






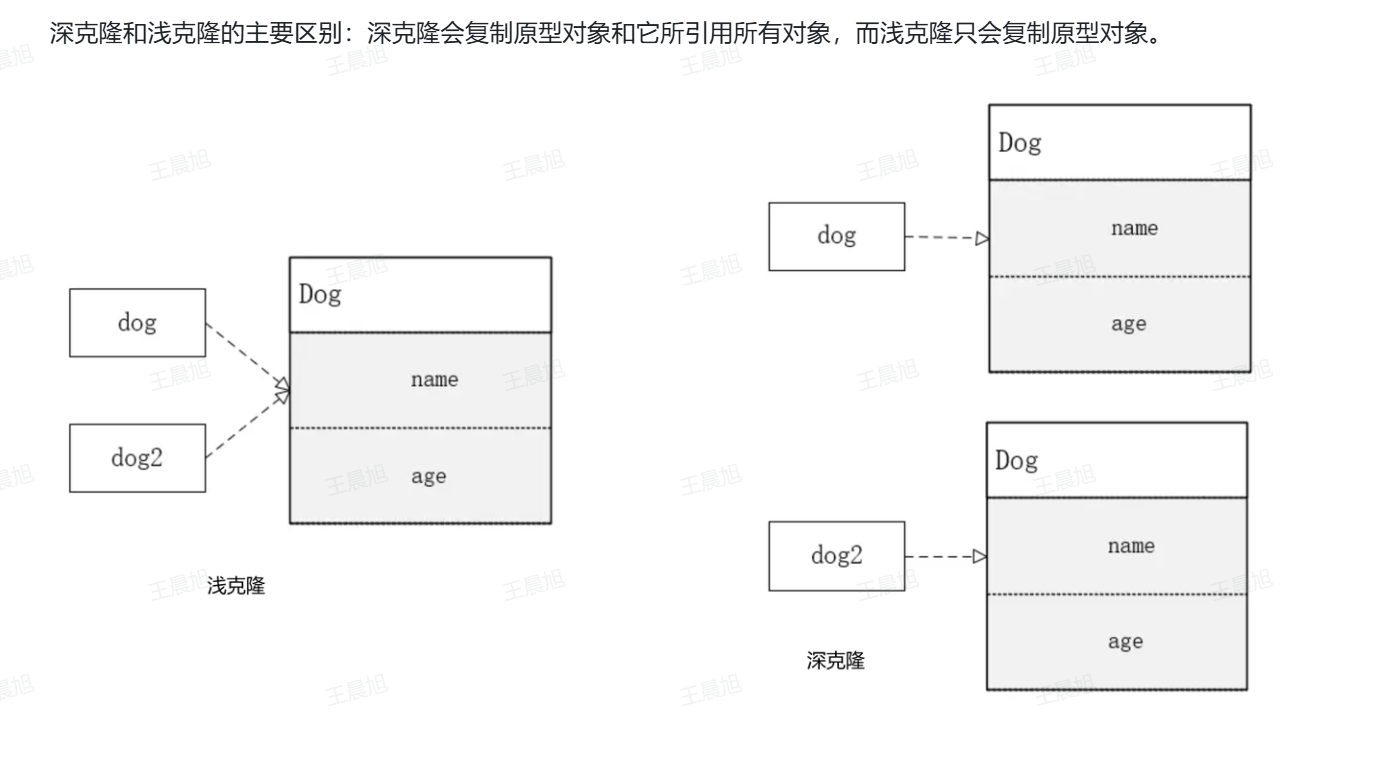
目录
一、开篇引入

在许多科幻电影中,比如《第六日》《双子杀手》 ,克隆人是经常出现的概念。在这些电影里,克隆人拥有和本体相同的外貌、基因,仿佛是从一个模子里刻出来的。这种神奇的设定让我们不禁对克隆技术充满了好奇,也引发了诸多关于伦理道德的思考。
在现实世界的编程领域,其实也存在着 “克隆” 的概念,那就是对象的克隆。它和科幻电影里的克隆人有着相似之处,都是创造出一个和原对象极为相似的副本。不过,在编程中,克隆又细分为深克隆和浅克隆,它们之间有着微妙而又关键的区别。这就好比双胞胎,看似一样,但性格、习惯等内在特质可能截然不同。接下来,就让我们一起深入探索编程世界里深克隆与浅克隆的奥秘。
二、克隆的基础概念
(一)Cloneable 接口
在 Java 中,克隆对象时,其所属类必须实现 Cloneable 接口,这是个无方法和属性的标记接口,相当于允许类被克隆的特殊徽章。它是 Java 的一种设计机制,避免任何类随意调用 clone () 方法引发不可预测问题,就像图书馆若无借阅规则会乱套一样。有了这个接口,只有实现它的类才能调用 clone () 方法,保证克隆操作安全规范。若类未实现 Cloneable 接口却调用 clone () 方法,会抛出 CloneNotSupportedException 异常。
class Animal { private String name; public Animal(String name) { this.name = name; } } public class Test { public static void main(String[] args) { Animal animal = new Animal("小狗"); try { Animal clonedAnimal = (Animal) animal.clone(); // 此处会抛出CloneNotSupportedException异常 } catch (CloneNotSupportedException e) { e.printStackTrace(); } } }
在上述代码中,Animal 类没有实现 Cloneable 接口,当尝试调用 clone () 方法时,就会抛出异常。所以,在进行克隆操作之前,一定要确保类实现了 Cloneable 接口。
(二)浅克隆与深克隆的初步概念
为助于理解浅克隆和深克隆,先看生活例子。假设你有份含文字(基本数据类型)和图片(引用数据类型)的重要文件要复制。浅克隆像复印文件,文字完整复制,图片直接引用原图,两份文件图片共享同一引用,一份图片修改,另一份也会变。深克隆则像重新制作文件,文字和图片都全新复制,两份文件图片相互独立,修改互不影响。在编程中,浅克隆对基本数据类型字段在新对象复制新值,引用类型字段仅复制引用,新原对象共享引用对象;深克隆递归复制所有引用类型字段,创建完全独立新对象,修改新对象不影响原对象。通过此比喻已有基本认识,接下来将用具体代码示例深入了解。
三、浅克隆深入剖析
(一)浅克隆原理
浅克隆在创建对象副本时,对于值类型字段,它会直接复制字段的值到新对象中 。比如一个整数类型的字段,浅克隆会在新对象中创建一个相同值的整数字段。而对于引用类型字段,浅克隆只是复制引用,也就是新对象和原对象中的引用类型字段指向同一个内存地址 。
(二)代码示例
以下是一个用 Java 实现浅克隆的代码示例:
class Address implements Cloneable { private String city; private String street; public Address(String city, String street) { this.city = city; this.street = street; } public String getCity() { return city; } public String getStreet() { return street; } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } } class Person implements Cloneable { private String name; private int age; private Address address; public Person(String name, int age, Address address) { this.name = name; this.age = age; this.address = address; } public String getName() { return