read()
- 缓冲字符流
- 字符缓冲输出流:BufferedReader
- 字符缓冲输入流:BufferedWriter
- write()、newline()、readline()
- 转换流:字节流 想要使用 字符流中的方法
- 字符转换输入流:InputStreamReader
- 字节转换输出流:OutputStreamWriter
- write()、read()
- 序列化流
- 序列化流:ObjectOutputStream
- 反序列化流:ObejectInputStream
- writeObject()、readObject()
- 打印流
- 字节打印流:PrintStream
- 字符打印流:PrintWriter
- write()、println()、print()、printf()、
- 压缩流
- 压缩流:ZipInputStream
- 解压缩流:ZipOutputStream
- getNextEntry()、isDirectory()、putNextEntry()、write()
- IO网络模型 BIO,NIO,AIO区别?
- 聊天池例子、烤串例子
- BIO同步阻塞模型:一个线程只能处理一个Socket链接,线程在处理Socket时,必须等待对方发送数据或完成操作后才能继续执行后续逻辑。线程数量消耗多、内存资源消耗高、CPU上下文切换频繁。适用于线程链接请求少的情况
- NIO同步非阻塞模型:
- 一个线程监听处理多个Socket链接,将所有客户端SocketChannel通道注册到轮询器的kernel内核上,上面有一个线程去轮询所有channel,当某一个channel状态发生变化时就去执行连接或接收请求逻辑。
- 执行过程中继续轮询,当线程发起一个I/O操作时,如果数据尚未准备好,NIO会立即返回。
- 其中轮询涉及到内核空间与用户空间之间的切换问题,所以使用了多路复用,多路复用就是内核一次查询所有用户空间传入的fd文件描述符,只进行两次内核与用户态之间的切换,类比于拿烤串。
- 轮询器分为select、poll它们区别就在于用户态传入的fd文件数量前者有限制、后者无限制。最好的是epoll,它在内核态实现了红黑树和双向链表,红黑树存可连接的fd文件,双向链表存fd状态修改的fd文件,双向链表的数据是由中断技术类似于信号驱动来自动存取的,中断技术在这里就是自动红黑树检测fd文件状态修改并放入双向链表中。
- AIO异步非阻塞模型,内核监听到请求事件后自动去处理请求,不需要切换到用户态去执行,异步处理完后会进行通知相应线程进行后续操作。
- 字节流


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