name; } public int getAge() { return age; } public Address getAddress() { return address; } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } } public class ShallowCloneExample { public static void main(String[] args) { try { Address address = new Address("北京", "中关村大街"); Person original = new Person("张三", 30, address); Person cloned = (Person) original.clone(); System.out.println("原对象地址信息: " + original.getAddress()); System.out.println("克隆对象地址信息: " + cloned.getAddress()); // 修改克隆对象的地址信息 cloned.getAddress().setCity("上海"); System.out.println("原对象的城市: " + original.getAddress().getCity()); System.out.println("克隆对象的城市: " + cloned.getAddress().getCity()); } catch (CloneNotSupportedException e) { e.printStackTrace(); } } }
在上述代码中,Person类和Address类都实现了Cloneable接口。Person类的clone方法直接调用了super.clone() ,这就实现了浅克隆。当我们修改cloned对象的address中的city属性时,original对象的address中的city属性也会被修改,这就验证了浅克隆中引用类型字段共享的特性。 运行结果如下:
原对象地址信息: Address@1540e19d
克隆对象地址信息: Address@1540e19d
原对象的城市: 上海
克隆对象的城市: 上海
从结果可以看出,原对象和克隆对象的address引用是相同的,所以修改其中一个对象的地址信息,另一个对象也会受到影响。
(三)浅克隆的应用场景和局限性
浅克隆适用于对性能要求高,且对象内部引用类型字段在生命周期中不变的场景。比如游戏开发里游戏角色对象基本属性常变,但关联的静态配置信息不变,可用浅克隆快速创建新角色对象,复制引用节省内存和时间。不过浅克隆也有局限,因其共享引用类型字段,当对象内部引用类型字段可能被修改时就会出问题,像多线程环境或电商系统中,一个线程或订单修改引用类型字段,其他相关对象也会受影响,导致数据不一致等错误。所以使用浅克隆时,务必充分考虑对象内部引用类型字段的可变性,规避共享引用带来的潜在问题。
四、深克隆深入剖析
(一)深克隆原理
深克隆的核心原理是递归复制对象及其内部所有引用类型字段。进行深克隆时,先创建与原对象类和基本数据类型字段值相同的新对象实例,接着对原对象的每个引用类型字段所引用的对象创建新副本,并递归复制新副本中的引用类型字段,直至所有引用类型字段都被复制为全新独立对象。
与浅克隆不同,浅克隆仅复制引用类型字段的引用,深克隆则是真正复制其指向的对象,就像复制文件夹,浅克隆是复制快捷方式,深克隆是复制所有文件和子文件夹。深克隆创建的新对象与原对象在内存中完全独立,修改克隆对象属性不会影响原对象,提供了更高的数据安全性和独立性。
(二)深克隆的实现方式
1. 重写 clone 方法
要通过重写 clone 方法实现深克隆,首先类要实现 Cloneable 接口 。然后在重写的 clone 方法中,不仅要调用 super.clone () 来复制基本数据类型和 String 类型的字段 ,还要对引用类型字段进行单独处理,递归地调用它们的 clone 方法(如果引用类型也实现了 Cloneable 接口) 。
例如,假设有一个包含多层引用的对象结构:
class Address implements Cloneable { private String city; private String street; public Address(String city, String street) { this.city = city; this.street = street; } public String getCity() { return city; } public String getStreet() { return street; } @Override protected Object clone() throws CloneNotSupportedException { return super.clone(); } } class Person implements Cloneable { private String name; private int age; private Address address; public Person(String name, int age, Address address) { this.name = name; this.age = age; this.address = address; } public String getName() { return name; } public int getAge() { return age; } public Address getAddress() { return address; } @Override protected Object clone() throws CloneNotSupportedException { Person cloned = (Person) super.clone(); cloned.address = (Address) address.clone(); // 深克隆引用类型字段 return cloned; } }
在上述代码中,Person类重写了clone方法 。首先调用super.clone()获取浅克隆的对象,然后对address引用类型字段进行单独的深克隆操作 。这样,当对Person对象进行克隆时,就实现了深克隆。需要注意的是,如果Address类中的引用类型字段还有嵌套的引用,也需要在Address类的clone方法中进行相应的递归克隆处理 ,以确保整个对象结构的完全独立复制。
2. 序列化和反序列化
通过 Java 的序列化机制也可以实现深克隆 。其原理是将对象写入到字节流中(序列化),然后再从字节流中读取数据创建新的对象(反序列化) 。在这个过程中,Java 会自动处理对象内部的引用关系,创建出一个全新的、与原对象完全独立的对象 。
实现步骤如下:
- 让需要克隆的类及其内部的所有引用类型字段所属的类都实现 Serializable 接口 ,该接口是一个标记接口,用于标识可以被序列化。
- 使用 ObjectOutputStream 将对象写入到 ByteArrayOutputStream 中 ,实现对象的序列化。
- 使用 ObjectInputStream 从 ByteArrayOutputStream 中读取数据,实现对象的反序列化,得到深克隆的对象。
代码示例:
import java.io.*; class Address implements Serializable { private String city; private String street; public Address(String city, String street) { this.city = city; this.street = street; } public String getCity() { return city; } public String getStreet() { return street; } } class Person implements Serializable { private String name; private int age; private Address address; public Person(String name, int age, Address address) { this.name = name; this.age = age; this.address = address; } public String getName() { return name; } public int getAge() { return age; } public Address getAddress() { return address; } public Object deepClone() { try { ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream oos = new ObjectOutputStream(bos); oos.writeObject(this); ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray()); ObjectInputStream ois = new ObjectInputStream(bis); return ois.readObject(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); return null; } } }
在上述代码中,Person类和Address类都实现了Serializable接口 。Person类中的deepClone方法通过序列化和反序列化实现了深克隆 。这种方式虽然实现起来相对简单,但由于涉及到 I/O 操作,性能上可能会比直接重写clone方法略差一些,并且要求所有相关类都必须实现Serializable接口 。
3. JSON 转换
将对象转换为 JSON 字符串,然后再将 JSON 字符串转换回对象,也可以实现深克隆 。其原理是利用 JSON 库将对象的状态信息转换为文本格式的字符串 ,在转换过程中,对象的所有属性都会被转换为字符串形式保存。然后,再通过 JSON 库将这个字符串解析为新的对象,这个新对象与原对象在内存中是相互独立的 。
使用方法如下:
- 引入 JSON 库,如 Gson、Jackson 等 。
- 使用 JSON 库的 API 将对象转换为 JSON 字符串 。
- 再使用 JSON 库将 JSON 字符串转换为新的对象。
以 Gson 库为例的代码示例:
import com.google.gson.Gson; class Address { private String city; private String street; public Address(String city, String street) { this.city = city; this.street = street; } public String getCity() { return city; } public String getStreet() { return street; } } class Person { private String name; private int age; private Address address; public Person(String name, int age, Address address) { this.name = name; this.age = age; this.address = address; } public String getName() { return name; } public int getAge() { return age; } public Address getAddress() { return address; } public Object deepClone() { Gson gson = new Gson(); String json = gson.toJson(this); return gson.fromJson(json, this.getClass()); } }
在上述代码中,Person类的deepClone方法通过 Gson 库将自身转换为 JSON 字符串,然后再从 JSON 字符串转换回新的Person对象 ,从而实现了深克隆。这种方式的优点是简单直观,并且不需要类实现特定的接口 。但它也有局限性,比如对于一些特殊类型(如含有循环引用、自定义序列化逻辑的对象)可能无法正确处理,而且性能上也可能存在一定的开销 。
4. 第三方工具
以 Apache Commons 库中的 SerializationUtils 类为例,它提供了方便的深克隆方法 。使用时,首先需要在项目中引入 Apache Commons Lang 库 。然后,对于实现了 Serializable 接口的类,就可以使用 SerializationUtils.clone 方法来实现深克隆 。
代码示例:
import org.apache.commons.lang3.SerializationUtils; import java.io.Serializable; class Address implements Serializable { private String city; private String street; public Address(String city, String street) { this.city = city; this.street = street; } public String getCity() { return city; } public String getStreet() { return street; } } class Person implements Serializable { private String name; private int age; private Address address; public Person(String name, int age, Address address) { this.name = name; this.age = age; this.address = address; } public String getName() { return name; } public int getAge() { return age; } public Address getAddress() { return address; } public Object deepClone() { return SerializationUtils.clone(this); } }
在上述代码中,Person类通过调用SerializationUtils.clone(this)方法实现了深克隆 。使用第三方工具可以大大简化深克隆的实现过程,并且这些工具通常经过了优化,在性能和稳定性上都有较好的表现 。不过,引入第三方库也会增加项目的依赖,需要在项目管理中进行合理的处理 。
(三)深克隆的应用场景
深克隆适用于许多需要完全独立对象副本的场景 。比如在游戏开发中,玩家在游戏中的角色可能有装备、技能等复杂的属性结构 。当玩家进行一些副本挑战时,为了保证每个玩家的游戏体验不受其他玩家影响,并且在玩家对自己的角色属性进行修改(如更换装备、升级技能)时,不会影响到原始的角色数据,就可以使用深克隆来创建角色的副本 。这样每个玩家在副本中操作的都是自己角色的独立副本,修改副本的属性不会影响到其他玩家和原始角色。
在金融系统中,对于一些重要的交易数据对象,也经常会用到深克隆 。例如,在进行一笔复杂的金融交易模拟时,需要根据原始的交易数据对象创建多个副本进行不同场景的模拟分析 。由于每个模拟场景可能会对交易数据进行各种修改(如调整交易金额、交易时间等),为了确保原始交易数据的完整性和准确性,就需要使用深克隆来创建完全独立的交易数据副本 。这样在一个模拟场景中对副本数据的修改不会影响到其他模拟场景和原始交易数据,保证了模拟分析的可靠性和数据的安全性 。
五、深克隆与浅克隆对比
| 对比维度 | 浅克隆 | 深克隆 |
| 原理 | 创建新对象,复制基本数据类型字段值,引用类型字段复制引用,新对象和原对象共享引用对象内存地址 | 递归复制对象及其内部所有引用类型字段,创建全新、独立对象,新对象和原对象在内存中无共享引用对象 |
| 实现难度 | 实现简单,类实现 Cloneable 接口并重写 clone 方法,直接调用 super.clone () 即可 | 实现相对复杂,重写 clone 方法时需递归处理引用类型字段;序列化和反序列化方式要求类实现 Serializable 接口;JSON 转换需引入 JSON 库并处理特殊类型;使用第三方工具需引入相关库并处理依赖 |
| 性能影响 | 性能优势明显,仅复制对象本身、基本数据类型和 String 类型字段及引用类型字段的引用,避免递归复制引用对象,减少内存分配和对象复制次数,性能开销小 | 性能劣势明显,需递归复制所有引用成员,创建更多新对象,进行更多内存分配和复制操作,处理大型对象或复杂引用关系对象时性能开销大,消耗更多 CPU 和内存资源 |
| 适用场景 | 适用于对性能要求高且对象内部引用类型字段在生命周期内不变的场景,如游戏开发中创建大量角色对象,其关联静态配置信息不变 | 适用于需要完全独立对象副本的场景,如游戏副本挑战中创建玩家角色副本,金融系统中进行交易数据模拟分析时创建交易数据副本 |
六、博主总结
深克隆和浅克隆作为对象克隆的两种重要方式,在编程世界中各自扮演着独特的角色。浅克隆通过简单地复制引用,在性能和内存利用上具有优势,适用于那些对效率要求较高且对象内部引用类型字段相对稳定的场景 ,为我们在处理一些简单对象结构或追求快速复制的情况下提供了便捷的解决方案。
- 深克隆与浅克隆区别
- 克隆前都要实现Cloneable接口,这是一个标记接口,表示可以被克隆
- 浅克隆:对于值类型字段,它会直接复制字段的值到新对象中 。对于引用类型的字段,浅克隆后的对象和原对象共享同一个内存地址,即修改任一对象另一对象也会改变。
- 深克隆:深克隆不仅复制对象本身,还会递归地复制对象内部的所有引用类型字段,创建一个完全独立的对象。深克隆后的对象和原对象是完全独立的,修改克隆对象的引用类型字段不会影响原对象。需要重写clone()很笨重,也可以通过⭕序列化和非序列化、⭕先将对象转换成JSON字符串,然后再将JSON字符串转换成新对象、⭕使用第三方克隆工具类实现深克隆:如Apache Commons库中的SerializationUtils类。
- 快速理解

















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









